






1.0 为什么要使用RDD?🐰
-
分布式计算需要:
分区控制、shuffer控制、数据存储/序列化、发送、数据计算
在分布式框架中,需要有一个统一的数据抽象对象来实现上述分布式计算所需的功能,
这个数据抽象对象就是RDD
1.1 RDD 是什么?-- 弹性分布式数据集
- R : 弹性 :数据可以存放在内存中也可以存储在磁盘中
- D :分布式 :分布式存储,用于分布式计算,RDD的数据是跨越机器存储(跨进程)
- D :数据集 :是一个数据的集合,用于存放数据 ( 类使用 list、Dict、array)
RDD 的定义:
-
RDD(Resilient Distributed Dataset)弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
-
所有的运算以及操作都建立在 RDD 数据结构的基础之上。
-
可以认为RDD是分布式的列表List或数组Array,抽象的数据结构,RDD是一个抽象类Abstract Class和泛型Generic Type
1.3 RDD 的五大特性
-
RDD 是有分区的
RDD 的分区是 RDD 数据的存储的最小单位
一份RDD的数据本本质上是分割了多少个分区
比如:1一个RDD有三个分区,123456,会分割为 [1,2] , [3,4] , [5,6]
-
RDD 的计算方法会作用在其 所有 的分区
简单来说:3个分区,在执行了map操作将数据都乘10,可以看到3个分区都乘以10了
-
RDD 之间是有依赖关系的( RDD 有血缘关系)
-
Key-Value 型的 RDD 可以有分区器
-
RDD 的分区规划,会尽量靠近数据所在的服务器
这样可以走
本地读取,避免网络读取本地读取:Executor 所在的服务器,同样是一个DataNode,同时这个DataNode上有它要读的数据,所以可以直接读取机器硬盘即可,无需走网络读取网络读取:读取数据需要经过网络的传输才能读取到
2.0 RDD编程入门
2.1 程序执行入口 SparkContext对象
Spark RDD 编程的程序入口对象是SparkContext对象(不论何种编程语言)
只有构建出SparkContext,基于它才能执行后续的API调用和计算,其主要功能就是创建第一个RDD
2.2 RDD的创建
概念:并行化创建,本地集合–>转向分布式RDD
rdd = sparkcontext.parallelize(参数1,参数2)
# 参数1 集合对象即可,比如list
# 参数2 分区数
完整代码
#conding:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':
# 构建Spark执行环境
conf = SparkConf().setAppName("create rdd").setMaster("local[*]")
sc = SparkContext(conf=conf)
#sc对象的parallize方法,将本地集合转换为分布式RDD
data = [1,2,3,4,5,6,7,8]
rdd = sc.parallelize(data,numSlices=3)
rdd.foreach(print)
读取文件创建:可以读取本地文件,可以读取hdfs数据
sparkcontest.textFile(参数1,参数2)
#参数1,必填,文件路径支持本地路径、HDFS 也支持一些比如S3协议
#参数2,可选,标识最小分区数量
#注意:参数2,话语权不足,spark有自己的判断,在它允许的范围内,参数2有效果,超出spark允许的范围,参数2失效
完整代码
#conding:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':
# 构建Spark执行环境
conf = SparkConf().setAppName("create rdd").setMaster("local[*]")
sc = SparkContext(conf=conf)
#textFile API 读取文件
rdd = sc.textFile("../data/words.txt",1000)
print(rdd.getNumPartitions())
rdd2 = sc.textFile("hdfs://master:8020/input/words.txt",1000)
# 最小分区数给了1000,但是实际就开了85个,spark没有理会你要求最少1000的要求而是尽量多开
print(rdd2.getNumPartitions())
rdd.foreach(print)
读取文件创建:读取一堆小文件
sparkcontext.wholeTextFiles(参数1,参数2)
#参数1,必填,文件路径支持本地路径、HDFS 也支持一些比如S3协议
#参数2,可选,标识最小分区数量
#注意:参数2,话语权不足,spark有自己的判断,在它允许的范围内,参数2有效果,超出spark允许的范围,参数2失效
2.3 RDD算子
算子:分布式集合对象上的 API 称之为算子
而本地的我们称之为方法
2.3.1 算子的分类🤒
- Transformation:转换算子
- Action:行动算子
Transformation 算子
定义:返回值
是一个RDD的,就是转换算子
Action算子
定义:返回值
不是rdd的就是行动算子
简单来说:转换算子就是流水线上的工序,数据则是物料,只有行动算子到了,这个数据处理的流水线才开始工作

2.4 常见的 Transformation 算子(转换算子)🏏
1. M a p 算 子 − T r a n s f o r m a t i o n \textcolor{Magenta}{1.Map算子 - Transformation} 1.Map算子−Transformation
功能:map算子,是
将RDD的数据一条条处理( 处理的逻辑基于map算子中接受的处理函数 )返回新的 RDD

完整代码
data = [1,2,3,4,5,6]
rdd1 = sc.parallelize(data,2)
# 定义方法,作为算子的传入函数体
def add(data):
return data * 10
# 定义 lambda
print(rdd1.map(lambda x: x * 10).collect())
2. f l a t M a p 算 子 − T r a n s f o r m a t i o n \textcolor{Magenta}{2. flatMap算子 - Transformation} 2.flatMap算子−Transformation
功能:对rdd执行map操作,然后进行
解除嵌套操作
解除嵌套:
# 嵌套的list
lst = [[1,2,3],[4,5,6],[7,8,9]]
# 如果解除了嵌套
lst = [1,2,3,4,5,6,7,8,9]
完整代码
data = ["hadoop hadoop hadoop","spark spark spark","kafka flink shy"]
rdd1 = sc.parallelize(data)
# 用 map 进行切分
print(rdd1.map(lambda x: x.split(" ")).collect())
# [['hadoop', 'hadoop', 'hadoop'], ['spark', 'spark', 'spark'], ['kafka', 'shy']]
# 用flatMap 进行切分的同时进行了解除嵌套操作
print(rdd1.flatMap(lambda x: x.split(" ")).collect())
# ['hadoop', 'hadoop', 'hadoop', 'spark', 'spark', 'spark', 'kafka', 'shy']
3. r e d u c e B y K e y 算 子 − T r a n s f o r m a t i o n \textcolor{Magenta}{3. reduceByKey算子 - Transformation} 3.reduceByKey算子−Transformation
功能:
针对KV型RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作
用法:
rdd.reduceByKey(func)
#func:(V,V) -> V
# 接受2个传入参数,类型需要一致,返回一个返回值,类型和传入要求一致

reduceByKey中的聚合逻辑:[1,2,3,4,5]聚合函数为:lambda a,b:a+b

完整代码
rdd = sc.parallelize[('a',1),('a',1),('b',1),('a',1)]
# reduceByKey 对相同的Key执行聚合操作
print(rdd.reduceByKey(lambda a,b:a+b).collect())
注意:reduceByKey只负责聚合,不理会分组,分组是自动by Key来分组的
4. m a p V a l u e s 算 子 − T r a n s f o r m a t i o n \textcolor{Magenta}{4. mapValues算子 - Transformation} 4.mapValues算子−Transformation
功能:针对
二元组RDD,对其内部的二元元组的Value执行Map操作
语法:
rdd.mapValues(func)
# 传入的参数,是二元元组的 value 值
# 这个方法只对 value 进行处理
完整代码
data = [('a',1),('b',2),('c',3)]
rdd = sc.parallelize(data)
# 如果使用map
print(rdd.map(lambda x: (x[0], x[1] * 10)).collect())
# 结果 [('a', 10), ('b', 20), ('c', 30)]
# 使用mapValue就比较简单
print(rdd.mapValues(lambda x: x * 10).collect())
# 结果 [('a', 10), ('b', 20), ('c', 30)]
2.4.1 WordCount 案例回顾
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("WordCountHelloWord")
# 通过 SparkConf 对象构建 SparkContext 对象
sc = SparkContext(conf=conf)
# 需求 : wordcount 单词计数,读取HDFS上的words.txt文件,对其内部的单词进行计数
# 1. 读取文件
file_rdd = sc.textFile("file:///D:/bigdata/spark-3.0.3-bin-hadoop2.7/README.md")
# 2. 通过 flatMap 取出所有单词
words_rdd = file_rdd.flatMap(lambda line:line.split(" "))
# 3. 将单词转换为元组对象,key是单词,v是数字1
words_one = words_rdd.map(lambda x: ( x , 1) )
# 4. 将元组的value,按照key进行分组,对所有的value进行聚合
result_rdd = words_one.reduceByKey(lambda a,b:a+b)
# 5. 通过collect算子,将rdd的数据收集到Driver中,并打印输出
print(result_rdd.collect())
5. g r o u p B y 算 子 − T r a n s f o r m a t i o n \textcolor{Magenta}{5. groupBy算子 - Transformation} 5.groupBy算子−Transformation
功能:将rdd的数据进行分组,通过这个函数,确定按照谁来分组(返回谁即可)

完整代码
rdd = sc.parallelize([('a'),1],[('a'),1],[('a'),3],[('b'),2],[('b'),1])
# 通过groupBy对数据进行分组
# groupBy 传入的函数的意思是:通过这个函数,确定按照谁来分组(返回谁即可)
# 分组规则 和 SQL 是相同的
rdd = sc.parallelize(data)
result = rdd.groupBy(lambda t:t[0])
print(result.collect())
#结果为:[('b', <pyspark.resultiterable.ResultIterable object at 0x1515A448>)]
# ResultIterable 可迭代对象。 我们进行一个迭代将他转换为list就可以了,可以使用map函数
print(result.map(lambda t: (t[0], list(t[1]))).collect())
#[('b', [('b', 2), ('b', 4), ('b', 4), ('b', 4)]), ('a', [('a', 1), ('a', 3), ('a', 4)])]
6. F i l t e r 算 子 − T r a n s f o r m a t i o n \textcolor{Magenta}{6. Filter算子 - Transformation} 6.Filter算子−Transformation
功能:把不想要的数据过滤掉
⚠️ 返回是True的数据被保留,False的数据被丢弃
完整代码
rdd = sc.parallelize([1,2,3,4,5,6,7])
# 通过Filter算子,过滤奇数
result = rdd.filter(lambda x:x%2 == 1)
print(result.collect()) #[1,3,5,7]
7. d i s t i n c t 算 子 − T r a n s f o r m a t i o n \textcolor{Magenta}{7. distinct算子 - Transformation} 7.distinct算子−Transformation
功能:对RDD数据进行去重,返回新的RDD
完整代码
rdd = sc.parallelize([1,2,3,4,5,6,6,7,7,7])
# 按照空格切分数据后,解除嵌套
print(rdd.distinct().collect())
rdd2 = sc.parallelize([('a',1),('a',1),('b',2)])
# 只要数据相同就会去重
print(rdd.distinct().collect()) #('a',1),('b',2)
8. u n i o n 算 子 − T r a n s f o r m a t i o n \textcolor{Magenta}{8. union算子 - Transformation} 8.union算子−Transformation
功能:2个rdd合并成1个rdd返回
⚠️只合并,不去重
完整代码
rdd = sc.parallelize([5,9,9,9])
rdd2 = sc.parallelize(['lxy','shy'])
# 类型不同也可以合并
union_rdd = rdd1.union(rdd2)
print(union_rdd.collect())
# 结果
[5,9,9,9,'lxy','shy']
9. j o i n 算 子 − T r a n s f o r m a t i o n \textcolor{Magenta}{9. join算子 - Transformation} 9.join算子−Transformation
功能:对两个RDD执行JOIN操作(可实现SQL的内\外连接)
⚠️join只能用于二元元组

完整代码
rdd = sc.parallelize([ (1001,"shy"),(1002,"lxy"),(1003,"wangwu") ])
rdd1 = sc.parallelize([ (1001,"销售部"), (1002,"科技部") ])
# 通过join算子来进行rdd之间的关联
# 通过join算子来说关联条件,按照二元组的K来进行关联
print(rdd.join(rdd1).collect())
#[(1001, ('shy', '销售部')), (1002, ('lxy', '科技部'))]
#左外连接,右外连接 可以更换一下rdd的顺序,或调用rightOutJoin即可
#
print(rdd1.leftOuterJoin(rdd).collect())
10. i n t e r s e c t i o n 算 子 − T r a n s f o r m a t i o n \textcolor{Magenta}{10. intersection算子 - Transformation} 10.intersection算子−Transformation
功能:求2个rdd的交集,返回一个新的rdd
什么是交集:你有我也有的,就算交集
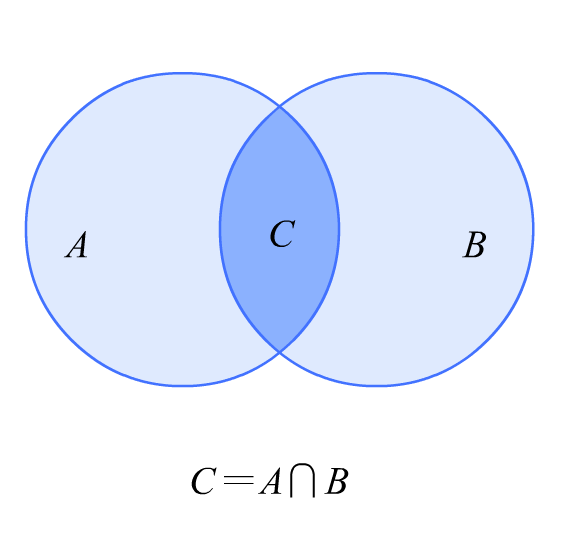
完整代码
rdd1 = sc.parallelize(['a',1],['b',1])
rdd2 = sc.parallelize(['a',1],['c',1])
result = rdd1.intersection(rdd2)
#结果
[('a',1)]
11. g l o m 算 子 − T r a n s f o r m a t i o n \textcolor{Magenta}{11.glom 算子 - Transformation} 11.glom算子−Transformation
功能:将RDD数据,加上嵌套,这个嵌套按照
分区来进行
比如:RDD数据[1,2,3,4] 有2个分区
那么,被glom后,数据变成[ [1,2,3,4],[4,5] ]
完整代码
rdd2 = sc.parallelize([1,2,3,4,5,6,7],2)
print(rdd2.glom().collect())
# [[1, 2, 3], [4, 5, 6, 7]]
# 如何进行解除嵌套
print(rdd2.glom().flatMap(lambda x: x).collect())
# [1, 2, 3, 4, 5, 6, 7]
12. g r o u p B y K e y 算 子 − T r a n s f o r m a t i o n \textcolor{Magenta}{12.groupByKey 算子 - Transformation} 12.groupByKey算子−Transformation
功能:
针对KV型RDD,自动按照key进行分组
如果是二元元组并且以key为条件的建议使用groupByKey,如果不是的话就可以使用groupBy
完整代码
rdd = sc.parallelize( [ ('a',1),('a',2),('b',1),('b',2) ] )
grouped_rdd = rdd.groupByKey()
# 这一步是将迭代数据变成list循环写出,与groupBy不同的是 他的数据是[('b',[1,2,3])]
print(grouped_rdd.map(lambda x:(x[0],list(x[1]))).collect())
13. s o r t B y 算 子 − T r a n s f o r m a t i o n \textcolor{Magenta}{13.sortBy 算子 - Transformation} 13.sortBy算子−Transformation
功能:对RDD数据进行排序,基于你指定的排序依据
⚠️如果要全局有序,排序分区请设置为1,如果是别的话他只能保证分区间有序
语法:
rdd.sortBy(func,ascending=Flase,numPartitionse=1)
# func:(T) -> U 告知rdd中的哪个数据进行排序,比如 lambda x:x[1] 表示按照rdd中的第二列元素进行排序
# ascending : True升序,False降序
# numPartitions : 用多少分区排序
完整代码:
rdd4= sc.parallelize([('c', 1), ('f', 4), ('d', 5), ('a', 2), ('s', 3), ('d', 6), ('x', 9), ('b', 2)])
#按照V来进行升序排序
print(rdd4.sortBy(lambda x: x[1], ascending=True, numPartitions=3).collect())
#按照K进行降序排序
print(rdd4.sortBy(lambda x: x[0], ascending=False, numPartitions=1).collect())
14. s o r t B y K e y 算 子 − T r a n s f o r m a t i o n \textcolor{Magenta}{14.sortByKey算子 - Transformation} 14.sortByKey算子−Transformation
功能: 针对
KE型RDD,按照key进行排序
语法:sortByKey(ascending=True,numPartitions=None,keyfunc=<function RDD.<lambda>>)
ascending: 升序or降序,True升序,False降序,默认是升序numPartitions:按照几个分区进行排序,如果全局有序,设置1keyfunc:在排序前对key进行处理,语法是:(K) -> U,一个参数传入,返回一个值
完整代码:
rdd5 = sc.parallelize([('c', 1), ('F', 4), ('d', 5), (' A', 2), ('s', 3), ('D', 6), ('x', 9),('b', 2), ('B',2) ])
# 将所有 K 的英文字母都转换为小写,但是元数据不会被改变
print(rdd5.sortByKey(ascending=False, numPartitions=1, keyfunc=lambda key: str(key).lower()).collect())
2.5 常见的 Action 算子 🚡
1. c o u n t B y K e y 算 子 − A c t i o n \textcolor{ForestGreen}{1.countByKey算子 - Action} 1.countByKey算子−Action
功能: 统计
key出现的次数(一般适用于KV型RDD)
完整代码:
rdd = sc.parallelize("hadoop hadoop hadoop spark spark flink")
rdd1 = rdd.flatMap(lambda x:x.split(" ")),map(lambda x:(x,1))
#通过countByKey来对key进行计数,这是一个Action算子
result = rdd1.countByKey()
print(result)#{'hadoop':3,'spark':2,'flink':1}
print(type(result))#collections.defaultdict
2. c o l l e c t 算 子 − A c t i o n \textcolor{ForestGreen}{2.collect算子 - Action} 2.collect算子−Action
功能: 将RDD各个分区内的数据,统一收集到Driver中,形成一个List对象
用法:rdd.collect()
⚠️ 这个算子,是将RDD各个分区的数据 都拉取到Driver
注意的是,RDD分区是分布式对象,其数据量可以很大,所以用这个算子之前
要心知肚明的了解 结果数据集不会太大
不然,会把Driver内存撑爆
3. r e d u c e 算 子 − A c t i o n \textcolor{ForestGreen}{3.reduce算子 - Action} 3.reduce算子−Action
功能:对RDD数据集按照你传入的逻辑进行聚合
与 reduceByKey不同的是:返回值不是
RDD
完整代码:
rdd = sc.parallelize([1,2,3,4])
# 将rdd的数据进行累加求和
print(rdd.reduce(lambda a,b:a+b)) #10

4. f o l d 算 子 − A c t i o n \textcolor{ForestGreen}{4.fold算子 - Action} 4.fold算子−Action
功能:和reduce一样,会对数据进行聚合,但是他是带有初始值的
这个初始值聚合,会作用在:
- 分区内聚合
- 分区间聚合
- 没有分区的情况下

例子:[ [1,2,3],[4,5,6],[7,8,9] ]
数据分布在3个分区内
分区1 :123聚合的时候带上10作为初始值得到 16
分区2: 456聚合的时候带上10作为初始值得到 25
分区3 :789聚合的时候带上10作为初始值得到 34
最后,分区间计算:
16+25+34 = 85
完整代码:
rdd = sc.parallelize(range(1,9),3)
print(rdd.fold(10,lambda a,b:a+b))
# 结果:85
5. f i r s t 算 子 − A c t i o n \textcolor{ForestGreen}{5.first算子 - Action} 5.first算子−Action
功能:取出RDD的第一个元素
用法
sc.parallelize([3,2,1]).first()
#输出:3
6. t a k e 算 子 − A c t i o n \textcolor{ForestGreen}{6.take算子 - Action} 6.take算子−Action
功能:取出RDD的前N个元素,组合成list返回给你
用法:
sc.parallelize([3,2,1,4,5,6]).take(5)
[3,2,1,4,5] #获取前5个
7. t o p 算 子 − A c t i o n \textcolor{ForestGreen}{7.top算子 - Action} 7.top算子−Action
功能:对RDD数据集进行降序排序,取前N个
用法:
sc.parallelize([3,2,1,4,5,6]).top(3) # top3 表示降序排序取前3个
[6,5,4]
8. c o u n t 算 子 − A c t i o n \textcolor{ForestGreen}{8.count算子 - Action} 8.count算子−Action
功能:计算RDD有多少条数据,返回值是一个数字
用法:
sc.parallelize([3,2,1,4,5,6]).count()
6
9. t a k e S a m p l e 算 子 − A c t i o n \textcolor{ForestGreen}{9.takeSample算子 - Action} 9.takeSample算子−Action
功能:随机抽样RDD的数据
用法:
takeSample( 参数1:True or Flase, 参数2:采样数, 参数3:随机种子 )
- 参数1:True表示运行取同一个数据,False表示不允许取同一个数据,和数据内容无关,是否重复表示的是同一个位置的数据
- 参数2:抽样要几个
- 参数3:随机数种子,这个参数传入一个数字即可,随意给
⚠️ 随机数种子 数字可以随便传,如果传同一个数字,那么取出的结果是一致的.
一般参数3 我们不传,Spark会自动给与随机的种子
完整代码:
rdd = sc.parallelize([1,3,5,3,1,3,2,6,7,8,6],1)
print(rdd.takeSample(False,22)) #不取出抽样的数据,并且抽样22个
10. t a k e O r d e r e d 算 子 − A c t i o n \textcolor{ForestGreen}{10.takeOrdered算子 - Action} 10.takeOrdered算子−Action
功能:对RDD进行排序取前N个
用法:
rdd.takeOrdered(参数1,参数2)
- 参数1 要几个数据
- 参数2 对排序的数据进行更改(不会更改数据本身,只是在排序的时候换个样子)
这个方法使用安装元素自然顺序升序排序,如果你想玩倒序,需要用参数2 来对排序的数据进行处理
完整代码:
rdd = sc.parallelize([1,3,2,4,7,9,6],1)
print(rdd.takeOrdered(3)) # [1,2,3]
#将数字转换为负数,那么原本正数最大的,反而变成排序中最小的,固出现在最前端
print(rdd.takeOrdered(3,lambda x:-x))# [9,7,6]
11. f o r e a c h 算 子 − A c t i o n \textcolor{ForestGreen}{11.foreach算子 - Action} 11.foreach算子−Action
功能:对每一个元素,执行你提供的逻辑操作(和map一个意思),但是没有返回值
完整代码:
rdd = sc.parallelize([1,3,2,4,9,6],1)
# 对数据执行乘以10的操作
# 注意,函数不能给返回值,所以在里面直接打印了
r = rdd.foreach(lambda x: x * 10 )
print(r) #这个r对象,是None,因为foreach没有返回值
lambda x:print(x*10) 就可以了
12. s a v e T e x t F i l e 算 子 − A c t i o n \textcolor{ForestGreen}{12.saveTextFile算子 - Action} 12.saveTextFile算子−Action
功能:将RDD的数据写入文本文件中,支持本地写出hdfs等文件系统
完整代码:这一届网课包含:数据同步到hdfs的操作
rdd = sc.parallelize([1,3,2,4,7,9,6],3)
rdd.saveAsTextFile("hdfs://master:8020/output/111111")

注意点:
我们学习的action中
- foreach
- saveAsTextFile
这两个算子是分区(Executor直接执行的)
跳过Driver,由分区所在的Executor直接执行
反之:其余的Action算子都会将结果发送至Driver
2.6 分区操作算子
1. m a p P a r t i t i o n s 算 子 − T r a n s f o r m a t i o n \textcolor{Brown}{1.mapPartitions算子-Transformation} 1.mapPartitions算子−Transformation
功能:与map算子功能相同,但它是
将一个分区直接进行处理作为一个迭代器(一次性list)传递过来💻CPU处理上可能没有区别,但是在空间IO上大大的提高了效率

完整代码:
rdd = sc.parallelize[(1,3,2,4,7,9,6),3]
def process(iter):
result = list()
for it in iter:
result.append(it * 10)
return result
print(rdd.mapPartitions(process).collect())
2. f o r e a c h P a r t i t i o n s 算 子 − T r a n s f o r m a t i o n \textcolor{Brown}{2.foreachPartitions算子-Transformation} 2.foreachPartitions算子−Transformation
功能:和普通foreach一致,一次处理的是一整个分区数据
🐯: foreachPartition 就是一个 foreach 加强版,性能会更好
rdd = sc.parallelize[(1,3,2,4,7,9,6),3]
def process(iter):
result = list()
for it in iter:
result.append(it * 10)
#return result 因为没有返回值,所以不需要return
print(rdd.foreachPartitions(process)) #其实不需要print的
3. p a r t i t i o n B y 算 子 − T r a n s f o r m a t i o n \textcolor{Brown}{3.partitionBy算子-Transformation} 3.partitionBy算子−Transformation
功能:对RDD进行自定义分区操作
用法:
rdd.partitionBy(参数1,参数2) - 参数1 重新分区后有几个分区 - 参数2 自定义分区规则,函数传入 参数2:(K) -> int 一个传入参数进来,类型无所谓,但是返回值一定是int类型 将key传给这个函数,你自己写逻辑,决定返回一个分区编号 分区编号从0开始,不要超出分区数-1
完整代码:
rdd = sc.parallelize([('hadoop',1),('spark',1),('hello',1),('flink'),1,('hadoop',1),('spark',1)])
def partition_self(key):
# 数据的key给你,决定返回分区号即可
if 'hadoop' == key or 'hello' == key:return 0
if 'spark' == key : return 1
return 2
print(rdd.partitionBy(3,partition_slef).glom.collect())
#结果
[[('hadoop',1)('hello',1)('hadoop',1)],[('spark',1),('spark',1)],[('flink',1)]]
4. r e p a r t i t i o n 算 子 − T r a n s f o r m a t i o n \textcolor{Brown}{4.repartition算子-Transformation} 4.repartition算子−Transformation
功能:对RDD的分区执行重新分区(仅数量)
用法:
rdd.repartition(N) 传入N决定新的分区数
注意:
⚠️ 对分区的数量进行操作,一定要慎重
一般情况下,我们写Spark代码,除了要求全局排序设置为1个分区外
多数时候,所有API中关于分区相关的代码我们都不太理会
因为如果你改分区了:
1️⃣ 会影响并行计算(内存迭代的并行管道数量)
2️⃣ 分区如果增加,
极大可能导致shuffle
5. c o a l e s c e 算 子 − T r a n s f o r m a t i o n \textcolor{Brown}{5.coalesce 算子-Transformation} 5.coalesce算子−Transformation
功能:对分区数量进行增减
用法:
rdd.coalesce(参数1,参数2) - 参数1,分区数 - 参数2,True or False True 表示允许shuffle,也就是可以加分区 Flase 表示不允许shuffle,也就是不能加分区,False是默认⚠️ 对比repartition,一般使用coaless较多,因为加分区要写参数2
这样避免写入repartition的时候手抖加分区了
完整代码:
rdd = sc.parallelize([1,2,3,4,5],3)
# repartition 修改分区
print(rdd.repartition(1).getNumPartitions())
print(rdd.repartition(5).getNumPartitions())
# coalesce
print(rdd.coalesce(1).getNumPartitions())
print(rdd.coalesce(5,shuffle=True).getNumPartitions())
2.7 groupByKey 和 reduceByKey的区别
功能上的区别:
-
groupByKey 仅仅有分组功能而已
-
reduceByKey 除了有
ByKey的分组功能外,还有reduce聚合功能.所以是一个分组+聚合一体化的算子
3.1 RDD 的数据是过程数据
RDD 之间进行相互迭代计算(Transformation的转换),当执行开启后,新RDD的生成,代表老RDD的消失.
RDD 的数据是过程数据,只在处理的过程中存在,一旦处理完成,老RDD就不见了.
🍰 : 这个特性可以最大化利用资源,老旧RDD没用了,就从内存中清理,给后续的计算腾出内存空间。
但是对于我们来说,它这个性能损耗太夸张了。

3.2 RDD 的缓存
对于上述情况,我们需要执行优化:
RDD3不消失的话,RDD1->RDD2->RDD3这个链条就不会执行2次,或更多次
***RDD的缓存技术:***💃
Spark提供了缓存API,可以让我们通过调用API,将指定的RDD数据保存在
内存和硬盘上
🚱如果全放在内存的话,它会占用运行内存空间,影响我们的速度,因此提供了 内存 和 硬盘
# RDD3 被2次使用,可以加入缓存进行优化
rdd3.cache() # 缓存到内存中.
rdd3.persist(StorageLevel.MEMORY_ONLY) # 仅内存缓存
rdd3.persist(StorageLevel.MEMORY_ONLY_2) # 仅内存缓存,2个副本
rdd3.persist(StorageLevel.DISK_ONLY) # 仅缓存硬盘上
rdd3.persist(StorageLevel.DISK_ONLY_2) # 仅缓存硬盘上,2个副本
rdd3.persist(StorageLevel.DISK_ONLY_3) # 仅缓存硬盘上,3个副本
rdd3.persist(StorageLevel.MEMORY_AND_DISK) # 先放内存,不够放硬盘
rdd3.persist(StorageLevel.MEMORY_AND_DISK_2) # 先放内存,不够放硬盘,2个副本
rdd3.persist(StorageLevel.OFF_HEAP) # 堆放内存(系统内存)
# 如上API,自行选择使用即可
# 一般建议使用rdd3.persist(StorageLevel.MEMORY_AND_DISK)
# 如果内存比较小的集群,建议使用rdd3.persist(StorageLevel.DISK_ONLY) 或者别用缓存了 用CheckPoint
# 主动清理缓存的API
rdd.unpersist()
***cache如何将数据放在内存中去:***🐶
分散存储:将它分为多block块分配到多个hdfs里面存储
🍉 缓存的两大特点:分散存储、保留血缘关系

3.3 RDD 的 CheckPoint
与上面相同,也是将数据保存起来
但是仅支持硬盘存储
and
1️⃣ 被设计认为是安全的(除非物理攻击)
2️⃣ 不保留血缘关系
**特点:**CheckPoint 是集中收集各个分区数据进行存储, 而 缓存 是分散存储

😿 缓 存 和 C h e c k P o i n t 的 对 比 \textcolor{Brown}{缓存 和 CheckPoint 的对比} 缓存和CheckPoint的对比:
- CheckPoint:不管分区数量多少,风险都一样。 缓存:分区越多,风险越多
- CheckPoint,支持写入HDFS,缓存不行。HDFS是高可靠存储,CheckPoint被认为是安全的
- CheckPoint,不支持内存,缓存可以。缓存如果写内存 性能比 CheckPoint 要好一些
- CheckPoint,因为设计是安全的,所以不保留血缘关系,而缓存则相反。
完整代码:
# 设置CheckPoint第一件事情,选择CP的保存路径
# 如果Local模式,可以支持本地文件系统,如果在集群运行,千万要用HDFS
sc.setCheckpointDir("hdfs://master:8020/output/11111")
# 用的时候,直接调用checkpoint算子即可.
rdd.checkpoint()
以下不用看,导入文件出错了
=‘green’>血缘关系
**特点:**CheckPoint 是集中收集各个分区数据进行存储, 而 缓存 是分散存储
[外链图片转存中…(img-YmN4iUoE-1646913688181)]
😿$\textcolor{Brown}{缓存 和 CheckPoint 的对比} $:
- CheckPoint:不管分区数量多少,风险都一样。 缓存:分区越多,风险越多
- CheckPoint,支持写入HDFS,缓存不行。HDFS是高可靠存储,CheckPoint被认为是安全的
- CheckPoint,不支持内存,缓存可以。缓存如果写内存 性能比 CheckPoint 要好一些
- CheckPoint,因为设计是安全的,所以不保留血缘关系,而缓存则相反。
完整代码:
# 设置CheckPoint第一件事情,选择CP的保存路径
# 如果Local模式,可以支持本地文件系统,如果在集群运行,千万要用HDFS
sc.setCheckpointDir("hdfs://master:8020/output/11111")
# 用的时候,直接调用checkpoint算子即可.
rdd.checkpoint()
















 538
538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











