







一、B树的特点
B树也叫多路平衡查找树,它有如下特点:
- 每个结点最多有m-1个关键字(m指阶数,阶代表B树中所有节点的孩子个树的最大值),至少有m棵子树;
- 根节点最少可以只有1个关键字(若根节点为非终端结点,最少有两棵子树);
- 非根节点至少有⌈m/2⌉-1个关键字;
- 每个结点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它;
- 所有叶子节点都位于同一层,并且不携带信息(即绝对平衡);
- 每个节点都存有索引和数据,也就是对应的key和value。
关键字数量范围:根节点:1~m-1;非叶节点:⌈m/2⌉-1~m-1
二、B树的查找
B树查找包含两个基本操作:
- 在B树中找节点;
- 在结点中找关键字。
B树的查找和二叉排序树很相似,可以看作是二叉排序树的扩展,二叉排序树是二路查找,B树是多路查找,因为B树结点内的关键字是有序的,在结点内进行查找时除了顺序查找外,还可以用折半查找来提升效率。B树的具体查找步骤如下(假设查找的关键字为key):
- 从根结点开始,在结点包含的关键码中查找给定的关键码,找到则查找成功;
- 否则确定给定关键码可能在的子树,重复上面的操作,直到查找成功或者指针为空为止。
三、B树的插入
规则:
判断当前结点key的个数是否小于等于m-1,
- 若满足,则直接插入;
- 若不满足,将结点的中间的key将这个结点分为左右两部分,中间的结点放到父节点中。
举例
在5阶B树中,结点最多有4个key,最少有2个key
(1) 插入18,70,50,40

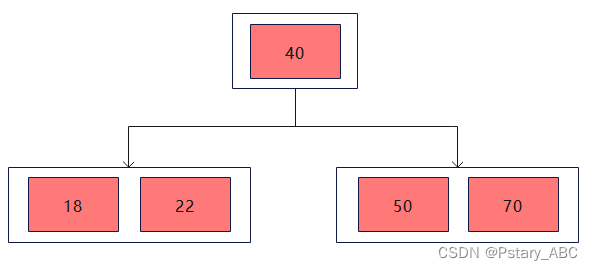
(2) 插入22

因为B树的阶为5,所以每个节点的key最多只有4个,而此时插入22之后根节点中有5个key,因此需要进行分裂:
(3) 插入23,25,39
插入的3个数据都比根节点40要大,因此都插入到左节点当中:
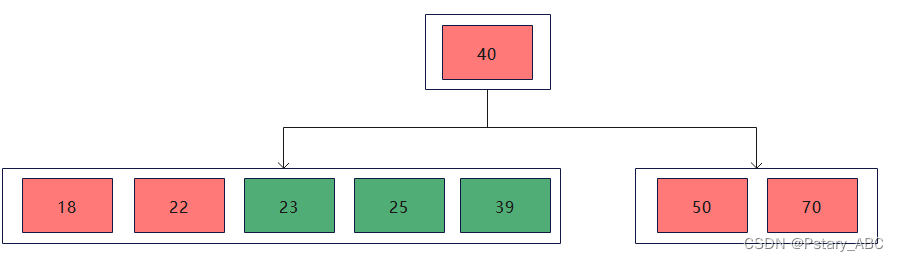
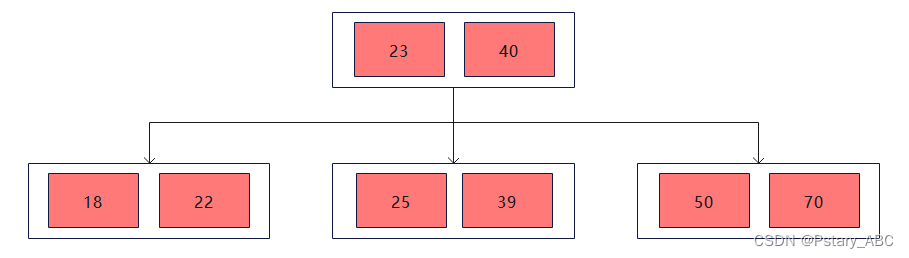
插入结点之后,左节点中的关键字已经超过了最大能包含的关键字数,因此需要进行分裂,将23放到父节点当中:
四、B树的删除
-
当被删的关键字k不在终端节点时(最底层的非叶结点)中时,用k的前驱(或后继)k’来替代k,然后在相应的结点中删除k’,关键字k’必定落在某个终端节点中,则转换成了被删关键字在终端节点中的情形。
-
当被删关键字在终端结点中时,有三种情况:
(1) 直接删除关键字。若被删关键字所在结点的关键字个数>=⌈m/2⌉,表明删除该关键字之后仍然满足B树的定义,则直接删去该关键字。
(2) 兄弟够借。若被删关键字所在结点删除前的关键字个数=⌈m/2⌉-1,且与该节点相邻的右(或左)兄弟结点的关键字个数>=⌈m/2⌉,则需要调整该节点、右(或左)兄弟结点及其双亲结点(父子换位法),以达到新的平衡。
(3) 兄弟不够借。若被删关键字所在结点删除前的关键字个数=⌈m/2⌉-1,且此时与该节点相邻的右、左兄弟结点的关键字个数均=⌈m/2⌉-1,则将关键字删除后与左(或右)兄弟结点即双亲结点中的关键字进行合并。
在合并过程中,双亲结点的关键字个数会减1。若其双亲结点是根节点且关键字个数减少至0(根节点关键字个数为1时,有2棵子树),则直接将根节点删除,合并后的新节点成为根节点;若双亲结点不是根节点,且关键字个数减少到⌈m/2⌉-2,则又要与他自己的兄弟节点进行调整或合并操作,并重复上述步骤,直至符合B树的要求为止。
举例:下面是一棵5阶B树,则非根节点关键字个数范围为:2~4
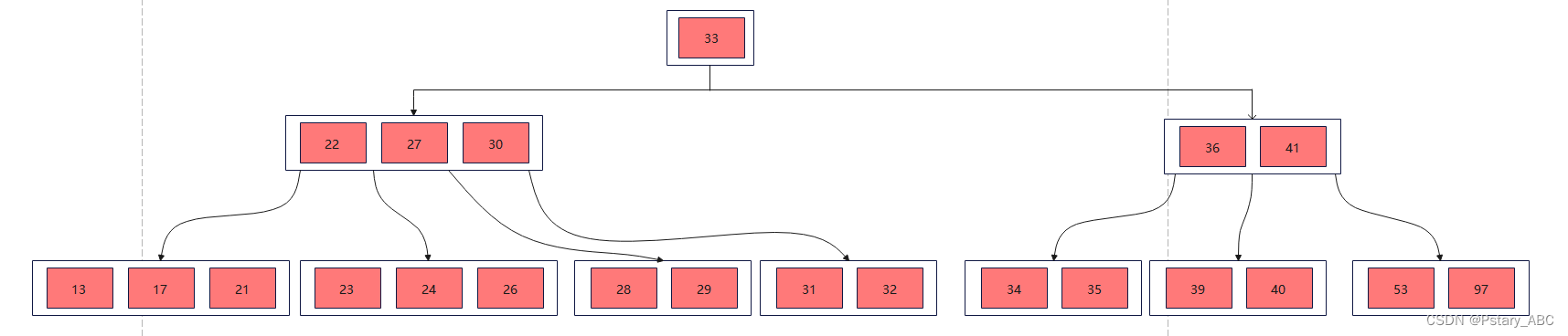
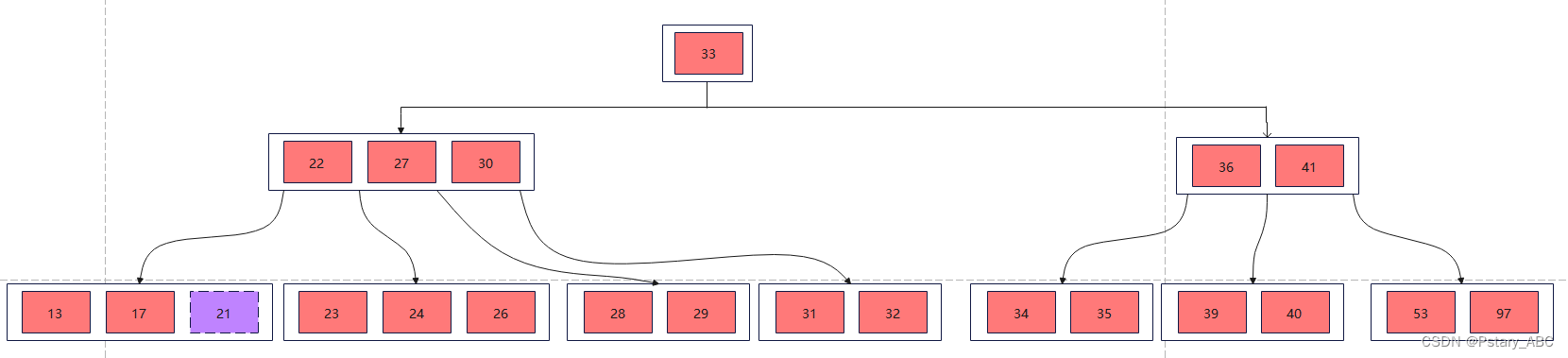
(1)删除21,此时删除的是终端节点关键字,删除之后结点关键字数为2,大于>=⌈m/2⌉-1,可以直接删除:(紫色代表被删除的元素)
(2)删除27,此时删除的结点为非终端节点关键字,需要用他的前驱或者后继元素覆盖要删除的关键字(这里选择的是后继元素28),然后在后继关键字所在的分支中将该后继关键字删除。
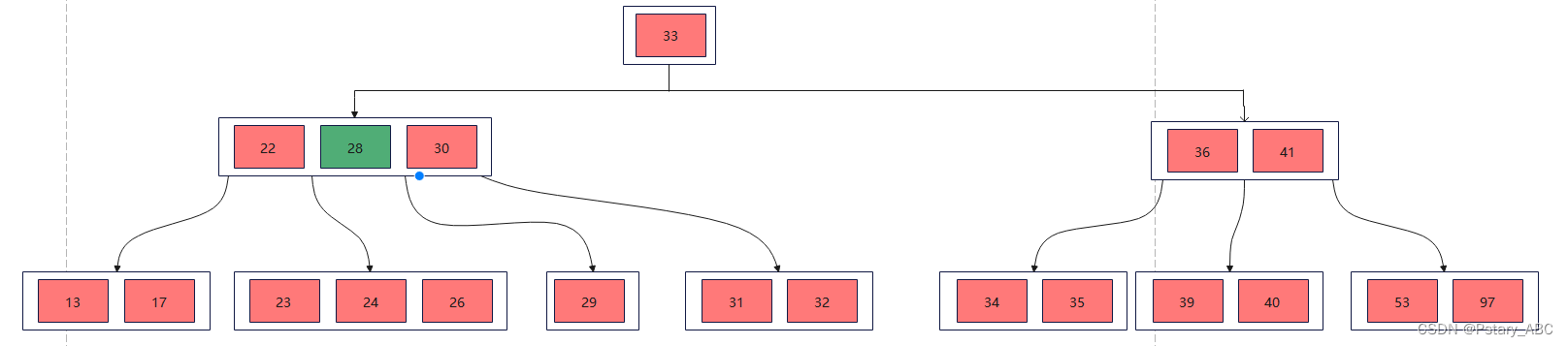
但是删除27之后,后继关键字所在的分支只留下29一个关键字,关键字的个数<⌈m/2⌉-1,而他的左兄弟结点元素个数>=⌈m/2⌉,则先将父节点的元素移到该节点,再将兄弟节点的元素移动到父节点:
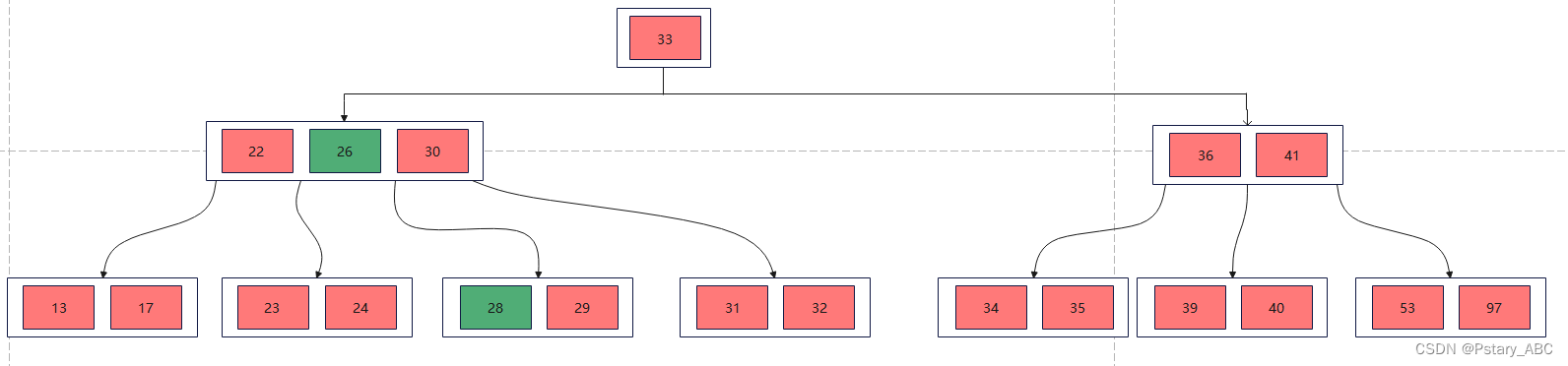
(3)删除32,删除的为终端节点关键字,删除32之后其所在的结点关键字个数<⌈m/2⌉-1,并且他的兄弟节点没有多余的元素可以借。首先将父节点的元素移到该节点,然后将当前节点与兄弟节点合并,形成新节点。
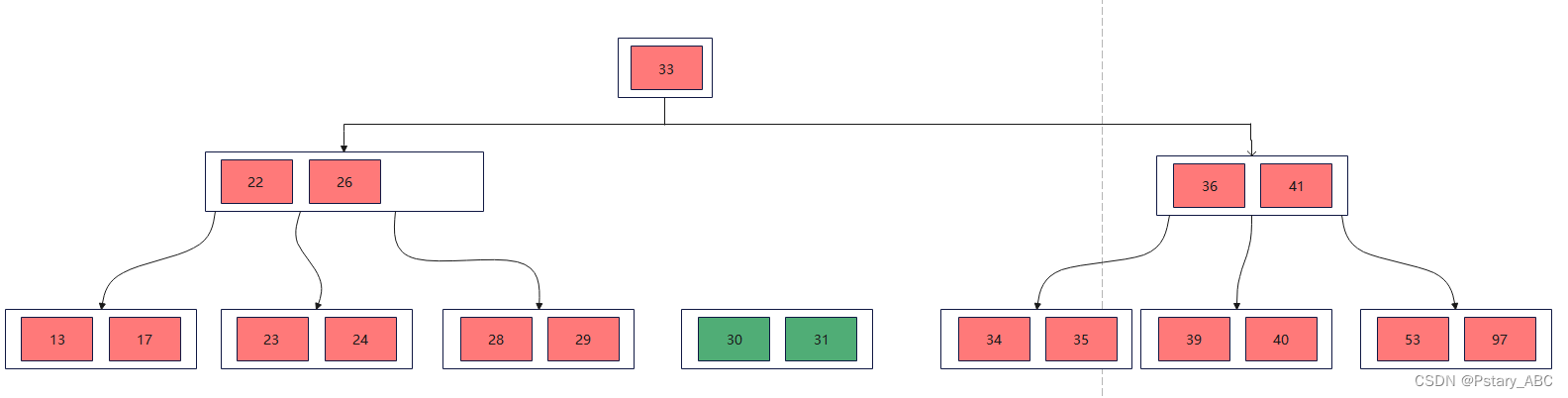
将当前结点与兄弟节点合并:
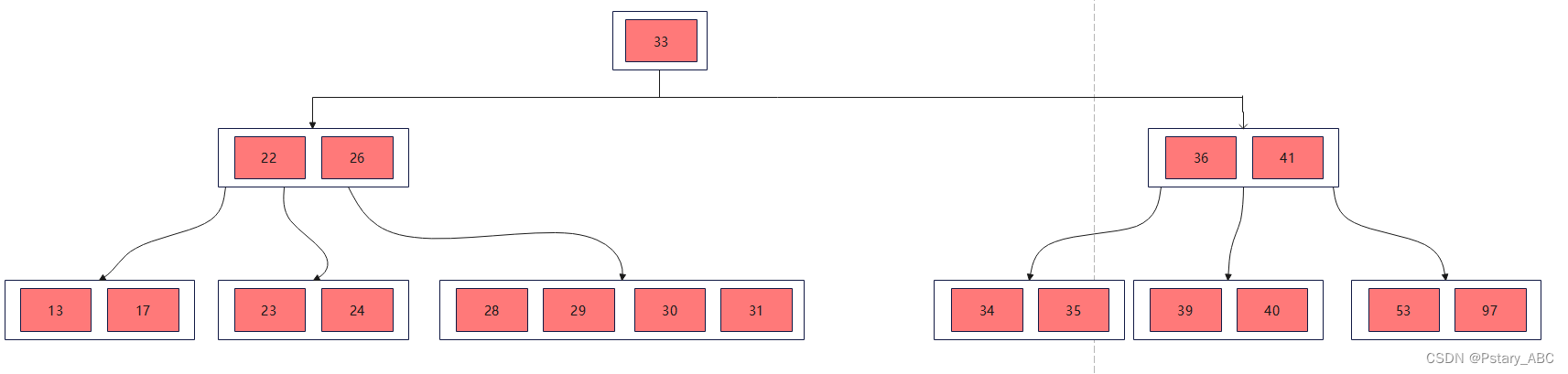
(4)删除40,删除的为终端节点关键字,删除40之后其所在的结点关键字个数<⌈m/2⌉-1,并且他的兄弟节点没有多余的元素可以借。首先将父节点的元素移到该节点,然后将当前节点与兄弟节点合并,形成新节点。
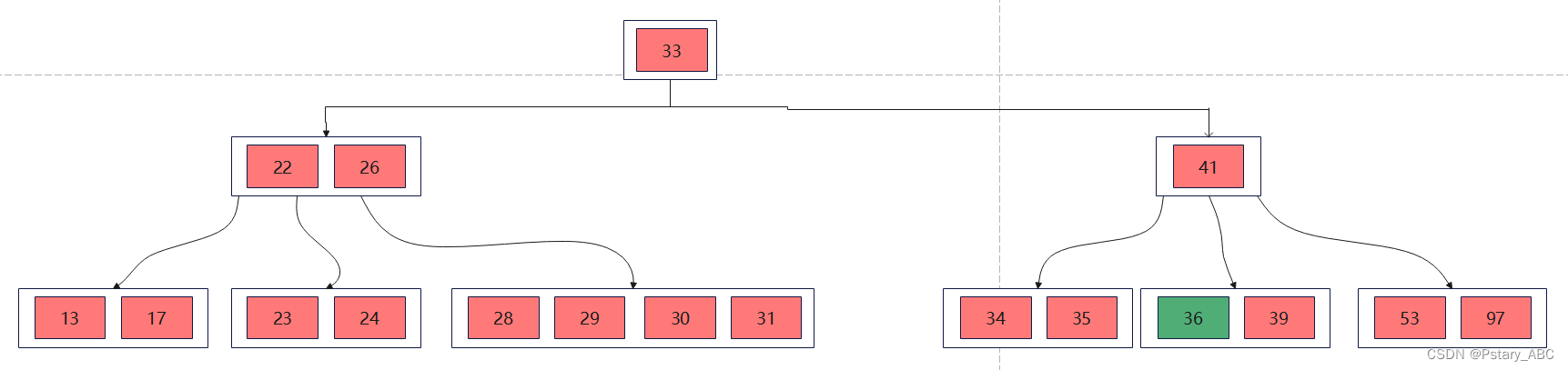
与兄弟结点合并:
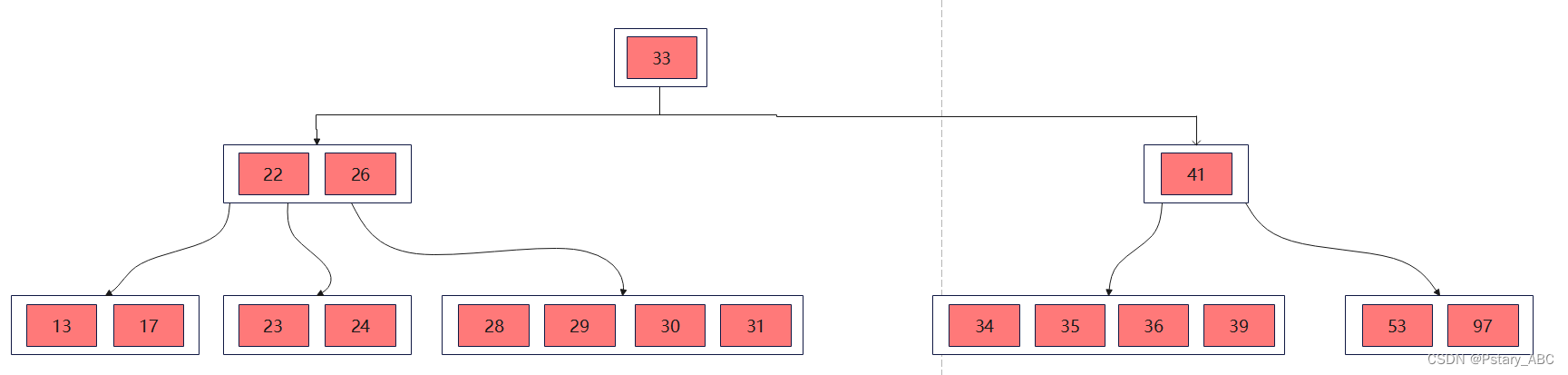
而父节点此时并不满足条件,且它的兄弟并没有多余的关键字可以给他,因此将父节点的父节点中的关键字移动到父节点当中,并且和兄弟节点合并:

此时父节点的父节点关键字个数减少至0,则直接将父节点的父节点删除,合并后的父节点成为根节点。
五、B树的使用场景40
用作文件系统的索引。
六、B树的优点
B树和二叉树、红黑树相比,子树更多,树的高度更低,搜索效率更高。若子树太多就可能变成一个有序数组,所以不能无限增加子树数量,因为文件系统和数据库一般都是存在电脑硬盘上的,若数据量太大不一定能一次性加载到内存中,但是B树可以多路存储,因此在文件查找时每次只加载一个结点的内容存入内存来查找,而红黑树在内存中查找非常快,但是在数据库和文件系统中,B树更优。















 1238
1238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









