







目录
Flink
Apache Flink® — Stateful Computations over Data Streams | Apache Flink
简介
Apache Flink — 数据流上的有状态计算。
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算处理。
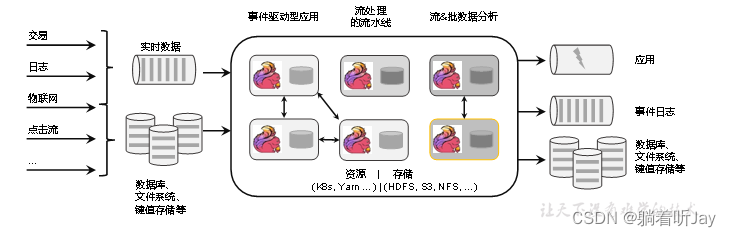
任何类型的数据都以事件流的形式生成。信用卡交易、传感器测量、机器日志或网站或移动应用程序 2上的用户交互,所有这些数据都以流的形式生成。
数据可以作为无界或有界流进行处理。
无界数据流:有定义流的开始,但是没有定义结束。会一直提供数据,没有结束。所以要一直连续的处理无界流,所以一旦有数据到来就要立即处理,不能等数据都到再处理,因为输入是无限的。处理无界数据通常需要按特定顺序(如数据引入的顺序),以便能够推断结果的完整性。
有界数据流:有具体的开始和结束。有界流的处理也称为批处理。有界数据可以等待所有数据到达之后再进行计算处理。有界数据不需要按顺序引入,因为可以对有界的数据集进行排序。
有状态处理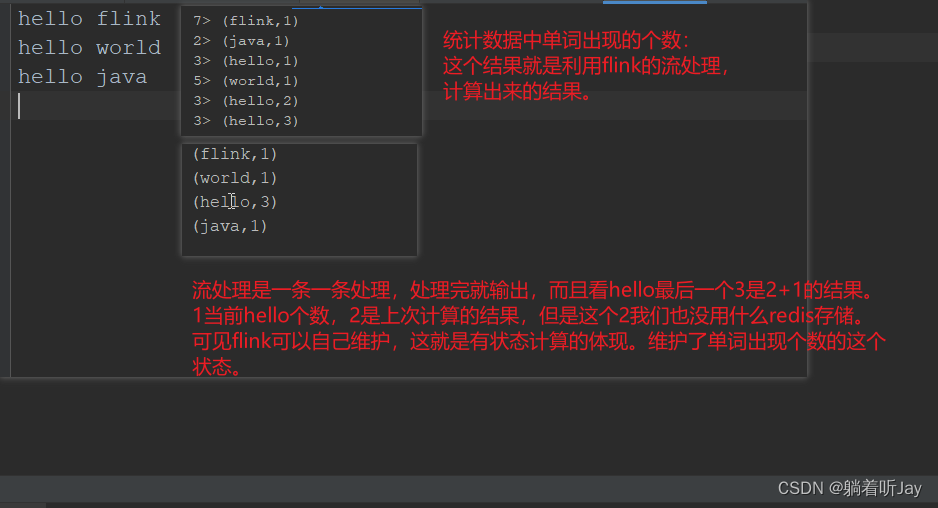
流处理和批处理

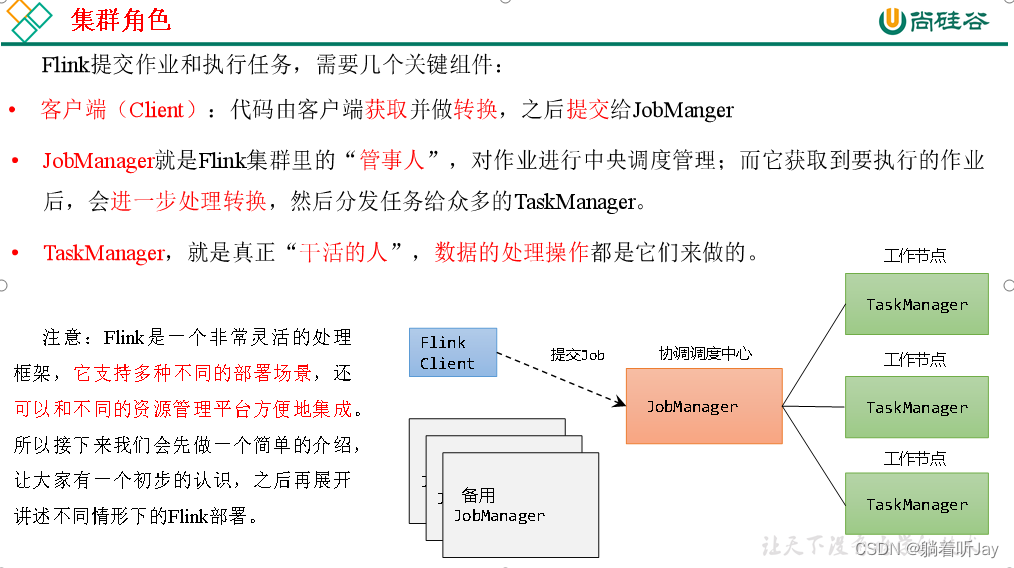
Flink架构
Flink 运行时由两种类型的进程组成:一个JobManager和一个或多个TaskManager。
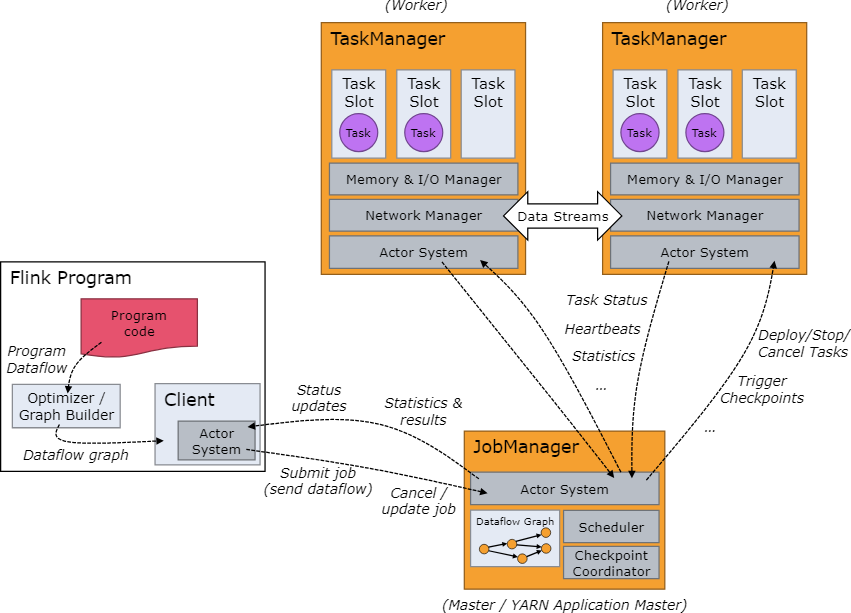
Client不是运行时和程序执行的一部分,而是用于准备数据流并将其发送到 JobManager 。之后,客户端可以断开连接(分离模式),或保持连接以接收进度报告
JobManager 和 TaskManager 可以通过多种方式启动:作为独立集群直接在机器上启动、在容器中启动或由YARN等资源框架进行管理。TaskManager 连接到 JobManager,宣布自己可用,并被分配工作。
JobManager
JobManager具有与协调 Flink 应用程序的分布式执行相关的许多职责:它决定何时安排下一个任务(或一组任务)、对已完成的任务或执行失败做出反应、协调检查点以及协调故障恢复等其他的。该过程由三个不同的部分组成:
ResourceManager资源管理器
ResourceManager负责 Flink 集群中的资源取消/分配和配置——它管理任务槽,任务槽是 Flink 集群中资源调度的单位(请参阅TaskManagers)。Flink 针对不同的环境和资源提供者(例如 YARN、Kubernetes 和独立部署)实现了多个 ResourceManager。在独立设置中,ResourceManager 只能分配可用 TaskManager 的插槽,而无法自行启动新的 TaskManager。
ResourceManager主要负责资源的分配和管理,在Flink 集群中只有一个。所谓“资源”,主要是指TaskManager的任务槽(task slots)。任务槽就是Flink集群中的资源调配单元,包含了机器用来执行计算的一组CPU和内存资源。每一个任务(Task)都需要分配到一个slot上执行。
Dispatcher分发器
Dispatcher提供 REST 接口来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster 。它还运行 Flink WebUI 以提供有关作业执行的信息。
JobMaster
JobMaster负责管理单个 JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
所以JobMaster和具体的Job是一一对应的,多个Job可以同时运行在一个Flink集群中, 每个Job都有一个自己的JobMaster。
在作业提交时,JobMaster会先接收到要执行的应用。JobMaster会把JobGraph转换成一个物理层面的数据流图,这个图被叫作“执行图”(ExecutionGraph),它包含了所有可以并发执行的任务。JobMaster会向资源管理器(ResourceManager)发出请求,申请执行任务必要的资源。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。
总是至少有一个 JobManager。高可用性设置可能有多个 JobManager,其中一个始终是领导者,其他是 备用(请参阅高可用性 (HA))。
TaskManager
必须始终至少有一个 TaskManager。TaskManager 中资源调度的最小单位是任务槽。TaskManager 中的任务槽数表示并发处理任务的数量。请注意,多个运算符可以在一个任务槽中执行(请参阅任务和运算符链)。
一个任务槽对应一个任务。
TaskManager是Flink中的工作进程,数据流的具体计算就是它来做的。Flink集群中必须至少有一个TaskManager;每一个TaskManager都包含了一定数量的任务槽(task slots)。
Slot是资源调度的最小单位,slot的数量限制了TaskManager能够并行处理的任务数量。
启动之后,TaskManager会向资源管理器注册它的slots;收到资源管理器的指令后,TaskManager就会将一个或者多个槽位提供给JobMaster调用,JobMaster就可以分配任务来执行了。
在执行过程中,TaskManager可以缓冲数据,还可以跟其他运行同一应用的TaskManager交换数据。
并行度
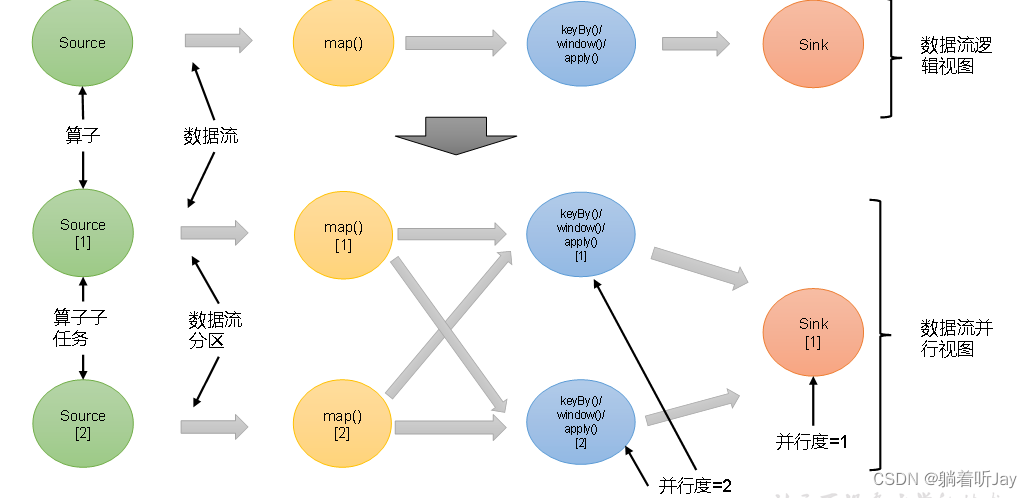
一个flink程序处理数据的流程中一般会包含多个算子,每个算子都会处理数据,如果要处理的数据特别大,可能就会导致算子处理数据的负担过大,导致速度太慢。为了应对这种现象,我们可以把要处理的数据分流,分到不同的节点上同时处理,而并行度就是同时处理数据的节点数。
在Flink执行过程中,每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中完全独立地执行。
比如:sum.print().setParallelism(2)比如这个,我们给print输出算子设置了并行度2,sum数据流的输出任务就会被分成两个子任务,到不同的物理机上执行输出:


并行度设置
代码中设置
我们在代码中,可以很简单地在算子后跟着调用 setParallelism()方法,来设置当前算子的并行度。这种方式设置的并行度,只针对当前算子有效,可以看哪个算子处理数据负担比较大,就可以将该算子的并行度设置大一点。stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2); // 给map设置并行度2
设置当前环境的并行度
这样代码中所有算子,默认的并行度就都为 2 了。我们一般不会在程序中设置全局并行度, 因为如果在程序中对全局并行度进行硬编码,会导致无法动态扩容。StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
提交应用时设置
在使用 flink run 命令提交应用时,可以增加-p 参数来指定当前应用程序执行的并行度, 它的作用类似于执行环境的全局设置。如果我们直接在Web UI 上提交作业,也可以在对应输入框中直接添加并行度。bin/flink run –p 2 –c 全类名 jar包
配置文件中设置
我们还可以直接在集群的配置文件 flink-conf.yaml 中直接更改默认并行度:
parallelism.default: 2
并行度设置优先级从上而下递减。
Flink部署
flink部署模式
Flink集群的部署方式是灵活的,支持在Local,Standalone,Yarn,Mesos,Docker,Kubernetes部署等。
而具体的如何跟这些资源交互,例如通信,回收,隔离等,则需要根据Flink job的提交方式,或者说是运行方式来决定。
flink的部署方式:
- 在应用程序模式下,
- 在会话模式下,
- 在 Per-Job 模式下(已弃用)。
它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的main方法到底在哪里执行——客户端(Client)还是JobManager。
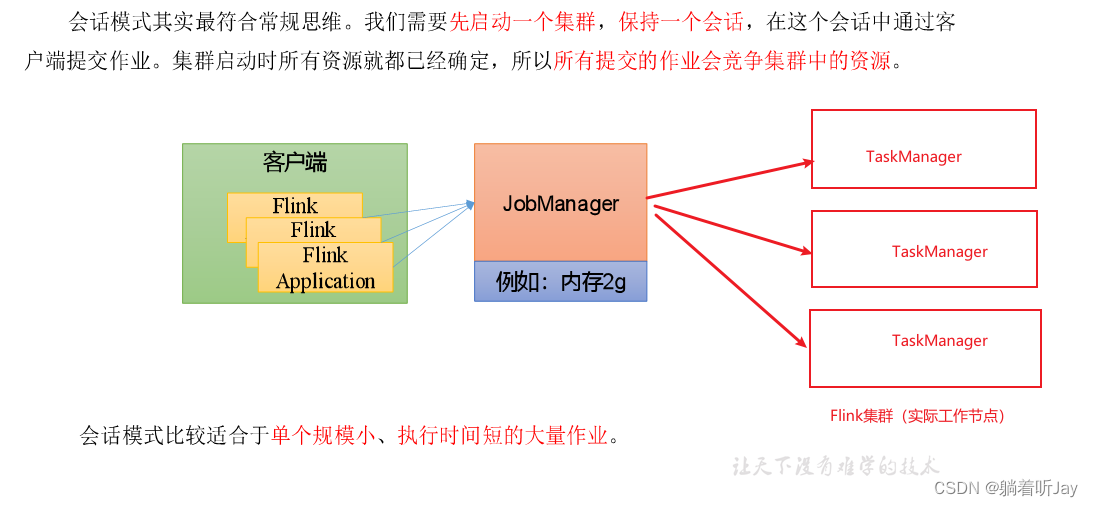
会话模式(Session Mode)
集群生命周期:在 Flink Session 集群中,客户端连接到一个预先存在的、长期运行的flink集群,该集群可以接受多个作业提交。即使所有作业完成后,集群(和 JobManager)仍将继续运行直到手动停止 session 为止。因此,Flink Session 集群的寿命不受任何 Flink 作业寿命的约束。
资源隔离:TaskManager slot 由 ResourceManager 在提交作业时分配,并在作业完成时释放。由于所有作业都共享同一集群,因此在集群资源方面存在一些竞争 — 例如提交工作阶段的网络带宽。此共享设置的局限性在于,如果 TaskManager 崩溃,则在此 TaskManager 上运行 task 的所有作业都将失败;类似的,如果 JobManager 上发生一些致命错误,它将影响集群中正在运行的所有作业。
其他注意事项:拥有一个预先存在的集群可以节省大量时间申请资源和启动 TaskManager。有种场景很重要,作业执行时间短并且启动时间长会对端到端的用户体验产生负面的影响 — 就像对简短查询的交互式分析一样,希望作业可以使用现有资源快速执行计算。
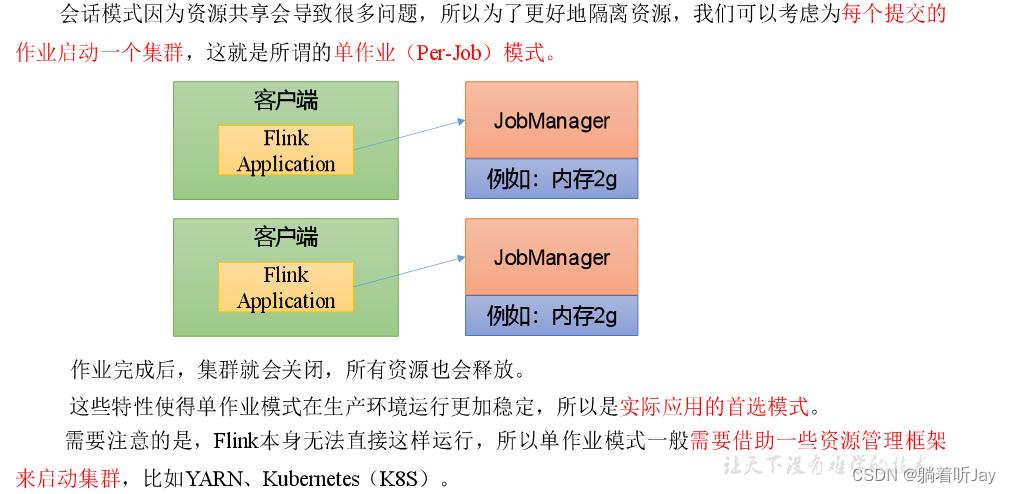
单作业模式(Per-Job Mode)
应用模式(Application Mode)
集群生命周期:Flink 应用程序集群是一个专用的 Flink 集群,仅执行来自一个 Flink 应用程序的作业,并且该
main()方法在集群上运行,而不是在客户端上运行。作业提交是一个一步过程:您不需要先启动 Flink 集群,然后将作业提交到现有集群会话;相反,您将应用程序逻辑和依赖项打包到可执行作业 JAR 中,集群入口点 (ApplicationClusterEntryPoint) 负责调用该main()方法来提取 JobGraph。例如,这允许您像 Kubernetes 上的任何其他应用程序一样部署 Flink 应用程序。因此,Flink 应用程序集群的生命周期与 Flink 应用程序的生命周期绑定在一起。资源隔离:在 Flink 应用程序集群中,ResourceManager 和 Dispatcher 的范围仅限于单个 Flink 应用程序,这比 Flink 会话集群提供了更好的关注点分离。

这里我们所讲到的部署模式,相对是比较抽象的概念。实际应用时,一般需要和资源管理平台结合起来,选择特定的模式来分配资源、部署应用。接下来,我们就针对不同的资源提供者的场景,具体介绍Flink的部署方式。
Standalone运行模式
会话模式部署

当集群启动后,TaskManager会向资源管理器注册它的任务槽slots;收到资源管理器的指令后,TaskManager就会将一个或者多个任务槽位提供给JobMaster调用,JobMaster就可以分配任务来执行了。
当用户提交一个flink计算任务时,分发器启动一个新的 JobMaster,JobMaster会先接收到要执行的任务应用,JobMaster会把JobGraph转换成一个物理层面的数据流图,这个图被叫作“执行图”(ExecutionGraph),它包含了所有可以并发执行的任务。
JobMaster会向资源管理器(ResourceManager)发出请求,申请执行任务必要的资源任务槽。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager(我的理解是哪个TaskManager有空闲的任务槽slot)上。
0)集群规划
| 节点服务器 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
| 角色 | 充当JobManager和TaskManager | TaskManager | TaskManager |
具体安装部署步骤如下:
*1)下载并解压安装包*
(1)https://flink.apache.org/downloads/ 下载安装包flink-1.17.0-bin-scala_2.12.tgz,将该jar包上传到hadoop102节点服务器的/opt/software路径上。
(2)在/opt/software路径上解压flink-1.17.0-bin-scala_2.12.tgz到/opt/module路径上。
[atguigu@hadoop102 software]$ tar -zxvf flink-1.17.0-bin-scala_2.12.tgz -C /opt/module/
*2)修改集群配置
(1)进入conf路径,修改flink-conf.yaml文件,指定hadoop102节点服务器为JobManager
[atguigu@hadoop102 conf]$ vim flink-conf.yaml
修改如下内容:
# JobManager节点地址.
jobmanager.rpc.address: hadoop102
jobmanager.bind-host: 0.0.0.0
rest.address: hadoop102
rest.bind-address: 0.0.0.0
\# TaskManager节点地址.需要配置为当前机器名
taskmanager.bind-host: 0.0.0.0
taskmanager.host: hadoop102
(2)修改workers文件,指定hadoop102、hadoop103和hadoop104为TaskManager
[atguigu@hadoop102 conf]$ vim workers
修改如下内容:
hadoop102
hadoop103
hadoop104
(3)修改masters文件
[atguigu@hadoop102 conf]$ vim masters
修改如下内容:
hadoop102:8081
(4)另外,在flink-conf.yaml文件中还可以对集群中的JobManager和TaskManager组件进行优化配置,主要配置项如下:
l jobmanager.memory.process.size:对JobManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1600M,可以根据集群规模进行适当调整。
l taskmanager.memory.process.size:对TaskManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1728M,可以根据集群规模进行适当调整。
l taskmanager.numberOfTaskSlots:对每个TaskManager能够分配的Slot数量进行配置,默认为1,可根据TaskManager所在的机器能够提供给Flink的CPU数量决定。所谓Slot就是TaskManager中具体运行一个任务所分配的计算资源。
l parallelism.default:Flink任务执行的并行度,默认为1。优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。
关于Slot和并行度的概念,我们会在下一章做详细讲解。
*3)分发安装目录*
(1)配置修改完毕后,将Flink安装目录发给另外两个节点服务器。
[atguigu@hadoop102 module]$ xsync flink-1.17.0/
(2)修改hadoop103的 taskmanager.host
[atguigu@hadoop103 conf]$ vim flink-conf.yaml
修改如下内容:
# TaskManager节点地址.需要配置为当前机器名
taskmanager.host: hadoop103
(3)修改hadoop104的 taskmanager.host
[atguigu@hadoop104 conf]$ vim flink-conf.yaml
修改如下内容:
# TaskManager节点地址.需要配置为当前机器名
taskmanager.host: hadoop104
*4)启动集群*
(1)在hadoop102节点服务器上执行start-cluster.sh启动Flink集群:
[atguigu@hadoop102 flink-1.17.0]$ bin/start-cluster.sh
(2)查看进程情况:
[atguigu@hadoop102 flink-1.17.0]$ jpsall
=============== hadoop102 ===============
4453 StandaloneSessionClusterEntrypoint
4458 TaskManagerRunner
4533 Jps
=============== hadoop103 ===============
2872 TaskManagerRunner
2941 Jps
=============== hadoop104 ===============
2948 Jps
2876 TaskManagerRunner
*5)访问Web UI*
启动成功后,同样可以访问http://hadoop102:8081对flink集群和任务进行监控管理。
这里可以明显看到,当前集群的TaskManager数量为3;由于默认每个TaskManager的Slot数量为1,所以总Slot数和可用Slot数都为3。
向集群提交作业
上传要计算的任务,这边是写了个计算单词出现个数的程序,数据源来自socket。具体步骤如下:
*1**)环境准备*
在hadoop102中执行以下命令启动netcat。
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
*2**)打包程序jar
(1)在我们编写的Flink入门程序的pom.xml文件中添加打包插件的配置,具体如下:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
(2)插件配置完毕后,可以使用IDEA的Maven工具执行package命令,出现如下提示即表示打包成功。
-------------------------------------------------------------------
[INFO] BUILD SUCCESS
-------------------------------------------------------------------
打包完成后,在target目录下即可找到所需JAR包,JAR包会有两个,FlinkTutorial-1.0-SNAPSHOT.jar和FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar,因为集群中已经具备任务运行所需的所有依赖,所以建议使用FlinkTutorial-1.0-SNAPSHOT.jar。比较大的带有依赖。
*3)**在Web* *UI上提交作业*
(1)任务打包完成后,我们打开Flink的WEB UI页面,在右侧导航栏点击“Submit New Job”,然后点击按钮“+ Add New”,选择要上传运行的JAR包,如下图所示。
JAR包上传完成,如下图所示:
(2)点击该JAR包,出现任务配置页面,进行相应配置。
主要配置程序入口主类的全类名,任务运行的并行度,任务运行所需的配置参数和保存点路径等,如下图所示,配置完成后,即可点击按钮“Submit”,将任务提交到集群运行。
(3)任务提交成功之后,可点击左侧导航栏的“Running Jobs”查看程序运行列表情况。
(4)测试
①在socket端口中输入hello
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
hello
②先点击Task Manager,然后点击右侧的192.168.10.104服务器节点
③点击Stdout,就可以看到hello单词的统计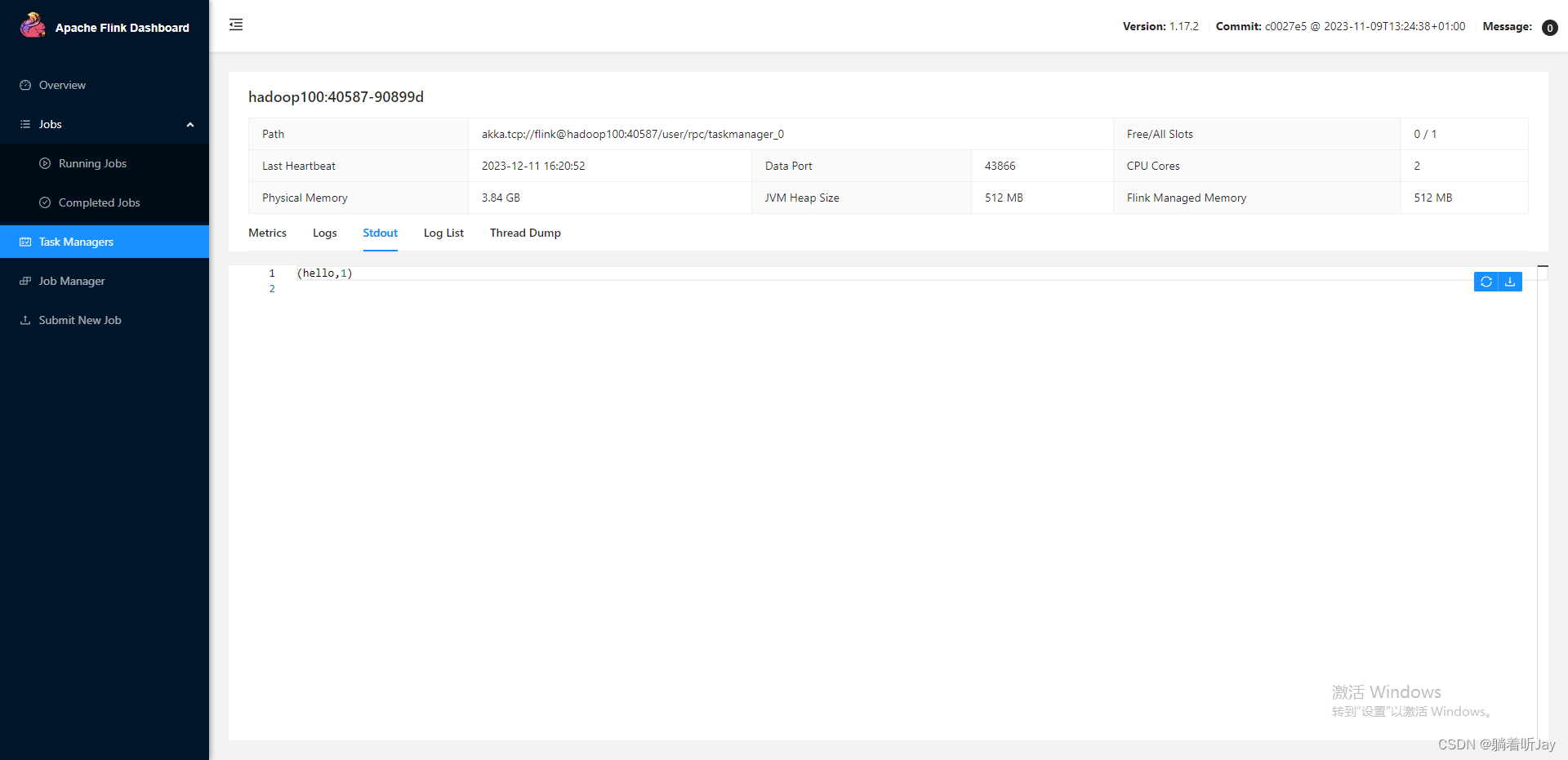
注意:如果hadoop104节点没有统计单词数据,可以去其他TaskManager节点查看。
(4)点击该任务,可以查看任务运行的具体情况,也可以通过点击“Cancel Job”结束任务运行。
4)命令行提交作业
除了通过WEB UI界面提交任务之外,也可以直接通过命令行来提交任务。这里为方便起见,我们可以先把jar包直接上传到目录flink-1.17.0下
(1)首先需要启动集群。
[atguigu@hadoop102 flink-1.17.0]$ bin/start-cluster.sh
(2)在hadoop102中执行以下命令启动netcat。
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
(3)将flink程序运行jar包上传到/opt/module/flink-1.17.0路径。
(4)进入到flink的安装路径下,在命令行使用flink run命令提交作业。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run -m hadoop102:8081 -c com.atguigu.wc.SocketStreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
这里的参数 -m指定了提交到的JobManager,-c指定了入口类。
(5)在浏览器中打开Web UI,http://hadoop102:8081查看应用执行情况。
用netcat输入数据,可以在TaskManager的标准输出(Stdout)看到对应的统计结果。
(6)在/opt/module/flink-1.17.0/log路径中,可以查看TaskManager节点。
[atguigu@hadoop102 log]$ cat flink-atguigu-standalonesession-0-hadoop102.out
(hello,1)
(hello,2)
(flink,1)
(hello,3)
(scala,1)
应用模式部署
Yarn运行模式
在将Flink任务部署至YARN集群之前,需要确认集群是否安装有Hadoop,保证Hadoop版本至少在2.2以上,并且集群中安装有HDFS服务。
会话模式部署
应用模式部署
DataStream API
DataStream API是Flink的核心层API,使用API实现对数据流的计算和处理。
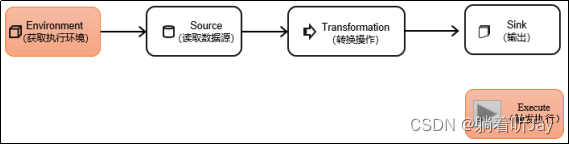
一个Flink程序,其实就是对数据流DataStream的各种转换。具体来说,代码基本上都由以下几部分构成:
- 获得一个
execution environment,- 加载/创建初始数据,
- 指定此数据的转换,
- 指定放置计算结果的位置,
- 触发程序执行
/**
* 计算单词出现个数
*
* flink处理无界数据流
* 程序会一直运行,一有数据来就处理
*
* @author shkstart
* @create 2023-09-10 16:44
*/
public class SocketStreamWordCount {
public static void main(String[] args) throws Exception {
// 1.创建flink流式处理环境 StreamExecutionEnvironment
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.接收要待处理的数据
DataStreamSource<String> dateStream = see.socketTextStream("192.168.239.128", 7777);
// 3.处理数据 数据处理后格式:(word,2)单词和对应出现的次数
/**
* flatMap(FlatMapFunction<T, R> flatMapper)
* 为数据流的每一个元素调用flatMapper
*/
System.out.println("原始数据流:" + dateStream);
// FlatMapFunction转换,处理数据流元素
FlatMapFunction<String, Tuple2<String, Integer>> flatMapFunction = new FlatMapFunctionImpl();
SingleOutputStreamOperator<Tuple2<String, Integer>> transformedDataStream =
dateStream.flatMap(flatMapFunction);
System.out.println("处理后的数据流:" + transformedDataStream);
// 按照word分组 按string分组 将Integer累加
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = transformedDataStream.keyBy(data -> data.f0).sum(1);
// 4.展示
sum.print();
// 5.执行 开始处理
// 代码末尾需要调用 流式处理环境 的execute方法,开始执行任务
see.execute();
}
}
public class FlatMapFunctionImpl implements FlatMapFunction<String , Tuple2<String,Integer>> {
/**
* 转换数据流元素
* @param value 输入的元素
* @param out 输出的元素
* @throws Exception
*/
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
// 切分
String[] words = value.split(" ");
// 收集
for (String word : words) {
out.collect(Tuple2.of(word,1));
}
}
}
1、获取执行环境
Flink程序可以在各种上下文环境中运行:我们可以在本地JVM中执行程序,也可以提交到远程集群上运行。
不同的环境,代码的提交运行的过程会有所不同。这就要求我们在提交作业执行计算时,首先必须获取当前Flink的运行环境,从而建立起与Flink框架之间的联系。
可以通过以下三种方法获取执行环境:
// 这个最常用的,官方也是推荐这个。这个会自动识别是本地运行还是远程集群运行,从而创建对应的执行环境。
StreamExecutionEnvironment.getExecutionEnvironment();
// 这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;
// 如果不传入,则默认并行度就是本地的CPU核心数。
StreamExecutionEnvironment.createLocalEnvironment();
// 这个方法返回集群执行环境。需要在调用时指定JobManager的主机名和端口号,并指定要在集群中运行的Jar包。
StreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment
.createRemoteEnvironment(
"host", // JobManager主机名
1234, // JobManager进程端口号
"path/to/jarFile.jar" // 提交给JobManager的JAR包
);
// 在获取到程序执行环境后,我们还可以对执行环境进行灵活的设置。
// 比如可以全局设置程序的并行度、禁用算子链,还可以定义程序的时间语义、配置容错机制。执行模式
DataStream API执行模式包括:流执行模式、批执行模式和自动模式。
流执行模式(Streaming)
这是DataStream API最经典的模式,一般用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是Streaming执行模式。
// 流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
批执行模式(Batch)
专门用于批处理(处理有界数据)的执行模式。
自动模式(AutoMatic)
在这种模式下,将由程序根据输入数据源是否有界,来自动选择执行模式。
批执行模式的使用。主要有两种方式:
(1)通过命令行配置
bin/flink run -Dexecution.runtime-mode=BATCH ...
bin/flink run -Dexecution.runtime-mode=BATCH -m hadoop102:8081 -c com.atguigu.wc.SocketStreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
在通过命令行提交作业时,增加execution.runtime-mode参数,指定值为BATCH。
(2)通过代码配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
在代码中,直接基于执行环境调用setRuntimeMode方法,传入BATCH模式。
实际应用中一般不会在代码中配置,而是使用命令行,这样更加灵活。
2、数据源(源算子)
flink处理的数据来源,可以从各种数据源获取数据,然后构建DataStream来转换数据,最后将结果写入保存。
从集合中读取数据
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
System.out.println("=========");
List<Integer> list = Arrays.asList(1, 3, 5);
DataStreamSource<Integer> source = env.fromCollection(list);
source.print();
env.execute();从文件中读取数据
public class MyFileSource {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
/**
* 文件数据源
* 文件可以来自本地系统,还可以从HDFS目录下读取,使用路径hdfs://...
*/
FileSource<String> fileSource =
FileSource.forRecordStreamFormat(new TextLineInputFormat(), new Path("input/words.txt")).build();
DataStreamSource<String> fileDataStream = env.fromSource(fileSource, WatermarkStrategy.noWatermarks(), "file");
fileDataStream.print();
env.execute();
}
}从socket中读取数据
不论从集合还是文件,我们读取的其实都是有界数据。在流处理的场景中,数据往往是无界的。
我们之前用到的读取socket文本流,就是流处理场景。但是这种方式由于吞吐量小、稳定性较差,一般也是用于测试。
DataStream<String> stream = env.socketTextStream("localhost", 7777);
从Kafka读取数据
flink可以和kafka配合构建实时数据处理和流式数据计算的架构。
生产者将数据源中的数据发送到kafka中的主题topic中,然后flink连接到kafka取topic中的数据来处理,然后将处理结果输出到外部系统比如mysql中。
我有个疑问,为啥flink不直接连接数据源,直接从数据源中取数据处理,用kafka作为中间件的好处?
第一个解耦:如果flink直接连接数据源取数据,会导致数据源和flink处理程序的耦合性太高,而引入kafka作为中间件,数据源只要将数据发给kafka就好,而无需知道数据具体用来干嘛,这样数据源和flink处理程序的耦合性就降低了,可以更灵活的扩展和维护程序。
第二个容错可靠性: Kafka 允许数据源将实时数据发送到主题,并在其中持久化。这样,即使 Flink 应用程序暂时不可用或者出故障了,数据仍然保存在 Kafka 中,避免了数据丢失,flink恢复后可以继续消费数据。
第三个水平扩展:Kafka 允许水平扩展,使其能够处理大量的数据,可以增加分区,将数据分发到不同的节点上。flink可以增加任务并行度来扩展处理能力。
kafka的优点和缺点:
- 高吞吐量:Kafka 可以处理非常高的吞吐量,每秒数百万的消息。这使得它适用于需要大规模数据处理和实时数据流的场景。
- 可扩展性:Kafka 允许将数据分布式地存储和处理在多个节点上。它支持在集群中动态地添加和删除节点,以适应不同的负载需求。
- 持久性:Kafka 将消息持久化到磁盘,因此即使消费者离线,也不会丢失数据。它可以作为可靠的数据存储和消息传递系统。
- 实时处理:Kafka 提供了低延迟的消息传递,使得实时数据流处理成为可能。它支持发布-订阅模型和流处理模型,方便实时数据分析和处理。
尽管 Kafka 具有许多优点,但也有一些潜在的缺点:
- 复杂性:Kafka 是一个分布式系统,需要配置和管理多个节点。这对于初学者来说可能有一定的学习曲线,而且需要更复杂的运维。
- 存储需求:由于 Kafka 持久化消息到磁盘,因此它需要占用较多的存储空间。这可能导致存储成本的增加。
- 配置和监控:为了确保 Kafka 集群的正常运行,需要进行适当的配置和监控。这需要一些管理和维护工作,以确保高可用性和性能。
总之,Kafka 是一个强大的分布式流处理平台,具有高吞吐量、可靠性、实时处理和可扩展性等优点。它在处理大规模实时数据流方面表现出色,但也需要考虑到复杂性和存储需求等潜在的缺点。
flink的kafka消费者:
Flink官方提供了连接工具flink-connector-kafka,直接帮我们实现了一个消费者FlinkKafkaConsumer,它就是用来读取Kafka数据的SourceFunction。
所以想要以Kafka作为数据源获取数据,我们只需要引入Kafka连接器的依赖。Flink官方提供的是一个通用的Kafka连接器,它会自动跟踪最新版本的Kafka客户端。目前最新版本只支持0.10.0版本以上的Kafka。这里我们需要导入的依赖如下。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
代码如下:
public class MyKafkaSource {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("192.168.10.102:9092")
.setTopics("fi")
.setGroupId("flink-consumer")
.setValueOnlyDeserializer(new SimpleStringSchema()) // 反序列器,只反序列值
// 可以设置key 和 value的反序列器
// .setProperty("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer")
// .setProperty("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer")
// flink消费kafka的策略: earliest从头开始消费 latest消费最新数据
.setStartingOffsets(OffsetsInitializer.latest())
.build();
DataStreamSource<String> kafkaDataStreamSource = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafka");
kafkaDataStreamSource.print("kafka");
env.execute();
}
}3、转换算子
从数据源读入数据之后,我们就可以使用各种转换算子,将数据分析、计算、处理成我们想要的样子。

基本转换算子
(map/ filter/ flatMap)
// map映射算子 来一条数据处理产出一条数据,这里来一条String,处理成一个person
SingleOutputStreamOperator<Person> processedDataStream = socketTextStream.map((MapFunction<String, Person>) value -> {
String[] split = value.split(",");
Person person = null;
try {
person = new Person(Integer.parseInt(split[0]), Integer.parseInt(split[1]), split[2]);
} catch (NumberFormatException e) {
e.printStackTrace();
}
return person;
});分区算子
对于Flink而言,DataStream是没有直接进行聚合的API的。因为我们对海量数据做聚合肯定要进行分区并行处理,这样才能提高效率。所以在Flink中,要做聚合,需要先进行分区;这个操作就是通过keyBy来完成的。
keyBy是聚合前必须要用到的一个算子。keyBy通过指定键(key),可以将一条流从逻辑上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务。
基于不同的key,流中的数据将被分配到不同的分区中去;这样一来,所有具有相同的key的数据,都将被发往同一个分区。
public class TransKeyBy {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1, 1),
new WaterSensor("sensor_1", 2, 2),
new WaterSensor("sensor_2", 2, 2),
new WaterSensor("sensor_3", 3, 3)
);
// 根据id进行分区
// 方式一:使用Lambda表达式
KeyedStream<WaterSensor, String> keyedStream = stream.keyBy(e -> e.id);
// 方式二:使用匿名类实现KeySelector
KeyedStream<WaterSensor, String> keyedStream1 = stream.keyBy(new KeySelector<WaterSensor, String>() {
@Override
public String getKey(WaterSensor e) throws Exception {
return e.id;
}
});
env.execute();
}
}简单聚合
4、输出算子sink
flink作为数据的处理框架,支持将最后的分析、计算、处理结果输出到外部系统,供其他使用。Flink程序中所有对外的输出操作,一般都是利用Sink算子完成的。

输出到文件
public class SinkFile {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每个目录中,都有 并行度个数的 文件在写入 。并行度多少,就会有多少个文件在同时写入。
// env.setParallelism(2);
// 必须开启checkpoint,否则后缀一直都是 .inprogress
env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
// 数据生成器DataGeneratorSource
DataGeneratorSource<String> dataGeneratorSource = new DataGeneratorSource<>(
new GeneratorFunction<Long, String>() {
@Override
public String map(Long value) throws Exception {
return "Number:" + value;
}
},
Long.MAX_VALUE,
RateLimiterStrategy.perSecond(1000),
Types.STRING
);
DataStreamSource<String> dataGen =
env.fromSource(dataGeneratorSource, WatermarkStrategy.noWatermarks(), "data-generator");
// 输出到文件系统
FileSink<String> fieSink = FileSink
// 输出行式存储的文件,指定路径、指定编码
.<String>forRowFormat(new Path("D:/linjl/2023年12月13日"), new SimpleStringEncoder<>("UTF-8"))
// 输出文件的一些配置: 文件名的前缀、后缀
.withOutputFileConfig(
OutputFileConfig.builder()
.withPartPrefix("lin-")
.withPartSuffix(".log")
.build()
)
// 按照目录分桶:如下,就是每个小时一个目录
.withBucketAssigner(new DateTimeBucketAssigner<>("yyyy-MM-dd HH", ZoneId.systemDefault()))
// 文件滚动策略: 1分钟 或 1m
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(1))
.withMaxPartSize(new MemorySize(1024*1024))
.build()
)
.build();
// dataGen.print();
dataGen.sinkTo(fieSink).setParallelism(3);
env.execute();
}
}输出到MySQL
<!--flink写入到MySQL-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>3.1.1-1.17</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.27</version>
</dependency>public class SinkSql {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("192.168.10.102", 9999);
// map映射算子 来一条数据处理产出一条数据,这里来一条String,处理成一个person
SingleOutputStreamOperator<Person> processedDataStream = socketTextStream.map((MapFunction<String, Person>) value -> {
String[] split = value.split(",");
Person person = null;
try {
person = new Person(Integer.parseInt(split[0]), Integer.parseInt(split[1]), split[2]);
} catch (NumberFormatException e) {
e.printStackTrace();
}
return person;
});
/**
* JdbcSink.sink(
* sqlDmlStatement, // mandatory
* jdbcStatementBuilder, // mandatory
* jdbcExecutionOptions, // optional
* jdbcConnectionOptions // mandatory
* );
*
* 第一个参数: 执行的sql,一般就是 insert into
* 第二个参数: 预编译sql, 对占位符填充值
* 第三个参数: 执行选项 ---》 攒批、重试
* 第四个参数: 连接选项 ---》 url、用户名、密码
*/
SinkFunction<Person> mysqlSink = JdbcSink.sink(
"insert into person values(?,?,?)",
new JdbcStatementBuilder<Person>() {
@Override
public void accept(PreparedStatement preparedStatement, Person o) throws SQLException {
// 每收到来自datastream的一条数据,如何处理
if(o == null) return;
preparedStatement.setInt(1, o.getId());
preparedStatement.setInt(2, o.getAge());
preparedStatement.setString(3, o.getName());
}
},
JdbcExecutionOptions.builder()
.withMaxRetries(3) // 重试次数
.withBatchSize(100) // 批次的大小:条数
.withBatchIntervalMs(3000) // 批次的时间
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://192.168.31.47:3306/test?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8")
.withUsername("root")
.withPassword("123456")
.withConnectionCheckTimeoutSeconds(60) // 重试之间的超时时间,jdbc连接超时会重试,重试超过60s没超过就超时异常。
.build()
);
// 指定数据流处理完流向哪个sink
processedDataStream.addSink(mysqlSink);
env.execute();
}
}flink窗口
flink一般用于流式数据的处理,而流式数据就是说数据会源源不断的进来,然后来一条数据处理一条,但是这样子处理不是非常高效,一般可以将数据攒一批,一批一批处理更加高效,将无限的数据切成一个一个数据块进行处理。flink中就是用一个一个窗口根据一定范围将数据切割成一个个数据块。
水桶接水:有一个水龙头一直在流水,拿水桶去接,可以等待一段时间接一桶,然后换个桶继续接,或者达到一定水量换一桶,这里桶就可以理解为窗口,水就是数据。
1、窗口分类
时间窗口
达到一定时间划分一个窗口
计数窗口
达到一定数据量划分一个窗口

窗口的具体实现可以分为4类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window),以及全局窗口(Global Window)
滚动窗口
根据时间或者数据个数进行滚动,当达到指定时间或者数据个数就滚动生成一个窗口,然后对窗口内的数据进行计算处理。比如:计算每个小时的订单数。

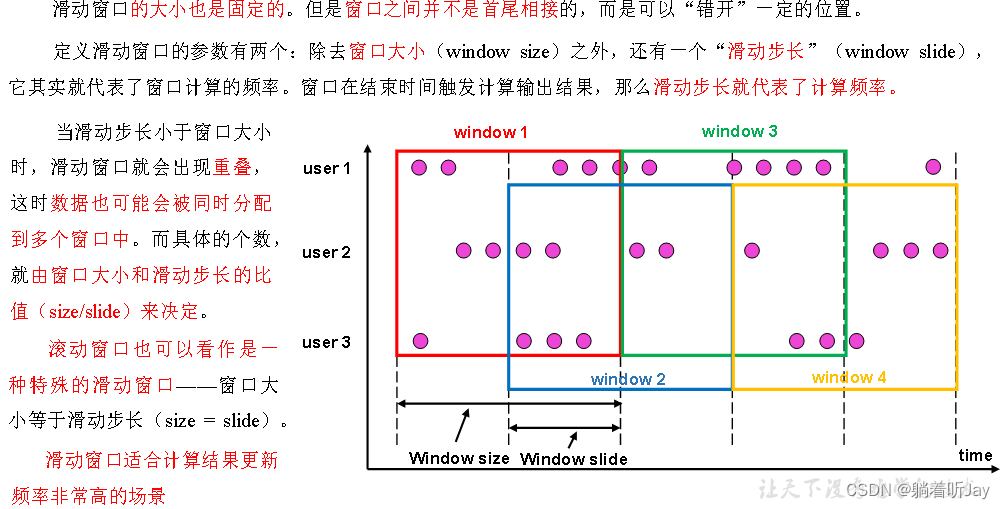
滑动窗口
例如,我们定义一个长度为 1 小时、滑动步长为 5 分钟的滑动窗口,那么就会统计 1 小时内的数据,每 5 分钟统计一次。同样,滑动窗口可以基于时间定义,也可以基于数据个数定义。
比如:统计最近一个小时订单数,每5分钟输出一次,那就可以定义一个长度为 1 小时、滑动步长为 5 分钟的滑动窗口。
会话窗口
数据相邻时间超过指定时间,就会另起一个窗口来装数据。

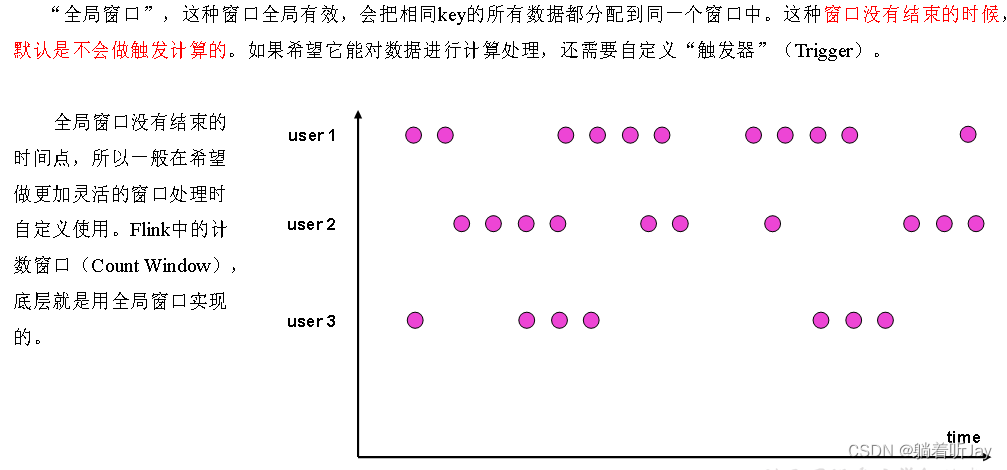
全局窗口
需要自定义触发器,触发窗口结束开始计算。
代码定义
// 基于时间的滚动窗口 窗口大小30s 30s新开一个窗口
AllWindowedStream<Person, TimeWindow> wsData = mapData.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(30)));
// 基于时间的滑动窗口 窗口大小是30s 滑动步长5s(5s计算一次)
AllWindowedStream<Person, TimeWindow> slideWSData = mapData.windowAll(SlidingProcessingTimeWindows.of(Time.seconds(30), Time.seconds(5)));
// 基于时间的会话窗口 会话时长30s 30s没数据来就新开一个窗口
AllWindowedStream<Person, TimeWindow> sessionWSData = mapData.windowAll(ProcessingTimeSessionWindows.withGap(Time.seconds(30)));
// 全局窗口需要配合自定义触发器
mapData.windowAll(GlobalWindows.create());2、窗口函数
增量聚合函数
数据来一条处理一条,数据来一条就和上一条数据执行增量聚合函数,然后在窗口大小结束后输出计算结果,因为毕竟flink还是流式的处理,所以这边就是我还没到窗口大小,但是我一来数据我就处理,然后在窗口大小结束后输出结果,否则你在窗口大小结束在计算窗口中的数据显然效率不好。
归约函数(ReduceFunction)
来一条数据就和上一条数据执行归约函数,然后窗口大小结束输出一次计算结果。
/**
* 输入的数据:
* id age name
* 1,1,1
* 1,1,2
* 1,1,3
* 1,1,4
* 1,1,5
* 1,1,6
* 1,1,7
* 1,18,8
*
* 输出:
* reduce函数执行了1--2
* reduce函数执行了2--3
* reduce函数执行了3--4
* reduce函数执行了4--5
* reduce函数执行了5--6
* 11> Person{id=1, age=6, name='6'} 30s窗口计算一次输出
* reduce函数执行了7--8
* 12> Person{id=1, age=19, name='8'} 然后就新开一个窗口也是30s计算输出,看前面的12>就知道不是同一个线程
*/
SingleOutputStreamOperator<Person> reducedData = wsData.reduce((ReduceFunction<Person>) (value1, value2)
-> {
System.out.println("reduce函数执行了" + value1.getName() + "--" + value2.getName());
return new Person(value2.getId(), value1.getAge() + value2.getAge(), value2.getName());
});
reducedData.print();
env.execute();聚合函数(AggregateFunction)
ReduceFunction可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。
Flink Window API中的aggregate就突破了这个限制,可以定义更加灵活的窗口聚合操作。这个方法需要传入一个AggregateFunction的实现类作为参数。
全窗口函数
有些场景下,我们要做的计算必须基于全部的数据才有效,这时做增量聚合就没什么意义了。
全窗口函数是数据来了先不计算,在内部缓存起来,等到窗口大小结束要输出结果的时候再取出数据进行计算。
/**
* 全窗口函数
*/
public class AllWindowFunc {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 源数据流
DataStreamSource<String> dataStreamSource = env.socketTextStream("192.168.10.102", 9999);
// map过的数据流
SingleOutputStreamOperator<Person> mapData = dataStreamSource.map((MapFunction<String, Person>) value -> {
String[] split = value.split(",");
try {
return new Person(Integer.parseInt(split[0]), Integer.parseInt(split[1]), split[2]);
} catch (NumberFormatException e) {
e.printStackTrace();
System.out.println("发生异常");
return null;
}
});
// 基于时间的滚动窗口
AllWindowedStream<Person, TimeWindow> WSData = mapData.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(30)));
/**
* ProcessAllWindowFunction<IN,OUT,W>:
* <IN> – 输入的数据类型.
* <OUT> – 输出的结果类型.
* <W> – 窗口类型.
*/
SingleOutputStreamOperator<String> allWData = WSData.process(new ProcessAllWindowFunction<Person, String, TimeWindow>() {
/**
*
* @param context 上下文对象,可以获取窗口对象,侧输出等等
* @param elements 窗口收集的数据
* @param out 收集器,收集器里面就是这个窗口的计算处理结果
* @throws Exception
*/
@Override
public void process(Context context, Iterable<Person> elements, Collector<String> out) throws Exception {
System.out.println("开始计算数据");
TimeWindow window = context.window();
String winStartTime = MyUtil.parseLongTime(window.getStart(), "yyyy-MM-dd HH:mm:ss");
String winEndTime = MyUtil.parseLongTime(window.getEnd(), "yyyy-MM-dd HH:mm:ss");
out.collect("窗口开始时间:" + winStartTime + ",窗口结束时间:" + winEndTime + ",窗口数据有:" + elements.toString());
}
});
/**
* 输入的数据:
* id age name
* 1,1,1lin
* 1,1,2lin 30s
*
* 1,1,3lin
* 1,1,4lin
* 1,1,5lin
* 1,1,6lin 30s
*
* 输出的数据:
* 开始计算数据
* 12> 窗口开始时间:2023-12-15 11:00:00,窗口结束时间:2023-12-15 11:00:30,窗口数据有:[Person{id=1, age=1, name='1lin'}, Person{id=1, age=1, name='2lin'}]
* 开始计算数据
* 1> 窗口开始时间:2023-12-15 11:00:30,窗口结束时间:2023-12-15 11:01:00,窗口数据有:[Person{id=1, age=1, name='3lin'}, Person{id=1, age=1, name='4lin'}, Person{id=1, age=1, name='5lin'}, Person{id=1, age=1, name='6lin'}]
*/
allWData.print();
env.execute();
}
}触发器
触发器主要是用来控制窗口什么时候触发计算。所谓的“触发计算”,本质上就是执行窗口函数,所以可以认为是计算得到结果并输出的过程。
基于WindowedStream调用.trigger()方法,就可以传入一个自定义的窗口触发器(Trigger)。
stream.keyBy(...)
.window(...)
.trigger(new MyTrigger())移除器
移除器主要用来定义移除某些数据的逻辑。基于WindowedStream调用.evictor()方法,就可以传入一个自定义的移除器(Evictor)。Evictor是一个接口,不同的窗口类型都有各自预实现的移除器。
stream.keyBy(...)
.window(...)
.evictor(new MyEvictor())flink时间
一些报错
提交任务后报错:
2023-12-12 10:21:35,243 WARN akka.remote.ReliableDeliverySupervisor [] - Association with remote system [akka.tcp://flink-metrics@hadoop102:46371] has failed, address is now gated for [50] ms. Reason: [Association failed with [akka.tcp://flink-metrics@hadoop102:46371]] Caused by: [java.net.ConnectException: 拒绝连接: hadoop102/192.168.10.102:46371]
因为flink程序中通过socket连接到9999端口,但是这个服务没开,就导致连接失败。通过nc -lk 9999 这将使 netcat 在本地监听端口 9999,并保持连接。可以通过在另一个终端窗口中使用 netcat 或其他工具建立到该端口的连接,实现简单的网络通信。
编码实操
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();在Apache Flink的默认配置下,当你调用StreamExecutionEnvironment.getExecutionEnvironment()时,它会自动使用本地环境进行执行,也就是说会在本地启动一个Flink集群,使用默认配置。
这种方式对于本地开发和测试是非常方便的,因为它无需额外的配置,你可以立即开始编写和运行Flink程序。但是在生产环境中,你通常需要配置Flink集群的地址和端口等参数,以便连接到真实的Flink集群。
















 5820
5820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











