







 !-- 配置连接池 -- > < bean id = "masterDataSource" class = "com.jolbox.bonecp.BoneCPDataSource" destroy-method = "close" >
!-- 配置连接池 -- > < bean id = "masterDataSource" class = "com.jolbox.bonecp.BoneCPDataSource" destroy-method = "close" >
1. 背景
我们一般应用对数据库而言都是“读多写少”,也就说对数据库读取数据的压力比较大,有一个思路就是说采用数据库集群的方案,
其中一个是主库,负责写入数据,我们称之为:写库;
其它都是从库,负责读取数据,我们称之为:读库;
那么,对我们的要求是:
1、 读库和写库的数据一致;
2、 写数据必须写到写库;
3、 读数据必须到读库;
2. 方案
解决读写分离的方案有两种:应用层解决和中间件解决。
2.1. 应用层解决:
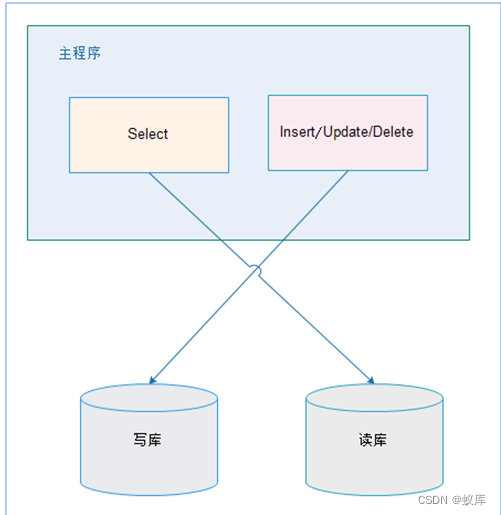
优点:
1、 多数据源切换方便,由程序自动完成;
2、 不需要引入中间件;
3、 理论上支持任何数据库;
缺点:
1、 由程序员完成,运维参与不到;
2、 不能做到动态增加数据源;
2.2. 中间件解决
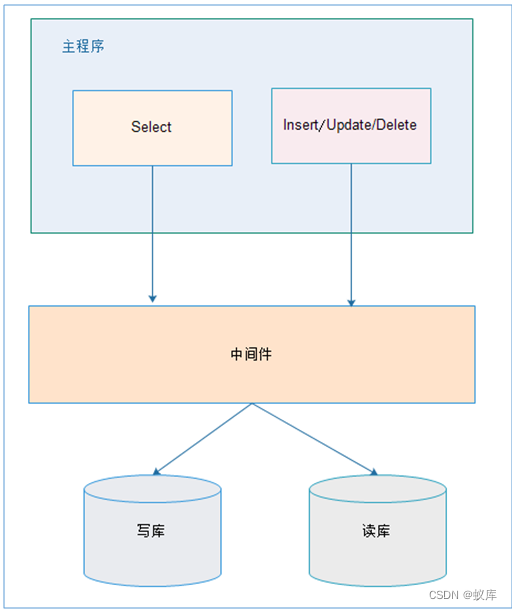
优缺点:
优点:
1、 源程序不需要做任何改动就可以实现读写分离;
2、 动态添加数据源不需要重启程序;
缺点:
1、 程序依赖于中间件,会导致切换数据库变得困难;
2、 由中间件做了中转代理,性能有所下降;
相关中间件产品使用:
mysql-proxy:http://hi.baidu.com/geshuai2008/item/0ded5389c685645f850fab07
Amoeba for MySQL:http://www.iteye.com/topic/188598和http://www.iteye.com/topic/1113437
3. 使用Spring基于应用层实现
3.1. 原理
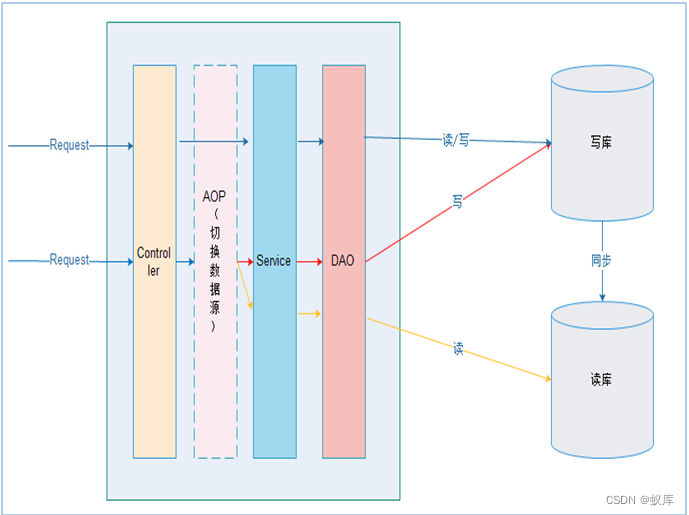
在进入Service之前,使用AOP来做出判断,是使用写库还是读库,判断依据可以根据方法名判断,比如说以query、find、get等开头的就走读库,其他的走写库。
3.2. DynamicDataSource
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
/**
* 定义动态数据源,实现通过集成Spring提供的AbstractRoutingDataSource,只需要实现determineCurrentLookupKey方法即可
*
* 由于DynamicDataSource是单例的,线程不安全的,所以采用ThreadLocal保证线程安全,由DynamicDataSourceHolder完成。
*
* @author yangbingwen
*
*/
public class DynamicDataSource extends AbstractRoutingDataSource{
@Override
protected Object determineCurrentLookupKey() {
// 使用DynamicDataSourceHolder保证线程安全,并且得到当前线程中的数据源key
return DynamicDataSourceHolder.getDataSourceKey();
}
}
3.3. DynamicDataSourceHolder
/**
*
* 使用ThreadLocal技术来记录当前线程中的数据源的key
*
* @author yangbingwen
*
*/
public class DynamicDataSourceHolder {
//写库对应的数据源key
private static final String MASTER = "master";
//读库对应的数据源key
private static final String SLAVE = "slave";
//使用ThreadLocal记录当前线程的数据源key
private static final ThreadLocal<String> holder = new ThreadLocal<String>();
/**
* 设置数据源key
* @param key
*/
public static void putDataSourceKey(String key) {
holder.set(key);
}
/**
* 获取数据源key
* @return
*/
public static String getDataSourceKey() {
return holder.get();
}
/**
* 标记写库
*/
public static void markMaster(){
putDataSourceKey(MASTER);
}
/**
* 标记读库
*/
public static void markSlave(){
putDataSourceKey(SLAVE);
}
}
3.4. DataSourceAspect
import org.apache.commons.lang3.StringUtils;
import org.aspectj.lang.JoinPoint;
/**
* 定义数据源的AOP切面,通过该Service的方法名判断是应该走读库还是写库
*
* @author yangbingwen
*
*/
public class DataSourceAspect {
/**
* 在进入Service方法之前执行
*
* @param point 切面对象
*/
public void before(JoinPoint point) {
// 获取到当前执行的方法名
String methodName = point.getSignature().getName();
if (isSlave(methodName)) {
// 标记为读库
DynamicDataSourceHolder.markSlave();
} else {
// 标记为写库
DynamicDataSourceHolder.markMaster();
}
}
/**
* 判断是否为读库
*
* @param methodName
* @return
*/
private Boolean isSlave(String methodName) {
// 方法名以query、find、get开头的方法名走从库
return StringUtils.startsWithAny(methodName, "query", "find", "get");
}
}
3.5. 配置2个数据源
3.5.1. jdbc.properties
jdbc.master.driver=com.mysql.jdbc.Driver
jdbc.master.url=jdbc:mysql://127.0.0.1:3306/mybatis_1128?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
jdbc.master.username=root
jdbc.master.password=123456
jdbc.slave01.driver=com.mysql.jdbc.Driver
jdbc.slave01.url=jdbc:mysql://127.0.0.1:3307/mybatis_1128?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
jdbc.slave01.username=root
jdbc.slave01.password=123456
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 959
959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











