







今天在csdn刷blink的时候,刷到一个冒泡排序的吐槽,看了看评论区,发现不少人分不清选择排序和冒泡排序,笔者想了一下,发现这两个排序确实相似度蛮高的,所以总结了c语言里涉及到六个排序算法,笔者才疏学浅,没有写到什么时间复杂度,空间复杂度之类的比较,只是在代码的角度进行区分,希望各位师傅不吝赐教。
冒泡排序
一次比较两个元素,不管是从大到小,还是从小到大,亦或是首字母从A到Z,按照规定的顺序进行比较,不符合便执行操作。对于冒泡排序,我们最起码应该有个数组,用来储存我们的数据,然后根据要求进行排序。
比如我们从小到大的排几个数,首先先输入这几个数:
int shuzu[] = { 20, 34, 1, 31, 30 };//我们输入了5个数
然后我们想,从小到大排序,我们就把第一个数跟第二个数比较,然后具体操作看下图:
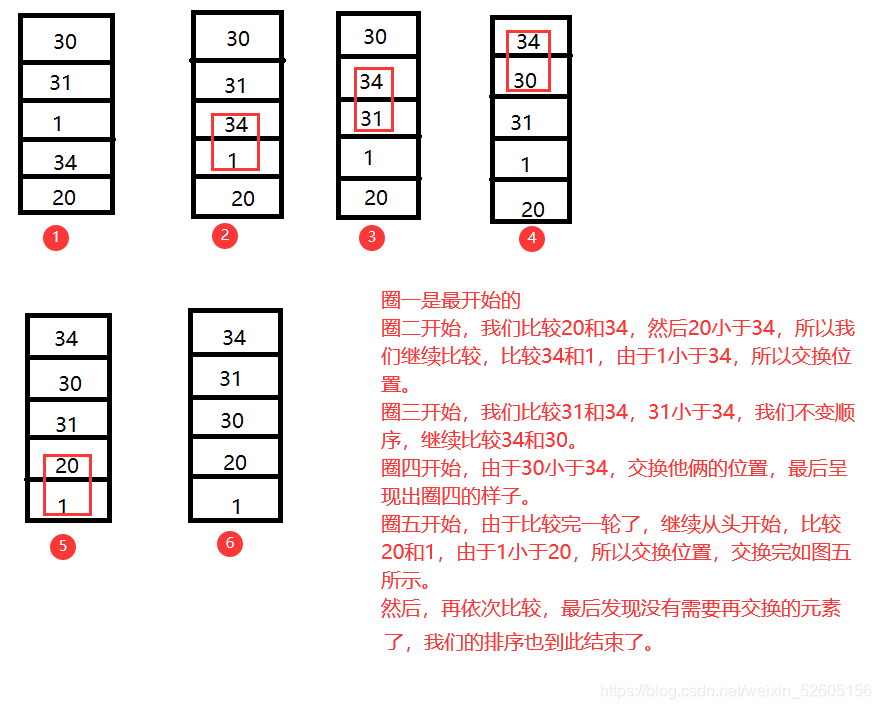
我们上面写了,起码有个数组,那么这时有了数组,就要考虑数组的范围,也就是临界在哪里,所以我们去求数组的边界:
int len = (int) sizeof(shuzu) / sizeof(*shuzu);
/*这里我们定义边界的值为len,也就是求出元素的个数,然后sizeof()是预定义的函数,编译器知道是统计字节的个数,然后(*shuzu)就是这个数组的元素的所占的地址。*/
/*数组元素总的字节数除以int型字节数就等于元素个数,然后前面的(int)是对我们的结果进行强制整型转换,这样我们就求出了数组里元素的个数。*/
然后我们把排序算法整入到一个函数里:
Bubble_sort(shuzu, len);//定义冒泡排序的函数,我们需要传入数组和我们上面求出的数组边界。
冒泡排序的函数:
void Bubble_sort(int shuzu[], int len)
{
int i, j, temp;
for (i = 0; i < len - 1; i++)
for (j = 0; j < len - 1 - i; j++)
if (shuzu[j] > shuzu[j + 1])//如果前面的数大于后面的数,就交换两者的位置。
{
temp = shuzu[j];
shuzu[j] = shuzu[j + 1];
shuzu[j + 1] = temp;
}
}
上面的代码里,可能大家对这两行代码有疑惑:
for (i = 0; i < len - 1; i++)
for (j = 0; j < len - 1 - i; j++)
首先我们想一个排序中,我们从第一个元素开始,一个个比较,然后比较完一轮又比较一轮,那么一共比较多少轮呢?也就是len -1轮,就好比本题有5个元素,我们每比较完一次,一定可以找出本轮排序里最大的那个数,那么我们4轮比较后,也就是等于找出来4个排好的数,剩下的第5个数是最小的元素,所以是len -1。
然后,我们发现在每一轮的比较时,比如第一轮比较,我们的5个数毫无顺序,那么我们两两比较,经过4轮,我们就找到了本轮比较最大的那个数,下一轮,由于知道了上一轮最大的数,我们只需要对4个数两两比较,也就是比较3次,所以可得len -1 -i。
最后整合到一起:
#include <stdio.h>
void Bubble_sort(int shuzu[], int len)
{
int i, j, temp;
for (i = 0; i < len - 1; i++)
for (j = 0; j < len - 1 - i; j++)
if (shuzu[j] > shuzu[j + 1])
{
temp = shuzu[j];
shuzu[j] = shuzu[j + 1];
shuzu[j + 1] = temp;
}
}
int main()
{
int shuzu[] = { 20, 34, 1, 31, 30 };
int len = (int) sizeof(shuzu) / sizeof(*shuzu);
Bubble_sort(shuzu, len);
int i;
for (i = 0; i < len; i++)
printf("%d ", shuzu[i]);
return 0;
}

选择排序
相比较于冒泡排序,选择排序就是我们在一堆杂乱的数据里,如果你是从小到大排序,我们先找出一个最小的数,放到最前面,然后继续找,再找出第二个小的数放在仅此于最小的数的后面,以此类推。我们上面的冒泡排序也是由小到大,但是你每次找到的是最大的数,然后从后往前走,而我们的选择排序是先找出最小的数,由前往后走。
我们的主函数和冒泡排序其实是一样的,差别不大:
int shuzu[] = { 5, 20, 1, 3, 14 };//往数组里面存入数据
int len = (int) sizeof(shuzu) / sizeof(*shuzu);//同冒泡排序
然后整个函数:
selection_sort(shuzu, len);
然后来看看这个函数怎么写:
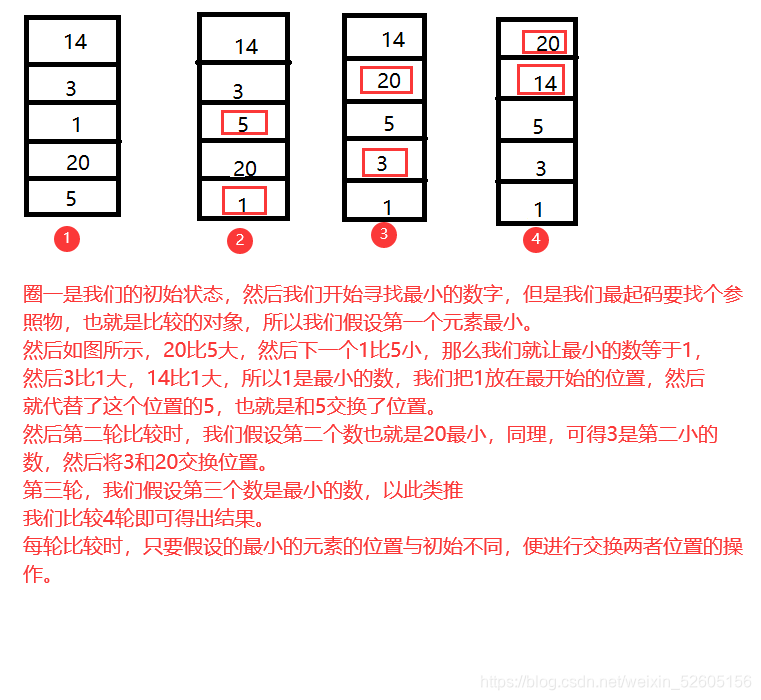
代码也就是这样的:
void selection_sort(int shuzu[], int len)
{
int i,j,temp;
for (i = 0 ; i < len - 1 ; i++) //总的循环次数为 len -1
{
int min = i; // 我们把本次循环的第一个元素设置为最小值
for (j = i + 1; j < len; j++) // 依次去访问没有排序的元素,直到最后一个数字
{
if (shuzu[j] < shuzu[min]) // 找到本次循环的目前的最小值
{
min = j; // 记录最小值
}
}
if(min != i) //只有当最小值的位置发生变化后,我们再进行比较操作
{
temp=shuzu[min]; // 交换两个变量
shuzu[min]=shuzu[i];
shuzu[i]=temp;
}
}
}
代码合并到一起:
#include<stdio.h>
void selection_sort(int shuzu[], int len)
{
int i,j,temp;
for (i = 0 ; i < len - 1 ; i++) //总的循环次数为 len -1
{
int min = i; // 我们把本次循环的第一个元素设置为最小值
for (j = i + 1; j < len; j++) // 依次去访问没有排序的元素,直到最后一个数字
{
if (shuzu[j] < shuzu[min]) // 找到本次循环的目前的最小值
{
min = j; // 记录最小值
}
}
if(min != i) //只有当最小值的位置发生变化后,我们再进行比较操作
{
temp=shuzu[min]; // 交换两个变量
shuzu[min]=shuzu[i];
shuzu[i]=temp;
}
}
}
int main()
{
int shuzu[] = { 5, 20, 1, 3, 14 };
int len = (int) sizeof(shuzu) / sizeof(*shuzu);
selection_sort(shuzu, len);
int i;
for (i = 0; i < len; i++)
printf("%d ", shuzu[i]);
return 0;
}
运行结果:

插入排序
采用插入的方式,对我们要排序的无序数列进行排序,将数据一个一个的插入到有序区的正确位置,直到整个数组都有序。
我们看一下图解(百度上找了张图,我自己的作图感太离谱了~),比如我们从小到大进行排序:
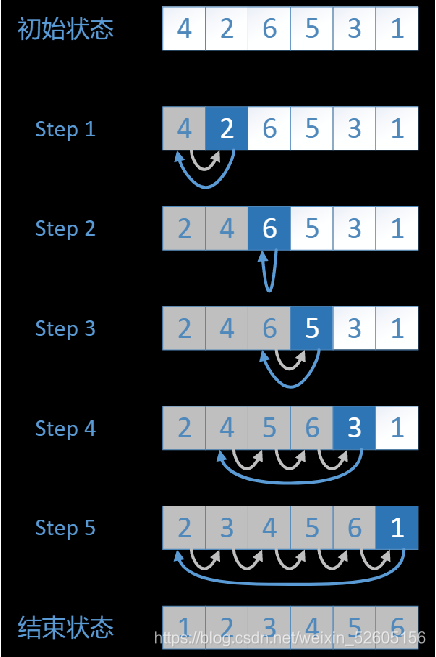
其实所谓的插入排序其实就好比分开一波一波的进行排序,我们看初始状态的时候,是4,2,6,5,3,1。然后啊,我们把4分为第一波,然后从后面进行比较,下一个数是2,2比4小,所以2移到4前面,我们这时把2和4看作是新的一组数据。
然后第二次,6比4大,我们就不动了,这时候把2,4,6看作一组新的数据。
第三次,5是不是比6小?所以我们把5移到6前面,然后5比4大,我们就不再移动数字5了,这时2,4,5,6是新的一波数据。
第四次,3是不是6小?然后我们往前面移动,3也比5小,继续移动,直到3比2大,我们就结束了本次比较。
第五次,数字1,依次一次次和前面的数比较,直到得出结果。
最后,本次插入排序也就到此结束了。
然后我们想一想代码怎么写?
主函数,和上面的冒泡排序还有选择排序一模一样:
int shuzu[] = { 4, 2, 6, 5, 3 ,1 };
int len = (int) sizeof(shuzu) / sizeof(*shuzu);
我们同理再定义一个我们的插入排序的函数:
insertion_sort(shuzu, len);
所以主函数就很容易写出来了:
int main()
{
int shuzu[] = { 4, 2, 6, 5, 3 ,1 };
int len = (int) sizeof(shuzu) / sizeof(*shuzu);
insertion_sort(shuzu, len);
int i;
for (i = 0; i < len; i++)
printf("%d ", shuzu[i]);
return 0;
}
然后是我们定义的插入函数:
void insertion_sort(int shuzu[], int len)
{
int i,j,temp;
for (i=1;i<len;i++)
{
temp = shuzu[i];
//我们的数组第一个元素是shuzu[0],这里我们是把shuzu[1]作为比较的变量
for (j=i;j>0 && shuzu[j-1]>temp;j--)
//我们是不是从后面往前移动?所以是j--,我们用这个temp之前的数和temp比较,如果比temp大,执行下面操作
shuzu[j] = shuzu[j-1];
//我们让 shuzu[j] = shuzu[j-1]; 也就是前面的数如果大于后面的数,就交换两者的位置
shuzu[j] = temp;
//我们上面有一个:temp = shuzu[i]; 所以也就是提前进行了备份数据,这样我们就可以将shuzu[j]的值赋回去(注意两个for循环的条件,就可以明白这里),进行下一次比较。
}
}
合并:
#include<stdio.h>
void insertion_sort(int shuzu[], int len)
{
int i,j,temp;
for (i=1;i<len;i++)
{
temp = shuzu[i];
for (j=i;j>0 && shuzu[j-1]>temp;j--)
shuzu[j] = shuzu[j-1];
shuzu[j] = temp;
}
}
int main()
{
int shuzu[] = { 4, 2, 6, 5, 3 ,1 };
int len = (int) sizeof(shuzu) / sizeof(*shuzu);
insertion_sort(shuzu, len);
int i;
for (i = 0; i < len; i++)
printf("%d ", shuzu[i]);
return 0;
}
运行结果:

希尔排序
学之前先看一个视频:https://www.bilibili.com/video/BV1xW411Y7gf,注意看,看完后你可能悟了,也可能已经懵了,其实当你学完后会发现这个视频是很形象的,下面我们来看一下希尔排序,希尔排序我们先记住一点:希尔排序的最后是插入排序,就是说最后要走一遍插入排序。
那么什么是希尔排序?
我们看下图便可知(作图不易,请多鼓励),其实就是对插入排序进行了升级改造,我不再傻乎乎的去一个一个的比较,我先一组组的分好,在组内比较完,再重新分组,再次排序,就这样一次次的进行下去,大大简化了我们的计算机运行时的步骤。

那么我们再把上面的图化作代码:
主函数还是和冒泡啊,选择排序它们是一样的:
int main()
{
int shuzu[] = { 2, 5, 6, 7, 1 , 9 , 3, 8 , 4 };
int len = (int) sizeof(shuzu) / sizeof(*shuzu);
shell_sort(shuzu, len);
int i;
for (i = 0; i < len; i++)
printf("%d ", shuzu[i]);
return 0;
}
然后我们看定义的函数怎么写,我们这么想,每次循环使用的都是插入排序的方法,那么就简单了,我们的插入排序是不是间隔为1的时候?那我们先写一个插入排序
void shell_sort(int shuzu[],int len)
{
int i,j,temp;
for( i=1; i<len; i++)
{
if(shuzu[i]<shuzu[i-1])
{
temp=shuzu[i];
for(j=i-1; shuzu[j]>temp; j--)
{
shuzu[j+1]=shuzu[j];
}
shuzu[j+1]=temp;
}
}
}
然后我们想,我们的希尔排序是每次的间隔都是不一样的,那么我们怎么修改这个已知的程序呢?
void shell_sort(int shuzu[],int len)
{
int i,j,temp,gap;
//temp作为临时插入时保存的变量,gap是间隔
//初始增量为 len/2,每一次除以 2
for(gap = len / 2 ; gap > 0; gap /=2)
{
for(i = gap; i < len; i++)//我们使用插入排序
{
temp=shuzu[i];
for(j = i; j>=gap && temp < shuzu[j-gap]; j-=gap)
//temp比下一个元素小,我们才往前面插入
shuzu[j] = shuzu[j-gap];//把前面的元素往后面移动
shuzu[j] = temp;
//我们的每次循环是处理了多组排序,就是笔者的演示图里,颜色相同的分组进行了各自排序
//我们不是一次性把一组都排序完 ,我们是对每一组都进行了插入排序
}
}
}
所以可以得到:
#include<stdio.h>
void shell_sort(int shuzu[],int len)
{
int i,j,temp,gap;
for(gap = len / 2 ; gap > 0; gap /=2)
{
for(i = gap; i < len; i++)
{
temp=shuzu[i];
for(j = i; j>=gap && temp < shuzu[j-gap]; j-=gap)
shuzu[j] = shuzu[j-gap];
shuzu[j] = temp;
}
}
}
int main()
{
int shuzu[] = { 2, 5, 6, 7, 1 , 9 , 3, 8 , 4 };
int len = (int) sizeof(shuzu) / sizeof(*shuzu);
shell_sort(shuzu, len);
int i;
for (i = 0; i < len; i++)
printf("%d ", shuzu[i]);
return 0;
}
快速排序
我们的快速排序,就是通过一趟排序将要排序的数据分割成独立的两部分,
其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,那么我们怎么保证能分成这样的两部分呢?
我们可以定义一个分界值,大于这个值的数放到一起,小于这个值的数放到一起,然后我们可以在小于这个值的那堆数里面再找一个分界值,以此类推,我们左右两边都能通过类似于递归的传递进行排序,就这样达到排序的目的。
我知道你没看懂上面写的啥,所以我们引入图片的概念进行理解:

我们需要注意的是,b应该先走,a后走
我们转换为代码,首先跟上面几种排序一样,我们的主函数没有很大的区别,这里笔者的做法是把数组没有放到主函数里
int main()
{
quick_sort(1,10);
int i;
for( i=1; i<=10; i++)
{
printf("%d ",shuzu[i]);
}
return 0;
}
然后我们调用的函数:
void quick_sort(int l, int r)//l代表左边,r代表右边
{
if(l>r) //当我们的左边大于右边时,结束递归调用
return;
int i=l,j=r,temp=shuzu[l]; //temp存入第一个数
int t; //中间变量
while(i!=j)//i=j的时候两者就相遇了
{
while(shuzu[j]>=temp&&i<j)
j--; //后面的数大于临界值
while(shuzu[i]<=temp&&i<j)
i++; //前面的数小于临界值
if(i<j)//找到这两个位置后,让这两个位置交换
{
t=shuzu[i];
shuzu[i]=shuzu[j];
shuzu[j]=t;
}
}
//相遇后,指向同一个元素,让这个基准值进行交换,我们的分界值存到temp里面了
shuzu[l]=shuzu[i];
shuzu[i]=temp;//一开始的分界值给a[i]
//左右两个部分分别进行排序
quick_sort(l,i-1);//递归调用
quick_sort(i+1,r);//递归调用
}
合并一下:
#include<stdio.h>
#define max 11
int shuzu[max]= {0,6,1,2,7,9,3,4,5,8};
void quick_sort(int l, int r)
{
if(l>r)
return;
int i=l,j=r,temp=shuzu[l];
int t;
while(i!=j)
{
while(shuzu[j]>=temp&&i<j)
j--;
while(shuzu[i]<=temp&&i<j)
i++;
if(i<j)
{
t=shuzu[i];
shuzu[i]=shuzu[j];
shuzu[j]=t;
}
}
shuzu[l]=shuzu[i];
shuzu[i]=temp;
quick_sort(l,i-1);
quick_sort(i+1,r);
}
int main()
{
quick_sort(1,10);
int i;
for( i=1; i<=10; i++)
{
printf("%d ",shuzu[i]);
}
return 0;
}
运行结果

归并排序
先分开,再合并,用空间,换时间。
在菜鸟教程上找到了一张图,感觉解释的十分明白:
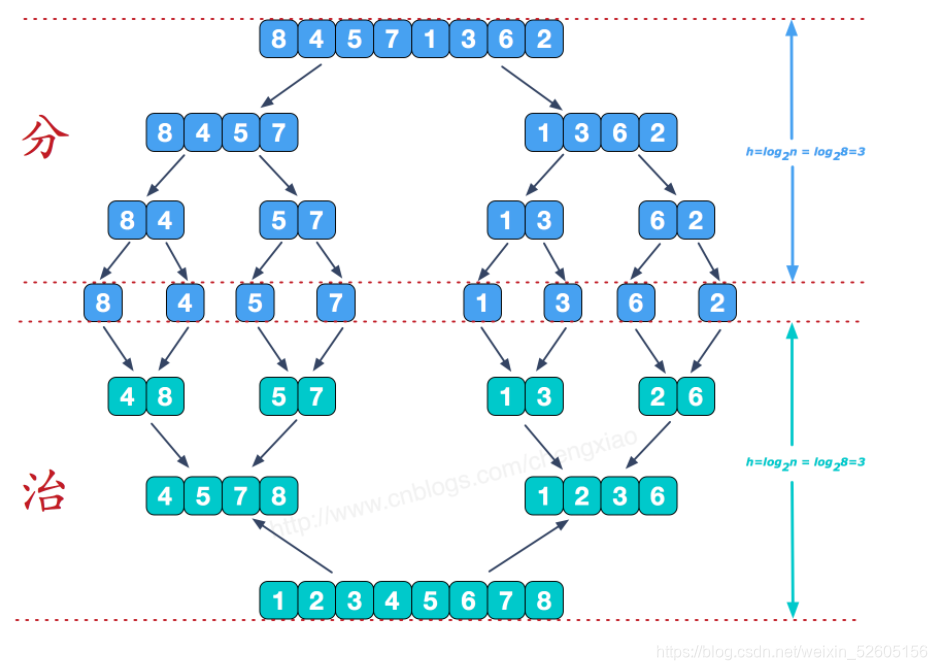
分开的时候好分,我们看一下合并的时候是怎么合的:
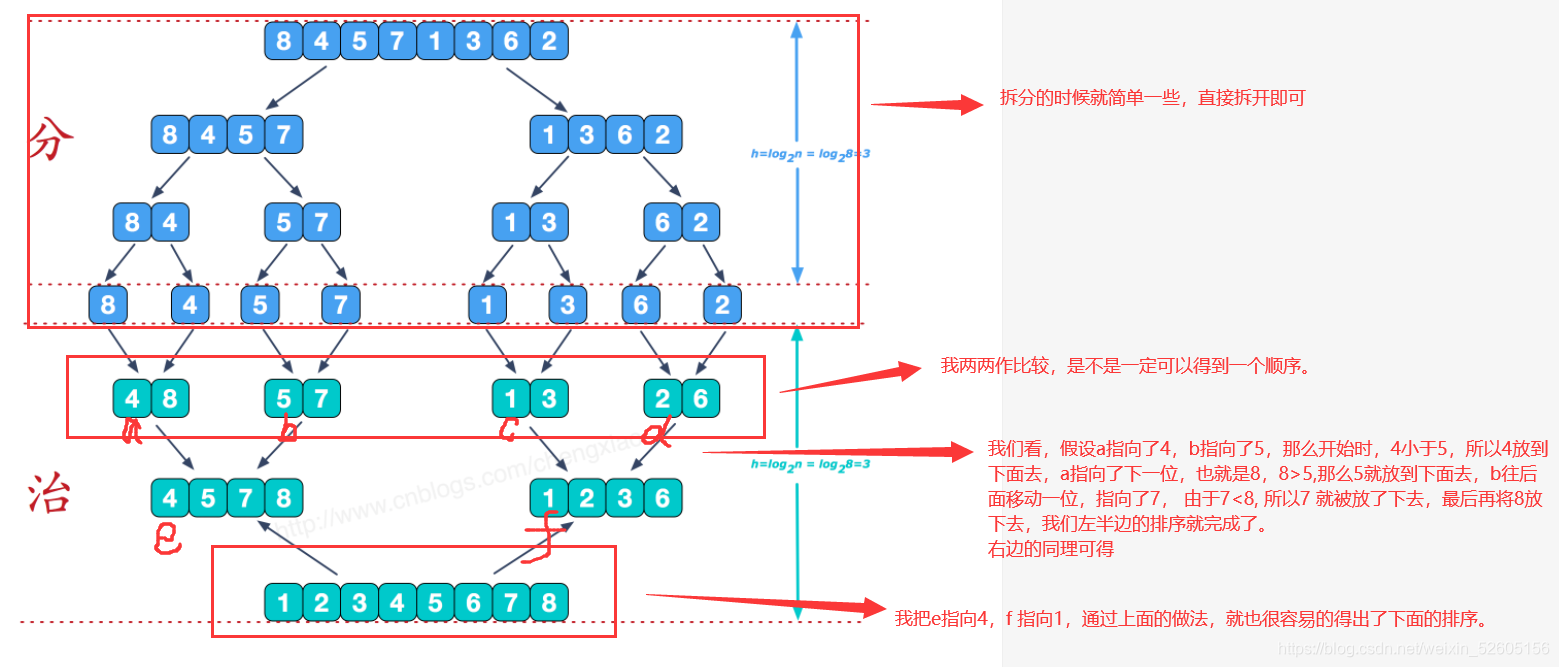
道理很简单,我们看一下代码怎么整:
先想主函数,这里主函数差别也不是很大,唯有在给我们定义的归并排序函数传参时有点差异,我们一会再说定义的部分:
int main()
{
int shuzu[] = { 2, 5, 6, 7, 1 , 9 , 3, 8 , 4, 0};
int len = (int) sizeof(shuzu) / sizeof(*shuzu);
merge_sort(shuzu, 0, len);
int i;
for (i = 0; i < len; i++)
{
printf("%d ", shuzu[i]);
}
return 0;
}
然后是定义的函数部分,先看拆的部分,比较简单:
void merge_sort(int shuzu[], int begin, int over)
//我们的begin是待排序数组开始的下标
//over是待排序数组结束时的下标
{
if(begin<over)
{
int middle;
middle=(begin + over)/2;// 万物归一,我先在中间劈开
//下面就是递归调用,继续劈下去,直到不满足if里的条件
merge_sort(shuzu, begin, middle);
merge_sort(shuzu, middle +1, over);
//然后上面的是分,下面的函数是合
merge(shuzu, begin, middle, over);
}
else
{
return;
}
}
合的部分,笔者最开始是左右分别设置了一个数组去承接,然后整两个指针,双数组循环序列,后来写了半天没有写出来(emmm…我是小菜鸟),所以上网找了好多版本,个人感觉写的最好的是这位大佬的:https://blog.csdn.net/assiduous_me/article/details/89414914
这里笔者为这段代码做注释:
void merge(int shuzu[], int begin, int middle, int over)
{
int temp[max];//临时存放数据
int a =0;
int i=begin;
int j=middle + 1;//左右分开
while(i<=middle && j<=over) //当i和j都在要合并的部分中成立的时候
{
if(shuzu[i]<shuzu[j])//那个小,那个就放到下面去
{
temp[a++]=shuzu[i++];
}
else
{
temp[a++]=shuzu[j++];
}
}
if(i==middle +1)//左边那个移动到头了
{
while(j<=over)//没超出范围的话 ,把数据放下来
{
temp[a++]=shuzu[j++];
}
}
if(j==over +1)//右边那个移动到头的话
{
while(i<=middle)
{
temp[a++]=shuzu[i++];//同理可知
}
}
for(j=0,i=begin; j<a; i++,j++)//把排序好的数组存回去
{
shuzu[i]=temp[j];
}
}
合并到一起:
#include<stdio.h>
#define max 20
void merge_sort(int shuzu[], int begin, int over)
{
if(begin<over)
{
int middle;
middle=(begin + over)/2;
merge_sort(shuzu, begin, middle);
merge_sort(shuzu, middle +1, over);
merge(shuzu, begin, middle, over);
}
else
{
return;
}
}
void merge(int shuzu[], int begin, int middle, int over)
{
int temp[max];
int a =0;
int i=begin;
int j=middle + 1;
while(i<=middle && j<=over)
{
if(shuzu[i]<shuzu[j])
{
temp[a++]=shuzu[i++];
}
else
{
temp[a++]=shuzu[j++];
}
}
if(i==middle +1)
{
while(j<=over)
{
temp[a++]=shuzu[j++];
}
}
if(j==over +1)
{
while(i<=middle)
{
temp[a++]=shuzu[i++];
}
}
for(j=0,i=begin; j<a; i++,j++)
{
shuzu[i]=temp[j];
}
}
int main()
{
int shuzu[] = { 2, 5, 6, 7, 1 , 9 , 3, 8 , 4, 0};
int len = (int) sizeof(shuzu) / sizeof(*shuzu);
merge_sort(shuzu, 0, len);
int i;
for (i = 0; i < len; i++)
{
printf("%d ", shuzu[i]);
}
return 0;
}
运行结果:
常见的排序算法有十个,剩下的堆排序,计数排序,桶排序,基数排序,笔者之后再补充哈~~~ 笔者也没得过什么蓝桥杯,ACM的奖,所以对于打比赛的大佬而言,这些算法可能太简单了,博主尽力写的详细一些,希望能让没学过这些东西的小白有所收获,当然笔者也是小白一个… …
如果代码有误或者文中哪里出现了不严谨的地方,请大家在评论区留言,方便笔者及时改正。

“ 谁知道那些ACM的大佬都是怎么学的啊,我还是当个凡人吧。。。”















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











