







题目描述
| Category | Difficulty | Likes | Dislikes |
|---|---|---|---|
| algorithms | Medium (64.44%) | 851 | - |
-
Tags
-
Companies
Unknown
给你一个链表的头节点 head 和一个特定值 **x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
示例 1:
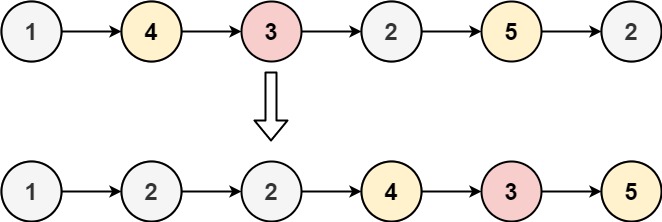
输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]
示例 2:
输入:head = [2,1], x = 2
输出:[1,2]
提示:
- 链表中节点的数目在范围
[0, 200]内 100 <= Node.val <= 100200 <= x <= 200
求解
方法一:模拟
思路及算法
直观来说我们只需维护两个链表 small 和 large 即可,small 链表按顺序存储所有小于 x 的节点,large 链表按顺序存储所有大于等于 x 的节点。遍历完原链表后,我们只要将 small 链表尾节点指向 large 链表的头节点即能完成对链表的分隔。
为了实现上述思路,我们设 smallHead 和 largeHead 分别为两个链表的哑节点,即它们的 next 指针指向链表的头节点,这样做的目的是为了更方便地处理头节点为空的边界条件。同时设 small 和 large 节点指向当前链表的末尾节点。开始时 smallHead=small,largeHead=large。随后,从前往后遍历链表,判断当前链表的节点值是否小于 x,如果小于就将 small 的 next 指针指向该节点,否则将 large 的 next 指针指向该节点。
遍历结束后,我们将 large 的 next 指针置空,这是因为当前节点复用的是原链表的节点,而其 next 指针可能指向一个小于 x 的节点,我们需要切断这个引用。同时将 small 的 next 指针指向 largeHead 的 next 指针指向的节点,即真正意义上的 large 链表的头节点。最后返回 smallHead 的 next 指针即为我们要求的答案。
代码
class Solution
{
public:
ListNode *partition(ListNode *head, int x)
{
ListNode *smallHead = new ListNode();
ListNode *small = smallHead;
ListNode *largeHead = new ListNode();
ListNode *large = largeHead;
while (head)
{
if (head->val < x)
{
small->next = head;
small = small->next;
}
else
{
large->next = head;
large = large->next;
}
head = head->next;
}
small->next = largeHead->next;
large->next = nullptr;
ListNode *ans = smallHead->next;
delete smallHead;
delete largeHead;
return ans;
}
};
复杂度分析
- 时间复杂度: O(n),其中 n 是原链表的长度。我们对该链表进行了一次遍历。
- 空间复杂度: O(1)。
方法二:队列
队列具有先进先出的特点,我们可以创建两个队列,分别为queue_less(存储小于x的节点指针), queue_more(存储大于x的节点指针),这样既可以分隔节点而且保留了原始链表的节点顺序。
先遍历一遍链表将节点分别存储到这两个队列中。然后创建建一个哑节点,先取出queue_less中的节点一个一个连接,再取出queue_more中的节点一个一个连接。最后将最终节点的next置空防止产生环形节点。
代码
class Solution
{
public:
ListNode *partition(ListNode *head, int x)
{
queue<ListNode *> queue_less, queue_more;
ListNode *dummy = new ListNode(0, head);
ListNode *p = dummy->next;
while (p)
{
if (p->val < x)
queue_less.push(p);
else
queue_more.push(p);
p = p->next;
}
p = dummy;
while (!queue_less.empty())
{
p->next = queue_less.front();
queue_less.pop();
p = p->next;
}
while (!queue_more.empty())
{
p->next = queue_more.front();
queue_more.pop();
p = p->next;
}
p->next = nullptr;
ListNode *ans = dummy->next;
delete dummy;
return ans;
}
};
复杂度分析
- 时间复杂度: O(n),其中 n 是原链表的长度。我们对该链表进行了一次遍历。
- 空间复杂度: O(n),借助队列存储 n 个节点的指针。
















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











