






背景
最近遇到了要从一个pdf表格中复制信息然后处理成excel,发现直接复制不能像平常那些数据按照合理的表格位置铺开,而是所有复制内容挤满在了复制的那一个单元格中,在网上也没找到这类处理方法,所以自己写了一个python代码处理一下这种问题:

Step1:将复制内容粘贴在一个txt文件中
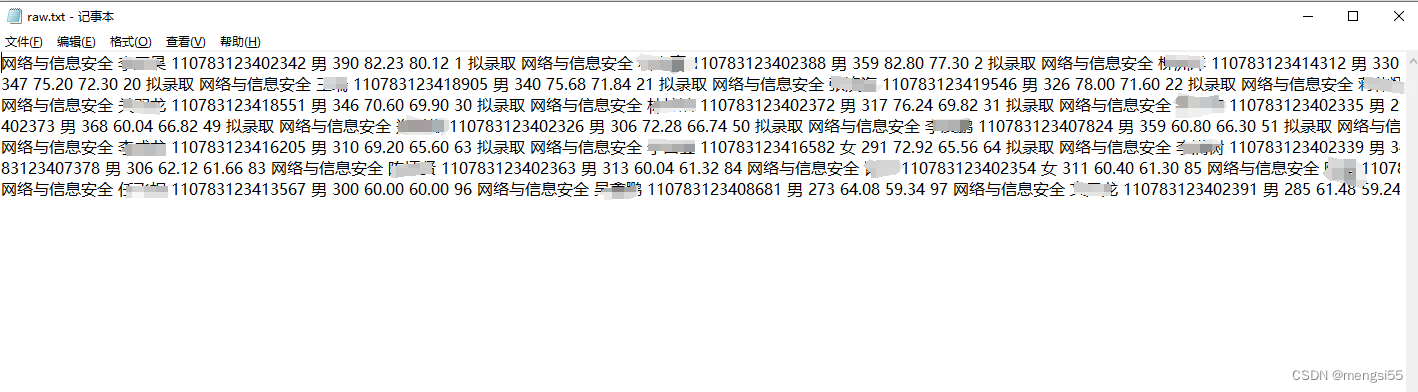
Step2:在python中使用正则表达式快速将其分段并保存进一个新的文件中
Step2.1:正则表达式书写
我要匹配的内容是“网络与信息安全......”,即每一个网络与信息安全就是一段信息,我希望将这些段分开来
p = re.compile(r"网络与信息安全\s+.*?(?=\s+网络与信息安全|$)", re.MULTILINE)上面这一段匹配字符串中,
(?=...)是正向预查的语法。正向预查是一种非捕获性的匹配,它指定一个位置,然后检查这个位置后面的内容是否满足某种条件。但是,它并不会消耗输入字符串中的字符,也不会将该条件作为匹配结果的一部分返回。
(?=\s+网络与信息安全|$)表示匹配的位置后面要么是一个或多个空白字符接着的 "网络与信息安全",要么是行尾。
Step2.2:打开和写入操作
with open('medium.txt', 'w', encoding='utf-8') as fw:
with open('raw.txt', 'r', encoding='utf-8') as fr:
results = p.findall(fr.read())
for result in results:
result = result.split(' ')
result2 = ','.join(result)
fw.write(result2 + '\n')Step3:写入excel表格中
def toExcel(fileName): # xlsxwriter库储存数据到excel
workbook = xw.Workbook(fileName) # 创建工作簿
sheet1 = workbook.add_worksheet("sheet1") # 创建子表
sheet1.activate() # 激活表
title = ['专业', '姓名', '考生编号', '性别', '初试分数', '复试分数', '总分', '总分排名', '是否录取'] # 设置表头
sheet1.write_row('A1', title) # 从A1单元格开始写入表头
with open('medium.txt', 'r') as f: # 这里打开的是处理过的分好段的txt文件
i = 2
lines = f.readlines()
for line in lines:
data = line.split(',')
row = 'A' + str(i)
sheet1.write_row(row, data)
i += 1
workbook.close() # 关闭表总体操作
import re
import xlsxwriter as xw
p = re.compile(r"网络与信息安全\s+.*?(?=\s+网络与信息安全|$)", re.MULTILINE) # 匹配从 "网络与信息安全" 开始,直到下一个 "网络与信息安全" 或行尾的部分
with open('medium.txt', 'w', encoding='utf-8') as fw:
with open('raw.txt', 'r', encoding='utf-8') as fr:
results = p.findall(fr.read())
for result in results:
result = result.split(' ')
result2 = ','.join(result)
fw.write(result2 + '\n')
def toExcel(fileName): # xlsxwriter库储存数据到excel
workbook = xw.Workbook(fileName) # 创建工作簿
sheet1 = workbook.add_worksheet("sheet1") # 创建子表
sheet1.activate() # 激活表
title = ['专业', '姓名', '考生编号', '性别', '初试分数', '复试分数', '总分', '总分排名', '是否录取'] # 设置表头
sheet1.write_row('A1', title) # 从A1单元格开始写入表头
with open('medium.txt', 'r') as f: # 这里打开的是处理过的分好段的txt文件
i = 2
lines = f.readlines()
for line in lines:
data = line.split(',')
row = 'A' + str(i)
sheet1.write_row(row, data)
i += 1
workbook.close() # 关闭表
fileName = '测试.xlsx'
toExcel(fileName)成果展示
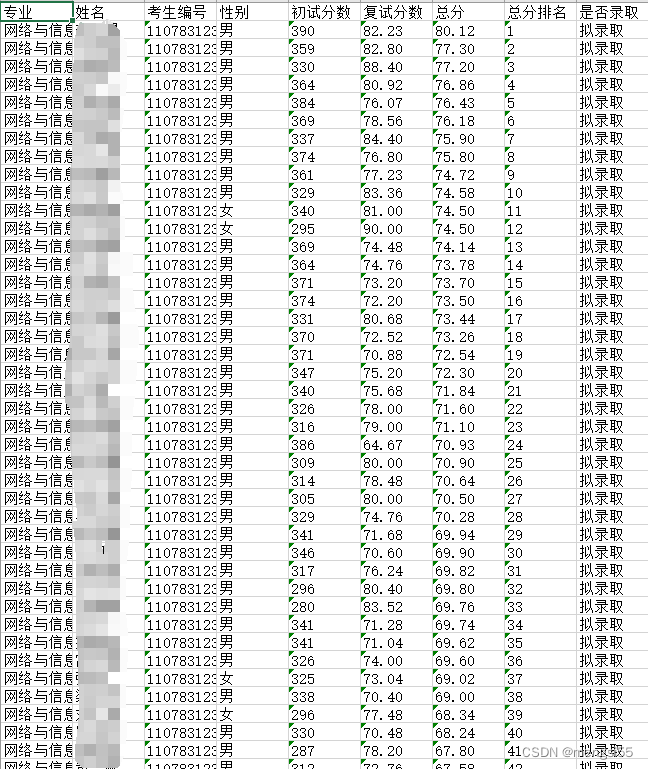
拓展方向
将最初的文本存储分段并且每列用逗号隔开,也很方便利用pandas库保存为csv文件















 8226
8226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









