







1.java基本数据类型?
byte 1,short 2 ,int 4,long 8 ,float 4,double 8,boolean 1,char 2
2.java为什么要有包装类型?
前 6 个类派生于公共的超类
Number,而Character和Boolean是Object的直接子类。被
final修饰, Java 内置的包装类是无法被继承的。
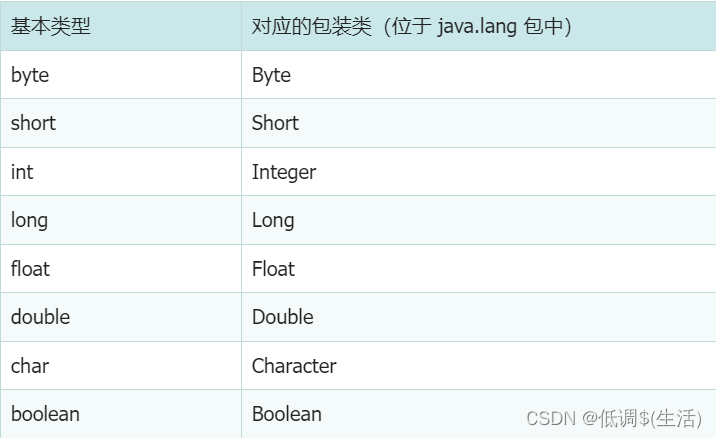
包装类作用
- 对象化 - 将基本数据类型用对象封装起来,实现一些特色的方法。
- 数据类型转换 - 通过包装类可以实现数据类型转换
- null值校验 - 例如如果基本数据类型没值的话,默认会给值,需要与数据库一致
装箱拆箱
- 装箱:将基本数据类型转换成包装类
- 拆箱:从包装类之中取出被包装的基本类型数据(使用包装类的 xxxValue 方法)
JDK 1.5 之后,Java 提供了自动装箱与自动拆箱的机制 , 主要依赖于valueOf和parseXXX方法实现。自动装箱和拆箱通常是由编译器在需要时自动进行的。
Integer obj = 10; // 自动装箱. 基本数据类型 int -> 包装类 Integer
int temp = obj; // 自动拆箱. Integer -> int
obj ++; // 直接利用包装类的对象进行数学计算
System.out.println(temp * obj); 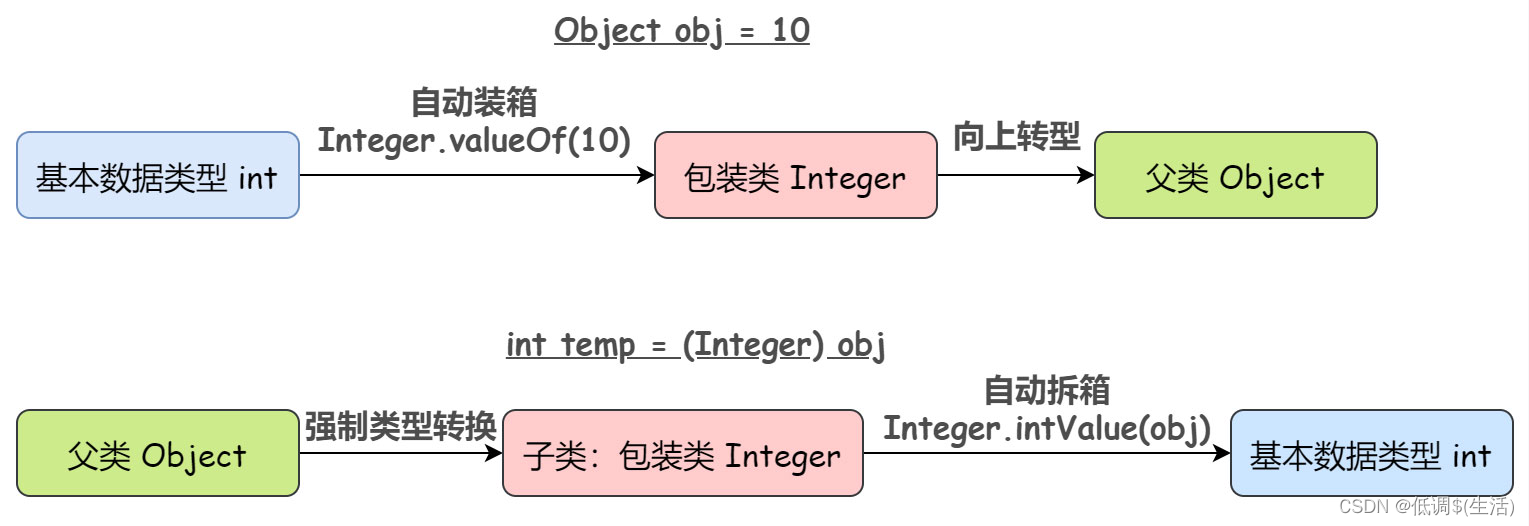
注意 - IntegerCache 内部类
Integer中有这个int缓存,当范围在-128 到 127之间,如果已经存在该对象,则之间复用,不新创建包装类。
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}Java自动装箱和自动拆箱_java自动拆箱和自动装箱-CSDN博客
3.string,stringbuilder,string buffer区别?
- string被final修饰,不可变字符串。
- stringbuilder可变字符串容器对象,线程不安全,效率比string高些
- stringbuffer可变字符串,线程安全,效率低。
String
1.8部分源码,类和变量value数组都是由final修饰,不可变。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
****
}StringBuilder
从以下部分源码可看出构造器调用父类方法进行扩容,说明操作的字符串在父类。然后继承的又只有一个,那就是AbstractStringBuilder类,线程不安全。
public final class StringBuilder extends AbstractStringBuilder implements java.io.Serializable, CharSequence
{
/** use serialVersionUID for interoperability */
static final long serialVersionUID = 4383685877147921099L;
/**
* Constructs a string builder with no characters in it and an
* initial capacity of 16 characters.
*/
public StringBuilder() {
super(16);
}
**************************
}然后发现这里操作的字符串没有用final修饰,那就是可变的。
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
char[] value;
/**
* The count is the number of characters used.
*/
int count;
****************************************************
}StringBuffer
可以看到,他们所继承的类都一样,不一样的是stringbuffer它重写了继承的方法,并且加上了synchronized关键字,所以线程安全。
public final class StringBuffer
extends AbstractStringBuilder
implements java.io.Serializable, CharSequence
{
private transient char[] toStringCache;
/** use serialVersionUID from JDK 1.0.2 for interoperability */
static final long serialVersionUID = 3388685877147921107L;
public StringBuffer() {
super(16);
}
public StringBuffer(int capacity) {
super(capacity);
}
public StringBuffer(String str) {
super(str.length() + 16);
append(str);
}
public StringBuffer(CharSequence seq) {
this(seq.length() + 16);
append(seq);
}
@Override
public synchronized int length() {
return count;
}
*******************************
}String、StringBuilder、StringBuffer、StringJoiner类的常用方法,以及区别_stringjoiner fangfa-CSDN博客
4.如何理解面向对象和面向过程?
面向过程就是以函数为主体,通过函数间互相调用实现目的,强调过程。
而面向过程就是将进行的操作封装到一个类中,通过类与类之间的调用实现目的。
5.面向对象的三大特性?
- 抽象,比如讲动物的名字封装成类变量,行为封装成动物方法。
- 封装,将变量和方法封装到对象中。
- 继承,类通过继承可以实现父类的方法,并使用。
- 多态,多个类可以继承一个父类,通过重写方法,实现不同的行为。
6.为什么浮点数不能表示金额?
因为浮点数会丢失精度,而且存储效率不如整型,所以一般正常生产中用bigint,且bigint计算高效。
7.什么是反射,为什么需要反射?*
反射是java作为动态语言的重要标志,通过反射,可以动态修改类的状态,内容。
创建反射的几种方式
Class<?> class=MyClass.class;
MyClass myClass=new MyClass();
Class<?> class=myClass.getClass();
Class<?> class=Class.forName("com.yy.xxx");利用反射对象操作类
调用构造参数创建类对象,简单写一下吧,如果有需要去下面的博客里看看。
User user = userClass.newInstance();
System.out.println(user);
Constructor<?>[] declaredConstructors = userClass.getDeclaredConstructors();
for (Constructor c:declaredConstructors) {
System.out.println(c.getParameterTypes());
}
Method[] methods = userClass.getMethods();
for (Method m:methods) {
System.out.println(m);
}
Field[] declaredFields = userClass.getDeclaredFields();
for (Field f:declaredFields) {
System.out.println(f.getName());
}
Java 中反射的概念、作用和特点,在什么情况下使用反射及使用实例_java反射的作用及应用场景-CSDN博客
8.为什么需要克隆?如何实现克隆??深拷贝和浅拷贝的区别?
因为经常我们业务上需要复制一份数据。
浅拷贝就是只复制表层对象,并不复制对象内部的对象.
深拷贝是对象及其对象内部对象都复制成新的对象.
他们都可以通过类实现cloneable接口重写clone方法
详情参考
Java深入理解深拷贝和浅拷贝区别_java深拷贝浅拷贝-CSDN博客
9.try-catch-finally 如果catch return了,那么还会执行finally嘛
会在return前执行finally。
10.String为什么被设计成不可变的?
- 字符串复用
- 线程安全
- hashcode 因为不可变,所以hashcode不用重新计算,并且很适合做key
string被final修饰,不可变。这样的好处可以实现字符串复用和线程安全。
当我们改变一个字符串值的时候,他是去创建一个新的字符串,然后把指针更改到新的位置。
Java 中 String 类为什么要设计成不可变的?-腾讯云开发者社区-腾讯云
11.error与exception的区别?以及常见的runtime exception?*
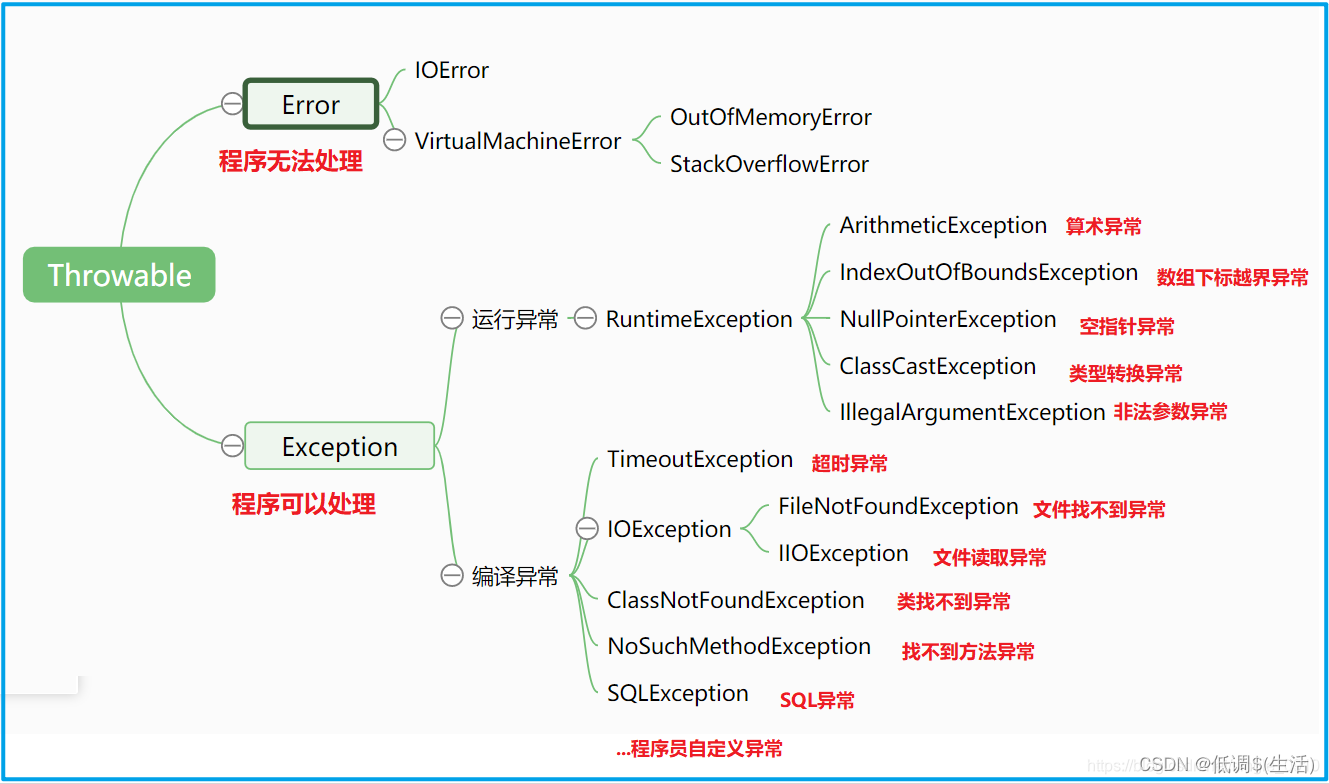
error是一些不可避免的错误,一般不是由于代码错误。
而exception分为运行时异常和编译时异常。
编译时异常try catch。
而运行时异常需要检查代码,比如空指针等等。
java之异常(Exception)与错误(Error)的区别_java中error和exception的区别-CSDN博客
12.抽象类和接口的区别?**
- 接口是定义一种规范,抽象类是定义一个模板。
- 接口没有构造方法。抽象类有构造方法。
- 接口成员变量默认由public static final修饰,必须赋初值,方法由public abstract修饰。抽象类成员变量么有限制,可以有构造方法,抽象方法或具体方法。
- 接口多实现,抽象类单继承。
13.==与equals区别?
在判断字符串时,==会判断内容和地址,而equals只判断内容,因为string重写了equals方法。
14.super和this区别?*
super调用父类方法,this调用子类的方法。
15.java集合类,特点?
- arraylist 基于数组实现,查找快,增删慢,线程不安全,默认长度为10,1.5倍扩容。
- linkedlist基于链表实现,查找慢,增删快。线程不安全。
- vector基于数组实现,线程安全,默认长度为10,2倍扩容。
- hashmap线程不安全,键值对,两倍扩容。底层使用了数组加链表加红黑树。
- concurrenthashmap线程安全。底层采用无冲突时采用乐观锁cas资源重试。冲突时采用synchronize锁代码块。需再看源码。
16.集合排序方案实现?***
Arrays类可以对数组排序
int[] arr = {1, 5, 2, 1, 4};
System.out.println("排序前:"+Arrays.toString(arr));
Arrays.sort(arr);
System.out.println("排序后:"+Arrays.toString(arr));Collections可以对list排序
List<String> list = new ArrayList<>();
list.add("b");
list.add("d");
list.add("ca");
list.add("da");
System.out.println("排序前:"+list);
Collections.sort(list);
System.out.println("排序后:"+list);
List<Person> list = new ArrayList<>();
list.add(new Person("李四1", 19));
list.add(new Person("张三1", 59));
list.add(new Person("张三2", 69));
list.add(new Person("张三3", 79));
list.add(new Person("张三4", 89));
System.out.println("按名字排序前:" + list);
Collections.sort(list, new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
//按名字排序
return o1.getName().compareTo(o2.getName());
}
});
System.out.println("按名字排序后:" + list);
System.out.println("按年龄排序前:" + list);
Collections.sort(list, new Comparator<Person>() {
@Override
public int compare(Person p1, Person p2) {
return p1.getAge() - p2.getAge();
}
});
System.out.println("按年龄排序后:" + list);实现comparable接口,重写compareTo方法
static class Person implements Comparable<Person> {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "[" + name + "," + age + "]";
}
@Override
public int compareTo(Person o) {
return Integer.compare(this.getAge(), o.getAge());
}
}
list.sort((o1, o2) -> o1.compareTo(o2));参考
一篇文章搞定Java中常用集合的排序方法_java 集合排序-CSDN博客
Java 中如何对集合进行排序_java集合排序-CSDN博客
17.arraylist,linkedlist,vector区别?*
- arraylist 基于数组实现,查找快,增删慢,线程不安全,默认长度为10,1.5倍扩容。
- linkedlist基于链表实现,查找慢,增删快。线程不安全。
- vector基于数组实现,线程安全,默认长度为10,2倍扩容。
ArrayList(1.8)
初始化
//默认容量
private static final int DEFAULT_CAPACITY = 10;
//用于空实例的共享空数组实例。
private static final Object[] EMPTY_ELEMENTDATA = {};
//用于默认大小空实例的共享空数组实例。我们区分它和EMPTY_ELEMENTDATA,
//以便在添加第一个元素时知道要扩展多少。
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//用于存储ArrayList元素的数组缓冲区。
//ArrayList的容量是这个数组缓冲区的长度。任何
//elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA的空ArrayList
//在添加第一个元素时,都会扩展到DEFAULT_CAPACITY。
transient Object[] elementData;
//数组长度
private int size;
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
//初始化容量
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
//空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList() {
//空数组
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList(Collection<? extends E> c) {
给数组赋值
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
//判断类型 若不等于obj数组类型
if (elementData.getClass() != Object[].class)
//转类型
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
//空数组
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
}补充小知识(右移运算)
int num = 8; // 二进制表示: 0000 0000 0000 0000 0000 0000 0000 1000
num >>= 1; // 逻辑右移1位,得到: 0000 0000 0000 0000 0000 0000 0000 0100
// num 现在是 4
int num = -8; // 二进制表示(补码): 1111 1111 1111 1111 1111 1111 1111 1000
num >>= 1; // 算术右移1位,得到: 1111 1111 1111 1111 1111 1111 1111 1100
// num 现在是 -4(注意,仍然是负数)
int num = -8; // 二进制表示(补码): 1111 1111 1111 1111 1111 1111 1111 1000
num >>>= 1; // 无符号右移1位,得到: 0111 1111 1111 1111 1111 1111 1111 1100
// num 现在是 2147483644(注意,这是一个正数,因为最高位是0)扩容核心方法
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
//如果当前容量不够的话,进行扩容
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
//获取旧容量
int oldCapacity = elementData.length;
//1.5倍扩容
int newCapacity = oldCapacity + (oldCapacity >> 1);
//若扩容后容量小于当前容量,则重新赋值
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//若最新容量大于最大容量
if (newCapacity - MAX_ARRAY_SIZE > 0)
//返回最大容量MAX_ARRAY_SIZE为最大-8
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}LinkedList(1.8)
初始化(构造方法)
transient 这是一个Java的关键字,用于指示某个字段不应当被序列化
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}get方法(遍历链表)
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}add方法
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
在某非空节点之前插入
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
void linkLast(E e) {
//在最后插入
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}Vector (1.8)
初始化
/**
* 存储向量组件的数组缓冲区。向量的容量是该数组缓冲区的长度,
* 并且它至少足够大以包含向量的所有元素。
*
* <p>在向量中的最后一个元素之后的任何数组元素都是null。
*
* @serial 这是一个标记,用于指示在序列化过程中应包含此字段。
*/
protected Object[] elementData;
/**
* 此{@code Vector}对象中有效组件的数量。
* 组件从{@code elementData[0]}到
* {@code elementData[elementCount-1]}是实际的项目。
*
* @serial 这是一个标记,用于指示在序列化过程中应包含此字段。
*/
protected int elementCount;
/**
* 当向量的大小变得大于其容量时,向量容量自动增加的数量。
* 如果容量增量小于或等于零,则每当向量需要增长时,其容量就会加倍。
*
* @serial 这是一个标记,用于指示在序列化过程中应包含此字段。
*/
protected int capacityIncrement;
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
public Vector() {
this(10);
}
public Vector(Collection<? extends E> c) {
elementData = c.toArray();
elementCount = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, elementCount, Object[].class);
}
线程安全的原因synchronized
public synchronized void insertElementAt(E obj, int index) {
modCount++;
if (index > elementCount) {
throw new ArrayIndexOutOfBoundsException(index
+ " > " + elementCount);
}
ensureCapacityHelper(elementCount + 1);
System.arraycopy(elementData, index, elementData, index + 1, elementCount - index);
elementData[index] = obj;
elementCount++;
}扩容
跟arraylist不一样
int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity);
如果capacityIncrement大于0则增加capacityIncrement容量,否则两倍扩容。
//capacityIncrement默认为0
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}ArrayList、LinkedList和Vector的区别_arraylist linkedlist vector的区别-CSDN博客
18.hashmap,hashtable,concurrentHashmap区别?***
hashmap线程不安全。
hashtable 通过给核心方法加synchronized关键字,实现线程安全。
concurrentHashmap线程安全,他是1.8之前使用分段锁,之后使用cas自旋锁加synchronized锁细化了锁粒度。
hashmap可以存储null值,而其他不行。
hashmap
hashtable
初始化(默认数组长度11,负载因子0.75)
//数组
private transient Entry<?,?>[] table;
//数组大小
private transient int count;
//扩容阈值
private int threshold;
//负载因子
private float loadFactor;
//修改次数
private transient int modCount = 0;
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
public Hashtable() {
this(11, 0.75f);
}
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);
putAll(t);
}
}put
synchronized 保证线程安全
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
//添加链表
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
//添加数组
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}扩容
int newCapacity = (oldCapacity << 1) + 1;扩容一倍加一
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}concurrentHashmap
初始化
//最大容量 private static final int MAXIMUM_CAPACITY = 1 << 30; //初始化容量 private static final int DEFAULT_CAPACITY = 16; //最大数组容量 static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; //默认并发等级 private static final int DEFAULT_CONCURRENCY_LEVEL = 16; //负载因子 private static final float LOAD_FACTOR = 0.75f; //数化阈值 static final int TREEIFY_THRESHOLD = 8; //链化阈值 static final int UNTREEIFY_THRESHOLD = 6; //最小树容量 static final int MIN_TREEIFY_CAPACITY = 64;
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
public ConcurrentHashMap() {
}
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
}put
主要有两段关键代码
//当没有发生哈希冲突时,进行乐观锁cas自旋重试
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
//发生哈希冲突,加synchronize锁
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//计算哈希
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//如果tab为空,初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//插入数组
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//加锁 发生冲突
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}扩容
//调用该扩容方法的地方有:
//java.util.concurrent.ConcurrentHashMap#addCount 向集合中插入新数据后更新容量计数时发现到达扩容阈值而触发的扩容
//java.util.concurrent.ConcurrentHashMap#helpTransfer 扩容状态下其他线程对集合进行插入、修改、删除、合并、compute 等操作时遇到 ForwardingNode 节点时触发的扩容
//java.util.concurrent.ConcurrentHashMap#tryPresize putAll批量插入或者插入后发现链表长度达到8个或以上,但数组长度为64以下时触发的扩容
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
//计算每条线程处理的桶个数,每条线程处理的桶数量一样,如果CPU为单核,则使用一条线程处理所有桶
//每条线程至少处理16个桶,如果计算出来的结果少于16,则一条线程处理16个桶
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) { // 初始化新数组(原数组长度的2倍)
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
//将 transferIndex 指向最右边的桶,也就是数组索引下标最大的位置
transferIndex = n;
}
int nextn = nextTab.length;
//新建一个占位对象,该占位对象的 hash 值为 -1 该占位对象存在时表示集合正在扩容状态,key、value、next 属性均为 null ,nextTable 属性指向扩容后的数组
//该占位对象主要有两个用途:
// 1、占位作用,用于标识数组该位置的桶已经迁移完毕,处于扩容中的状态。
// 2、作为一个转发的作用,扩容期间如果遇到查询操作,遇到转发节点,会把该查询操作转发到新的数组上去,不会阻塞查询操作。
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
//该标识用于控制是否继续处理下一个桶,为 true 则表示已经处理完当前桶,可以继续迁移下一个桶的数据
boolean advance = true;
//该标识用于控制扩容何时结束,该标识还有一个用途是最后一个扩容线程会负责重新检查一遍数组查看是否有遗漏的桶
boolean finishing = false; // to ensure sweep before committing nextTab
//这个循环用于处理一个 stride 长度的任务,i 后面会被赋值为该 stride 内最大的下标,而 bound 后面会被赋值为该 stride 内最小的下标
//通过循环不断减小 i 的值,从右往左依次迁移桶上面的数据,直到 i 小于 bound 时结束该次长度为 stride 的迁移任务
//结束这次的任务后会通过外层 addCount、helpTransfer、tryPresize 方法的 while 循环达到继续领取其他任务的效果
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
//每处理完一个hash桶就将 bound 进行减 1 操作
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
//transferIndex <= 0 说明数组的hash桶已被线程分配完毕,没有了待分配的hash桶,将 i 设置为 -1 ,后面的代码根据这个数值退出当前线的扩容操作
i = -1;
advance = false;
}
//只有首次进入for循环才会进入这个判断里面去,设置 bound 和 i 的值,也就是领取到的迁移任务的数组区间
else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
//扩容结束后做后续工作,将 nextTable 设置为 null,表示扩容已结束,将 table 指向新数组,sizeCtl 设置为扩容阈值
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
//每当一条线程扩容结束就会更新一次 sizeCtl 的值,进行减 1 操作
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
//(sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT 成立,说明该线程不是扩容大军里面的最后一条线程,直接return回到上层while循环
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
//(sc - 2) == resizeStamp(n) << RESIZE_STAMP_SHIFT 说明这条线程是最后一条扩容线程
//之所以能用这个来判断是否是最后一条线程,因为第一条扩容线程进行了如下操作:
// U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)
//除了修改结束标识之外,还得设置 i = n; 以便重新检查一遍数组,防止有遗漏未成功迁移的桶
finishing = advance = true;
i = n; // recheck before commit
}
}
else if ((f = tabAt(tab, i)) == null)
//遇到数组上空的位置直接放置一个占位对象,以便查询操作的转发和标识当前处于扩容状态
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)
//数组上遇到hash值为MOVED,也就是 -1 的位置,说明该位置已经被其他线程迁移过了,将 advance 设置为 true ,以便继续往下一个桶检查并进行迁移操作
advance = true; // already processed
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
//该节点为链表结构
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
//遍历整条链表,找出 lastRun 节点
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
//根据 lastRun 节点的高位标识(0 或 1),首先将 lastRun设置为 ln 或者 hn 链的末尾部分节点,后续的节点使用头插法拼接
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
//使用高位和低位两条链表进行迁移,使用头插法拼接链表
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
//setTabAt方法调用的是 Unsafe 类的 putObjectVolatile 方法
//使用 volatile 方式的 putObjectVolatile 方法,能够将数据直接更新回主内存,并使得其他线程工作内存的对应变量失效,达到各线程数据及时同步的效果
//使用 volatile 的方式将 ln 链设置到新数组下标为 i 的位置上
setTabAt(nextTab, i, ln);
//使用 volatile 的方式将 hn 链设置到新数组下标为 i + n(n为原数组长度) 的位置上
setTabAt(nextTab, i + n, hn);
//迁移完成后使用 volatile 的方式将占位对象设置到该 hash 桶上,该占位对象的用途是标识该hash桶已被处理过,以及查询请求的转发作用
setTabAt(tab, i, fwd);
//advance 设置为 true 表示当前 hash 桶已处理完,可以继续处理下一个 hash 桶
advance = true;
}
//该节点为红黑树结构
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
//lo 为低位链表头结点,loTail 为低位链表尾结点,hi 和 hiTail 为高位链表头尾结点
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
//同样也是使用高位和低位两条链表进行迁移
//使用for循环以链表方式遍历整棵红黑树,使用尾插法拼接 ln 和 hn 链表
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
//这里面形成的是以 TreeNode 为节点的链表
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
//形成中间链表后会先判断是否需要转换为红黑树:
//1、如果符合条件则直接将 TreeNode 链表转为红黑树,再设置到新数组中去
//2、如果不符合条件则将 TreeNode 转换为普通的 Node 节点,再将该普通链表设置到新数组中去
//(hc != 0) ? new TreeBin<K,V>(lo) : t 这行代码的用意在于,如果原来的红黑树没有被拆分成两份,那么迁移后它依旧是红黑树,可以直接使用原来的 TreeBin 对象
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
//setTabAt方法调用的是 Unsafe 类的 putObjectVolatile 方法
//使用 volatile 方式的 putObjectVolatile 方法,能够将数据直接更新回主内存,并使得其他线程工作内存的对应变量失效,达到各线程数据及时同步的效果
//使用 volatile 的方式将 ln 链设置到新数组下标为 i 的位置上
setTabAt(nextTab, i, ln);
//使用 volatile 的方式将 hn 链设置到新数组下标为 i + n(n为原数组长度) 的位置上
setTabAt(nextTab, i + n, hn);
//迁移完成后使用 volatile 的方式将占位对象设置到该 hash 桶上,该占位对象的用途是标识该hash桶已被处理过,以及查询请求的转发作用
setTabAt(tab, i, fwd);
//advance 设置为 true 表示当前 hash 桶已处理完,可以继续处理下一个 hash 桶
advance = true;
}
}
}
}
}
}ConcurrentHashMap1.8 - 扩容详解_concurrenthashmap1.8的扩容机制-CSDN博客
HashMap,Hashtable,ConcurrentHashMap_hashtable和concurrenthashmap-CSDN博客
19.hashmap初始化,put,get,扩容?****
初始化
首先看一下hashmap容量是否在规定范围,然后设置一下负载因子,根据容量初始化扩容阈值。
put方法底层有数组加链表加红黑树。第一次put方法时候进行扩容。当链表长度大于8,链表转化为红黑树,当红黑树结点小于6时转化为链表,并且在最后判断一下是否达到扩容阈值,达到则进行扩容。
get如果有链,则去遍历链表找数据,有树,则去树上找。
扩容1.7之前采用头插法,1.8之后采用尾插法。
头插法会带来一些问题,因多线情况下引发的链成环和数据丢失问题。
而尾插法保证插入顺序而不会导致出现环链死循环问题。
扩容时两倍扩容,默认数组长度16
七、JDK1.7中HashMap扩容机制_jdk1.7 hashmap扩容数组对应的数据排列-CSDN博客
hashmap头插法和尾插法区别_一个跟面试官扯皮半个小时的HashMap-CSDN博客
20.hashmap,hashset,arraylist是否线程安全?****
线程不安全
21.创建线程的几种方式?
继承thread类,重写run方法
class MyThread extends Thread {
//2.重写Thread类的run()
@Override
public void run() {
for (int i = 0; i < 100; i++) {
if (i % 2 == 0) {
System.out.println(Thread.currentThread().getName() + ":" + i);
}
}
}
}
public class ThreadTest {
public static void main(String[] args) {
MyThread t1 = new MyThread();
t1.start();
/*问题一:我们不能通过直接调用run()的方式启动线程,
这种方式只是简单调用方法,并未新开线程*/
//t1.run();
/*问题二:再启动一个线程,遍历100以内的偶数。
不可以还让已经start()的线程去执行。会报IllegalThreadStateException*/
//t1.start();
MyThread t2 = new MyThread();
t2.start();
//如下操作仍然是在main线程中执行的。
for (int i = 0; i < 100; i++) {
if (i % 2 == 0) {
System.out.println(Thread.currentThread().getName() + ":" + i + "***********main()************");
}
}
}
}
实现runnable接口,重写run方法
//1.创建一个实现了Runnable接口的类
class MThread implements Runnable {
//2.实现类去实现Runnable中的抽象方法:run()
@Override
public void run() {
for (int i = 0; i < 100; i++) {
if (i % 2 == 0) {
System.out.println(Thread.currentThread().getName() + ":" + i);
}
}
}
}
public class ThreadTest1 {
public static void main(String[] args) {
MThread mThread = new MThread();
//4.将此对象作为参数传递到Thread类的构造器中,创建Thread类的对象
Thread t1 = new Thread(mThread);
t1.setName("线程1");
//5.通过Thread类的对象调用start():① 启动线程 ②调用当前线程的run()-->调用了Runnable类型的target的run()
t1.start();
//再启动一个线程,遍历100以内的偶数
Thread t2 = new Thread(mThread);
t2.setName("线程2");
t2.start();
}
}
实现callable接口
class NumThread implements Callable {
//2.实现call方法,将此线程需要执行的操作声明在call()中
@Override
public Object call() throws Exception {
int sum = 0;
//把100以内的偶数相加
for (int i = 1; i <= 100; i++) {
if (i % 2 == 0) {
System.out.println(i);
sum += i;
}
}
return sum;
}
}
public class ThreadNew {
public static void main(String[] args) {
//3.创建Callable接口实现类的对象
NumThread numThread = new NumThread();
//4.将此Callable接口实现类的对象作为传递到FutureTask构造器中,创建FutureTask的对象
FutureTask futureTask = new FutureTask(numThread);
//5.将FutureTask的对象作为参数传递到Thread类的构造器中,创建Thread对象,并调用start()
new Thread(futureTask).start();
try {
//6.获取Callable中call方法的返回值
//get()返回值即为FutureTask构造器参数Callable实现类重写的call()的返回值。
Object sum = futureTask.get();
System.out.println("总和为:" + sum);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
线程池
public class ThreadPool {
public static void main(String[] args) {
//1. 提供指定线程数量的线程池
ExecutorService service = Executors.newFixedThreadPool(10);
//输出class java.util.concurrent.ThreadPoolExecutor
System.out.println(service.getClass());
ThreadPoolExecutor service1 = (ThreadPoolExecutor) service;
//自定义线程池的属性
// service1.setCorePoolSize(15);
// service1.setKeepAliveTime();
//2. 执行指定的线程的操作。需要提供实现Runnable接口或Callable接口实现类的对象
service.execute(new NumberThread());//适用于Runnable
service.execute(new NumberThread1());//适用于Runnable
// service.submit(Callable callable);//适合使用于Callable
//3. 关闭连接池
service.shutdown();
}
}java创建线程(Thread)的5种方式_java new thread-CSDN博客
22.什么是线程池?如何实现?常见参数?******
线程池就是可以实现的线程复用的一种技术。可以节省线程反复创建关闭所造成的开销。
有七种方式,分为两大类。
一种是自定义线程池通过threadpoolexecutor实现
另一种是通过executors实现
其中又分为六种小模式
- newfixedthreadpool 固定数量的线程池
- newcachedthreadpool 有缓存的线程池
- newscheduledthreadpool 定时任务的线程池
- newSingleThreadpool 单线程
- newSingleScheduledThreadpool单线程定时线程池
- newWorkStealing pool抢占式线程池
常见参数:
核心线程数,最大线程数,等待队列,拒绝策略,最大存活时间,时间单位。
【Thread】线程池的 7 种创建方式及自定义线程池-CSDN博客
23.线程同步的方式?***
加互斥锁
- sychronized加方法上
- synchronized同步代码块
- reetrantlock锁
同步工具类,例如atomic下的类
class Bank {
private AtomicInteger account = new AtomicInteger(100);
public AtomicInteger getAccount() {
return account;
}
public void save(int money) {
account.addAndGet(money);
}
}threadlocal类
public class Bank{
// 创建一个线程本地变量 ThreadLocal
private static ThreadLocal<Integer> account = new ThreadLocal<Integer>(){
@Override
//返回当前线程的"初始值"
protected Integer initialValue(){
return 100;
}
};
public void save(int money){
//设置线程副本中的值
account.set(account.get()+money);
}
public int getAccount(){
//返回线程副本中的值
return account.get();
}
}阻塞队列
BlockingQueue是java.util.concurrent包提供的一个接口,经常被用于多线程编程中容纳任务队列。它提供了两个支持阻塞的方法:
- put(E e):尝试把元素e放入队列中,如果队列已满,则阻塞当前线程,直到队列有空位。
- take():尝试从队列中取元素,如果没有元素,则阻塞当前线程,直到取到元素。
BlockingQueue有很多实现类,如
- ArrayBlockingQueue
- LinkedBlockingQueue
- PriorityBlockingQueue
实现商家生产商品和买卖商品的同步?
import java.util.Random;
import java.util.concurrent.LinkedBlockingQueue;
/**
* 用阻塞队列实现线程同步 LinkedBlockingQueue的使用
*
* @author XIEHEJUN
*
*/
public class BlockingSynchronizedThread {
/**
* 定义一个阻塞队列用来存储生产出来的商品
*/
private LinkedBlockingQueue<Integer> queue = new LinkedBlockingQueue<Integer>();
/**
* 定义生产商品个数
*/
private static final int size = 10;
/**
* 定义启动线程的标志,为0时,启动生产商品的线程;为1时,启动消费商品的线程
*/
private int flag = 0;
private class LinkBlockThread implements Runnable {
@Override
public void run() {
int new_flag = flag++;
System.out.println("启动线程 " + new_flag);
if (new_flag == 0) {
for (int i = 0; i < size; i++) {
int b = new Random().nextInt(255);
System.out.println("生产商品:" + b + "号");
try {
queue.put(b);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("仓库中还有商品:" + queue.size() + "个");
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} else {
for (int i = 0; i < size / 2; i++) {
try {
int n = queue.take();
System.out.println("消费者买去了" + n + "号商品");
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("仓库中还有商品:" + queue.size() + "个");
try {
Thread.sleep(100);
} catch (Exception e) {
// TODO: handle exception
}
}
}
}
}
public static void main(String[] args) {
BlockingSynchronizedThread bst = new BlockingSynchronizedThread();
LinkBlockThread lbt = bst.new LinkBlockThread();
Thread thread1 = new Thread(lbt);
Thread thread2 = new Thread(lbt);
thread1.start();
thread2.start();
}
}Java使用阻塞队列BlockingQueue实现线程同步_java 多个线程同时从priorityblockingqueue中take数据,会取到同一条数据吗-CSDN博客
Java实现线程同步的几种方式?_java线程同步的几种方法-CSDN博客
24.任务添加到线程池的流程?
首先一个任务提交到线程池,创建线程,当数量达到核心线程数之后不再继续创建,而是添加到等待队列,当队列满了之后,再根据最大线程数去创建线程。当核心线程数和最大线程数都满了,这时候执行拒绝策略。
拒绝策略
- 抛掉最新的,不做其他操作
- 跑掉最新的,异常
- 谁提交谁执行
- 结束掉最开始执行的,执行最新的
线程池应该注意什么问题? **
1.死锁 : 虽然死锁可能发生在任何多线程程序中,但线程池引入了另一个死锁案例,其中所有执行线程都在等待队列中某个阻塞线程的执行结果,导致线程无法继续执行。
2.线程泄漏 : 如果线程池中线程在任务完成时未正确返回,将发生线程泄漏问题。例如,某个线程引发异常并且池类没有捕获此异常,则线程将异常退出,从而线程池的大小将减小一个。如果这种情况重复多次,则线程池最终将变为空,没有线程可用于执行其他任务。
3.线程频繁轮换: 如果线程池大小非常大,则线程之间进行上下文切换会浪费很多时间。所以在系统资源允许的情况下,也不是线程池越大越好。
4.线程池大小优化: 线程池的最佳大小取决于可用的处理器数量和待处理任务的性质。对于CPU密集型任务,假设系统有N个逻辑处理核心,N 或 N+1 的最大线程池数量大小将实现最大效率。对于 I/O密集型任务,需要考虑请求的等待时间(W)和服务处理时间(S)的比例,线程池最大大小为 N*(1+ W/S)会实现最高效率。
25.synchronized如何使用?加在普通方法上和静态方法的区别?*****
可以加在方法上或者加在同步代码块上
普通方法,锁的是进入该方法的对象,锁的是一个对象多次调用
静态方法,锁的是本类,锁的是多个相同对象多次调用
面试官:请详细说下synchronized的实现原理 - 知乎
synchronized修饰静态方法和普通方法的区别-CSDN博客
26.java锁分类?***
可重入锁 retrantlock
不可重入锁 synchronized
乐观锁 retrantlock
悲观锁 synchronized
公平锁 retrantlock
非公平锁 retrantlock
一般是使用synchronized和retrantlock锁来实现
27.什么情况下对对象进行序列化?***
当 Java 对象需要在网络上传输 或者 持久化存储到文件中时,就需要对 Java 对象进行序列化处理。
注意事项:
- 某个类可以被序列化,则其子类也可以被序列化
- 声明为 static 和 transient 的成员变量,不能被序列化。static 成员变量是描述类级别的属性,transient 表示临时数据
- 反序列化读取序列化对象的顺序要保持一致
什么是 java 序列化?什么情况下需要序列化?_什么是 java 序列化?什么情况下需要序列化?-CSDN博客
28.aio,bio,nio?
- bio同步阻塞
- nio同步非阻塞
- aio异步非阻塞
29.synchronize锁升级?
- 无锁
- 偏向锁 单线程
- 轻量级锁 多线程
- 重量级锁 轻量级-自旋重试长时间失败
30.synchronize锁优化?**
锁升级
- 无锁
- 偏向锁 单线程
- 轻量级锁 多线程
- 重量级锁 轻量级-自旋重试长时间失败
锁消除
比如stringbuffer类的append方法,当stringbuffer是一个局部变量时,根本不需要保证线程安全,则字节码编译出来的是stringbuffer继承的stringbuilder线程不安全的类。
锁粗化
如果虚拟机检测到有一系列操作都是对某个对象反复加锁和解锁,会将加锁同步的范围粗化到整个操作序列的外部。可以看下面这个经典案例。
for(int i=0;i<n;i++){
synchronized(lock){
}
}这段代码会导致频繁地加锁和解锁,锁粗化后
synchronized(lock){
for(int i=0;i<n;i++){
}
}自适应自旋锁**
自适应性自旋锁的意思是,自旋的次数不是固定的,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。
表现是如果此次自旋成功了,很有可能下一次也能成功,于是允许自旋的次数就会更多,反过来说,如果很少有线程能够自旋成功,很有可能下一次也是失败,则自旋次数就更少。这样能最大化利用资源,随着程序运行和性能监控信息的不断完善,虚拟机对锁的状况预测会越来越准确,也就变得越来越智能。
31.synchronize与reetrantlock区别?**
- synchronized是Java语法的一个关键字,加锁的过程是在JVM底层进行。Lock是一个类,是JDK应用层面的,在JUC包里有丰富的API。
- synchronized在加锁和解锁操作上都是自动完成的,Lock锁需要我们手动加锁和解锁。
- Lock锁有丰富的API能知道线程是否获取锁成功,而synchronized不能。
- synchronized能修饰方法和代码块,Lock锁只能锁住代码块。
- Lock锁有丰富的API,可根据不同的场景,在使用上更加灵活。
- synchronized是非公平锁,而Lock锁既有非公平锁也有公平锁,可以由开发者通过参数控制。
32.volatile能保证原子性嘛?为什么?**
不能,他只能保证可见性
谈谈Volatile关键字?为什么不能保证原子性?用什么可以替代?为什么? - 知乎
33.juc并发类?特性?场景?**
6、JUC并发工具类在大厂的应用场景详解_juc的应用场景-CSDN博客
34.concurrentHashmap底层原理?**
1.7之前分段锁
之后是cas乐观锁加synchronize锁,细化了锁的粒度
concurrenthashmap1.8为什么取消了reetrantlock?
面试官问:JDK8 的ConcurrentHashMap为什么放弃了分段锁 - 知乎
硬核讲解JDK1.8的ConcurrentHashMap为何放弃分段锁改用CAS + synchronized_concurrenthashmap1.8为什么放弃了分段锁-CSDN博客
35.simpleDateFormat线程安全?**
这个类中有一个calander变量,是用来专门存储时间的。在多线程情况下,操作一个对象会导致时间混乱。
解决方案
- 每次新建对象
- 加锁 synchronize或reetrantlock
-
创建一个ThreadLocal对象使SimpleDateFormat线程私有
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
/**
* @author coderzpw
* 线程安全的日期格式化工具类
*/
public class DateFormatUtil {
// 创建一个静态的 ThreadLocal的 pattern:dateFormat 的map映射 (因为ThreadLocal使得dateFormatMap线程独享,因此dateFormatMap是不会有线程问题的)
public static ThreadLocal<Map<String, SimpleDateFormat>> dateFormatMap = new ThreadLocal<Map<String, SimpleDateFormat>>(){
@Override
protected Map<String, SimpleDateFormat> initialValue() {
return new HashMap<String,SimpleDateFormat>();
}
};
/**
* 根据日期格式获取对应的SimpleDateFormat对象
* @param pattern
* @return
*/
private static SimpleDateFormat getSimpleDateFormat(final String pattern) {
// 获取ThreadLocal在当前线程初始化的 HashMap<String,SimpleDateFormat>
Map<String, SimpleDateFormat> map = dateFormatMap.get();
SimpleDateFormat sdf = map.get(pattern);
// 如果对应的sdf为null才会去创建一个新的sdf, 这样做确保只创建一次,既当前线程下是单例的
if (sdf == null) {
sdf = new SimpleDateFormat(pattern);
map.put(pattern, sdf);
}
return sdf;
}
/**
* 封装format方法 Date 转 String
* @param date
* @param pattern
* @return
*/
public static String format(Date date, String pattern) {
return getSimpleDateFormat(pattern).format(date);
}
/**
* 封装format方法 Long 转 String
* @param longTime
* @param pattern
* @return
*/
public static String format(long longTime, String pattern) {
return getSimpleDateFormat(pattern).format(longTime);
}
/**
* 封装parse方法 String 转 Date
* @param strDate
* @param pattern
* @return
*/
public static Date parse(String strDate, String pattern) {
Date date = null;
try {
date = getSimpleDateFormat(pattern).parse(strDate);
} catch (ParseException e) {
System.out.println("时间格式不符合要求,无法解析!");
e.printStackTrace();
}
return date;
}
}
SimpleDateFormat线程安全问题_simpledateformat线程问题-CSDN博客
36.aqs,cas?***
aqs同步队列
cas自旋重试机制
38.解决hash冲突方案?**
拉链法
39.hashmap,arraylist key可以为空/重复吗?
hashMap虽然支持key和value为null,但是null作为key只能有一个,null作为value可以有多个; 因为hashMap中,如果key值一样,那么会覆盖相同key值的value为最新,所以key为null只能有一个。
ArrayList可以存储重复的元素,没有任何限制。 你可以将相同的元素多次添加到ArrayList中,而且在访问和删除元素时也没有问题。
解释下ArrayList集合为啥允许值为null-CSDN博客
41.java四种引用,强软弱虚?
强
软 gc发现回收
弱 内存不够回收
虚
Java中四种引用详解以及对比区别_java四种引用的区别-CSDN博客
42.为什么说cas是乐观锁?底层对应哪些类?**
不仅仅是乐观锁,它是一种思想,例如atomic包下的原子类
深入分析CAS(乐观锁)_cas为什么是乐观锁-CSDN博客
43.aba问题?
乐观锁,需要CAS操作(Compare And Swap)来实现。
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存地址里面的值和A的值是一样的,那么就将内存里面的值更新成B。CAS是通过无限循环来获取数据的,若果在第一轮循环中,a线程获取地址里面的值被b线程修改了,那么a线程需要自旋,到下次循环才有可能机会执行。
ABA问题是指在CAS操作时,其他线程将变量值A改为了B,但是又被改回了A,等到本线程使用期望值A与当前变量进行比较时,发现变量A没有变,于是CAS就将A值进行了交换操作,但是实际上该值已经被其他线程改变过,这与乐观锁的设计思想不符合。
ABA问题的解决思路
- 版本号
- 时间戳
面试|详解CAS及其引发的三个问题-腾讯云开发者社区-腾讯云
44.threadlocal底层原理应该注意什么?
内存泄漏:由于ThreadLocal为每个线程提供了独立的变量副本,如果在使用完ThreadLocal后没有及时清理,就可能导致内存泄漏。因此,在使用ThreadLocal时,需要确保在不再需要时能够正确移除对应的变量值。通常可以通过在finally块中调用ThreadLocal的remove()方法来实现。
初始值设置:ThreadLocal的变量值需要在首次访问时通过initialValue()方法进行初始化。如果initialValue()方法返回的初始值不合理,可能会导致程序出错。因此,在使用ThreadLocal时,需要确保initialValue()方法返回正确的初始值。
线程池中的使用:在使用线程池时,由于线程是复用的,如果不正确地使用ThreadLocal,可能会导致数据污染。因此,在使用线程池时,需要特别注意ThreadLocal的正确使用方式,确保每个线程在执行任务前都能获取到正确的变量值。
彻底攻克ThreadLocal:搞懂原理、实战应用,深挖源码!扩展InheritableThreadLocal、FastThreadLocal!-腾讯云开发者社区-腾讯云
45.jmm内存模型?为什么需要?
jmm java memory model java内存模型
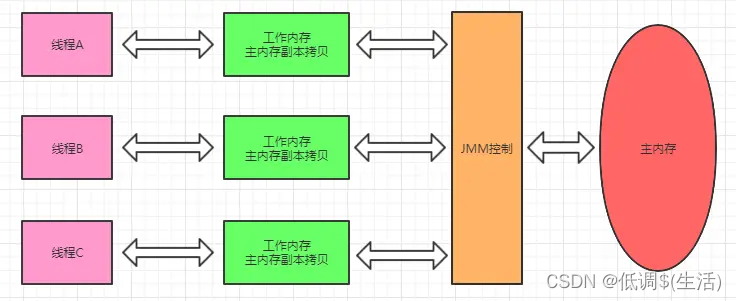
java有一个块主内存专门用来存储一些变量等信息,java每一个线程有一块工作内存,java更新变量时,先更新到线程的工作内存,然后再更新到主内存
jmm有八种操作
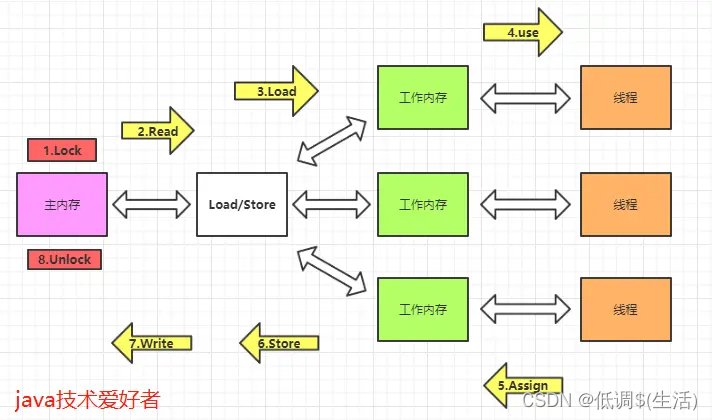
volatile可见性
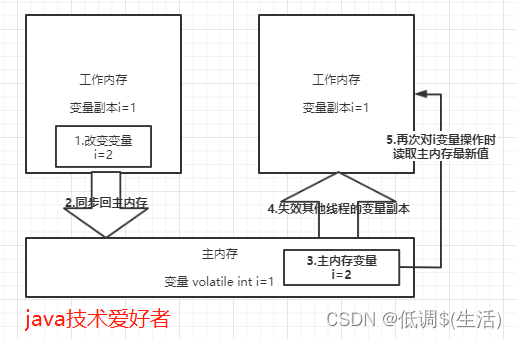
46.stream流使用?
【java基础】吐血总结Stream流操作_java stream流操作-CSDN博客
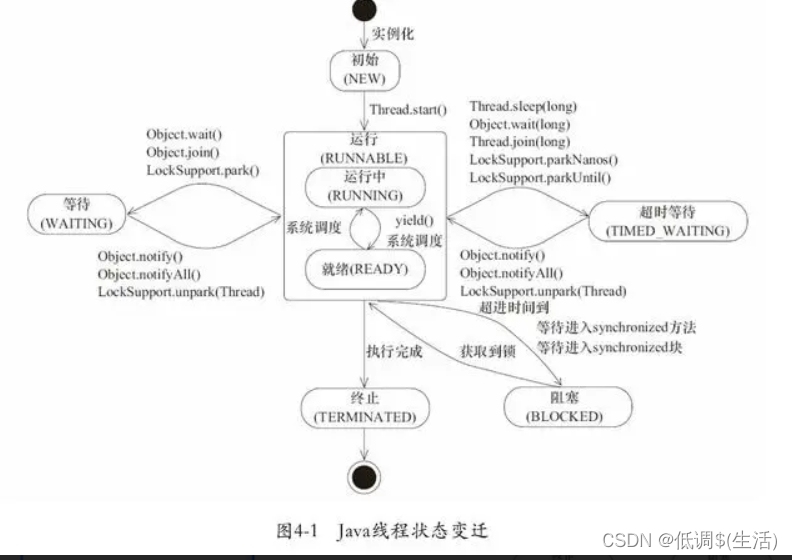
47.线程状态


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











