







1、combiner运行机制:
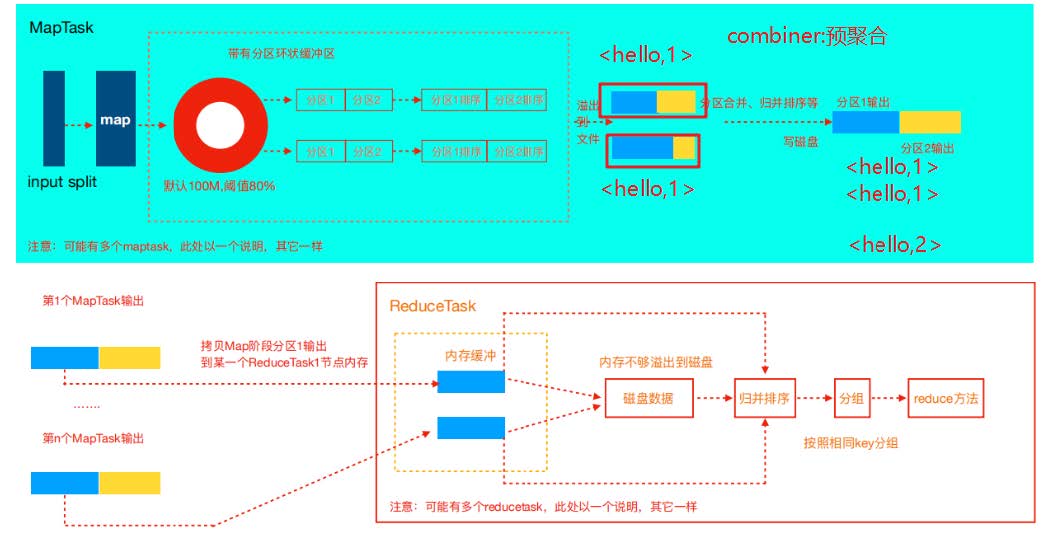
- Combiner是MR程序中Mapper和Reducer之外的一种组件
- Combiner组件的父类就是Reducer
- Combiner和reducer的区别在于运行的位置
- Combiner是在每一个maptask所在的节点运行;
- Combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量。
- Combiner能够应用的前提是不能影响最终的业务逻辑,此外,Combiner的输出kv应该跟reducer的输入kv类型要对应起来。
举例说明
假设一个计算平均值的MR任务
Map阶段
2个MapTask
MapTask1输出数据:10,5,15 如果使用Combiner:(10+5+15)/3=10
MapTask2输出数据:2,6 如果使用Combiner:(2+6)/2=4
Reduce阶段汇总
(10+4)/2=7而正确结果应该是
(10+5+15+2+6)/5=7.6
自定义Combiner实现步骤
- 自定义一个Combiner继承Reducer,重写Reduce方法
- 在驱动(Driver)设置使用Combiner(默认是不适用Combiner组件)
2、改造WordCount程序
MapReduce编程规范及示例编写_悠然予夏的博客-CSDN博客
package com.lagou.mr.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
// combiner组件的输入和输出类型与map()方法保持一致
public class WordCountCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable total = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 进行局部汇总,逻辑是与reduce方法保持一致(遍历key对应的values,然后累加结果)
int num = 0;
for (IntWritable value : values) {
int i = value.get();
num += 1;
}
// 直接输出当前key对应的sum值,结果就是单词出现的总次数
total.set(num);
context.write(key, total);
}
}
在驱动(Driver)设置使用Combiner
job.setCombinerClass(WordcountCombiner.class);验证结果:
观察程序运行日志
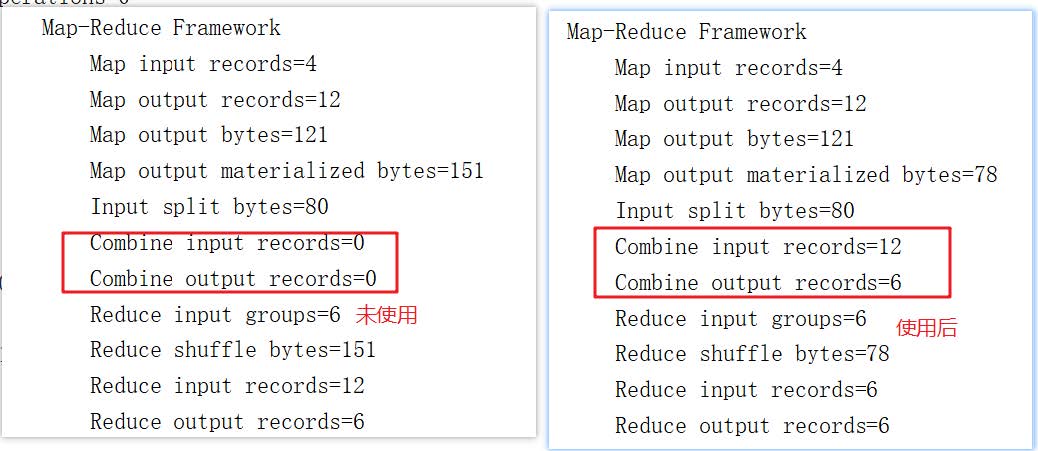
如果直接使用WordCountReducer作为Combiner使用是否可以?
直接使用Reducer作为Combiner组件来使用是可以的!!
















 2355
2355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











