







机器学习
机器学习的思路:
如何根据数据特征选择方法
机器学习的流程
1.获取数据集
2.数据基本处理
3.特征⼯程
特征预处理:
归一化和标准化:使用转换函数使数据更加符合算法模型
标准化用得多:通过对原始数据进⾏变换把数据变换到均值为0,标准差为1范围内
4.机器学习
5.模型评估
1.获取数据集
2.数据基本处理
3.特征⼯程
4.机器学习
5.模型评估
机器学习的算法
KNN
KNN与K_means的异同
重新看KNN的时候就在思考他与聚类的区别与联系,搜索到了一些解释。
1.KNN算法是分类算法,分类算法肯定是需要有学习语料,然后通过学习语料的学习之后的模板来匹配我们的测试语料集,将测试语料集合进行按照预先学习的语料模板来分类。
2.K-means算法是聚类分析中使用最广泛的算法之一。它把n个对象根据他们的属性分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。其聚类过程可以用下图表示。
当时聚类的代码环节也是有点纳闷,怎么这个没有数据集的划分啊,也没想深,看到这个解释就明白了。
KNN流程
KNN算法流程总结
1)计算已知类别数据集中的点与当前点之间的距离(欧式,其他各种距离)
2)按距离递增次序排序
3)选取与当前点距离最⼩的k个点
4)统计前k个点所在的类别出现的频率
5)返回前k个点出现频率最⾼的类别作为当前点的预测分类
KD树
作用:减少距离的计算量,优化。A离B近,C离B远,推出C离A远,另外还有balltreee优化程度(应该是指减少计算量)更高的算法
步骤:
1.计算维度方差(x,y)选择方差大的维度进行划分。
2.计算该维度的中位数,选择离中位数最近的点作为根节点(划分维度xyxyxy(在剩余维度选择方差较大的重复上述步骤))
3.给出一个查找点。先把查找点放到根节点,比较参考维度,根据kd数特点左小右大,依次走到叶子节点。把路径上的点依次放入栈。依次出栈,计算出栈元素与查找点的距离,查找点为圆心,距离为半径画圆,若与最近的。枝干不相交,则继续出栈,若相交,则要把新区域的点入栈。继续判断,更新最短距离。直到栈空。
交叉验证网格搜索:
交叉验证(不能提高准确率):将拿到的训练数据,分为训练和验证集
训练集:训练集+验证集
测试集:测试集
返回训练的平均值
N折交叉验证,改变训练集和测试集
网格搜索:
调节参数组合,输出最优结果
KNN的步骤
1.获取数据集
2.数据基本处理
#2.1 缩小数据范围
#2.2 提取出需要的值
#2.3 去掉噪声值
#2.4 确定特征值和⽬标值,特征值x是相关的影响量,y是要预测的量
#2.5 分割数据集 x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.2,random_state = 22)(rs固定每次输出一样)
3.特征⼯程
#实例化一个转换器
transfer = StandardScaler()
#调⽤fit_transform,注意特征工程处理的是特征值x,因为要把影响y的量弄到合适的范围。
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
4.机器学习
#4.1 实例化⼀个估计器
estimator = KNeighborsClassifier()
#4.2 调⽤gridsearchCV
param_grid = {“n_neighbors”: [1, 3, 5, 7, 9]}
estimator = GridSearchCV(estimator, param_grid=param_grid, cv=5)
#4.3 模型训练
#训练的两个都是train,训练是用训练集的特征值和目标值训练模型
estimator.fit(x_train, y_train)
5.模型评估
#5.1 基本评估⽅式
score = estimator.score(x_test, y_test)
print(“最后预测的准确率为:\n”, score)
#使用测试集的特征值估计测试集的目标值,估计器在之前已经用x和y训练过了。
#要估计y
y_predict = estimator.predict(x_test)
线性回归
定义:
线性回归(Linear regression)是利⽤回归⽅程(函数)对⼀个或多个⾃变量(特征值)和 因变量(⽬标值)之间关系进⾏建模的⼀种分析⽅式。
h(w)=w1x1+w2x2+…
线性回归的损失函数:

优化方法:正规方程,梯度下降
梯度下降公式:α是 步长
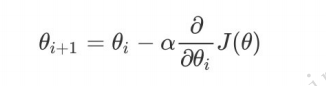
梯度下降法的步骤:
1.对损失函数求梯度(每个θi求偏导)
2.梯度x步长得到下降的距离,有n个(向量)
3.检查θi梯度下降距离(n个向量)是否都小于阈值,是就退出
4.不是的话就更新θi,返回1
梯度下降种类:
全梯度下降算法(Full gradient descent)
计算训练集所有样本误差,对其求和再取平均值作为⽬标函数。
随机梯度下降算法(Stochastic gradient descent)
每次只取一个训练集的样本
⼩批量梯度下降算法(Mini-batch gradient descent)
随机平均梯度下降算法(Stochastic average gradient descent)
随机平均梯度算法克服了这个问题,在内存中为每⼀个样本都维护⼀个旧的梯度, 随机选择第i个样本来更新此样本的梯度,其他样本的梯度保持不变,然后求得所有 梯度的平均值,进⽽更新了参数。
api:
estimator = SGDRegressor(max_iter=1000)
过拟合,欠拟合
过拟合,特征多,训练集表现好,测试集表现不好。
解决:添加其他特征项
添加多项式特征
欠拟合,都表现不好。
解决:重新清洗数据
增⼤数据的训练量
减少特征维度,防⽌维灾难
正则化(削弱某些项(尤其是高次项)的比例)
岭回归:系数接近0
LASSO回归:直接为0
弹性网络,RIDGE和LASSO调和比例
api:estimator = Ridge(alpha=1)
逻辑回归
是一种分类模型,适用于二分类问题
过程:输入一个函数(线性回归的结果),通过一个激活函数输出一个0,1的值,和阈值比较,标记为0或1完成二分类
损失函数:对数似然损失
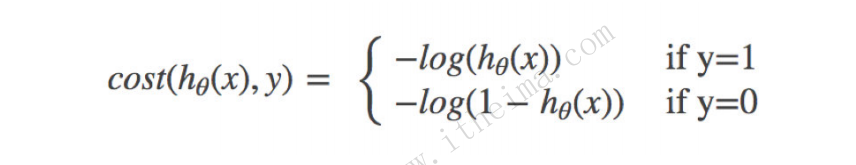

每个都有损失,预测值和实际值越接近损失值越小,eg预测0.99实际1损失小,log0.99,预测0.99实际0损失大,log0.01.
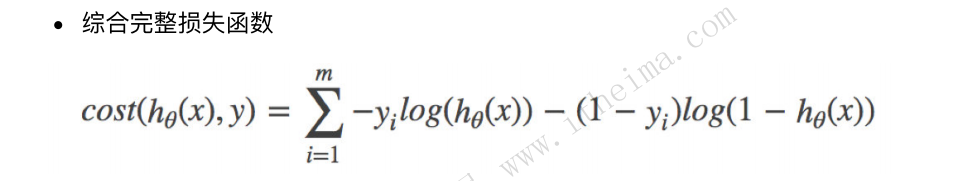
精确率(Precision):预测结果为正例样本中真实为正例的⽐例(了解)
召回率(Recall):真实为正例的样本中预测结果为正例的⽐例
模型评估:
真正例(TP) 伪反例(FN) 伪正例(FP) 真反例(TN)
准确率:(对不对) (TP+TN)/(TP+TN+FN+FP)
精确率 – 查的准不准
TP/(TP+FP)
召回率 – 查的全不全
TP/(TP+FN)
TODO:ROC和AUC
决策树
通过树形结构层层判断
信息熵:“信息熵” (information entropy)是度量样本集合纯度最常⽤的⼀种指标。

当所有事件的概率相同时,信息熵越大,这件事越不确定。划分数据时要是信息熵尽量小。
信息增益:
在不同的属性用信息熵的分类指标进行划分,x权重,计算类别信息熵和属性信息熵之差,差越大,效果越好。比如说计算性别属性的信息熵,分别对男女按照分类的信息熵求得新的信息熵,x男女的比例加起来。信息增益大的指标重点考察。

信息增益率:信息增益/只用属性算信息熵
IV:信息分裂度量

属性信息熵一定小于类别信息熵?应该是
C4.5计算流程
while(当前节点"不纯"):
1.计算当前节点的类别熵(以类别取值计算)
2.计算当前阶段的属性熵(按照属性取值吓得类别取值计算)
3.计算信息增益
4.计算各个属性的分裂信息度量
5.计算各个属性的信息增益率
end while
当前阶段设置为叶⼦节点
目的:选择更纯的分类标准作为叶子结点
基尼值和基尼指数:

先计算根节点的GINI值
再按照属性计算GINI值eg

对每个属性分别计算GINI值,找到最好的(GINI值最小的)分割方法,分成两个结点
对那两个结点重复以上步骤继续找最好的分割方法
注意新循环的根节点是上一个循环的最好的分割方法选出来不纯的所有结点,如果纯的话就不用继续分了,整个流程图呈树状发散
流程
while(当前节点"不纯"):
1.遍历每个变量的每⼀种分割⽅式,找到最好的分割点
2.分割成两个节点N1和N2
end while
剪枝:解决过拟合问题
预剪枝:一边生成树一边剪枝:对单节点进行分析(第二代)剪掉会使整体正确率降低的结点。似乎准确率更高。
后剪枝:生成完之后再剪枝,回溯剪枝。保留信息更多,欠拟合风险小,泛化性更好。消耗空间更大。
集成学习
原理:集成学习通过建⽴⼏个模型来解决单⼀预测问题。它的⼯作原理是⽣成多个分类器/ 模型,各⾃独⽴地学习和作出预测。这些预测最后结合成组合预测,因此优于任何
⼀个单分类的做出预测
1.解决⽋拟合问题
弱弱组合变强
2.解决过拟合问题
互相遏制变壮
Bagging

采样一部分数据,分类学习,平权投票集成
Boosting,在区域上画线划分,将分错的放大,分对的缩小,继续划线
Kmeans聚类
原理和步骤:
1、随机设置K个特征空间内的点作为初始的聚类中⼼
2、对于其他每个点计算到K个中⼼的距离,未知的点选择最近的⼀个聚类中⼼ 点作为标记类别
3、接着对着标记的聚类中⼼之后,重新计算出每个聚类的新中⼼点(平均 值)
4、如果计算得出的新中⼼点与原中⼼点⼀样(质⼼不再移动),那么结束, 否则重新进⾏第⼆步过程
聚类的模型评估:
1.误差平方和
2.肘方法:下降变平缓的位置是最佳K值
3.轮廓系数法

缺点:
1.对离群点,噪声敏感 (中⼼点易偏移)
2.很难发现⼤⼩差别很⼤的簇及进⾏增量计算
3.结果不⼀定是全局最优,只能保证局部最优(与K的个数及初值选取有关)
canopy配合聚类:画圆,优先选择圆外的点作为聚类中心
缺点:算法中 T1、T2的确定问题 ,依旧可能落⼊局部最优解
2 K-means++

选择更远的点作为聚类圆心
2分k-means
1.所有点作为⼀个簇
2.将该簇⼀分为⼆
3.选择能最⼤限度降低聚类代价函数(也就是误差平⽅和)的簇划分为两个
簇。
4.以此进⾏下去,直到簇的数⽬等于⽤户给定的数⽬k为⽌。
朴素贝叶斯
朴素:假设相互独立
应用:文章情感分析
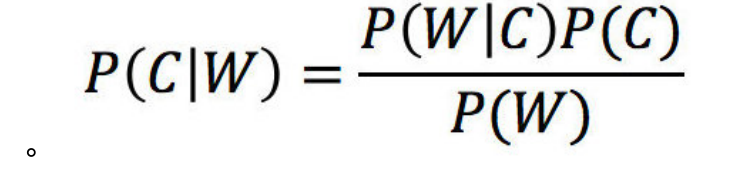
w是特征值(词的频数),c是文档类别

先验概率:根据之前的经验
后验概率:根据结果推原因(形式上同条件概率)
若出现概率为0则引入拉普拉斯平滑系数:


SVM
原理概述:寻找一个超平面使样本分成两类,并且间隔最大。
硬间隔:让所有实例都不在最大间隔之间。线性可分才有效
软间隔:有些数据在最大间隔之间甚至错误,但是间隔更宽,寻求平衡。C越大,惩罚系数越大,间隔越小。
核函数Φx:
矩阵的范数:1范数,各个元素绝对值之和
2范数:每个元素的平方和再开平方根
无穷范数:所有向量中绝对值最大或最小(对应正无穷范数和负无穷范数)
损失函数:注:x=0,y=1时无误差,y为别的数时,带入函数得到x,x距离0的距离为误差

核函数:特征值从低维空间到高维空间的映射

在属性空间中找到⼀些超圆,⽤这些超圆来判定正反类。
EM
⾸先根据⼰经给出的观测数据,估计出模型参数的值;
然后再依据上⼀步估计出的参数值估计缺失数据的值,再根据估计出的缺 失数据加上之前⼰经观测到的数据重新再对参数值进⾏估计;
然后反复迭代,直⾄最后收敛,迭代结束。
z值:表示硬币1还是硬币2
投掷5次x5组,z代表每组是1或者2(未知),为五个向量的矩阵
硬币1和2投掷出现正反面的几率不同
先随便给P1和P2赋值(P1和P2是硬币1或硬币2出现正面的概率),把P1,P2带到每组的结果里,选择较大的概率,Z就确定了。再按照分组的结果重新计算P1P2(用分得组里所有的正负值计算),不断迭代至收敛。
EM进阶版:(把P1,P2带到每组的结果里,选择较大的概率)这一步不选择较大的概率,而是乘以期望得权重,依次获得新的P1P2,迭代至收敛。
HMM
⻢尔科夫链即为状态空间中从⼀个状态到另⼀个状态转换的随机过程。当前状态只与上一个状态有关。
HMM说到的马尔科夫链其实是隐含状态链。隐含状态之间存在转换概率。
隐含状态和可见状态之间有一个概率叫输出概率。egD6掷出1的概率。
隐藏状态影响观察状态,上一个隐藏状态影响隐藏状态.
什么样的问题可以用HMM?
⼀类序列数据是可以观测到的,即观测序列;
⽽另⼀类数据是不能观察到的,即隐藏状态序列,简称状态序列。
拥有这两类数据,符合HMM模型
HMM的三种问题:
A:状态转移概率分布矩阵 下一个盒子选哪个概率
B:观测状态转移矩阵 下一个抽到哪个球概率
Π:初始状态分布矩阵 一开始选哪个盒子的概率
1)知道骰⼦有⼏种(隐含状态数量),每种骰⼦是什么(转换概率),根据掷骰 ⼦掷出的结果(可⻅状态链),我想知道每次掷出来的都是哪种骰⼦(隐含状态 链)。前向后向算法.掷出每一次骰子都要进行求和(3个隐藏状态)

2)还是知道骰⼦有⼏种(隐含状态数量),每种骰⼦是什么(转换概率),根据 掷骰⼦掷出的结果(可⻅状态链),我想知道掷出这个结果的概率。求最大值.维特比算法
3)(最常见)知道骰⼦有⼏种(隐含状态数量),不知道每种骰⼦是什么(转换概率),观 测到很多次掷骰⼦的结果(可⻅状态链),我想反推出每种骰⼦是什么(转换概 率)。前向算法:每一步的概率计算的是概率和.(解决:鲍姆韦尔奇算法 奇怪的EM有点看不懂emmm
奇怪的EM有点看不懂emmm
我们已知HMM模型的参数(前向算法中输入)λ=(A,B,Π)。
其中A是隐藏状态转移概率的矩阵,
(抽盒子的路径)
B是观测状态⽣成概率的矩阵,
(抽出来的结果)
Π是隐藏状态的初始概率分布
(一开始选择哪个盒子的概率)
要计算的结果是路径,也就是在哪个盒子里抽的。最可能的隐藏序列,最可能沿哪些盒子抽过来
XBOOST
决策树的⽣成和剪枝分别对应了经验⻛险最⼩化和结构⻛险最⼩化
XGBoost的决策树⽣成是结构⻛险最⼩化的结果,后续会详细介绍。
经验风险最小化容易复杂度较高,容易过拟合。
正则化,防止过拟合,结构风险最小化




XGBOOST分裂结点时采用贪心算法,分裂有增益就分,增益取最大(还要综合考虑分裂产生的空间成本)
XGBOOST考虑了树的复杂度,二阶导,选取切分的时候开启多线程,GBDT(梯度提升决策树)构建树没有考虑,但剪枝考虑.XGBOOST拟合上一轮损失函数的二阶导(准确率更高),GBDT一阶.XGBOOST在寻找切分点是能够多线程运行,速度更快.
LightGBM
- 基于Histogram(直⽅图)的决策树算法
先把连续的浮点特征值离散化成k个整数,同时构造⼀个宽度为k的直⽅图。 在遍历数据的时候,根据离散化后的值作为索引在直⽅图中累积统计量,当遍 历⼀次数据后,直⽅图累积了需要的统计量,然后根据直⽅图的离散值,遍历 寻找最优的分割点。使⽤直⽅图算法有很多优点。⾸先,最明显就是内存消耗的降低,直⽅图算法不仅 不需要额外存储预排序的结果,⽽且可以只保存特征离散化后的值,⽽这个值⼀般 ⽤8位整型存储就⾜够了,内存消耗可以降低为原来的1/8。不过分割点找的不准,但是影响不大. - Lightgbm 的Histogram(直⽅图)做差加速
⼀个叶⼦的直⽅图可以由它的⽗亲节点的直⽅图与它兄弟的直⽅图做差得到。 通常构造直⽅图,需要遍历该叶⼦上的所有数据,但直⽅图做差仅需遍历直⽅图的 k个桶。 利⽤这个⽅法,LightGBM可以在构造⼀个叶⼦的直⽅图后,可以⽤⾮常微⼩的代 价得到它兄弟叶⼦的直⽅图,在速度上可以提升⼀倍。 - 带深度限制的Leaf-wise的叶⼦⽣⻓策略
Leaf-wise则是⼀种更为⾼效的策略,每次从当前所有叶⼦中,找到分裂增益最⼤ 的⼀个叶⼦,然后分裂,如此循环。 因此同Level-wise相⽐,在分裂次数相同的情况下,Leaf-wise可以降低更多的 误差,得到更好的精度。
Leaf-wise的缺点是可能会⻓出⽐较深的决策树,产⽣过拟合。因此LightGBM
在Leaf-wise之上增加了⼀个最⼤深度的限制,在保证⾼效率的同时防⽌过拟 合。 - 直接⽀持类别特征
实际上⼤多数机器学习⼯具都⽆法直接⽀持类别特征,⼀般需要把类别特征,转化 到多维的0/1特征,降低了空间和时间的效率。 ⽽类别特征的使⽤是在实践中很常⽤的。基于这个考虑,LightGBM优化了对类别 特征的⽀持,可以直接输⼊类别特征,不需要额外的0/1展开。并在决策树算法上 增加了类别特征的决策规则。 在Expo数据集上的实验,相⽐0/1展开的⽅法,训练速度可以加速8倍,并且精度⼀ 致。⽬前来看,LightGBM是第⼀个直接⽀持类别特征的GBDT⼯具。 - 直接⽀持⾼效并⾏
LightGBM还具有⽀持⾼效并⾏的优点。LightGBM原⽣⽀持并⾏学习,⽬前⽀持特
征并⾏和数据并⾏的两种。 特征并⾏的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割
点,然后在机器间同步最优的分割点。
数据并⾏则是让不同的机器先在本地构造直⽅图,然后进⾏全局的合并,最后 在合并的直⽅图上⾯寻找最优分割点。
在特征并⾏算法中,通过在本地保存全部数据避免对数据切分结果的通信;
在数据并⾏中使⽤分散规约 (Reduce scatter) 把直⽅图合并的任务分摊到不同 的机器,降低通信和计算,并利⽤直⽅图做差,进⼀步减少了⼀半的通信量。
基于投票的数据并⾏(Voting Parallelization)则进⼀步优化数据并⾏中的通信
代价,使通信代价变成常数级别。在数据量很⼤的时候,使⽤投票并⾏可以得 到⾮常好的加速效果。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









