






实验3 生成对抗网络实验
一、基本要求
- 学习生成对抗网络实验的基本原理
- 学习与参考:https://blog.csdn.net/qq_45510888/article/details/113761697
- 运行代码,做好实验记录
二、实验报告
不要求
三、作业
寻找除mnist之外的数据集或自建数据集,采用GAN实验,并撰写实验说明书。
作业 GAN生成Fashion-MNIST集
一、实验概述
在这个实验中,我使用GAN生成对抗网络对Fashion-MINST数据集进行了训练,并生成了数据。我在训练中记录了可被10整除的epoch的实验结果。
二、GAN模型
GAN网络及训练代码如下。其中D(判别器)含有一个输入层、一个输出层和两个隐含层,激活函数使用的是LeakyRelu,最后使用Sidmoid函数将输出控制在0和1之间。G(生成器同样含有两个隐含层 ,激活函数使用ReLu。我利用python内置的logger模块把实验结果保存到了GAN.log日志文件中。每个epoch输出一张生成图和原数据集图片的对比图,保存到img文件夹下。
import logging
import time
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader
from torchvision import models
from torchvision import transforms
# 创建logger对象
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
# 创建文件处理器
file_handler = logging.FileHandler('GAN.log', mode='a', encoding='utf-8')
# 创建格式化器
formatter = logging.Formatter('%(levelname)s - %(message)s')
file_handler.setFormatter(formatter)
# 将文件处理器添加到logger
logger.addHandler(file_handler)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
batch_size = 32
image_size = 784
hidden_size = 256
# Compose定义了一系列transform,此操作相当于将多个transform一并执行
transform = transforms.Compose([
transforms.ToTensor(),
# mnist是灰度图,此处只将一个通道标准化
transforms.Normalize(mean=0.5, std=0.5)
])
# 设定数据集
mnist_data = torchvision.datasets.FashionMNIST("../data", train=True, download=True, transform=transform)
# 加载数据集,按照上述要求,shuffle本意为洗牌,这里指打乱顺序,很形象
dataloader = DataLoader(dataset=mnist_data, batch_size=batch_size, shuffle=True, num_workers=2, persistent_workers=True,
pin_memory=True)
# Discriminator
D = nn.Sequential(
nn.Linear(image_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, 1),
nn.Sigmoid() # sigmoid结果为(0,1)
)
# Generator
latent_size = 64 # latent_size,相当于初始噪声的维数
G = nn.Sequential(
nn.Linear(latent_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, image_size),
nn.Tanh() # 转换至(-1,1)
)
# 放到gpu上计算(如果有的话)
D = D.to(device)
G = G.to(device)
# 定义损失函数、优化器、学习率
loss_fn = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0002)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0002)
# 先定义一个梯度清零的函数,方便后续使用
def reset_grad():
d_optimizer.zero_grad()
g_optimizer.zero_grad()
# 迭代次数与计时
total_step = len(dataloader)
num_epochs = 100
if __name__ == '__main__':
start = time.perf_counter() # 开始时间
# 开始训练
for epoch in range(num_epochs):
total_dx = 0
total_dgz = 0
print("Epoch [{}/{}]------------------------------------------------------------".format(epoch + 1, num_epochs))
logger.info(f"Epoch [{epoch + 1}/{num_epochs}]----------------------------------------------------")
for i, (images, _) in enumerate(dataloader): # 当前step
batch_size = images.size(0) # 变成一维向量
images = images.reshape(batch_size, image_size).to(device)
# 定义真假label,用作评分
real_labels = torch.ones(batch_size, 1).to(device)
fake_labels = torch.zeros(batch_size, 1).to(device)
# 对D进行训练,D的损失函数包含两部分
# 第一部分,D对真图的判断能力
outputs = D(images) # 将真图送入D,输出(0,1),应该是越接近1越好
d_loss_real = loss_fn(outputs, real_labels)
real_score = outputs # 真图的分数,越大越好
total_dx += torch.sum(real_score).item()
# 第二部分,D对假图的判断能力
z = torch.randn(batch_size, latent_size).to(device) # 开始生成一组fake images即32*784的噪声经过G的假图
fake_images = G(z)
outputs = D(fake_images.detach()) # 将假图片给D,detach表示不作用于求grad
d_loss_fake = loss_fn(outputs, fake_labels)
fake_score = outputs # 假图的分数,越小越好
total_dgz += torch.sum(fake_score).item()
# 开始优化discriminator
d_loss = d_loss_real + d_loss_fake # 总的损失就是以上两部分相加,越小越好
reset_grad()
d_loss.backward()
d_optimizer.step()
# 对G进行训练,G的损失函数包含一部分
# 可以用前面的z,也可以新生成,因为模型没有改变,事实上是一样的
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
outputs = D(fake_images)
g_loss = loss_fn(outputs, real_labels) # G想骗过D,故让其越接近1越好
# 开始优化generator
reset_grad()
g_loss.backward()
g_optimizer.step()
# 优化完成,下面进行一些反馈,展示学习进度
if i % 100 == 0:
print("Step [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.2f}, D(G(z)): {:.2f}"
.format(i, total_step, d_loss.item(), g_loss.item(), real_score.mean().item(),
fake_score.mean().item()))
logger.info("Step [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.2f}, D(G(z)): {:.2f}"
.format(i, total_step, d_loss.item(), g_loss.item(), real_score.mean().item(),
fake_score.mean().item()))
total_dx /= total_step * batch_size
total_dgz /= total_step * batch_size
print(f"Avg D(x):{total_dx}\nAvg D(G(z)):{total_dgz}")
logger.info(f"Avg D(x):{total_dx}\nAvg D(G(z)):{total_dgz}")
if epoch % 10 == 0:
# 向G输入一个噪声,观察生成的图片
z = torch.randn(1, latent_size).to(device)
fake_images = G(z).view(28, 28).data.cpu().numpy()
plt.subplot(1, 2, 1)
plt.imshow(fake_images, cmap=plt.cm.gray)
plt.subplot(1, 2, 2)
plt.imshow(next(iter(dataloader))[0][0][0], cmap=plt.cm.gray)
plt.savefig(f'img/image-{epoch}.png', dpi=300)
# plt.show()
# 训练结束,跳出循环,检验成果
end = time.perf_counter() # 结束时间
total = end - start
minutes = total // 60
seconds = total - minutes * 60
print("利用GPU总用时:{:.2f}分钟{:.2f}秒".format(minutes, seconds))
logger.info("利用GPU总用时:{:.2f}分钟{:.2f}秒".format(minutes, seconds))
三、实验记录
实验中共记录了四个参数的变化:d_loss、g_loss、D(x)、D(G(z))。
损失函数的分析
通过对完整数据的分析,我发现d_loss和g_loss,也就是判别器的损失函数和生成器的损失函数,是在不断波动的。这个结果与GAN生成对抗网络的特性是对应的,因为在GAN的训练过程中,判别器和生成器是交替训练的,它们的损失函数相互影响。判别器的目标是最小化d_loss,而生成器的目标是最小化g_loss。这是一个动态的博弈的过程,最终可以达到一个均衡,此时不管时d_loss还是g_loss的梯度都非常小了,无法继续进化。
图片score分析
在这个过程中,还有两个重要的参数——D(x)和 D(G(z)),分别代表判别器对真实样本的输出和对生成样本的输出,为了更直观的感受它们的变化,我将结果通过plt显示出来,如下图
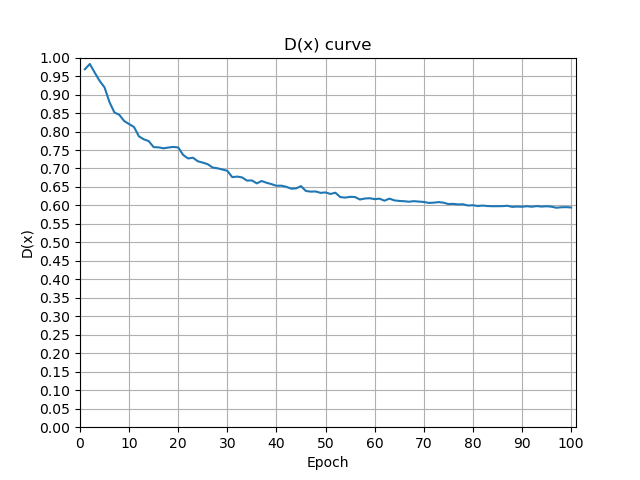
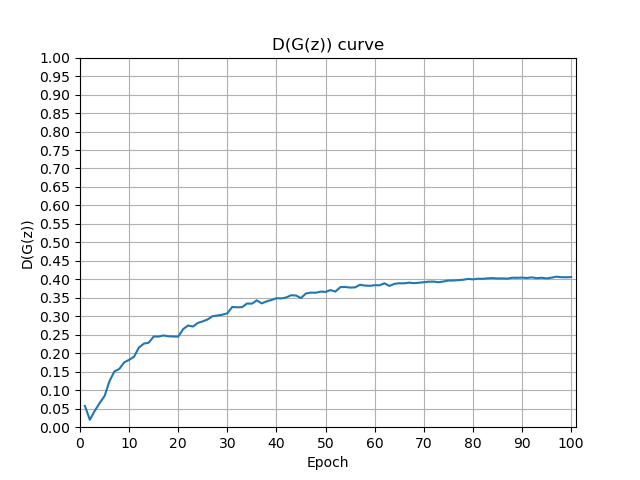
初始化时,real_label赋值为1,fake_label为0。实验结果表明,在哦100次Epoch中,D(x)随着训练过程逐渐减小,并最终稳定在0.6左右;D(G(z))随着训练过程逐渐增大并最终稳定在0.4左右。这与预期相符。
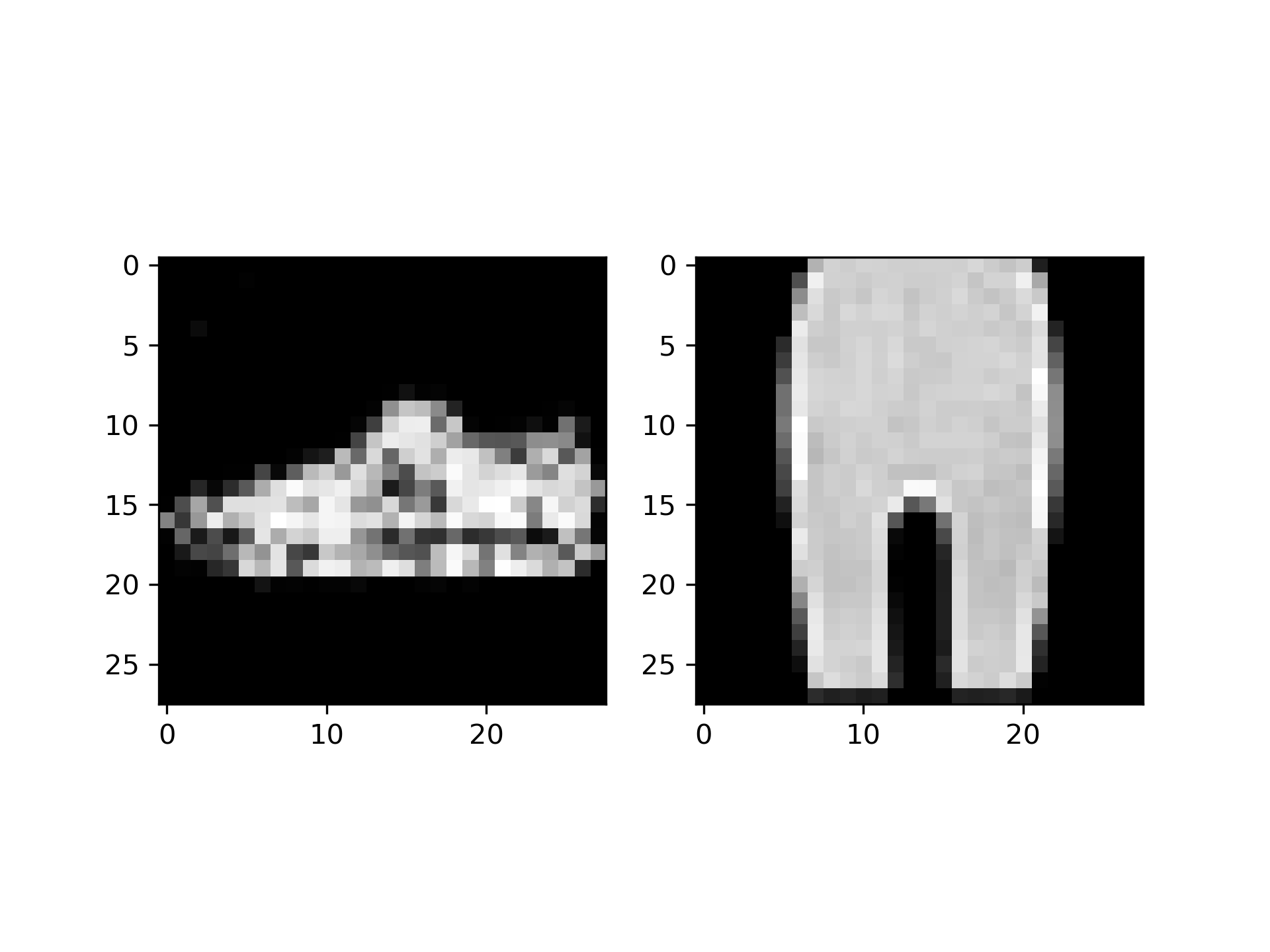
上图是训练60个Epoch后模型输出(左)与原数据集中的一张图片(右)对比
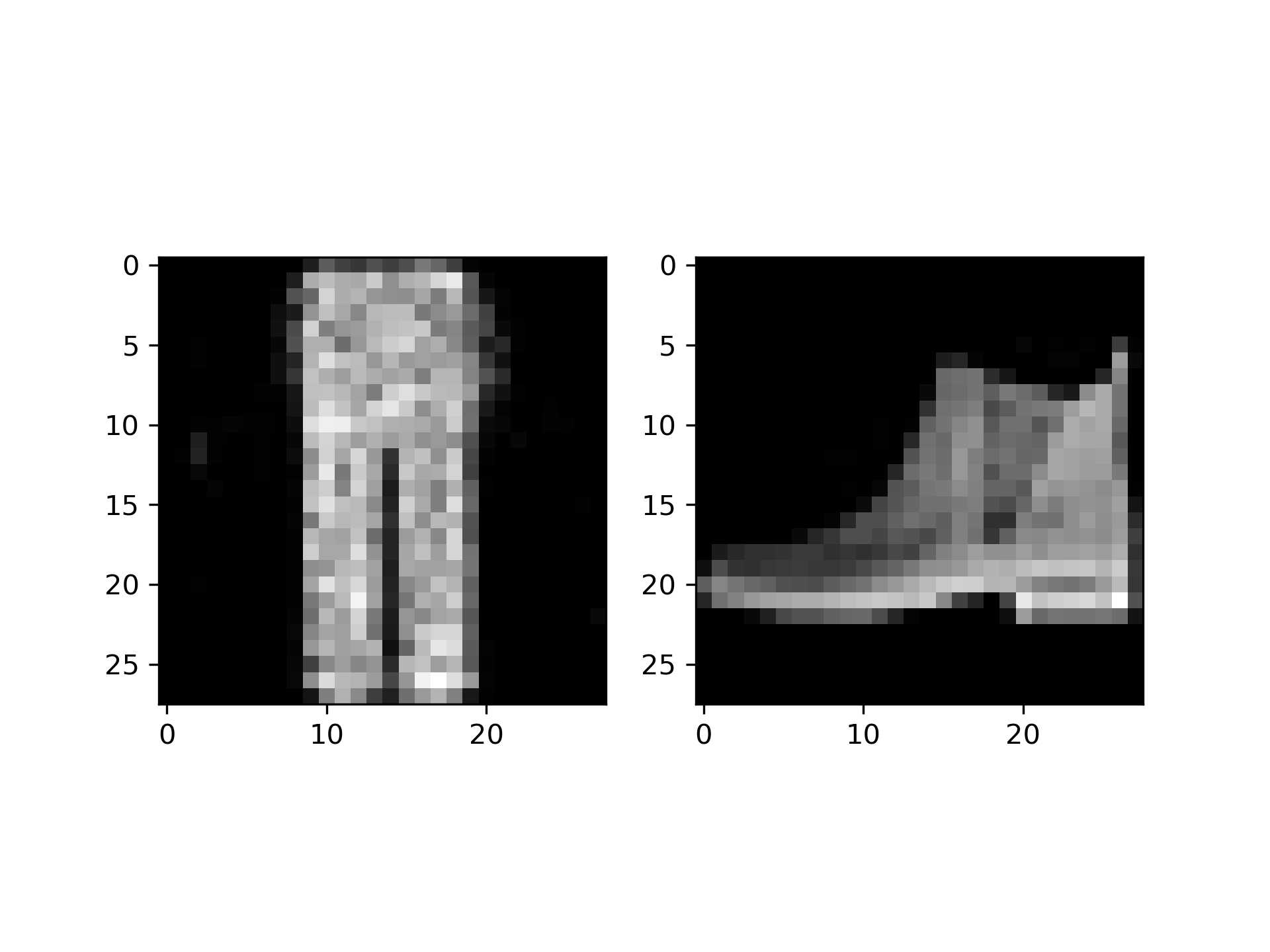
上图是100次训练后模型的输出(左)与原数据集的一张图片(右)对比,可以看出生成的是一条裤子,主观上看还是和原数据集有一定差距。经过分析,我认为这可能是由于训练次数过少导致的,也可能是网络结构比较简单的原因。
四、总结
本次实验我实现了简单的GAN网络模型,了解到了生成对抗网络的基本原理,并且对GAN的特性有了初步的认知。如果有时间,我会研究一下其他的生成网络,如WGAN、DCGAN等。















 8708
8708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









