






目录
MySQL架构原理
MySQL体系架构
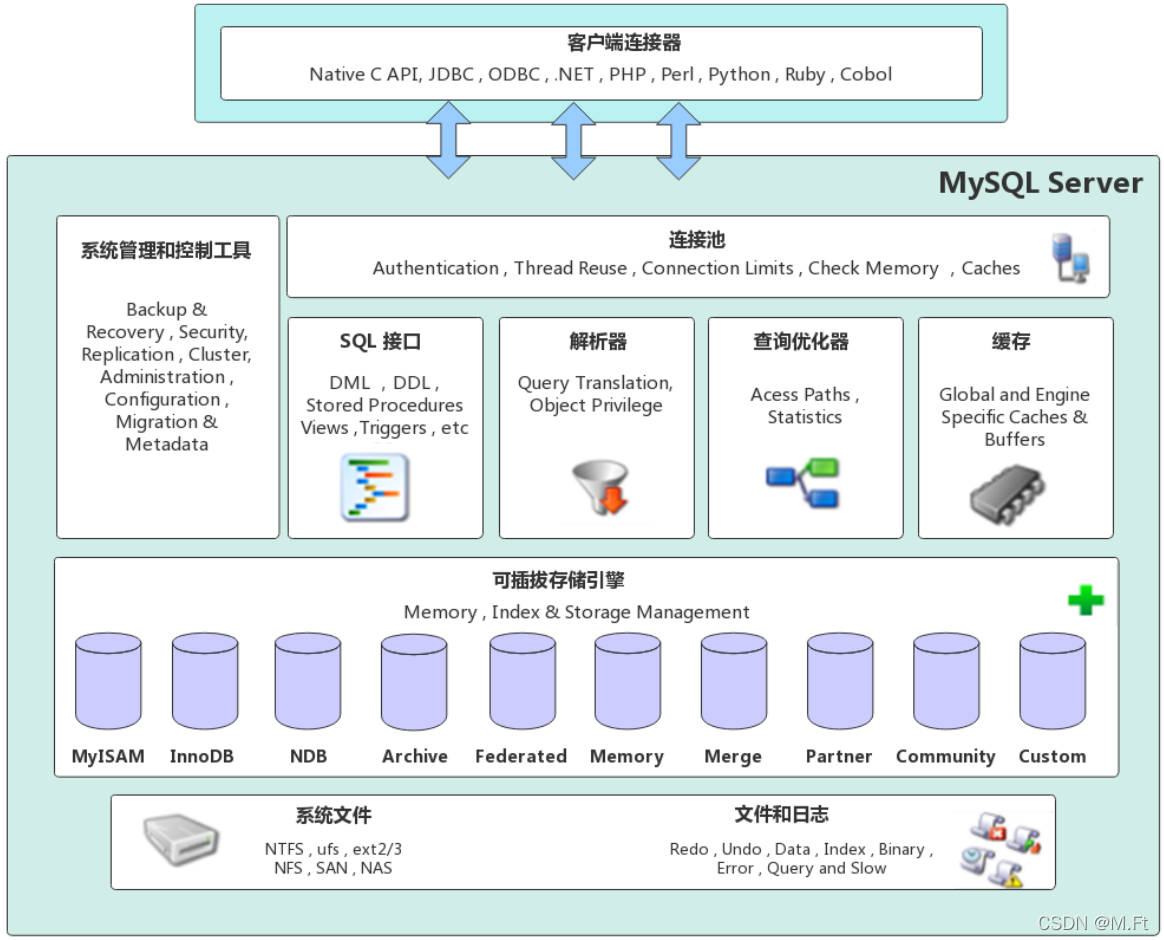
MySQL Server架构自顶向下大致可以分网络连接层、服务层、存储引擎层和系统文件层。
- 连接池(Connection Pool):负责存储和管理客户端与数据库的连接,一个线程负责管理一个连接。
- 系统管理和控制工具(Management Services & Utilities):例如备份恢复、安全管理、集群管理等
- SQL接口(SQL Interface):用于接受客户端发送的各种SQL命令,并且返回用户需要查询的结果。比如DML、DDL、存储过程、视图、触发器等。
- 解析器(Parser):负责将请求的SQL解析生成一个"解析树"。然后根据一些MySQL规则进一步检查解析树是否合法。
- 查询优化器(Optimizer):当“解析树”通过解析器语法检查后,将交由优化器将其转化成执行计划,然后与存储引擎交互。
- 缓存(Cache&Buffffer): 缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,权限缓存,引擎缓存等。如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
三、存储引擎层(Pluggable Storage Engines)
- 日志文件
- 错误日志(Error log)
默认开启,show variables like '%log_error%' - 通用查询日志(General query log)
记录一般查询语句,show variables like '%general%'; - 二进制日志(binary log)
记录了对MySQL数据库执行的更改操作,并且记录了语句的发生时间、执行时长;但是它不记录select、show等不修改数据库的SQL。主要用于数据库恢复和主从复制。
show variables like '%log_bin%'; //是否开启
show variables like '%binlog%'; //参数查看
show binary logs;//查看日志文件 - 慢查询日志(Slow query log)
记录所有执行时间超时的查询SQL,默认是10秒。
show variables like '%slow_query%'; //是否开启
show variables like '%long_query_time%'; //时长
- 错误日志(Error log)
- 配置文件
用于存放MySQL所有的配置信息文件,比如my.cnf、my.ini等。 - 数据文件
- db.opt 文件:记录这个库的默认使用的字符集和校验规则。
- frm 文件:存储与表相关的元数据(meta)信息,包括表结构的定义信息等,每一张表都会有一个frm 文件。
- MYD 文件:MyISAM 存储引擎专用,存放 MyISAM 表的数据(data),每一张表都会有一个.MYD 文件。
- MYI 文件:MyISAM 存储引擎专用,存放 MyISAM 表的索引相关信息,每一张 MyISAM 表对应一个 .MYI 文件。
- ibd文件和 IBDATA 文件:存放 InnoDB 的数据文件(包括索引)。InnoDB 存储引擎有两种表空间方式:独享表空间和共享表空间。独享表空间使用 .ibd 文件来存放数据,且每一张InnoDB 表对应一个 .ibd 文件。共享表空间使用 .ibdata 文件,所有表共同使用一个(或多个,自行配置).ibdata 文件。
- ibdata1 文件:系统表空间数据文件,存储表元数据、Undo日志等 。
- ib_logfifile0、ib_logfifile1 文件:Redo log 日志文件。
- pid 文件
pid 文件是 mysqld 应用程序在 Unix/Linux 环境下的一个进程文件,和许多其他 Unix/Linux 服务端程序一样,它存放着自己的进程 id。 - socket 文件
socket 文件也是在 Unix/Linux 环境下才有的,用户在 Unix/Linux 环境下客户端连接可以不通过TCP/IP 网络而直接使用 Unix Socket 来连接 MySQL。
MySQL运行机制
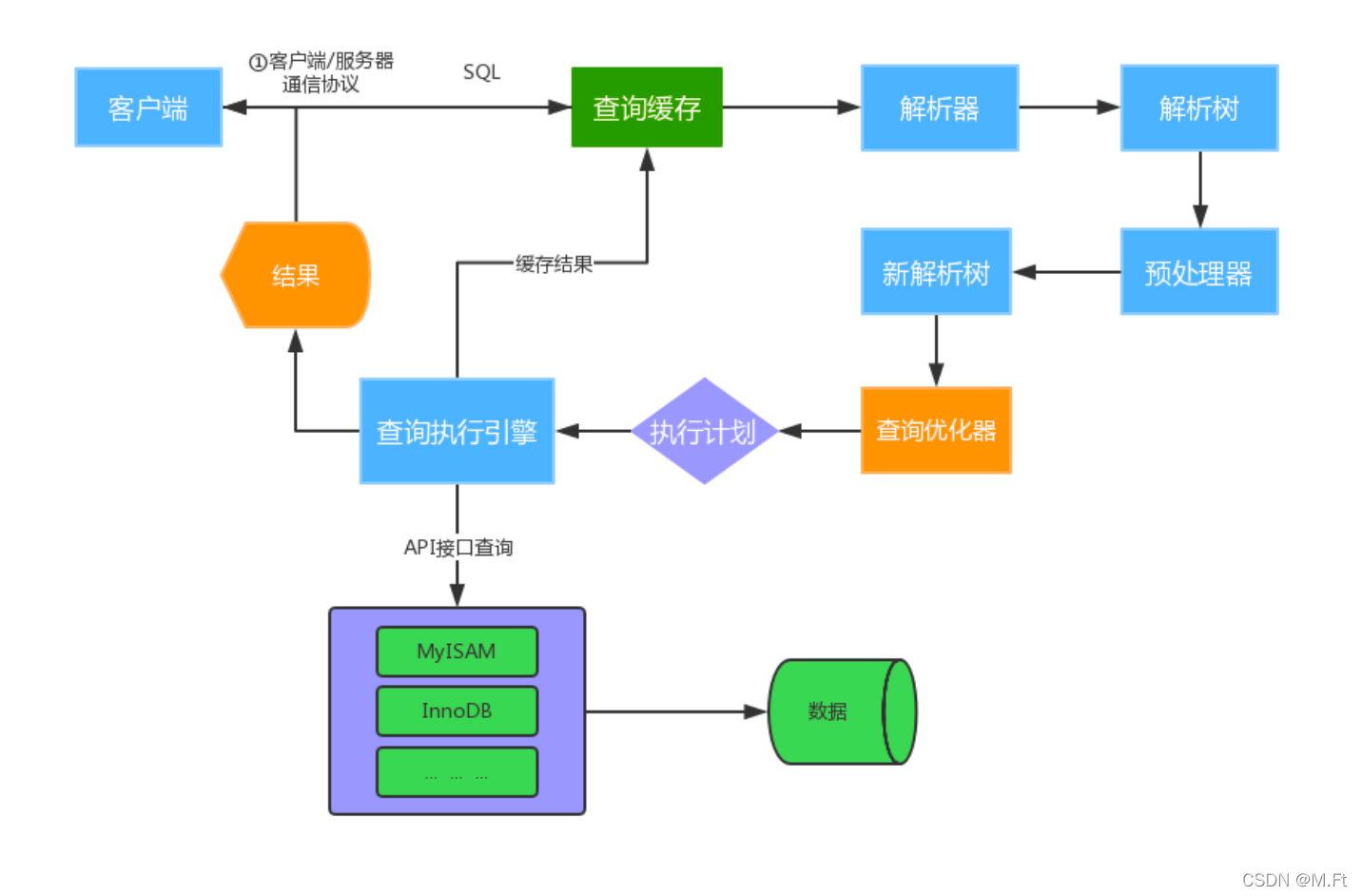
1. 建立连接:对于每一个 MySQL 的连接,时刻都有一个线程状态来标识这个连接正在做什么。
2.查询缓存 :如果开启了查询缓存且在查询缓存过程中查询到完全相同的SQL语句,则将查询结果直接返回给客户端。
即使开启查询缓存,以下SQL也不能缓存
- 查询语句使用SQL_NO_CACHE
- 查询的结果大于query_cache_limit设置
- 查询中有一些不确定的参数,比如now()
3.解析器:将客户端发送的SQL进行语法解析,生成"解析树"。预处理器根据一些MySQL规则进一步检查“解析树”是否合法,例如这里将检查数据表和数据列是否存在,还会解析名字和别名,看看它们是否有歧义,最后生成新的“解析树”。
4.查询优化:根据“解析树”生成最优的执行计划。
- 等价变换策略
- 5=5 and a>5 改成 a > 5
- a < b and a=5 改成b>5 and a=5
- 基于联合索引,调整条件位置等
- 优化count、min、max等函数
- InnoDB引擎min函数只需要找索引最左边
- InnoDB引擎max函数只需要找索引最右边
- MyISAM引擎count(*),不需要计算,直接返回
- 提前终止查询
- 使用了limit查询,获取limit所需的数据,就不在继续遍历后面数据
- in的优化
- MySQL对in查询,会先进行排序,再采用二分法查找数据。比如where id in (2,1,3),变成 in (1,2,3)
5.查询执行引擎 执行sql
如果开启了查询缓存,先将查询结果做缓存操作
返回结果过多,采用增量模式返回
MySQL存储引擎
负责MySQL中的数据的存储和提取
InnoDB和MyISAM对比
| innoDB | MyISAM | innoDB场景 | MyISAM场景 | |
| 事物和外键 | 支持事物和外键,具有安全性和完整性,适合大量insert或update操作 | 不支持事物和外键,它提供高速存储和检索,适合大量的select查询操作 | 数据更新较为频繁的场景 | 数据修改相对较少,以读为主的场景 |
| 索引结构 | InnoDB使用聚集索引(聚簇索引),索引和记录在一起存储,既缓存索引,也缓存记录 | MyISAM使用非聚集索引(非聚簇索引),索引和记录分开 | 需要事务支持的场景(具有较好的事务特性) | 不需要事务支持的场景 |
| 锁机制 | InnoDB支持行级锁,锁定指定记录。基于索引来加锁实现 | MyISAM支持表级锁,锁定整张表 | ||
| 并发处理能力 | InnoDB读写阻塞可以与隔离级别有关,可以采用多版本并发控制(MVCC)来支持高并发 | MyISAM使用表锁,会导致写操作并发率低,读之间并不阻塞,读写阻塞 | 行级锁定对高并发有很好的适应能力的场景 | 并发相对较低的场景(锁定机制问题) |
| 存储文件 | InnoDB表对应两个文件,一个.frm表结构文件,一个.ibd数据文件。 InnoDB表最大支持64TB | MyISAM表对应三个文件,一个.frm表结构文件,一个MYD表数据文件,一个.MYI索引文件。 从MySQL5.0开始默认限制是256TB | 硬件设备内存较大,可以利用InnoDB较好的缓存能力来提高内存利用率,减少磁盘IO | |
| 一致性 | 数据一致性要求较高的场景 | 数据一致性要求不高场景 |
InnoDB存储结构
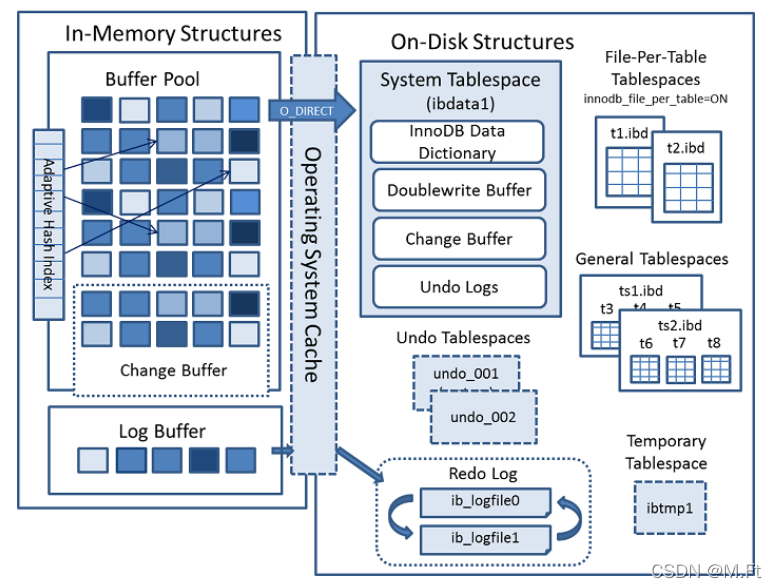
从MySQL 5.5版本开始默认使用InnoDB作为引擎,它擅长处理事务,具有自动崩溃恢复的特性,主要分为内存结构和磁盘结构两大部分。
内存结构主要包括Buffffer Pool、Change Buffffer、Adaptive Hash Index和Log Buffffer四大组件;
InnoDB磁盘主要包含Tablespaces,InnoDB Data Dictionary,Doublewrite Buffffer、Redo Log和Undo Logs。
内存结构:
- Buffffer Pool:缓冲池。BP以Page页为单位,默认大小16K,BP的底层采用链表数据结构管理Page。在InnoDB访问表记录和索引时会在Page页中缓存,以后使用可以减少磁盘IO操作,提升效率。
- Change Buffffer:写缓冲区。在进行DML操作时,如果BP没有其相应的Page数据,并不会立刻将磁盘页加载到缓冲池,而是在CB记录缓冲变更,等未来数据被读取时,再将数据合并恢复到BP中。写缓冲区,仅适用于非唯一普通索引页
- Adaptive Hash Index:自适应哈希索引,用于优化对BP数据的查询。InnoDB存储引擎会监控对表索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引,所以称之为自适应。InnoDB存储引擎会自动根据访问的频率和模式来为某些页建立哈希索引。
- Log Buffer:日志缓冲区,LogBuffer主要是用于记录InnoDB引擎日志,在DML操作时会产生Redo和Undo日志。LogBuffer空间满了,会自动写入磁盘(可以通过将innodb_log_buffer_size参数调大),减少磁盘IO频率,当遇到BLOB或多行更新的大事务操作时,增加日志缓冲区可以节省磁盘I/O
磁盘结构:
- Tablespaces:表空间
- InnoDB Data Dictionary:数据字典
- Doublewrite Buffer:双写缓冲区
- Redo Log:重做日志
- Undo Logs:撤销日志
InnoDB线程模型
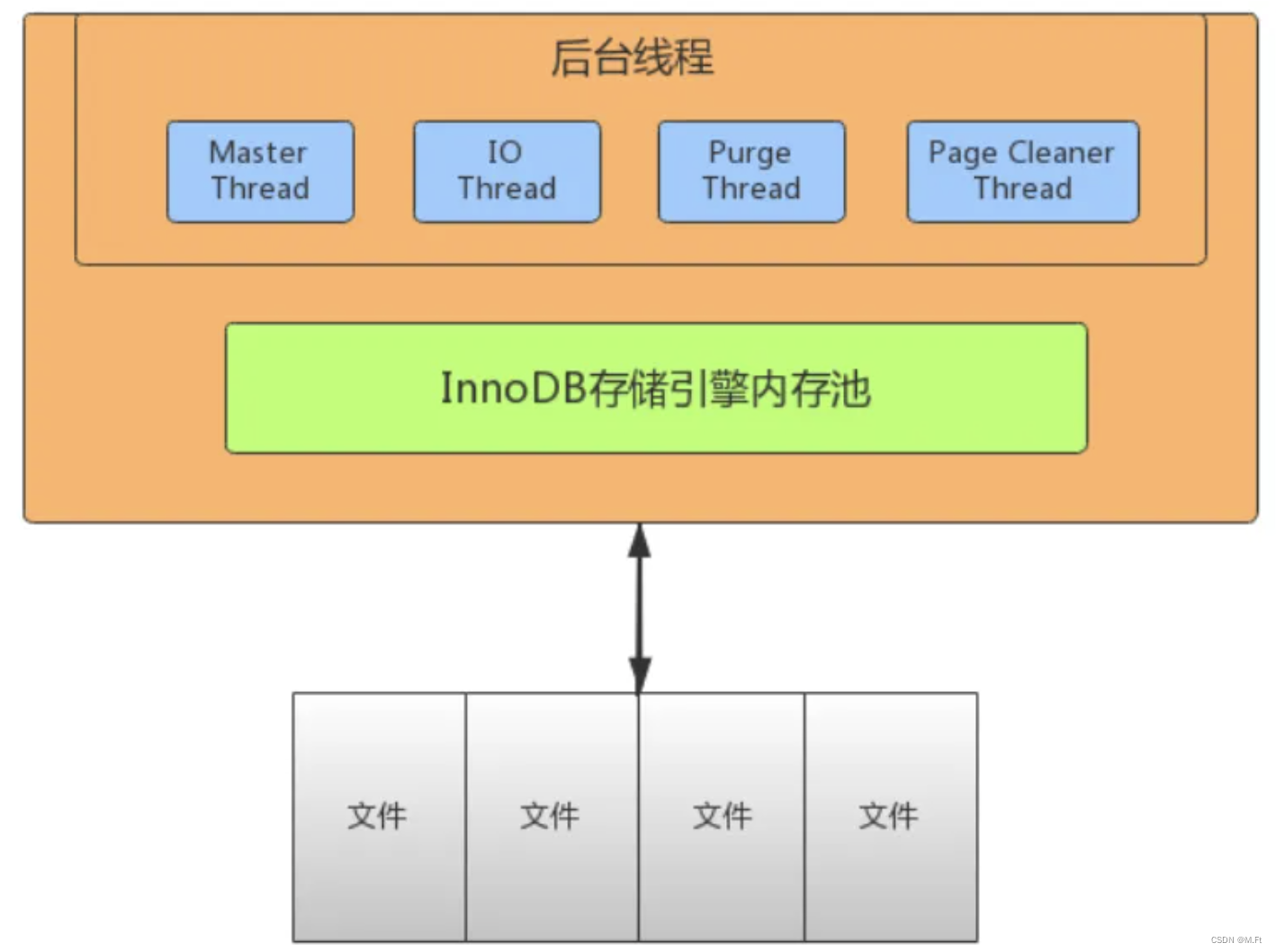
IO Thread
在InnoDB中使用了大量的AIO(Async IO)来做读写处理,这样可以极大提高数据库的性能。在InnoDB1.0版本之前共有4个IO Thread,分别是write,read,insert buffer和log thread,后来版本将read thread和write thread分别增大到了4个,一共有10个了。
- read thread : 负责读取操作,将数据从磁盘加载到缓存page页。4个
- write thread:负责写操作,将缓存脏页刷新到磁盘。4个
- log thread:负责将日志缓冲区内容刷新到磁盘。1个
- insert buffer thread :负责将写缓冲内容刷新到磁盘。1个
Purge Thread
事务提交之后,其使用的undo日志将不再需要,因此需要Purge Thread回收已经分配的undo页。
show variables like '%innodb_purge_threads%';Page Cleaner Thread
作用是将脏数据刷新到磁盘,脏数据刷盘后相应的redo log也就可以覆盖,即可以同步数据,又能达到redo log循环使用的目的。会调用write thread线程处理。
select @@innodb_page_cleaners;Master Thread
Master thread是InnoDB的主线程,负责调度其他各线程,优先级最高。作用是将缓冲池中的数据异步刷新到磁盘 ,保证数据的一致性。包含:脏页的刷新(page cleaner thread)、undo页回收(purge thread)、redo日志刷新(log thread)、合并写缓冲等。内部有两个主处理,分别是每隔1秒和10秒处理。
MySQL索引原理
索引类型
索引可以提升查询速度,会影响where查询,以及orderBy排序。MySQL索引类型如下:
- 从索引存储结构划分:BTree索引、Hash索引、FULLTEXT全文索引、RTree索引
- 从应用层次划分:普通索引、唯一索引、主键索引、复合索引
- 从索引键值类型划分:主键索引、辅助索引(二级索引)
- 从数据存储和索引键值逻辑关系划分:聚集索引(聚簇索引)、非聚集索引(非聚簇索引)
普通索引
- CREATE INDEX <索引的名字> ON tablename (字段名);
- ALTER TABLE tablename ADD INDEX [索引的名字] (字段名);
- CREATE TABLE tablename ( [...], INDEX [索引的名字] (字段名) );
唯一索引
- CREATE UNIQUE INDEX <索引的名字> ON tablename (字段名);
- ALTER TABLE tablename ADD UNIQUE INDEX [索引的名字] (字段名);
- CREATE TABLE tablename ( [...], UNIQUE [索引的名字] (字段名) ;
主键索引
- CREATE TABLE tablename ( [...], PRIMARY KEY (字段名) );
- ALTER TABLE tablename ADD PRIMARY KEY (字段名);
复合索引
- CREATE INDEX <索引的名字> ON tablename (字段名1,字段名2...);
- ALTER TABLE tablename ADD INDEX [索引的名字] (字段名1,字段名2...);
- CREATE TABLE tablename ( [...], INDEX [索引的名字] (字段名1,字段名2...) );
- 何时使用复合索引,要根据where条件建索引,注意不要过多使用索引,过多使用会对更新操作效率有很大影响。
- 如果表已经建立了(col1,col2),就没有必要再单独建立(col1);如果现在有(col1)索引,如果查询需要col1和col2条件,可以建立(col1,col2)复合索引,对于查询有一定提高。
全文索引
- CREATE FULLTEXT INDEX <索引的名字> ON tablename (字段名);
- ALTER TABLE tablename ADD FULLTEXT [索引的名字] (字段名);
- CREATE TABLE tablename ( [...], FULLTEXT KEY [索引的名字] (字段名) ;
select * from user
where match(name) against('aaa');全文索引使用注意事项:
- 全文索引必须在字符串、文本字段上建立。
- 全文索引字段值必须在最小字符和最大字符之间的才会有效。(innodb:3-84;myisam:4-84)
- 全文索引字段值要进行切词处理,按syntax字符进行切割,例如b+aaa,切分成b和aaa
- 全文索引匹配查询,默认使用的是等值匹配,例如a匹配a,不会匹配ab,ac。如果想匹配可以在布尔模式下搜索a*
索引原理
定义:是存储引擎用于快速查找记录的一种数据结构。需要额外开辟空间和数据维护工作。
- 索引是物理数据页存储,在数据文件中(InnoDB,ibd文件),利用数据页(page)存储。
- 索引可以加快检索速度,但是同时也会降低增删改操作速度,索引维护需要代价。
B+Tree结构

- 非叶子节点不存储data数据,只存储索引值,这样便于存储更多的索引值;
- 叶子节点包含了所有的索引值和data数据;
- 叶子节点用指针连接,提高区间的访问性能;
相比B树,B+树进行范围查找时,只需要查找定位两个节点的索引值,然后利用叶子节点的指针进行遍历即可。而B树需要遍历范围内所有的节点和数据,显然B+Tree效率高。
B+树是多叉树结构,每个结点都是一个16k的数据页,能存放较多素引信息,所以扇出很高。三层左右就可以存储2kw左右的数据。也就是说查询一次数据,如果这些数据页都在磁盘里,那么最多需要查询三次磁盘IO。
聚簇索引和辅助索引
- 聚簇索引:B+Tree的叶子节点存放主键索引值和行记录就属于聚簇索引
- 非聚簇索引:如果索引值和行记录分开存放就属于非聚簇索引
- 主键索引:B+Tree的叶子节点存放的是主键字段值就属于主键索引
- 辅助索引:如果存放的是非主键值就属于辅助索引(二级索引)
索引分析与优化
EXPLAIN
MySQL 提供了一个 EXPLAIN 命令,它可以对 SELECT 语句进行分析,并输出 SELECT 执行的详细信息,供开发人员有针对性的优化。例如:
EXPLAIN select * from table;
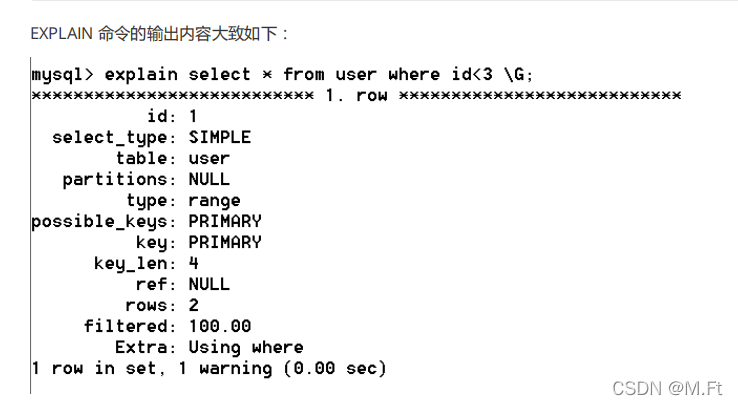
- select_type
表示查询的类型。常用的值如下:- SIMPLE : 表示查询语句不包含子查询或union
- PRIMARY:表示此查询是最外层的查询
- UNION:表示此查询是UNION的第二个或后续的查询DEPENDENT UNION:UNION中的第二个或后续的查询语句,使用了外面查询结果
- UNION RESULT:UNION的结果
- SUBQUERY:SELECT子查询语句
- DEPENDENT SUBQUERY:SELECT子查询语句依赖外层查询的结果。
- type:
表示存储引擎查询数据时采用的方式。比较重要的一个属性,通过它可以判断出查询是全表扫描还是基于索引的部分扫描。常用属性值如下,从上至下效率依次增强。- ALL:表示全表扫描,性能最差。
- index:表示基于索引的全表扫描,先扫描索引再扫描全表数据。
- range:表示使用索引范围查询。使用>、>=、
- ref:表示使用非唯一索引进行单值查询。
- eq_ref:一般情况下出现在多表join查询,表示前面表的每一个记录,都只能匹配后面表的一行结果。
- const:表示使用主键或唯一索引做等值查询,常量查询。
- NULL:表示不用访问表,速度最快。
- possible_keys
表示查询时能够使用到的索引。注意并不一定会真正使用,显示的是索引名称。 - key
表示查询时真正使用到的索引,显示的是索引名称。 - rows
MySQL查询优化器会根据统计信息,估算SQL要查询到结果需要扫描多少行记录。原则上rows是越少效率越高,可以直观的了解到SQL效率高低。 - key_len
表示查询使用了索引的字节数量。可以判断是否全部使用了组合索引。
key_len的计算规则如下:- 字符串类型
-
字符串长度跟字符集有关: latin1=1 、 gbk=2 、 utf8=3 、 utf8mb4=4char(n) : n* 字符集长度varchar(n) : n * 字符集长度 + 2 字节
-
数值类型TINYINT : 1 个字节SMALLINT : 2 个字节MEDIUMINT : 3 个字节INT 、 FLOAT : 4 个字节BIGINT 、 DOUBLE : 8 个字节
-
时间类型DATE : 3 个字节TIMESTAMP : 4 个字节DATETIME : 8 个字节
-
字段属性NULL 属性占用 1 个字节,如果一个字段设置了 NOT NULL ,则没有此项。
-
ExtraExtra 表示很多额外的信息,各种操作会在 Extra 提示相关信息,常见几种如下:
-
Using where
表示查询需要通过索引回表查询数据。 -
Using index表示查询需要通过索引,索引就可以满足所需数据。
-
Using fifilesort表示查询出来的结果需要额外排序,数据量小在内存,大的话在磁盘,因此有 Using fifilesort建议优化。
-
Using temprorary查询使用到了临时表,一般出现于去重、分组等操作。
-
回表查询
通过辅助索引查询主键值,然后再去聚簇索引查询记录信息
覆盖索引
只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快,这就叫做索引覆盖。
实现索引覆盖最常见的方法就是:将被查询的字段,建立到组合索引。
最左前缀原则
复合索引使用时遵循最左前缀原则,最左前缀顾名思义,就是最左优先,即查询中使用到最左边的列,那么查询就会使用到索引,如果从索引的第二列开始查找,索引将失效。
慢查询优化
long_query_time:指定慢查询的阀值,单位秒。如果SQL执行时间超过阀值,就属于慢查询记录到日志文件中。
- 如何判断是否为慢查询?
MySQL判断一条语句是否为慢查询语句,主要依据SQL语句的执行时间,它把当前语句的执行时间跟 long_query_time 参数做比较,如果语句的执行时间 > long_query_time,就会把这条执行语句记录到慢查询日志里面。long_query_time 参数的默认值是 10s,该参数值可以根据自己的业务需要进行调整。 - 如何判断是否应用了索引?
SQL语句是否使用了索引,可根据SQL语句执行过程中有没有用到表的索引,可通过 explain命令分析查看,检查结果中的 key 值,是否为NULL。 - 慢查询原因总结
全表扫描:explain分析type属性all 全索引扫描:explain分析type属性index 索引过滤性不好:靠索引字段选型、数据量和状态、表设计 频繁的回表查询开销:尽量少用select *,使用覆盖索引
事务和锁
事务控制的演进
并发事务
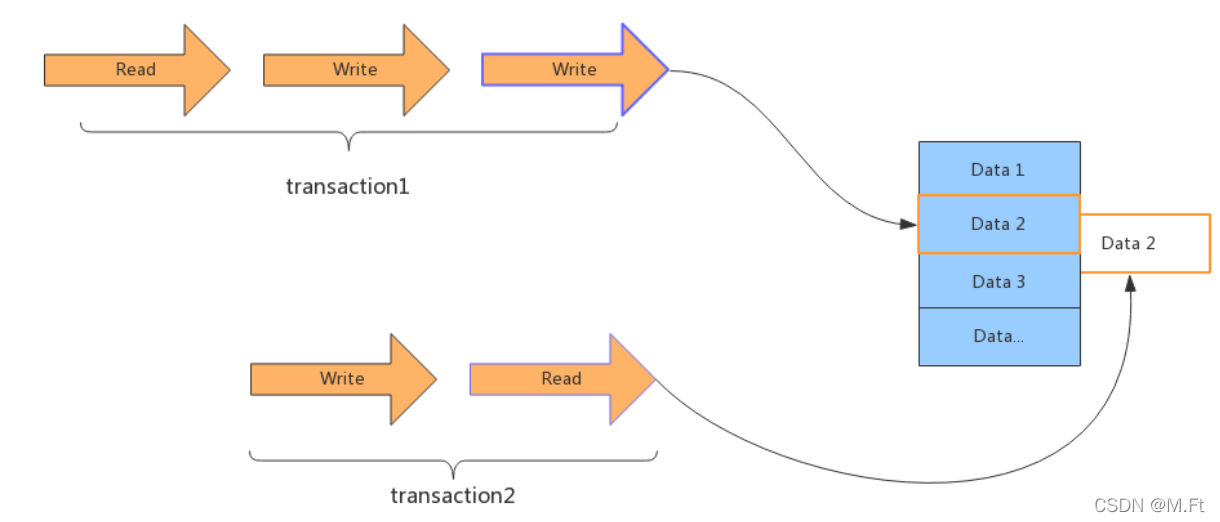
- 更新丢失
当两个或多个事务更新同一行记录,会产生更新丢失现象。可以分为回滚覆盖和提交覆盖。- 回滚覆盖:一个事务回滚操作,把其他事务已提交的数据给覆盖了。
- 提交覆盖:一个事务提交操作,把其他事务已提交的数据给覆盖了。
- 脏读
一个事务读取到了另一个事务修改但未提交的数据。 - 不可重复读
一个事务中多次读取同一行记录不一致,后面读取的跟前面读取的不一致。 - 幻读
一个事务中多次按相同条件查询,结果不一致。后续查询的结果和面前查询结果不同,多了或少了几行记录。
排他锁
排他锁:引入锁之后就可以支持并发处理事务,如果事务之间涉及到相同的数据项时,会使用排他锁,或叫互斥锁,先进入的事务独占数据项以后,其他事务被阻塞,等待前面的事务释放锁。
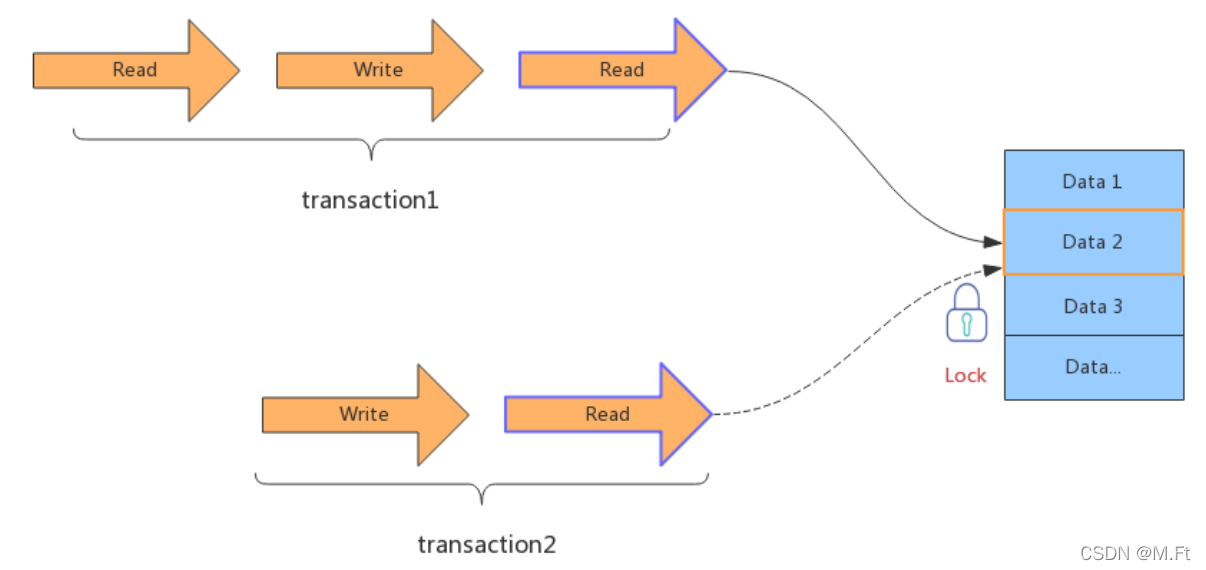
注意,在整个事务1结束之前,锁是不会被释放的,所以,事务2必须等到事务1结束之后开始。
读写锁
读和写操作:读读、写写、读写、写读。
读写锁就是进一步细化锁的颗粒度,区分读操作和写操作,让读和读之间不加锁,这样下面的两个事务就可以同时被执行了。
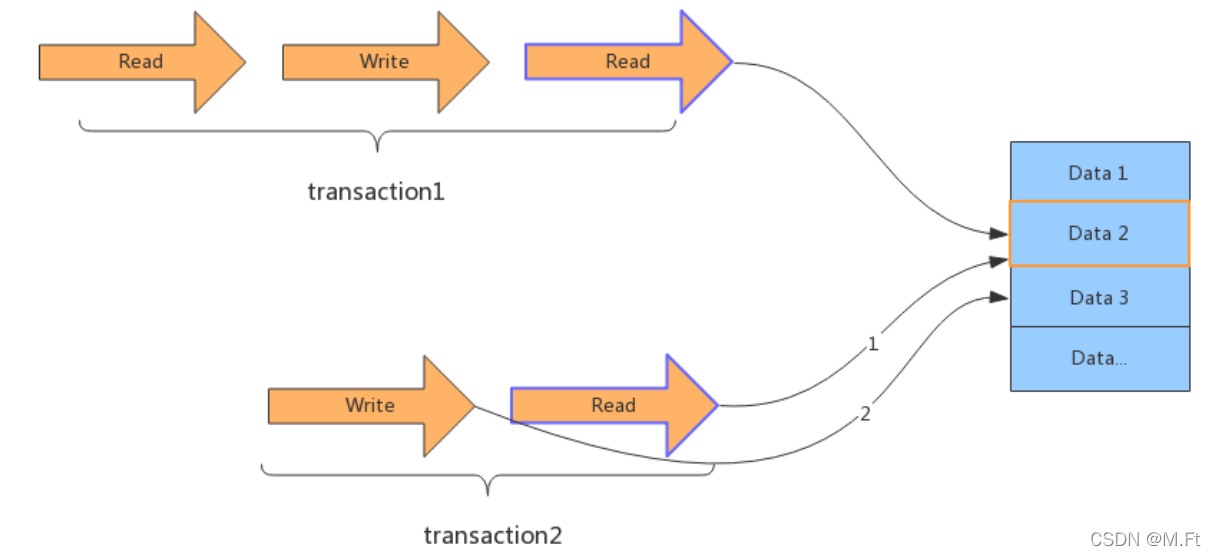
读写锁,可以让读和读并行,而读和写、写和读、写和写这几种之间还是要加排他锁。
MVCC
多版本控制MVCC,也就是Copy on Write的思想。MVCC除了支持读和读并行,还支持读和写、写和读的并行,但为了保证一致性,写和写是无法并行的。
MVCC最大的好处是读不加锁,读写不冲突。在读多写少的系统应用中,读写不冲突是非常重要的,极大的提升系统的并发性能,这也是为什么现阶段几乎所有的关系型数据库都支持 MVCC 的原因,不过目前MVCC只在 Read Commited 和 Repeatable Read 两种隔离级别下工作。
在 MVCC 并发控制中,读操作可以分为两类: 快照读(Snapshot Read)与当前读 (Current Read)。
- 快照读:读取的是记录的快照版本(有可能是历史版本),不用加锁。(select)
- 当前读:读取的是记录的最新版本,并且当前读返回的记录,都会加锁,保证其他事务不会再并发修改这条记录。(select... for update 或lock in share mode,insert/delete/update)
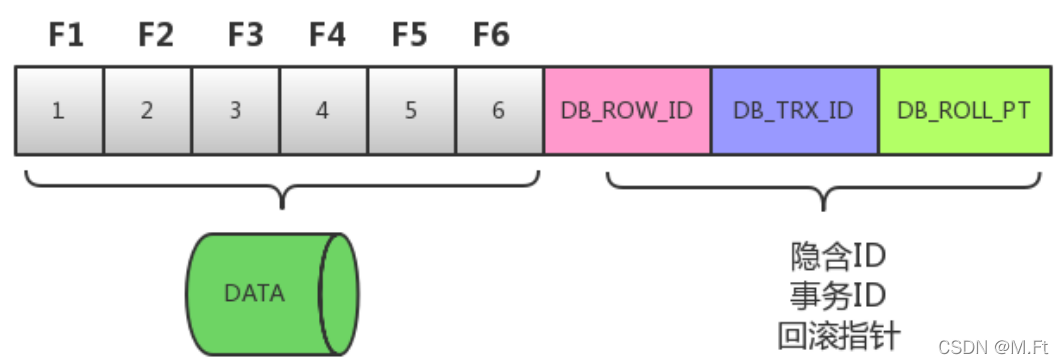
假设 F1~F6 是表中字段的名字,1~6 是其对应的数据。后面三个隐含字段分别对应该行的隐含ID、事务号和回滚指针,如下图所示。
具体的更新过程如下:
假如一条数据是刚 INSERT 的,DB_ROW_ID 为 1,其他两个字段为空。当事务 1 更改该行的数据值时,会进行如下操作,如下图所示。
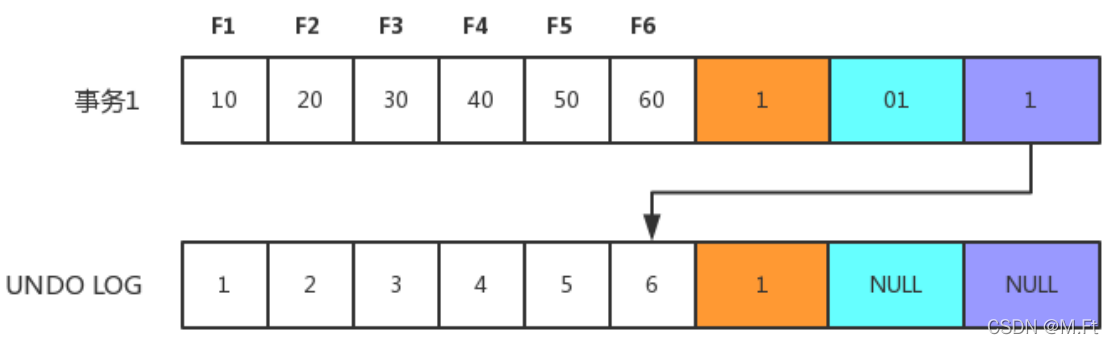
- 用排他锁锁定该行;记录 Redo log;
- 把该行修改前的值复制到 Undo log,即图中下面的行;
- 修改当前行的值,填写事务编号,使回滚指针指向 Undo log 中修改前的行。
事务隔离级别
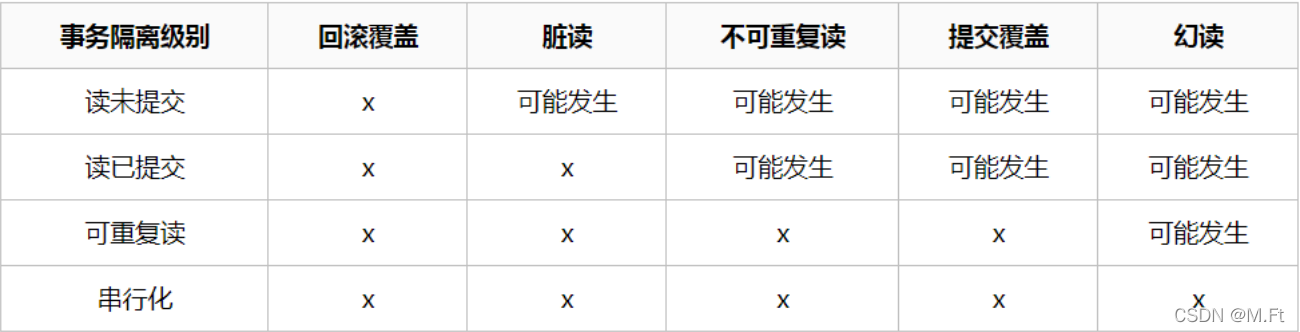
事务隔离级别和锁的关系
- 事务隔离级别是SQL92定制的标准,相当于事务并发控制的整体解决方案,本质上是对锁和MVCC使用的封装,隐藏了底层细节。
- 锁是数据库实现并发控制的基础,事务隔离性是采用锁来实现,对相应操作加不同的锁,就可以防止其他事务同时对数据进行读写操作。
- 对用户来讲,首先选择使用隔离级别,当选用的隔离级别不能解决并发问题或需求时,才有必要在开发中手动的设置锁。
锁机制
锁分类
在 MySQL中锁有很多不同的分类。
- 从操作的粒度可分为表级锁、行级锁和页级锁。
- 表级锁:每次操作锁住整张表。锁定粒度大,发生锁冲突的概率最高,并发度最低。应用在MyISAM、InnoDB、BDB 等存储引擎中。
- 行级锁:每次操作锁住一行数据。锁定粒度最小,发生锁冲突的概率最低,并发度最高。应用在InnoDB 存储引擎中。
- 页级锁:每次锁定相邻的一组记录,锁定粒度界于表锁和行锁之间,开销和加锁时间界于表锁和行锁之间,并发度一般。应用在BDB 存储引擎中。
- 从操作的类型可分为读锁和写锁。
IS锁、IX锁:意向读锁、意向写锁,属于表级锁,S和X主要针对行级锁。在对表记录添加S或X锁之前,会先对表添加IS或IX锁。
S锁:事务A对记录添加了S锁,可以对记录进行读操作,不能做修改,其他事务可以对该记录追加S锁,但是不能追加X锁,需要追加X锁,需要等记录的S锁全部释放。
X锁:事务A对记录添加了X锁,可以对记录进行读和修改操作,其他事务不能对记录做读和修改操作。- 读锁(S锁):共享锁,针对同一份数据,多个读操作可以同时进行而不会互相影响。
- 写锁(X锁):排他锁,当前写操作没有完成前,它会阻断其他写锁和读锁。
- 从操作的性能可分为乐观锁和悲观锁。
- 乐观锁:一般的实现方式是对记录数据版本进行比对,在数据更新提交的时候才会进行冲突检测,如果发现冲突了,则提示错误信息。
- 悲观锁:在对一条数据修改的时候,为了避免同时被其他人修改,在修改数据之前先锁定,再修改的控制方式。共享锁和排他锁是悲观锁的不同实现,但都属于悲观锁范畴。
















 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









