






Oracle和MySQL语法区别
一、数据类型
1. Number类型
MySQL中是没有Number类型的,但有int/decimal 类型,Oracle中的Number(5,1)对应MySQL中的decimal(5,1),Number(5) 对应 int(5)。MySQL中的数字型类型比较多,分的也比较细,还有tinyint、smallint、mediumint、bigint等类型
2. Varchar2(n)类型
MySQL中对应Oracle Varchar2(n)类型的替代类型是varchar(n)类型。
3. Date 类型
MySQL 中的日期时间类型有Date、Time、Datetime等类型,MySQL中Date类型仅表示日期(年-月-日),Time类型仅表示时间(时:分:秒),而Datetime类
sysdate:返回当前日期+时间; MySQL对应的函数为 now();
三、其他
1. 引号
MySQL可识别双引号和单引号,Oracle只能识别单引号。
2. 字符串连接符 ||
Oracle 可用'||'来连接字符串,但MySQL不支持'||'连接,MySQL可通过concat()函数链接字符串。
Oracle的 a.studentname||'【'||a.studentno||'】' 相当于 MySQL的 concat(a.studentname, '【', a.studentno, '】')
3. ROWNUM
Oracle可通过rownum获取前n条记录,MySQL通过limit来获取前n条记录,但二者的写法略有不同,在Oracle中rownum作为where条件的一部分,而MySQL中limit不是where条件的一部分。
5. 表(左/右)关联(+)
Oracle左连接,右连接可以使用(+)来实现. MySQL只能使用left join ,right join等关键字。
Oracle 中可用with来构建一个临时表,但MySQL不支持with,对应临时表,MySQL可通过小括号的方式来处理,但构建的临时表必须设置临时表名。
4. 条件函数(nvl()、nvl2()、decode())
nvl(tab.columnName, 0):如果tab.columnName值为空,则返回值取0,否则取tab.clumnName;对应的MySQL函数为:ifnull(tab.columnName, 0)。
mysql、oracle、sql server做分页
mysql的分页语句:
select * from student limit 页数*页面大小,页面大小
select rownum,t.*from student t where rownum >=(n-1)*10+1 and rownum <=n*10 order by number;
1.如果根据number排序则rownum会混乱
(解决方案:分开使用->先只排序,再只查询rownum)
2.rownum不能查询>的数据
sQLServer此种分页sql与oralce分页sql的区别:
- rownum ,row_number()
- oracle需要排序(为了排序,单独写了一个子查询),但是在sqlserver 中可以省略该排序的子查询 因为sqlserver中可以通过over直接排序
-
网络编程
-
1.5、通信协议
协议:就是约定。
**网络通信协议:**速率、传输速率、代码结构、传输控制~
TCP/IP协议簇
重要:
- TCP:用户传输协议
- UDP:用户数据报协议
- IP:网络互连协议
.使用数据库连接池好处
但这里还是有必要说一下,数据库连接池的好处:
连接资源重用
系统的响应速度更快
属于一种新的资源分配的手段(以前我们是从数据库服务器直接获取连接实现交互。现在我们只需要从连接池中拿连接,用完了,再放回连接池即可,而不必大费周章的去直接连接数据库)
避免服务器(一言不合就)宕机
Jpa使用

Query(value=" 这里就是查询语句")
@Query支持hql和原生sql两种方式,默认是hql ,hql就是语句中用的是实体名字和实体属性,原生sql用的表名字和表字段,
MyBatis与JPA的区别是什么
仓储
Repository 模式是领域驱动设计中另一个经典的模式。在早期,我们常常将数据访问层命名为:DAO,而在 SpringData JPA 中,其称之为 Repository(仓储),这也不是巧合,而是设计者有意为之。
熟悉 SpringData JPA 的朋友都知道当一个接口继承 JpaRepository 接口之后便自动具备了 一系列常用的数据操作方法,findAll, findOne ,save等。
Mybatis优势
MyBatis可以进行更为细致的SQL优化,可以减少查询字段。
MyBatis容易掌握,而Hibernate门槛较高。
Hibernate优势
Hibernate的DAO层开发比MyBatis简单,Mybatis需要维护SQL和结果映射。
Hibernate对对象的维护和缓存要比MyBatis好,对增删改查的对象的维护要方便。
Hibernate数据库移植性很好,MyBatis的数据库移植性不好,不同的数据库需要写不同SQL。
Hibernate有更好的二级缓存机制,可以使用第三方缓存。MyBatis本身提供的缓存机制不佳
hibernate是全自动,而mybatis是半自动
hibernate完全可以通过对象关系模型实现对数据库的操作,拥有完整的JavaBean对象与数据库的映射结构来自动生成sql。而mybatis仅有基本的字段映射,对象数据以及对象实际关系仍然需要通过手写sql来实现和管理。
hibernate数据库移植性远大于mybatis
hibernate通过它强大的映射结构和hql语言,大大降低了对象与数据库(oracle、mysql等)的耦合性,而mybatis由于需要手写sql,因此与数据库的耦合性直接取决于程序员写sql的方法,如果sql不具通用性而用了很多某数据库特性的sql语句的话,移植性也会随之降低很多,成本很高。
hibernate拥有完整的日志系统,mybatis则欠缺一些
hibernate日志系统非常健全,涉及广泛,包括:sql记录、关系异常、优化警告、缓存提示、脏数据警告等;而mybatis则除了基本记录功能外,功能薄弱很多。
mybatis相比hibernate需要关心很多细节
hibernate配置要比mybatis复杂的多,学习成本也比mybatis高。但也正因为mybatis使用简单,才导致它要比hibernate关心很多技术细节。mybatis由于不用考虑很多细节,开发模式上与传统jdbc区别很小,因此很容易上手并开发项目,但忽略细节会导致项目前期bug较多,因而开发出相对稳定的软件很慢,而开发出软件却很快。hibernate则正好与之相反。但是如果使用hibernate很熟练的话,实际上开发效率丝毫不差于甚至超越mybatis。
sql直接优化上,mybatis要比hibernate方便很多
由于mybatis的sql都是写在xml里,因此优化sql比hibernate方便很多。而hibernate的sql很多都是自动生成的,无法直接维护sql;虽有hql,但功能还是不及sql强大,见到报表等变态需求时,hql也歇菜,也就是说hql是有局限的;hibernate虽然也支持原生sql,但开发模式上却与orm不同,需要转换思维,因此使用上不是非常方便。总之写sql的灵活度上hibernate不及mybatis。
Spring Security 与JWT 实现单点登录。
用户认证:这一环节主要是用户向认证服务器发起认证请求,认证服务器给用户返回一个成功的令牌token,主要在认证服务器中完成,即图中的认证系统,注意认证系统只能有一个。
身份校验: 这一环节是用户携带token去访问其他服务器时,在其他服务器中要对token的真伪进行检验,主要在资源服务器中完成,即图中的应用系统2 3。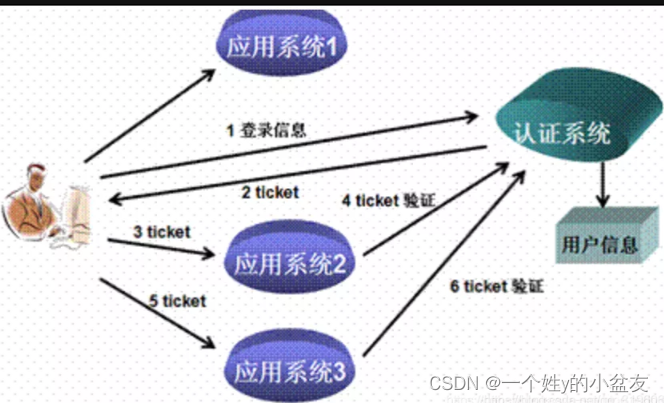
RabbitMq和kafka的区别
实际场景选择
在实际生产应用中,通常会使用kafka作为消息传输的数据管道,rabbitmq作为交易数据作为数据传输管道,主要的取舍因素则是是否存在丢数据的可能;rabbitmq在金融场景中经常使用,具有较高的严谨性,数据丢失的可能性更小,同事具备更高的实时性;而kafka优势主要体现在吞吐量上,虽然可以通过策略实现数据不丢失,但从严谨性角度来讲,大不如rabbitmq;而且由于kafka保证每条消息最少送达一次,有较小的概率会出现数据重复发送的情况;
1.应用场景方面
RabbitMQ:用于实时的,对可靠性要求较高的消息传递上。
kafka:用于处于活跃的流式数据,大数据量的数据处理上。
2.架构模型方面
producer,broker,consumer
RabbitMQ:以broker为中心,有消息的确认机制
kafka:以consumer为中心,无消息的确认机制
3.吞吐量方面
RabbitMQ:支持消息的可靠的传递,支持事务,不支持批量操作,基于存储的可靠性的要求存储可以采用内存或硬盘,吞吐量小。
kafka:内部采用消息的批量处理,数据的存储和获取是本地磁盘顺序批量操作,消息处理的效率高,吞吐量高。
4.集群负载均衡方面
RabbitMQ:本身不支持负载均衡,需要loadbalancer的支持
kafka:采用zookeeper对集群中的broker,consumer进行管理,可以注册topic到zookeeper上,通过zookeeper的协调机制,producer保存对应的topic的broker信息,可以随机或者轮询发送到broker上,producer可以基于语义指定分片,消息发送到broker的某个分片上。
1.RabbitMQ的消息应当尽可能的小,并且只用来处理实时且要高可靠性的消息。
2.消费者和生产者的能力尽量对等,否则消息堆积会严重影响RabbitMQ的性能。
3.集群部署,使用热备,保证消息的可靠性。
1.应当有一个非常好的运维监控系统,不单单要监控Kafka本身,还要监控Zookeeper。(kafka强烈的依赖于zookeeper,如果zookeeper挂掉了,那么Kafka也不行了)
2.对消息顺序不依赖,且不是那么实时的系统。
3.对消息丢失并不那么敏感的系统。
4.从 A 到 B 的流传输,无需复杂的路由,最大吞吐量可达每秒 100k 以上。
Spring cloud 的微服务知识
SpringCloud五大核心组件:
服务注册发现-Netflix Eureka
配置中心 - spring cloud config
负载均衡-Netflix Ribbon
断路器 - Netflix Hystrix
路由(网关) - Netflix Zuul
1.5 什么是服务熔断?什么是服务降级?
熔断机制是应对雪崩效应的一种微服务链路保护机制。当扇出链路的某个微服务不可用或者响应时间太长时,会进行服务降级,进而熔断该节点微服务的调用,快速返回“错误”的响应信息。当检测到该节点微服务调用响应正常后恢复调用链路。
在SpringCloud框架里熔断机制通过Hystrix实现,Hystrix会监控微服务间调用的状况,当失败的调用到一定阈值,缺省是5秒内调用20次,如果失败,就会启动熔断机制。熔断机制的注解是@HystrixCommand。
服务降级,一般是从整体负荷考虑。就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的fallback回调,返回一个缺省值。这样做,虽然水平下降,但好歹可用,比直接挂掉强。
1.6 微服务的优缺点分别是什么?说一下你在项目开发中遇到的坑?
优点:
松耦合,聚焦单一业务功能,无关开发语言,团队规模降低。在开发中,不需要了解多有业务,
只专注于当前功能,便利集中,功能小而精。微服务一个功能受损,对其他功能影响并不是太大,可以快速定位问题。
微服务只专注于当前业务逻辑代码,不会和 html、css 或其他界面进行混合。可以灵活搭配技术,独立性比较舒服。
缺点:
随着服务数量增加,管理复杂,部署复杂,服务器需要增多,服务通信和调用压力增大,运维工程师压力增大,
人力资源增多,系统依赖增强,数据一致性,性能监控。
1.7 你所知道的服务器技术栈有哪些?请列举一二?
服务开发 SpringBoot、Spring、SpringMVC
服务注册与发现 Eureka、Consul、Zookeeper等
服务熔断器 Hystrix、Envoy等
负载均衡 Ribbon、Nginx等
服务部署 Docker、OpenStack、Kubernetes等
1.8 eureka和zookeeper都可以提供服务注册与发现的功能,请说说这两个之间的区别?
Zookeeper保证了CP(C:一致性,P:分区容错性),Eureka保证了AP(A:高可用)
Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像Zookeeper那样使整个微服务瘫痪。
Sentinel 的基本概念
Sentinel 的基本概念有两个,它们分别是:资源和规则。
| 基本概念 | 描述 |
|---|---|
| 资源 | 资源是 Sentinel 的关键概念。它可以是 Java 应用程序中的任何内容,例如由应用程序提供的服务或者是服务里的方法,甚至可以是一段代码。 我们可以通过 Sentinel 提供的 API 来定义一个资源,使其能够被 Sentinel 保护起来。通常情况下,我们可以使用方法名、URL 甚至是服务名来作为资源名来描述某个资源。 |
| 规则 | 围绕资源而设定的规则。Sentinel 支持流量控制、熔断降级、系统保护、来源访问控制和热点参数等多种规则,所有这些规则都可以动态实时调整。 |
@SentinelResource 注解
Eureka 两大组件
Eureka 采用 CS(Client/Server,客户端/服务器) 架构,它包括以下两大组件:
- Eureka Server:Eureka 服务注册中心,主要用于提供服务注册功能。当微服务启动时,会将自己的服务注册到 Eureka Server。Eureka Server 维护了一个可用服务列表,存储了所有注册到 Eureka Server 的可用服务的信息,这些可用服务可以在 Eureka Server 的管理界面中直观看到。
- Eureka Client:Eureka 客户端,通常指的是微服务系统中各个微服务,主要用于和 Eureka Server 进行交互。在微服务应用启动后,Eureka Client 会向 Eureka Server 发送心跳(默认周期为 30 秒)。若 Eureka Server 在多个心跳周期内没有接收到某个 Eureka Client 的心跳,Eureka Server 将它从可用服务列表中移除(默认 90 秒)。
注:“心跳”指的是一段定时发送的自定义信息,让对方知道自己“存活”,以确保连接的有效性。大部分 CS 架构的应用程序都采用了心跳机制,服务端和客户端都可以发心跳。通常情况下是客户端向服务器端发送心跳包,服务端用于判断客户端是否在线。
Eureka 服务注册与发现
Eureka 实现服务注册与发现的原理,如下图所示。
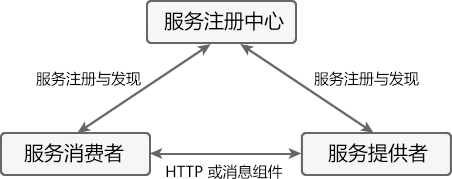
图1:Eureka 原理图
上图中共涉及到以下 3 个角色:
- 服务注册中心(Register Service):它是一个 Eureka Server,用于提供服务注册和发现功能。
- 服务提供者(Provider Service):它是一个 Eureka Client,用于提供服务。它将自己提供的服务注册到服务注册中心,以供服务消费者发现。
- 服务消费者(Consumer Service):它是一个 Eureka Client,用于消费服务。它可以从服务注册中心获取服务列表,调用所需的服务。
Spring Cloud Gateway 工作流程说明如下:
- 客户端将请求发送到 Spring Cloud Gateway 上。
- Spring Cloud Gateway 通过 Gateway Handler Mapping 找到与请求相匹配的路由,将其发送给 Gateway Web Handler。
- Gateway Web Handler 通过指定的过滤器链(Filter Chain),将请求转发到实际的服务节点中,执行业务逻辑返回响应结果。
- 过滤器之间用虚线分开是因为过滤器可能会在转发请求之前(pre)或之后(post)执行业务逻辑。
- 过滤器(Filter)可以在请求被转发到服务端前,对请求进行拦截和修改,例如参数校验、权限校验、流量监控、日志输出以及协议转换等。
- 过滤器可以在响应返回客户端之前,对响应进行拦截和再处理,例如修改响应内容或响应头、日志输出、流量监控等。
- 响应原路返回给客户端。
总而言之,客户端发送到 Spring Cloud Gateway 的请求需要通过一定的匹配条件,才能定位到真正的服务节点。在将请求转发到服务进行处理的过程前后(pre 和 post),我们还可以对请求和响应进行一些精细化控制。
Predicate 就是路由的匹配条件,而 Filter 就是对请求和响应进行精细化控制的工具。有了这两个元素,再加上目标 URI,就可以实现一个具体的路由了。
Dubbo是什么?
Apache Dubbo是一款高性能的Java RPC框架。其前身是阿里巴巴公司开源的一个高性能、轻量级的开源Java RPC框架,可以和Spring框架无缝集成。
什么是RPC?
RPC全称为remote procedure call,即远程过程调用。比如两台服务器A和B,A服务器上部署一个应用,B服务器上部署一个应用,A服务器上的应用想调用B服务器上的应用提供的方法,由于两个应用不在一个内存空间,不能直接调用,所以需要通过网络来表达调用的语义和传达调用的数据。
需要注意的是RPC并不是一个具体的技术,而是指整个网络远程调用过程。
RPC是一个泛化的概念,严格来说一切远程过程调用手段都属于RPC范畴。各种开发语言都有自己的RPC框架。Java中的RPC框架比较多,广泛使用的有RMI、Hessian、Dubbo等。
Dubbo干什么?
Dubbo提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
Vue和React的区别
1.框架本质不同
Vue本质是MVVM框架,由MVC发展而来;
React是前端组件化框架,由后端组件化发展而来。
2.数据流的不同
Vue1.0中可以实现两种双向绑定:父子组件之间,props可以双向绑定;组件与DOM之间可以通过v-model双向绑定。Vue2.x中去掉了第一种,也就是父子组件之间不能双向绑定了(但是提供了一个语法糖自动帮你通过事件的方式修改),并且Vue2.x已经不鼓励组件对自己的 props进行任何修改了。
React一直不支持双向绑定,提倡的是单向数据流,称之为onChange/setState()模式。不过由于我们一般都会用Vuex以及Redux等单向数据流的状态管理框架,因此很多时候我们感受不到这一点的区别了。
3.监听数据变化的实现原理不同
Vue通过 getter/setter以及一些函数的劫持,能精确知道数据变化。
React默认是通过比较引用的方式(diff)进行的,如果不优化可能导致大量不必要的VDOM的重新渲染。为什么React不精确监听数据变化呢?这是因为Vue和React设计理念上的区别,Vue使用的是可变数据,而React更强调数据的不可变,两者没有好坏之分,Vue更加简单,而React构建大型应用的时候更加鲁棒。
router
1.嵌套的路由/视图表
2.模块化的、基于组件的路由配置
3.路由参数、查询、通配符
4.基于 Vue.js 过渡系统的视图过渡效果
5.细粒度的导航控制
6.带有自动激活的 CSS class 的链接
7.HTML5 历史模式或 hash 模式,在 IE9 中自动降级
8.自定义的滚动条行为
ax 即“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),是指一种创建交互式网页应用的网页开发技术 Ajax = 异步 JavaScript 和 XML 或者是 HTML(标准通用标记语言的子集) Ajax 是一种用于创建快速动态网页的技术 Ajax 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术 通过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新 传统的网页(不使用 Ajax)如果需要更新内容,必须重载整个网页页面 参考百度百科
优点:
- 在页面无刷新的情况下与服务器通讯维护数据,用户体验好
- 异步通讯方式,不打断用户操作,响应能力迅速
- 把一些请求转到客户端,“按需取数据”,最大程度的减少冗余请求和对服务器造成的负担
- 基于标准化的并被广泛支持的技术,不需要下载浏览器插件或者小程序
使用:
1. 原生 ajax
ajax 的核心是 JavaScript 对象 XmlHttpRequest
2. jquery将ajax封装成了一个函数 $.ajax(),我们可以直接用这个函数来执行ajax请求
常用参数:
url : 请求的 URL 地址 type : 请求方式,默认是 GET,常用的还有 POST async : 请求是否异步,默认值是 true,表示异步,false 表示同步 dataType : 返回的数据类型,常用的是 json 格式 contentType: 请求的数据类型,默认为"application/x-www-form-urlencoded" data : 请求的数据参数 success : 请求成功后的回调函数 error : 请求失败后的回调函数
axios
axios 是一个基于promise 的 http 库,可以用于浏览器和 nodejs 中
优点:
- 从浏览器中创建 XMLHttpRequests
- 从 node.js 创建 http 请求
- 支持 Promise API
- 拦截请求和响应
- 转换请求数据和响应数据
- 取消请求
- 自动转换 JSON 数据
- 客户端支持防御 XSRF
使用:
通过向 axios 传递相关配置来创建请求
常用参数:
url : 请求的 URL 地址 method : 请求方式,默认是 GET,常用的还有 POST baseURL: baseURL 将自动加在 url 前面,除非 url 是一个绝对 URL responseType : 返回的数据类型,常用的是 json 格式 headers: 请求的自定义请求头 params : 与请求一起发送的 URL 参数 data : 请求的数据参数,只适用于 PUT, POST, 和 PATCH
axios({
url: 'https://me.csdn.net/weixin_45426836',
method: 'get',
responseType: 'json',
params: {
//'a': 1,
//'b': 2,
}
}).then(function (data) {
console.log(data)
}).catch(function (err) {
console.log(err)
})Markdown富文本编辑器(Vue),含图片上传mavon-editor插件和marked(解析成html)——> 导入mavonEditor组件 ——> 绑定对应事件以及model ——> 进行事件处理
linux
1.1 Linux系统的文件结构
/bin 二进制文件,系统常规命令
/boot 系统启动分区,系统启动时读取的文件
/dev 设备文件
/etc 大多数配置文件
/home 普通用户的家目录
/lib 32位函数库
/lib64 64位库
/media 手动临时挂载点
/mnt 手动临时挂载点
/opt 第三方软件安装位置
/proc 进程信息及硬件信息
/root 临时设备的默认挂载点
/sbin 系统管理命令
/srv 数据
/var 数据
/sys 内核相关信息
/tmp 临时文件
/usr 用户相关设定
六、打包与解压
6.1 说明
.zip、.rar //windows系统中压缩文件的扩展名
.tar //Linux中打包文件的扩展名
.gz //Linux中压缩文件的扩展名
.tar.gz //Linux中打包并压缩文件的扩展名
1
2
3
4
6.2 打包文件
tar -zcvf 打包压缩后的文件名 要打包的文件
参数说明:z:调用gzip压缩命令进行压缩; c:打包文件; v:显示运行过程; f:指定文件名;
示例:
tar -zcvf a.tar file1 file2,... //多个文件压缩打包
1
2
3
4
6.3 解压文件
tar -zxvf a.tar //解包至当前目录
tar -zxvf a.tar -C /usr------ //指定解压的位置
unzip test.zip //解压*.zip文件
unzip -l test.zip //查看*.zip文件的内容
4.3 编辑文件(vi、vim)
查看目录(ls)
创建目录(mkdir)
修改目录(mv)
docker images -a列出本地所有的镜像docker images -p只显示镜像IDdocker images --digests显示镜像的摘要信息
docker ps列出当前所有正在运行的容器docker ps -a列出所有的容器
docker start 容器ID或容器名称启动容器
docker restart 容器ID或容器名称重新启动容器
docker stop容器ID或容器名称停止容器
docker kill 容器ID或容器名称强制停止容器
docker rm 容器ID或容器名称删除容器
docker rm -f 容器ID或容器名称强制删除容器















 1539
1539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









