







《UIGEN-T2 模型速读》
一、模型概述
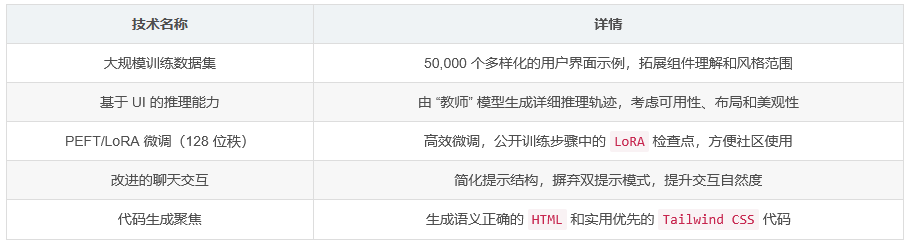
UIGEN-T2 是一款在 Qwen2.5-Coder-7B-Instruct 基础模型上,通过 PEFT/LoRA 微调得到的专门用于网页界面代码生成的模型。该模型能够产生具有功能性和语义性的 HTML 以及基于实用性的 Tailwind CSS 代码,其核心优势在于经过大规模的数据集训练,并具备独特的基于用户界面的推理能力。训练数据集样本数量庞大,达到 50,000 个,涵盖各种不同的用户界面示例,助力模型更全面地理解组件构成以及不同的风格类型。
二、模型亮点
-
高质量 UI 代码生成 :可生成既具备功能性又符合语义规范的
HTML代码,并与实用优先的Tailwind CSS相结合,从而构建出优秀的用户界面。 -
大规模训练数据集 :依托 50,000 个多样化的用户界面示例进行训练,相较于以往模型在组件理解和风格范围上有了显著拓展。
-
创新的基于 UI 的推理能力 :引入经过专门训练的 “教师” 模型生成的详细推理轨迹,使得输出的代码能充分考虑可用性、布局以及美观性等诸多因素。例如在设计一个优雅的秒表用户界面时,模型会遵循内部的推理过程来生成代码。
-
基于 PEFT/LoRA 的高效微调(128 位秩) :通过这种方式,不仅提升了模型在用户界面生成方面的性能,还实现了高效的训练过程。并且,团队在训练过程中的每个步骤都公开了
LoRA检查点,这既增加了透明度,也方便了社区使用者进行进一步的研究或应用开发。 -
改进的聊天交互体验 :简化了提示结构,摒弃了之前别扭的双提示交互模式,使得整个交互过程更加自然流畅。
三、示例推理与输出
文中展示了一段模型内部的示例推理过程(由 “教师” 模型生成),在面对打造一个优雅的秒表用户界面这一任务时,模型会从自身的第一反应开始,逐步深入思考,最终生成相应的代码。同时,模型能够根据描述或者线框图快速生成 HTML 和 Tailwind CSS 代码片段 ,还能创建标准以及定制化的用户界面组件,如按钮、卡片、表单、布局等,助力前端开发加速,为从设计概念到初始代码实现搭建桥梁。
四、使用场景与局限性
-
推荐使用场景 :适用于快速进行用户界面原型制作,生成基础的组件结构,协助前端开发人员提升开发效率,在设计概念与代码实现之间起到关键的衔接作用。
-
局限性 :对于动态行为、复杂状态管理等复杂的
JavaScript逻辑交互无能为力,通常需要人工手动去实现这些部分。而且在面对具有严格独特风格要求的复杂企业级设计系统时,可能需要进一步的专项微调才能达到理想效果。
五、使用方法
首先要确保安装了 PEFT,然后模型名(路径)、基础模型名等参数需要正确设置 。利用 transformers 库中的 AutoModelForCausalLM 和 AutoTokenizer 等类,依次加载基础模型、 PEFT 模型(LoRA 权重),并使用基础模型的分词器。 在构建提示时,采用简化的提示结构,模型会根据提示生成推理过程以及相应的代码。通过调用模型的生成方法并设置好最大新生成的令牌数、是否采样以及温度等参数,就能获取生成结果,并使用分词器解码输出。
六、优势与劣势
-
优势
-
能生成语义正确且结构合理的
HTML和Tailwind CSS代码。 -
凭借庞大的数据集(50k 样本),在鲁棒性和多样性方面表现出色。
-
借助设计推理,产出更具深思熟虑的用户界面。
-
聊天模板改进,提升了易用性。
-
向社区公开
LoRA检查点,利于大家使用。
-
-
劣势
-
当前仅限生成
HTML和Tailwind CSS,不过后续计划增加对Bootstrap的支持。 -
复杂的
JavaScript交互行为需手动实现。 -
强化学习进一步精化(以便更严格地遵循原则 / 奖励机制)是后续需要开展的工作。
-
七、技术架构与关键参数
该模型是基于变换器架构的大型语言模型,通过 PEFT/LoRA 进行适配。基础模型是 Qwen/Qwen2.5-Coder-7B-Instruct,适配器秩(LoRA)为 128。训练数据规模达到 50,000 个样本,训练时采用 bf16 或 fp16 精度,并且根据不同的量化 / 精度要求,基础模型需要相应的精度处理。在硬件方面,建议使用显存 >= 16GB 的 GPU 来高效进行推理,软件依赖包括 Hugging Face Transformers 以及 PyTorch。
八、核心技术创新表格


















 1158
1158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











