







文章目录
GoLang里runtime.Goexit讲解及使用runtime.Goexit()函数来使goroutine跑一半即退出
1.介绍"使goroutine跑一半即退出"
package main
import (
"fmt"
"time"
)
func Foo() {
fmt.Println("打印1")
defer fmt.Println("打印2")
fmt.Println("打印3")
}
func main() {
go Foo()
fmt.Println("打印4")
time.Sleep(1000*time.Second)
}
// 这段代码,正常运行会有下面的结果
打印4
打印1
打印3
打印2
注意这上面"打印2"是在defer中的,所以会在函数结束前打印,因此后置于"打印3";
那么今天的问题是,如何让Foo()函数跑一半就结束,比如说跑到打印2,就退出协程,使之输出如下结果
打印4
打印1
打印2
2.使用runtime.Goexit()函数
方法是:在"打印2"后面插入一个 runtime.Goexit(), 协程就会直接结束,并且结束前还能执行到defer里的打印2
package main
import (
"fmt"
"runtime"
"time"
)
func Foo() {
fmt.Println("打印1")
defer fmt.Println("打印2")
runtime.Goexit() // 加入这行
fmt.Println("打印3")
}
func main() {
go Foo()
fmt.Println("打印4")
time.Sleep(1000*time.Second)
}
// 输出结果
打印4
打印1
打印2
3.runtime.Goexit()函数的内部实现
内部实现代码如下:
func Goexit() {
// 为了方便讲解,Goexit()里省略了很多代码
gp := getg()
for {
// 获取defer并执行
d := gp._defer
reflectcall(nil, unsafe.Pointer(d.fn), deferArgs(d), uint32(d.siz), uint32(d.siz))
}
goexit1()
}
func goexit1() {
// 为了方便讲解,Goexit()里省略了很多代码
mcall(goexit0)
}
func goexit0(gp *g) {
// 为了方便讲解,Goexit()里省略了很多代码
// 获取当前的 goroutine
_g_ := getg()
// 将当前goroutine的状态置为 _Gdead
casgstatus(gp, _Grunning, _Gdead)
// 全局协程数减一
if isSystemGoroutine(gp, false) {
atomic.Xadd(&sched.ngsys, -1)
}
// 省略各种清空逻辑...
// 把g从m上摘下来。
dropg()
// 把这个g放回到p的本地协程队列里,放不下放全局协程队列。
gfput(_g_.m.p.ptr(), gp)
// 重新调度,拿下一个可运行的协程出来跑
schedule()
}
从代码上看,runtime.Goexit()会先执行一下defer里的方法,这里就解释了开头的代码里为什么在defer里的打印2能正常输出;
然后代码再执行goexit1,本质就是对goexit0的简单封装;
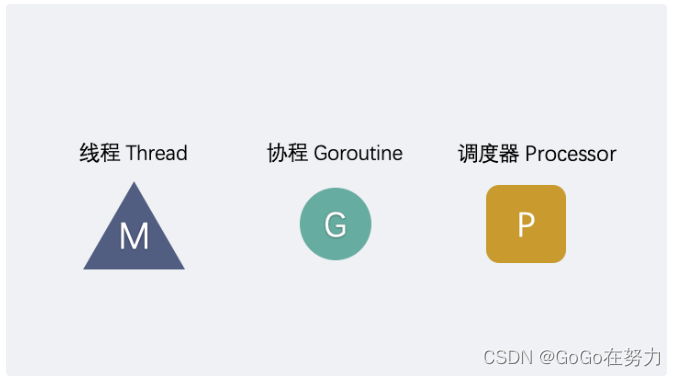
goexit0里的这段代码信息密度比较大,很多名词可能让人一脸懵,简单描述下,Go语言里有个GMP模型的说法,M是内核线程,G也就是我们平时用的协程goroutine,P会在G和M之间做工具人,负责调度G到M上运行,既然是调度,也就是说不是每个G都能一直处于运行状态,等G不能运行时,就把它存起来,再调度下一个能运行的G过来运行,暂时不能运行的G,P上会有个本地队列去存放这些这些G,P的本地队列存不下的话,还有个全局队列,干的事情也类似
了解这个背景后,再回到 goexit0 方法看看,做的事情就是将当前的协程G置为_Gdead状态,然后把它从M上摘下来,尝试放回到P的本地队列中,然后重新调度一波,获取另一个能跑的G,拿出来跑;
所以简单总结一下,只要执行 goexit 这个函数,当前协程就会退出,同时还能调度下一个可执行的协程出来跑;
看到这里,大家应该就能理解,开头的代码里,为什么runtime.Goexit()能让协程只执行一半就结束了

4.在Debug里的使用runtime.goexit()函数
package main
import (
"fmt"
"time"
)
func Foo() {
fmt.Println("打印1")
}
func main() {
go Foo()
fmt.Println("打印3")
time.Sleep(1000 * time.Second)
/*
输出:
打印3
打印1
*/
}
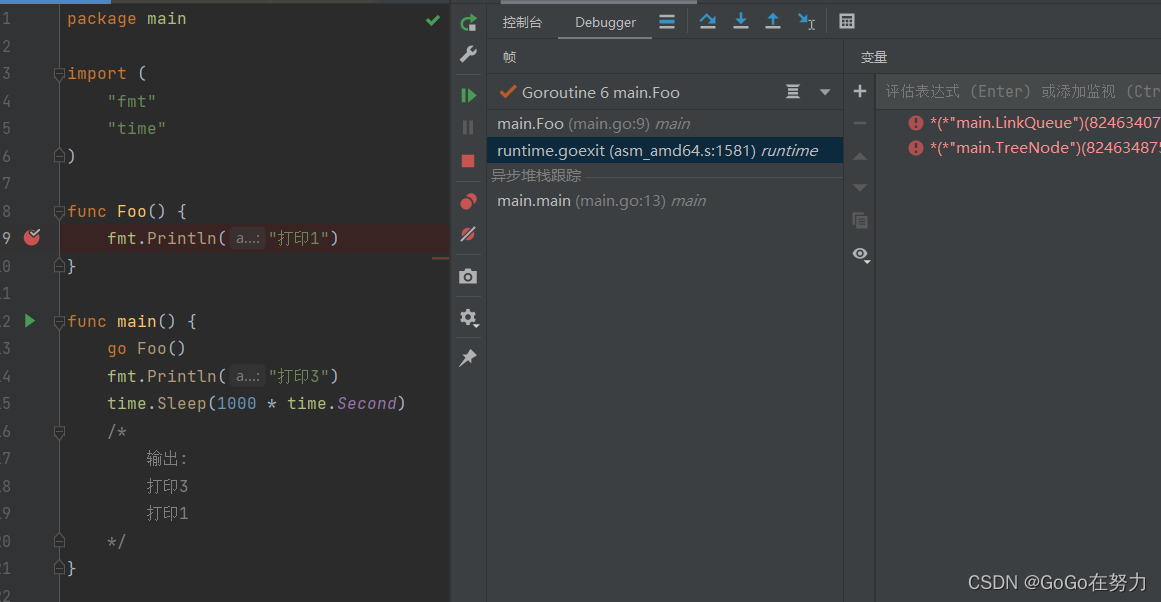
这是一段非常简单的代码,通过go关键字启动了一个goroutine执行Foo(),里面打印一下就结束,主协程sleep很长时间,只为死等;
我们现在在Foo()函数内随便打个断点,然后debug一,会发现,这个协程的堆栈底部是从runtime.goexit()里开始启动的;
如果大家平时有注意观察,会发现,其实所有的堆栈底部,都是从这个函数开始的
5.介绍runtime.goexit()函数
从上面的debug堆栈里点进去会发现,这是个汇编函数,可以看出调用的是runtime包内的 goexit1() 函数;
于是跟到了pruntime/proc.go里的代码中;
是不是很熟悉,这不就是我们开头讲runtime.Goexit()里内部执行的goexit0吗;
// The top-most function running on a goroutine
// returns to goexit+PCQuantum.
TEXT runtime·goexit(SB),NOSPLIT,$0-0
BYTE $0x90 // NOP
CALL runtime·goexit1(SB) // does not return
// traceback from goexit1 must hit code range of goexit
BYTE $0x90 // NOP
// 省略部分代码
func goexit1() {
mcall(goexit0)
}
6.每个堆栈底部都使用runtime.goexit()函数的原因
func main() {
B()
}
func B() {
A()
}
func A() {
}
我们首先需要知道的是,函数栈的执行过程,是先进后出;
假设我们有以上代码,上面的代码是main运行B函数,B函数再运行A函数,代码执行时就跟下面的动图那样;
这个是先进后出的过程,也就是我们常说的函数栈,执行完子函数A()后,就会回到父函数B()中,执行完B()后,最后就会回到main(),这里的栈底是main(),如果在栈底插入的是 goexit 的话,那么当程序执行结束的时候就都能跑到goexit里去;
结合前面讲过的内容,我们就能知道,此时栈底的goexit,会在协程内的业务代码跑完后被执行到,从而实现协程退出,并调度下一个可执行的G来运行
那么问题又来了,栈底插入goexit这件事是谁做的,什么时候做的;
直接说答案,这个在runtime/proc.go里有个newproc1方法,只要是创建协程都会用到这个方法,里面有个地方是这么写的:
func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) {
// 获取当前g
_g_ := getg()
// 获取当前g所在的p
_p_ := _g_.m.p.ptr()
// 创建一个新 goroutine
newg := gfget(_p_)
// 底部插入goexit
newg.sched.pc = funcPC(goexit) + sys.PCQuantum
newg.sched.g = guintptr(unsafe.Pointer(newg))
// 把新创建的g放到p中
runqput(_p_, newg, true)
// ...
}
主要的逻辑是获取当前协程G所在的调度器P,然后创建一个新G,并在栈底插入一个goexit;
所以我们每次debug的时候,就都能看到函数栈底部有个goexit函数
7.os.Exit()和runtime.Goexit()函数的区别
除了runtime.Goexit(),是不是还可以改为用os.Exit()?
同样都是带有"退出"的含义,两者退出的对象不同;
os.Exit() 指的是整个进程退出,而runtime.Goexit()指的是协程退出;
可想而知,改用os.Exit() 这种情况下,defer里的内容就不会被执行到了
package main
import (
"fmt"
"os"
"time"
)
func Foo() {
fmt.Println("打印1")
defer fmt.Println("打印2")
os.Exit(0)
fmt.Println("打印3")
}
func main() {
go Foo()
fmt.Println("打印4")
time.Sleep(1000*time.Second)
}
// 输出结果
打印4
打印1




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











