







目录
1、PySpark中创建RDD的方式
并行化本地集合:sc.parallelize(data, numSlices)
读取外部文件数据:sc.textFile(name, minPartitions)
读取外部小文件数据:sc.wholeTextFile(path, minPartitions)
引言
官方文档: http://spark.apache.org/docs/latest/rdd-programming-guide.html#resilient-distributed-datasets-rdds
如何将数据封装到RDD集合中,主要有两种方式:
并行化本地集合(Driver Program中)和引用加载外部存储系统(如HDFS、Hive、HBase、Kafka、Elasticsearch等
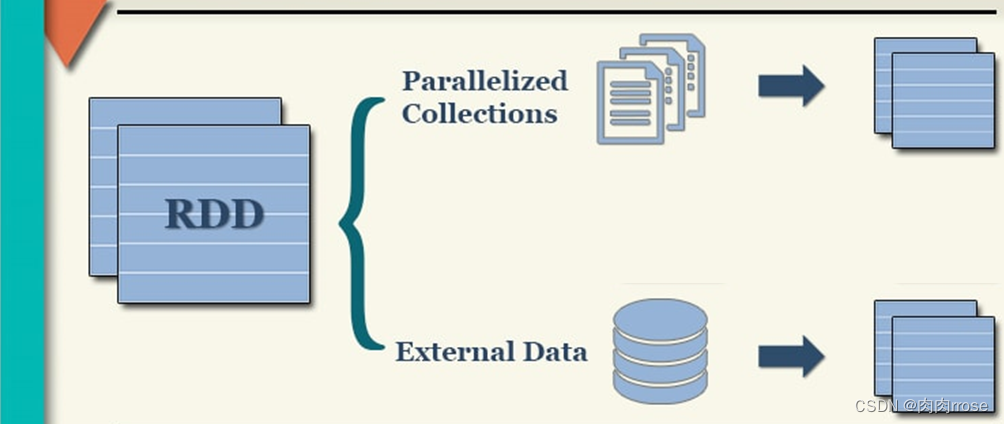
1、通过 textFile(data): 通过读取外部文件的方式来初始化RDD对象,实际工作中经常使用。 2、通过 parallelize(data): 通过自定义列表的方式初始化RDD对象。(一般用于测试)
(1)第一步 创建sparkContext
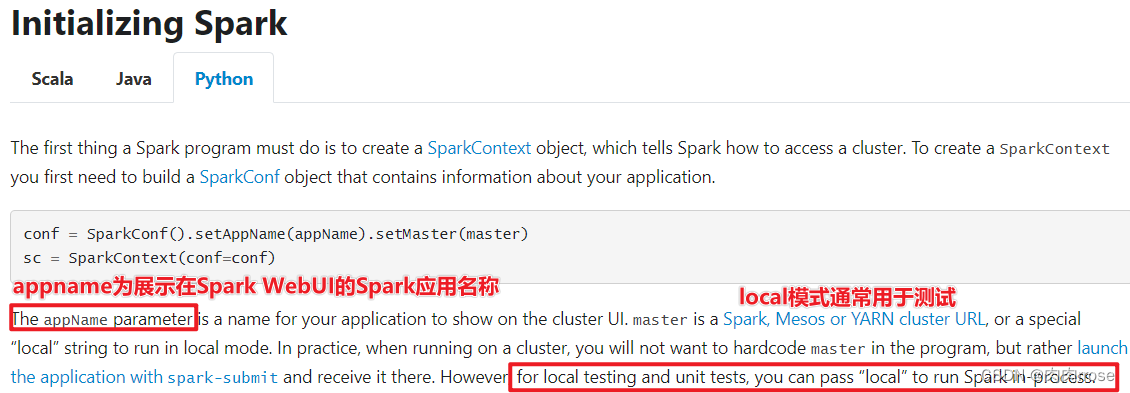
SparkContext:Spark程序的入口. SparkContext代表了和Spark集群的链接, 在Spark集群中通过SparkContext来创建RDD
SparkConf:创建SparkContext的时候需要一个SparkConf, 用来传递Spark应用的基本信息。
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)
在pyspark shell中 已经为我们创建好了 SparkContext 通过sc直接使用 可以在spark UI中看到当前的Spark作业 在浏览器访问当前centos的4040端口 192.168.88.161:4040
2、并行化方式创建RDD
首先Spark官网针对创建方式的说明:
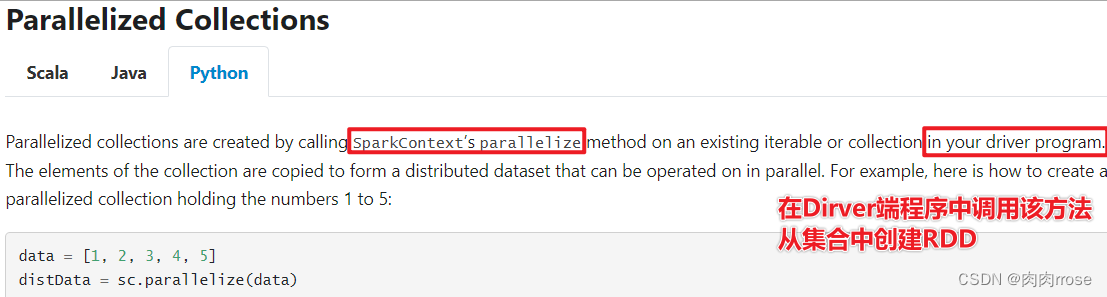
调用`SparkContext`的 `parallelize` 方法并且传入已有的可迭代对象或者集合:
>>> data = [1, 2, 3, 4, 5]
>>> distData = sc.parallelize(data)
>>> data [1, 2, 3, 4, 5]也可以在spark ui中观察执行情况
在通过parallelize方法创建RDD 的时候可以指定分区数量
>>> distData = sc.parallelize(data,5)
>>> distData.reduce(lambda a, b: a + b)
15

from pyspark import SparkContext, SparkConf
import os
os.environ['SPARK_HOME'] = '/export/servers/spark'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
print('PySpark First Program')
# 输入数据
data = ["hello", "world", "hello", "world"]
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
# sc = SparkContext.getOrCreate(conf)
sc = SparkContext(conf=conf)
# 将collection的data转为spark中的rdd并进行操作
rdd = sc.parallelize(data)
# 执行map转化操作以及reduceByKey的聚合操作
res_rdd = rdd.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
# 将rdd转为collection并打印
res_rdd_coll = res_rdd.collect()
for line in res_rdd_coll:
print(line)
print('停止 PySpark SparkSession 对象')
sc.stop()3、小文件读取
在实际项目中,有时往往处理的数据文件属于小文件(每个文件数据数据量很小,比如KB,几十MB等),文件数量又很大,如果一个个文件读取为RDD的一个个分区,计算数据时很耗时性能低下,使用SparkContext中提供:wholeTextFiles类,专门读取小文件数据。

范例演示:
读取100个小文件rating数据,每个文件大小小于1MB,查看默认情况下分区个数情况
# -*- coding: utf-8 -*-
from pyspark import SparkContext, SparkConf
import os
os.environ['SPARK_HOME'] = '/export/servers/spark'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
print('PySpark WholeTextFile Program')
# TODO:1、创建应用程序入口SparkContext实例对象
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
# TODO: 2、从文件系统加载数据,调用textFile
resultRDD1 = sc.textFile("file:///export/pyfolder1/pyspark-chapter02_3.8/data/ratings100/")
# TODO: 3、调用集合RDD中函数处理分析数据,调用wholeTextFiles
resultRDD2 = sc.wholeTextFiles("file:///export/pyfolder1/pyspark-chapter02_3.8/data/ratings100/")
# TODO: 4、获取分区数
print("textFile numpartitions:", resultRDD1.getNumPartitions())
print("whole textFile numpartitions:", resultRDD2.getNumPartitions())
# print(resultRDD2.take(2))
print('停止 PySpark SparkSession 对象')
# 关闭SparkContext
sc.stop()

4、通过外部数据创建RDD
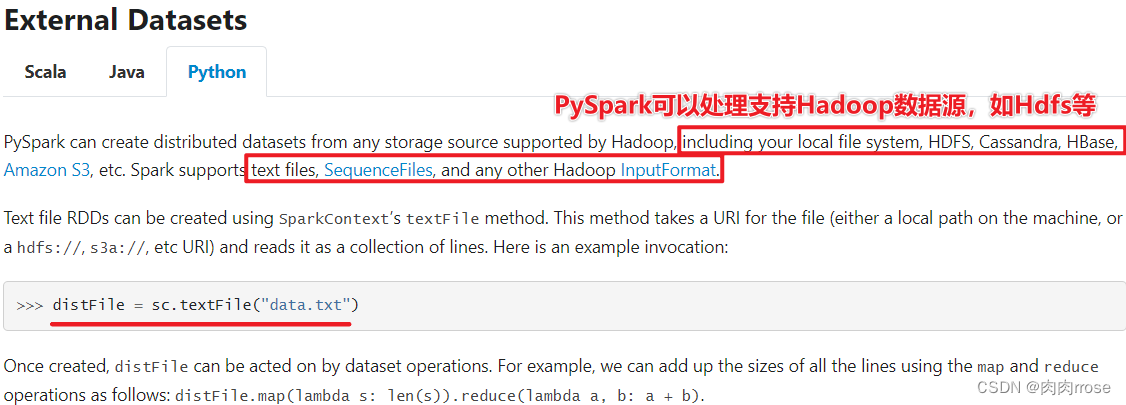
1、PySpark可以从Hadoop支持的任何存储源创建RDD,包括本地文件系统,HDFSCassandra,HBase,Amazon S3等。
2、支持整个目录、多文件、通配符
3、支持压缩文件
如下为Spark官网描述的支持文件信息:
>>> rdd1 = sc.textFile('file:///root/tmp/word.txt')
>>> rdd1.collect()
['foo foo quux labs foo bar quux abc bar see you by test welcome test', 'abc labs foo me python hadoop ab ac bc bec python']
from pyspark import SparkContext, SparkConf
import os
import re
os.environ['SPARK_HOME'] = '/export/servers/spark'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
print('PySpark RDD Program')
data = ["hello", "world", "hello", "world"]
# TODO:1、创建应用程序入口SparkContext实例对象
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
# TODO: 2、从文件系统加载数据,创建RDD数据集
# TODO: 3、调用集合RDD中函数处理分析数据
resultRDD2 = sc.textFile("file:///export/pyfolder1/pyspark-chapter02_3.8/data/word.txt") \
.flatMap(lambda line: re.split("\s+", line)) \
.map(lambda x: (x, 1)) \
.reduceByKey(lambda a, b: a + b)
# TODO: 4、保存结果RDD到外部存储系统(HDFS、MySQL、HBase。。。。)
res_rdd_coll = resultRDD2.collect()
for line in res_rdd_coll:
print(line)
print('停止 PySpark SparkSession 对象')
# 关闭SparkContext
sc.stop()
5、扩展:RDD分区数
在描述RDD 属性时,多次提到了分区(partition)的概念。分区是一个偏物理层的概念,也是 RDD 并行计算的单位。 数据在 RDD 内部被切分为多个子集合,每个子集合可以被认为是一个分区,运算逻辑最小会被应用在每一个分区上,每个分区是由一个单独的任务(task)来运行的,所以分区数越多,整个应用的并行度也会越高。 获取RDD分区数目方式,如下:

http://spark.apache.org/docs/latest/api/python/reference/api/pyspark.RDD.getNumPartitions.html#pyspark.RDD.getNumPartitions bin/pyspark --master local[2]
>>> data = [1, 2, 3, 4, 5]
>>> distData = sc.parallelize(data)
>>> distData.getNumPartitions() #2
RDD分区的数据取决于哪些因素?
第一点:RDD分区的原则是使得分区的个数尽量等于集群中的CPU核心(core)数目,这样可以充分利用CPU的计算资源;
第二点:在实际中为了更加充分的压榨CPU的计算资源,会把并行度设置为cpu核数的2~3倍;
第三点:RDD分区数和启动时指定的核数、调用方法时指定的分区数、如文件本身分区数有关系,具体如下说明:
1)、启动的时候指定的CPU核数确定了一个参数值:
spark.default.parallelism=指定的CPU核数(集群模式最小2)
思考:尝试spark.default.parallelism设置小一些,查看分区数
2)、对于Scala集合调用parallelize(集合,分区数)方法
如果没有指定分区数,就使用spark.default.parallelism
如果指定了就使用指定的分区数(建议不要指定大于spark.default.parallelism)
3)、对于textFile(文件, 分区数)
defaultMinPartitions
如果没有指定分区数sc.defaultMinPartitions=min(defaultParallelism,2)
如果指定了就使用指定的分区数sc.defaultMinPartitions=指定的分区数rdd的分区数
rdd的分区数
对于本地文件
rdd的分区数 = max(本地file的分片数,sc.defaultMinPartitions)
注意:这里即便自定义设置分区个数也不行,如sc.textFile(“”,3)
对于HDFS文件
rdd的分区数 = max(hdfs文件的block数目, sc.defaultMinPartitions)
所以如果分配的核数为多个,且从文件中读取数据创建RDD,即使hdfs文件只有1个切片,最后的Spark的RDD的partition数也有可能是2
总结:
RDD分区数量(线程数量)一般设置为CPU核心数的2~3倍
RDD分区数量有多个原因:调用任务时设置CPU核心数,调用API可以设置分区数量,读取文件数据的文件的数量
当初始化SparkContext时,取决于spark.default.parallelism的值
本地:spark.default.parallelism取决于local[N]中N为多少,并行度就是多少
集群:spark.default.parallelism至少为2
创建RDD时
并行化本地创建:sc.parallelize(data, numSlices)
如果没有指定分区数numSlices,分区数量取决于spark.default.parallelism
如果设置了分区数numSlices,以你设置的分区数为准
读取外部文件:sc.textFile(name, minPartition)
分区数量首先取决于defaultMinPartion的值
如果指定了minPartition,defaultMinPartition就等于minPartition
如果没有指定minPartition,defaultMinPartition就等于min(spark.default.parallelism, 2)
分区数量最终确定
当读取本地文件时:RDD分区数=max(本地文件分片数, defaultMinPartition)
当读取HDFS文件时:RDD分区数=max(文件的block块数, defaultMinPartition















 912
912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









