







5月29日,录信数软技术总监郑其华在QCon全球软件开发者大会分享了“基于Lucene实现万亿级多维检索与实时分析”的主题演讲,现场座无虚席,活动在浓烈的技术讨论氛围中圆满结束。下面,我们将分享演讲全文及课件。
一、演讲全文
1.万亿挑战之一:数据存储
第一个关于数据存储。平常我们保存数据很简单,往硬盘里面写就行了。海量数据就没那么简单,会面临很多问题。比如成本问题。是使用SSD固态硬盘还是机械磁盘,是使用100块大磁盘,还是使用1万块小磁盘,在成本上都会造成巨大的差异。
其次,数据的安全性也是一个问题。万一磁盘损坏了,或者误删除了,数据就会丢失。数据迁移、扩容也会比较麻烦。另外,还有一个读写均衡的问题。数据写入不均衡的话,可能就会导致有的磁盘特别忙,有的磁盘很空闲。或者,如果有个别磁盘出问题了,读写速度变慢了,就会导致所有的查询都会卡在这个磁盘的IO上面,降低了整体性能。
针对存储的这些问题,我们采用了基于HDFS的索引技术来解决。

采用HDFS可以解决哪些问题呢?对于读写不均衡的问题,HDFS是一个高度容错的系统,如果有磁盘坏掉了,或者速度变慢了,会自动切换到速度较快的副本上进行读取。并且,会对磁盘数据读写进行自动均衡,避免出现数据倾斜的问题。对于数据安全性的问题,HDFS有数据快照、冗余副本等功能,可以降低因磁盘损坏,或者误删除操作带来的数据丢失问题。对于存储成本问题,HDFS支持异构存储,可以混合使用各种存储介质,降低硬件成本。而且,HDFS可以支持大规模的集群,使用和管理成本都比较低。
除此之外,为了进一步降低存储成本,我们研发了列簇的功能。原生Lucene是不支持列簇的,列簇的好处是什么呢?
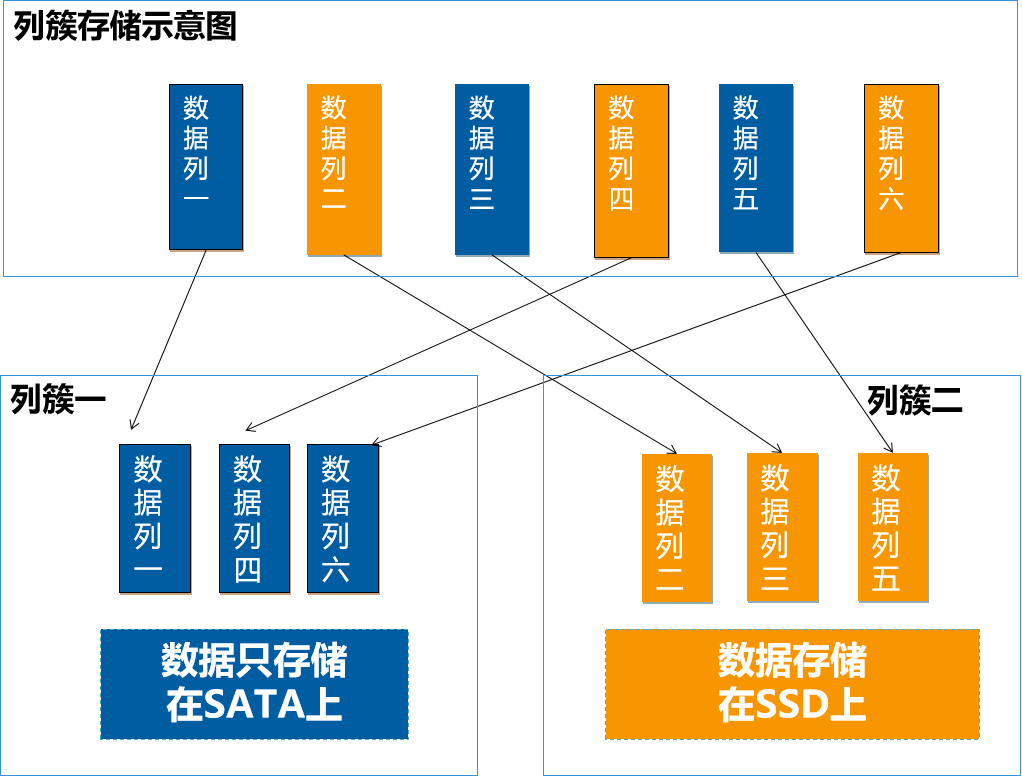
我们可以将数据列,指定为不同的列簇,按列簇来混合使用不同磁盘,并且可以对不同列簇设置不同的生命周期。比如,一个文档里面可能包含一些结构化的数据,像标题、作者、摘要等等,这些数据一般比较小,而且是经常要进行检索的。那么我们就可以将这些数据列定义为一个列簇,放在SSD上。还有一些类似附件、图片、视频等非结构化的数据,这些数据比较大,而且一般不会进行查询的,可以定义为另一个列簇,放在的SATA盘上面。从而降低了SSD固态硬盘的使用量。另外,列簇结合HDFS的异构策略,我们还可以实现冷热数据的分离。比如,有的业务经常查询最近1个月以内数据。那么,我们就可以将最近1个月保留在SSD上,1个月以后,将数据,移到SATA盘上,从而进一步降低SSD使用量。

接下来,再看另外一个问题。大数据有一个基本的应用,就是查询检索。比如这个页面上显示的一个“全文检索”功能,是从海量数据里面查找包含用户输入关键字的数据。这样的搜索功能很常见,也不难实现。难的地方在于性能。对于万亿规模的数据,是几秒就响应了,还是几个小时再响应呢?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2054
2054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









