







 该作业介绍了如何利用HMM模型进行词性标注。学生需使用1998人民日报语料库训练模型,估计HMM的参数,如初始概率、转移矩阵,并通过维特比算法进行解码。作业还涉及模型参数的拉普拉斯平滑处理和测试文本的词性标注结果分析。
该作业介绍了如何利用HMM模型进行词性标注。学生需使用1998人民日报语料库训练模型,估计HMM的参数,如初始概率、转移矩阵,并通过维特比算法进行解码。作业还涉及模型参数的拉普拉斯平滑处理和测试文本的词性标注结果分析。
NLP作业01:请利用HMM实现词性标注
NLP作业01:请利用HMM实现词性标注
作业头
| 这个作业属于哪个课程 | 自然语言处理 |
|---|---|
| 这个作业要求在哪里 | https://bbs.csdn.net/topics/614556240 |
| 我在这个课程的目标是 | 理解并学会应用HMM模型 |
| 这个作业在那个具体方面帮助我实现目标 | 应用HMM |
| 参考文献 | https://zhuanlan.zhihu.com/p/224770895 |
一、作业内容:
1.利用“1998人民日报词性标注语料库”进行模型的训练。
2.根据数据估计HMM的模型参数:全部的词性集合Q,全部的词集合V ,初始概率向量PI ,词性到词性的转移矩阵A ,词性到词的转移矩阵B 。 可以采用频率估计概率的方法计算模型参数,但需要进一步采用拉普拉斯平滑处理。
3.在模型预测阶段基于维特比算法进行解码,并给出测试文本:“那个球状闪电呈橘红色,拖着一条不太长的尾迹,在夜空中沿一条变换的曲线飘行着。”的词性标注结果。
二、作业要求:
作业包括以下几个部分:
1)作业头:请务必加上作业头,认真填写作业头的内容,特别是目标和参考文献。(1分)
(2)对HMM模型进行介绍:必须是在自身理解的基础上进行总结,可以借鉴,但不可以抄袭。(2分)
(3)估计HMM的模型参数:对模型参数估计所采用的公式进行介绍,并给出相应实现代码(2分)
(4)基于维特比算法进行解码:对维特比算法进行介绍,并给出相应实现代码(3分)
(5)词性标注结果:给出题目要求的测试文本的词性标注结果,并对结果进行分析,针对标注结果不理想的情况,请给出具体解决方案。(2分)
一 HMM模型介绍
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。

二 估计HMM的模型参数
是在被建模的系统被认为是一个马尔可夫过程与未观测到的(隐藏的)的状态的统计马尔可夫模型。
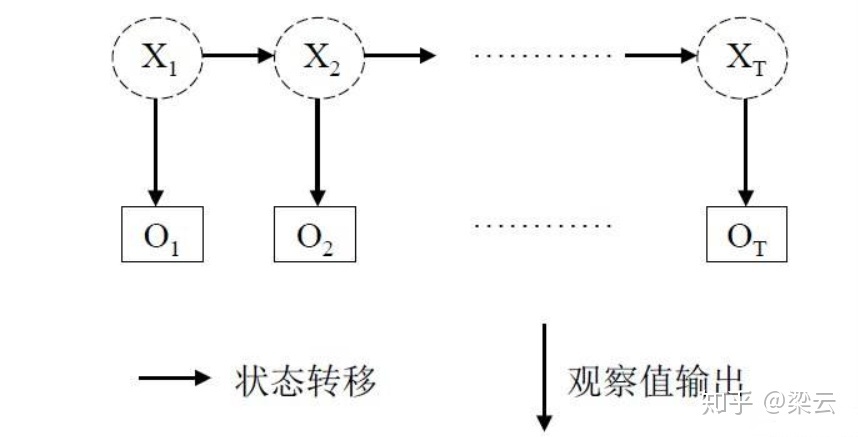
HMM模型是一个生成模型,描述了两个相关序列的依赖关系。这两个相关序列称为状态序列
X1,X2,X3,……,XTX_1,X_2,X_3,……,X_TX_1,X_2,X_3,……,X_T 和 观测序列
O1,O2,X3,……,OTO_1,O_2,X_3,……,O_TO_1,O_2,X_3,……,O_T.其中状态序列在t时刻的值只和t-1时刻
状态序列的取值有关,观测序列在t时刻的值只和t时刻观测序列的取值有关。
其联合概率函数如下
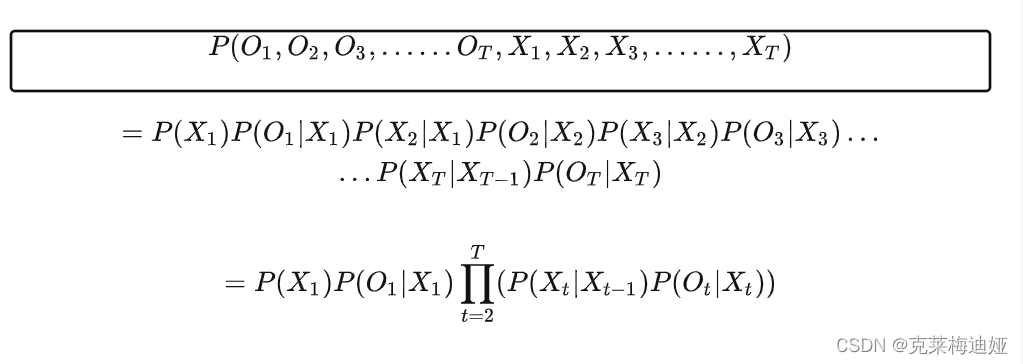
基于维特比算法进行解码
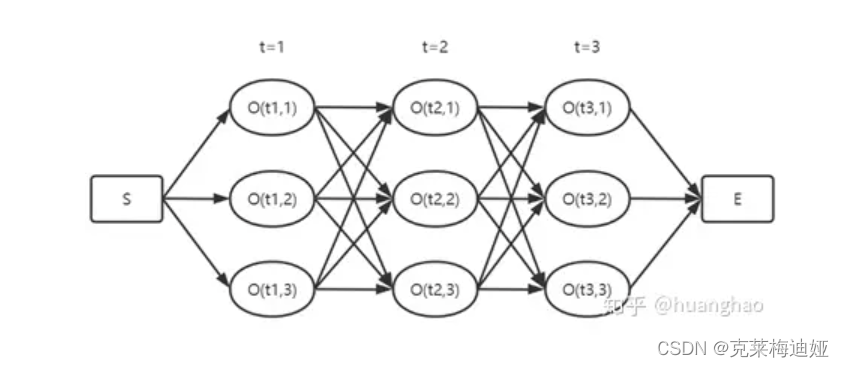
维特比算法就是求所有观测序列中的最优,如下图所示,我们要求从S到E的最优序列,中间有3个时刻,每个时刻都有对应的不同观察的概率,下图中每个时刻不同的观测标签有3个。

# 统计words和tags
words = set()
tags = set()
for words_with_tag in sentences:
for word_with_tag in words_with_tag:
word, tag = word_with_tag
words.add(word)
tags.add(tag)
words = list(words)
tags = list(tags)
# 统计 词性到词性转移矩阵A 词性到词转移矩阵B 初始向量pi
# 先初始化
A = {
tag:  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









