



常用SQL语句汇总
本篇文章主要为常见查询语句的汇总,有少量增、删、改的SQL语句。
目录:
SQL查询语句的语法结构:
select—from—where—group by—having—order by—limit
SQL查询语句的运行顺序:
from—where—group by—having—order by—limit—select
一、查询
videoGame
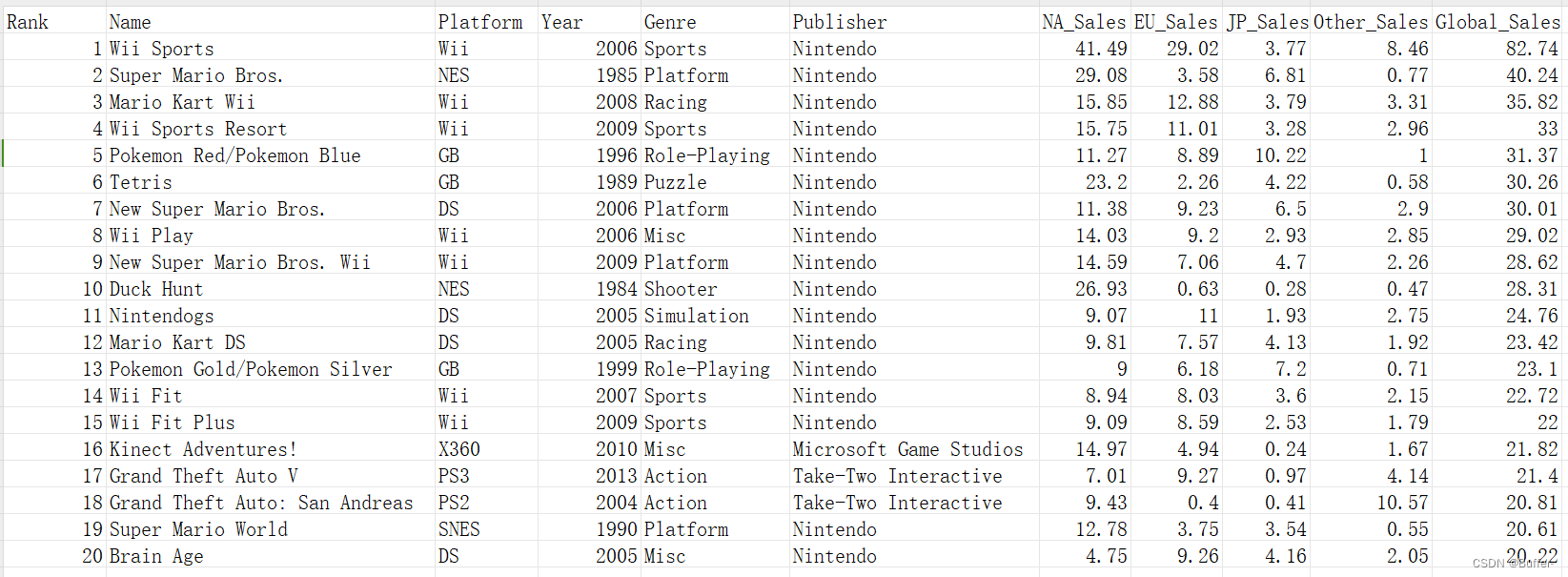
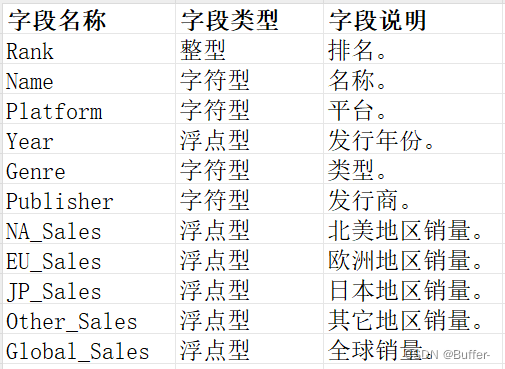
以下SQL语句除了表连接部分,其余均按照这张数据表写
1、select&from
select * from videoGame;
select Name, Platform from videoGame;
select Name as GameName, platform from videoGame; --重命名
select Name from videoGame where Global_Sales >= 30;
select distinct Publisher from videoGame; --Publisher字段重复的话,去重
select distinct Name, Platform, Genre from videoGame; --多个字段,去重重复放行数据
select name,NA_Sales/Global_Sales 北美地区销量占比 from videoGame;--加减乘除都能做
2、where
运算符:
= > < >= <= !=/<>
between and
in not in
is null is not null
and or not
select Name from videoGame where Global_Sales >= 30;
select Name, Global_Sales from videoGame where Global_Sales between 30 and 40;--[30,40]
--等价于
--select Name, Global_Sales from videoGame where Global_Sales >=30 and Global_Sales <= 40;
select Name, Global_Sales from videoGmae where Publisher='Nintendo';
select Name, Genre, Global_Sales from videoGame where Genre in ('Sports','Role-Playing','Rancing')--筛选出类型为体育、角色扮演和竞速类类的游戏
--等价于
--select Name, Genre, Global_Sales from videoGame where Genre = 'Sports' or Genre = 'Role-Playing' or Genre = 'Rancing';
select Name from videoGame where Name like 'W%';--模糊查询 %:任意多或0个字符 _:单个字符
select Name from videoGame where Name like '%w%' and Global_Sales >= 30;
select Name from videoGame where NA_Sales > 20 or (NA_Sales >10 and Global_Sales > 30);--不加括号也行,and优先级大于or
select Name, Global_Sales from videoGame where Global_Sales between 30 and 40 and Global_Sales != 40;--[30,40)
select Name from videoGame where Publisher like '%t%' and Publisher like '%e%' and Publisher not like '% %'; --Publisher中包含字母t和e的,且名称中没有空格的
select Name from videoGame where lower(Publisher) like '%t%' and lower(Publisher) like '%e%' and Publisher not like '% %'; --查询时不分大小写 upper是小写转大写
3、order by
--查询Name以W开头,Platform和Year,并按year由近到远排序,再按Platform升序
select Name, Platform, Year from videoGame where Name like 'W%' order by Year desc, Platform asc;--默认升序
--查询所有字段,Platform为GB和DS的放在最后,然后按照Year降序,Name升序
select *
from videoGame
order by
case
when Platform in ('GB','DS') then 1
else 0
end,
Year desc,
Name asc;
--在 ORDER BY 子句中,首先按照这个排序权重进行排序,因此 Platform 为 'GB' 或 'DS' 的记录会被排在后面(因为它们的排序权重是 1),而其他记录会被排在前面(因为它们的排序权重是 0)。
4、limit
select * from videoGame where year > 2000 order by Global_Sales desc limit 5;--返回前五行
--limit x,n 从第x+1行开始,返回n行
--在SQL中,行号是从1开始的。LIMIT 0, 10 表示从第 1 行开始,返回 10 行数据
5、聚合函数&group by
聚合函数:
| 函数 | 说明 |
|---|---|
| AVG() | 返回某列的均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列的和 |
count(*) 有多少行就是多少
count(字段名) 忽略空行
sum、avg、max、min函数必须必须指定字段进行聚合运算,无法使用通配符,同时这些指定字段的聚合函数都会忽略空值行
group by 提供聚合依据,依据哪个字段聚合
--计算表格行数
select count(*) from videoGame;
--查询各个Publisher的总Global_Sales
select Publisher, sum(Global_Sales) from videoGame group by Publisher;
--下面这个SQL语句的逻辑对于这张数据表来说,语法正确,但逻辑稍微有一些问题
select Name, max(Global_Sales)
from videoGame
where Publisher = 'Nintendo' GROUP BY Name;
--注:在标准的 SQL 中,如果一个查询中包含了聚合函数,那么 SELECT 子句中列出的列应该是聚合函数或者是 GROUP BY 子句中列出的列。所以,此句语法正确。
--但是,这样的查询会按照游戏名称(Name)分组,然后找出每个分组中 Global_Sales 的最大值。
--所以,如果想要查找到供应商为Nintendo的游戏中全球销量最大的游戏,并返回对应的游戏名和全球销量,可使用如下方法:
--子查询:
SELECT Name, Global_Sales
FROM videoGame
WHERE Publisher = 'Nintendo' and
Global_Sales = (
SELECT MAX(Global_Sales)
FROM videoGame
);
--窗口函数:
SELECT Name, Global_Sales
FROM (
SELECT Name, Global_Sales,
MAX(Global_Sales) OVER () AS max_global_sales
FROM videoGame
WHERE Publisher = 'Nintendo'
) AS max_sales_games
WHERE Global_Sales = max_global_sales;
--如果有多款游戏的全球销量都等于最大值,那么这个查询将会返回所有这些游戏。如果只想返回其中的一款,可以使用 LIMIT 1 或者在子查询中添加其他条件来确保只返回一个结果。
--查询Wii平台上每年每个产商的产品数量,按年份从大到小,数量从小到大排列。
select Year, Publisher, count(Name) from videoGame where Platform = ‘Wii’ group by Year,Publisher order by Year desc, count(Name) asc;
--group by子句中多个字段时,依据写的字段顺序,依次对字段分区
--使用group by子句的时候,select只能使用聚合函数和group by引用过的字段,否则会报错
--查询每个产商以及该产商的游戏中,全球销量大于25w的游戏数量
select Publisher, count(Name) 'number of game' from videoGame where Global_Sales > 25 group by publisher;
6、having
group by—having—order by
group by 聚合依据搞定后,再进行筛选
where是聚合前筛选,having是聚合后筛选
非聚合的字段用where筛选,聚合字段用having筛选
--查询游戏总数量大于5的产商
select Publisher from videoGame group by Publisher having count(Name)>5;
--查询总游戏数量大于2的平台和他的平均全球销量,其中全球销量大于25w且北美销量大于10w的游戏或者全球销量低于24w且游戏名以W开头的游戏计入计算,最后按游戏数,从大到小排序,只显示第一行
select Platform, avg(Global_Sales)
from videoGame
where (Global_Sales > 25 and NA_Sales > 10) or (Global_Sales < 24 and Name like 'W%')
group by Platform
having count(Name)>2
order by count(Name) desc
limit 1;
--查询平均游戏全球销量大于25w的平台以及它的游戏数,仅全球销量大于20w小于40w的游戏进行计算
select Platform, count(Name),avg(Global_Sales) from videoGame
where Global_Sales > 20 and Global_Sales < 40
group by Platform
having avg(Global_Sales)>25;
7、部分常见函数
| 函数 | 说明 |
|---|---|
| 数学函数: | |
| round(x,y) | 对x进行四舍五入,精确到小数点后y位 |
| y为负值的时候,保留小数点左边相应位数为0,不进行四舍五入 | |
| 例如:round(3.15,1)返回3.2 round(14.23,-1)返回10 | |
| 字符串函数: | |
| concat(s1,s2,…) | 连接字符串函数 |
| 任意参数为null时,返回null | |
| 例如:concat(‘My’,‘SQL’)返回mysql concat(‘My’,‘null’,‘SQL’)返回null | |
| replace(s,s1,s2) | 使用s2替换s中的s1 |
| 例如:replace(‘MysqlMysql’,‘sql’,‘SQL’)返回MySQLMySQL | |
| left(s,n) | 返回字符串s最左边的n个字符 |
| 例如:left(‘abcdefg’,3) 返回abc | |
| right(s,n) | 返回字符串s最右边的n个字符 |
| 例如:right(‘abcdefg’) 返回efg | |
| subString(s,n,len) | 返回字符串s从第n个字符起,取长度为len的子字符串,n为负值的时候,从倒数第n个起,取长度为len的子字符串,没有len值则取从第n个字符起到最后一位。 |
| 例如:subString(‘abcdefg’,2,3) 返回bcd subString(‘abcdefg’,-2,3) 返回 fg | |
| 数据类型转换函数: | |
| cast(x as type) | 转换数据类型函数 |
| cast函数将一个类型的x值转换成另一个类型的值 | |
| type参数可以填写char(n)/date/time/datetime/decimal等,转换为对应的数据类型 | |
| 日期时间函数: | |
| year(date) | date可以是年月日组成的日期,也可以是年月日,时分秒组成的日期 |
| 例如:year(‘2024-03-27’)返回2024 | |
| month(date) | date可以是年月日组成的日期,也可以是年月日,时分秒组成的日期 |
| 例如:month(‘2024-03-27’)返回3 | |
| day(date) | date可以是年月日组成的日期,也可以是年月日,时分秒组成的日期 |
| 例如:day(‘2024-03-27’)返回27 | |
| date_add(date,interval expr type) | date指定起始时间,可以是年月日组成的日期,也可以是年月日,时分秒组成的日期。 |
| date_sub(date,interval expr type) | expr用来指定从起始时间添加或减去的时间间隔 |
| type指示的是expr被解释的方式,type可以是以下值: | |
| SECOND、MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER、YEAR | |
| 例如:date_add(‘2024-03-27 18:28:00’, interval 1 second) 返回 2024-03-27 18:28:01 | |
| date_sub(‘2024-03-27 18:28:00’, interval 1 month) 返回 2024-02-27 18:28:00 | |
| datediff(date1,date2) | 计算两个日期之间的时间间隔天数 |
| datediff(‘2024-03-08’,‘2024-03-01’)返回7 | |
| datediff(‘2024-03-08 23:30:45’,‘2024-03-01 21:00:00’)返回7 | |
| datediff(‘2024-03-01’,‘2024-03-08’)返回-7 | |
| date_format(date,format) | 将日期和时间格式化 |
| 根据format指定格式显示date值 | |
| date_format(‘2018-06-01 16:23:12’,‘%b %d %Y %h:%i %p’)返回Jun 01 2018 04:23 PM | |
| date_format(‘2018-06-01 16:23:12’,‘%Y/%d/%m’)返回2018/01/06 | |
年-月-日(YYYY-MM-DD):'%Y-%m-%d' 月/日/年(MM/DD/YYYY): '%m/%d/%Y' 日-月-年(DD-MM-YYYY): '%d-%m-%Y' 年月日(YYYY年MM月DD日): '%Y年%m月%d日' 月份全名(March 25, 2024): '%M %d, %Y' 周几(Sunday, Monday, etc.): '%W' 24小时制时间(HH:MM:SS): '%H:%i:%s' 12小时制时间(hh:MM:SS AM/PM): '%h:%i:%s %p'缩写月名(Mar): %b | |
| 条件判断函数: | |
| if(expr,v1,v2) | 如果表达式expr是true返回值v1,否则返回v2 |
| 例如:if(1<2,‘Y’,‘N’)返回Y,if(1>2,‘Y’,‘N’)返回N | |
| case expr when v1 then r1 [when v2 then r2] …[else rn] end | 例如:case 2 when 1 then ‘one’ when 2 then ‘two’ else ‘more’ end 返回two |
| case when v1 then r1 [when v2 then r2]…[else rn] end | 例如:case when 1<0 then ‘T’ else ‘F’ end返回F |
--对全球销量做评估
select Name, Global_Sales,
case
when Global_Sales >= 20 and Global_Sales <= 30 then 'good'
when Global_Sales > 30 then 'really good'
else 'not good'
end as review
from videoGame
where Global_Sales > 0;
--以百分比的形式返回北美销量占比
select Name, concat(round((NA_Sales/Global_Sales)*100,2),'%') 北美销量占比
from videoGame
where Global_Sales > 0;
--查询游戏名称和平台名称都以相同字母开头的游戏及其平台,且不能包括游戏名称和平台名称完全相同的情况
select Name, Platform from videoGame
where left(Name,1) = left(Platform,1) and Name != Platform;
--查询游戏名和平台名,其中游戏名是由平台名开头命名的,且是平台名的扩展
select Name, Platform from videoGame
where Name like concat(Platform,'%') and Name != Platform;
8、窗口函数
over([partition by 字段名] [order by 字段名 asc|desc])
over()中两个子句为可选项,partition by指定分区依据,order by指定排序依据
排序窗口函数:
-
rank() over()
rank():跳跃式排序——例如:99、99、90、89 通过此函数得到的排名为:1 、1 、3 、4
-
dense_rank() over()
dense_rank():并列连续型排序 ——例如:99、99、90、89 通过此函数得到的排名为:1 、1 、2 、3
-
row_number() over()
row_number():连续型排序——例如:99、99、90、89 通过此函数得到的排名为:1 、2 、3、4
偏移分析函数:
- LAG(column, offset, default_value) OVER (PARTITION BY … ORDER BY …)
column是要获取前一个行的值的列名。offset是指定向前偏移的距离,可以是正数或负数。正数是前,复数是后default_value是可选的,用于在找不到前一个行时返回的默认值。ORDER BY子句指定了窗口函数计算时的排序规则。
- LEAD(column, offset, default_value) OVER (PARTITION BY … ORDER BY …)
column是要获取前一个行的值的列名。offset是指定向前偏移的距离,可以是正数或负数。正数是后,复数是前default_value是可选的,用于在找不到前一个行时返回的默认值。ORDER BY子句指定了窗口函数计算时的排序规则。
LEAD(Global_Sales, 1, 0) 与 LAG(Global_Sales, -1, 0) 是等价的,都表示获取当前行的后一个行的 Global_Sales 值,如果找不到后一个行,则返回默认值 0。
窗口函数中,如果本身只有一个分区,就不用写partition by
排序窗口函数:
--查询每年Nintendo产商的游戏所在的平台,以及其平台的全国总销量,并按照总销量赋予名次,同一年份不同平台进行比较。最后根据平台和年份进行升序排序
select Year, Platform, sum(Global_Sales),
rank() over(partition by Year order by sum(Global_Sales) desc) as posn
from videoGame
where Publisher = 'Nintendo'
group by Year,Platform
order by Platform, year;
--可以理解为正常流程走完,也就是排序完,进行select的时候,发现窗口函数,重新回到having之后,order by之前,复制表格,执行窗口函数,匹配标签,回到select。赋予序号
窗口函数只能写在select子句中
窗口函数中的partition by 子句可以指定数据的分区,和group by去重分组不同的是group by只分区不去重
窗口函数中没有partition by子句时,即不对数据分区,直接将整个表为一个区
排序窗口函数中order by子句时必填项,窗口函数中,order by子句在分区内,依据指定字段和排序方法对字段进行排序。
偏移窗口函数:
--查询Nintendo和Take-Two Interactive每年游戏的全球总销量,表中上一年游戏的全球总销量,以及与表中上一年游戏全球总销量的差,最后按产商和年份正序
select Publisher, Year,
sum(Global_Sales) as Current_Year_Global_Sales,
lag(sum(Global_Sales),1,0) over(partition by Publisher order by Year) as Last_Year_Global_Sales,
sum(Global_Sales)-lag(sum(Global_Sales),1,0) over(partition by Publisher order by Year) as Difference
from videoGame
where Publisher in ('Nintendo', 'Take-Two Interactive')
group by Publisher, Year
order by Publisher, Year
周同比 lag(xxx,7)
9、表连接
1、内连接
- select 字段名 from 表名1 inner join 表名2 on 表名1.字段名 = 表名2.字段名
- 注意内连接inner可以省略,直接使用join默认为内连接
2、左连接
- select 字段名 from 表名1 left join 表名2 on 表名1.字段名 = 表名2.字段名
- 左表完整,右表空值补null
3、右连接
- select 字段名 from 表名1 right join 表名2 on 表名1.字段名 = 表名2.字段名
- 右表完整,左表空值补null
表连接的SQL换如下的数据表进行:
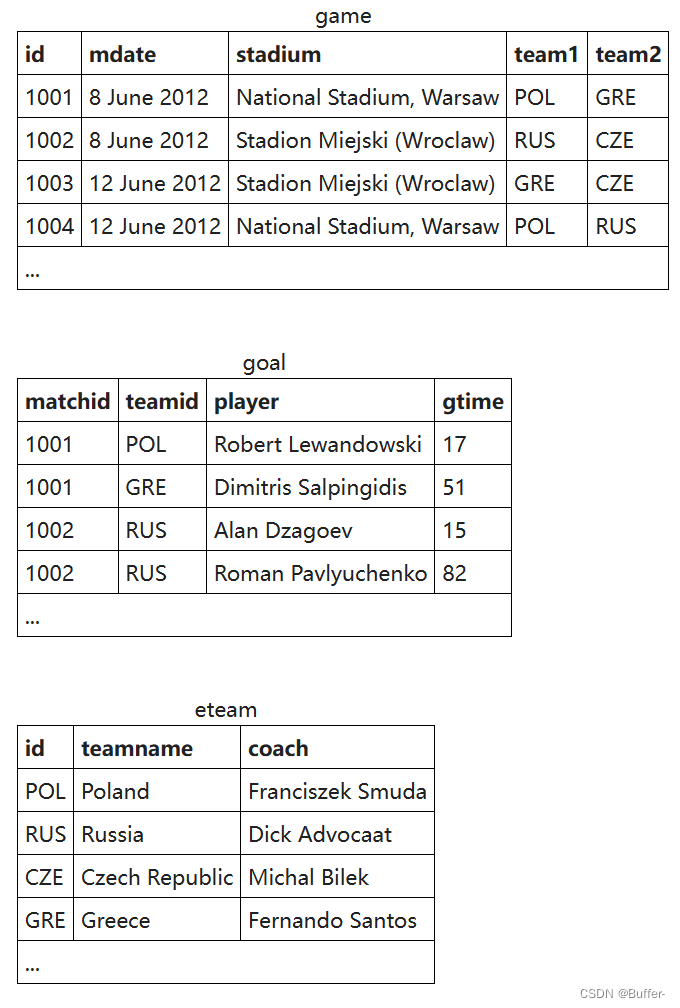
game:
记录赛事的表
- id-编号-赛事编号
- mdate-日期-举办赛事的日期
- stadium-场馆-赛事场馆
- team1-队伍1-参与赛事队伍1
- team2-队伍2-参与赛事队伍2

goal:
记录球员进球得分的表
- matchid-赛事编号
- teamid-队伍编号-入球球员所在的队伍编号
- player-入球球员
- gtime-入球时间-比赛开始到入球时间的分钟数
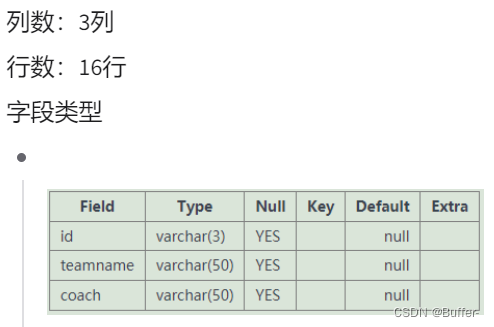
eteam:
队伍表
- id-编号-队伍编号
- teamname-队名-队伍名字
- coach-教练-队伍的教练
-- 查询有球员名叫Mario进球的队伍1(team1),队伍2(team2)及球员姓名
select team1, team2, player
from game inner join goal on game.id = goal.matchid
where player like 'Mario%';
--查询队伍1(team1)的教练是“Fernando Santos”的球队名称(teamname)、比赛日期(mdate)和赛事编号(id)
select teamname, mdate, game.id
from game join eteam on game.team1 = eteam.id
where coach = 'Fernando Santos'
--查询在比赛前十分钟有进球记录的球员,他的队伍编号(teamid),教练(coach), 进球时间(gtime)
select player, teamid, coach, gtime
from goal join eteam on goal.teamid = eteam.id
where gtime<10
--查询每场比赛,每个球队的得分情况
select game.mdate, game.team1,
sum(case when game.team1=goal.teamid then 1 else 0 end) score1,
game.team2,
sum(case when game.team2=goal.teamid then 1 else 0 end) score2
from game left join goal on game.id = goal.matchid
group by game.mdate, game.team1,game.team2
order by game.mdate, goal.matchid, game.team1, game.team2
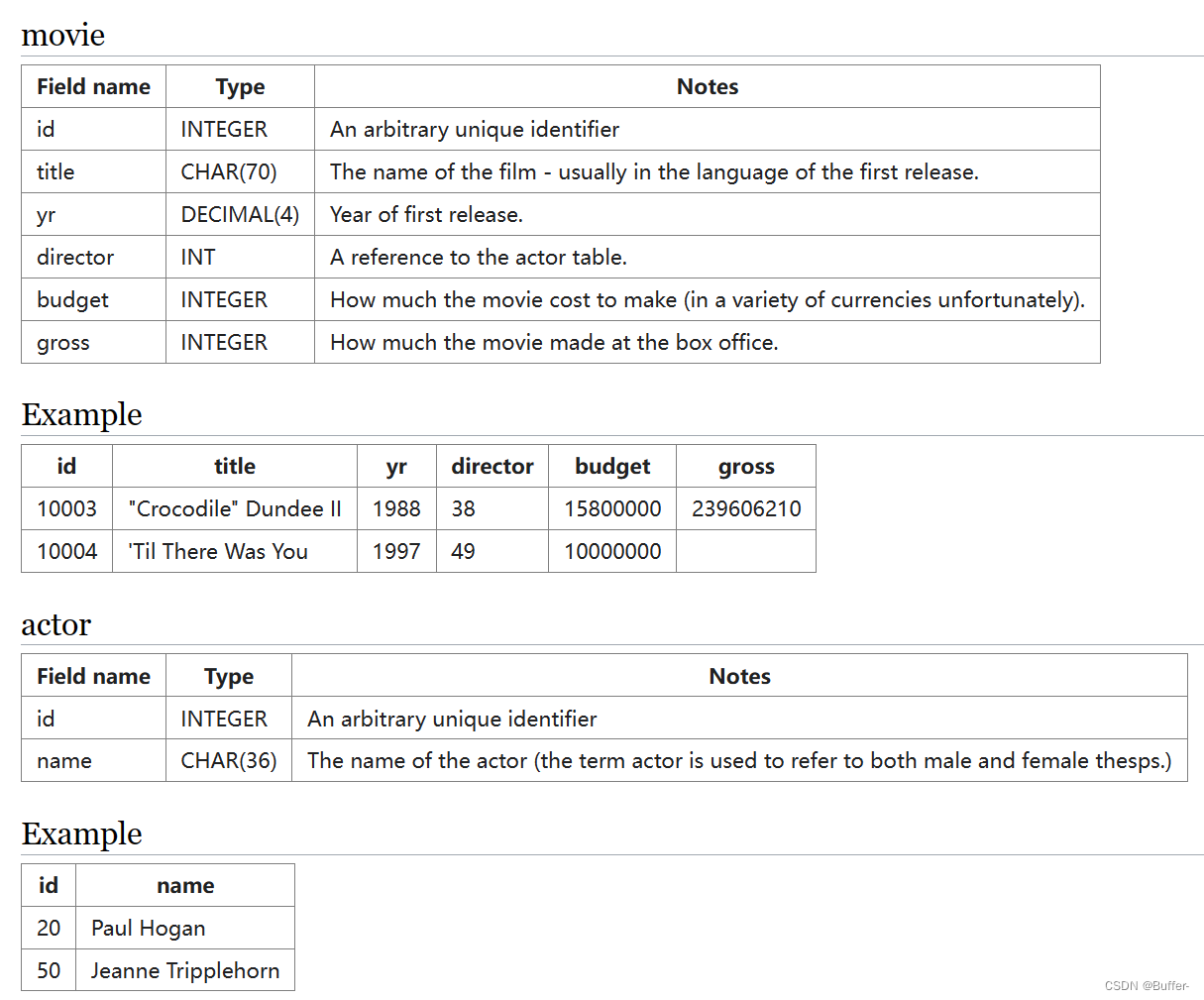
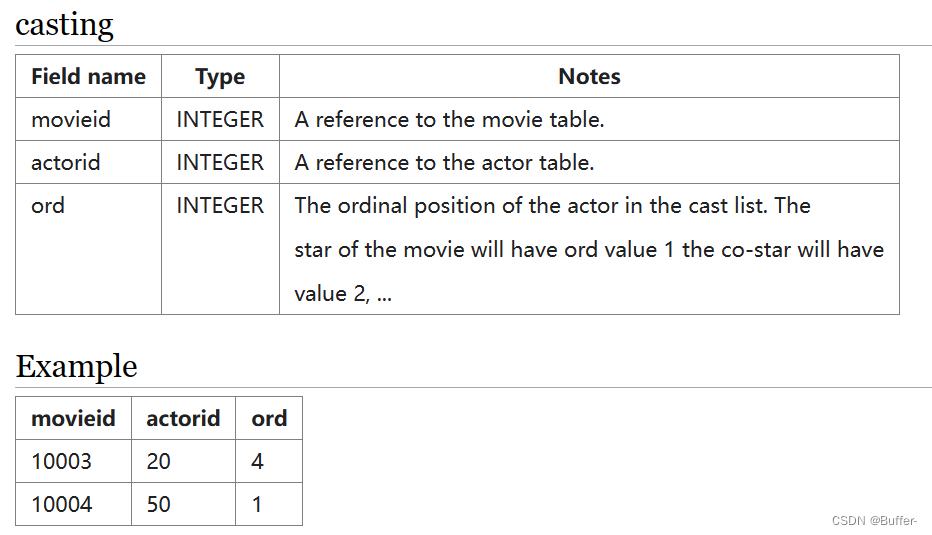
--查询至少出演过第1主角30次的演员名
select name
from actor join casting on actor.id = casting.actorid
where ord = 1
group by name
having count(movieid) >= 30;
10、子查询
这里还是使用videoGame表进行SQL编写
--查询出全球销量高于GB平台中每款游戏的所有游戏名,排除全球销量为null的游戏
select Name from videoGame
where Global_Sales is not null
and Global_Sales >
(select max(Global_Sales) from videoGame where Platform = 'GB')
--查询和Wii Sports和Grand Theft Auto: San Andreas同一个产商的所有游戏名,及其所属得到产商,并按照游戏名名进行排序
select Name, Publisher from videoGame
where Publisher in (select Publisher from videoGame where Name in('Wii Sports','Grand Theft Auto: San Andreas'))
order by Name;
--查询2006年所有出自于Nintendo的游戏所在的平台及其类型,获胜游戏即为各平台中全球销量最高的游戏
select Platfrom, Genre from
(
select Platform, Genre, Global_Sales,
rank() over(partition by Platform order by Global_Sales desc) as posn
from videoGame
where Year = 2006 and Publisher = 'Nintendo'
)as rk
where rk.posn = 1;
--查询Nintendo所制作的游戏中,北美销量占比大于Wii Sports Resort的游戏
select Name from videoGame
where NA_Sales/Global_Sales >
(
select NA_Sales/Global_Sales from videoGame where Name='Wii Sports Resort'
) and Publisher = 'Nintendo';
--查询平台拥有的游戏数大于X360小于Wii的平台,结果显示平台名,及其所拥有的游戏数
select Platform, count(Name) from videoGame
group by Platform
having count(Name)>(select count(Name) from videoGame where Platform = 'X360')
and count(Name)<(select count(Name) from videoGame where Platform = 'Wii');
--查询平台内所有游戏的北美销量占比大于40%的平台,以及其北美销量占比和游戏名
select Platform, NA_Sales/Global_Sales, Name from videoGame
where Platform in
(select distinct Platform from videoGame where NA_Sales/Global_Sales > 0.4);
--查找每个平台中全球销量最大的游戏,显示平台,游戏名,销量
select Platform, Name, Global_Sales from videoGme
where (Platform,Global_Sales) in
(select Platfrom max(Global_Sales) from videoGame group by Platform);
--查询游戏产商为Nintendo和Take-Two Interactive所在的平台每年新增全球销量,并从高到低排名,查询结果显示游戏产商,年份,每年新增全球销量,排名,按排名正序
select Publisher, Year, Increment,
rank() over(Partition by Publisher order by Increment) as posn
from(
select Publisher, Year,
(Global_Sales - lag(Global_Sales,1,0) over(Partition by Publisher order by Year)) as Increment
from videoGame
where Publisher in ('Nintendo','Take-Two Interactive')
) as re
order by posn;
二、增加
--创建数据库
create database Job;
--查看数据库
show databases;
--查看数据库中的所有表
show tables;
--创建数据表
create table employees(
id int primary key,
name varchar(100),
age INT,
salary deciaml(10,2)--该列存储的数值可以包含最多 8 位整数部分和 2 位小数部分。
);
--插入数据
insert into employees (id, name, age, salary)
value
(1, 'John Doe', 30, 50000.00),
(2, 'Jane Smith', 25, 60000.00),
(3, 'Mike Johnson', 35, 70000.00);
--覆盖写入
insert overwrite table emplayees_salary --这里假设emplayees_salary已经创建好了
select id, name, salary from employees;
三、修改
--修改值
update employees
set salary = 60000.00, age = 35
where id =1;
--修改表中的列名,理论讲不能直接修改,可以先创一个新表,然后用select将旧表的内容提出写入新表,然后删除旧表,并重命名新表
--删除旧表重命名新表的SQL:
drop table employees;
alter table employees_new rename to employees;
四、删除
--删除某一列
alter table employees
drop column age,
drop column salary;
--删除某一行
delete from employees where id = i;
--删除整张表
drop table employees;
--删除数据库
drop datebase Job;
本文参考:
戴师兄数据分析课SQL部分

















 8528
8528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









