







编程编的其实就是启动之后的内存⭐
配置环境
Java环境
简单来讲,Java环境就是Java开发和运行时的地方。
任何一门语言在学习前都需要搭建出对应的开发环境,就好比你生产汽车,必须得先修建起一个工厂,这就是造车时所必须的“环境”,如果想要搭建出Java的开发和运行环境,就必须安装JDK并配置JDK环境变量。
1.JDK
对我们Java程序员来说,要想开发Java项目,必须安装的第一个软件就是JDK。
JDK:Java Development Kits,Java开发工具集/包。 JDK是Java开发人员首先必备的软件包,其中包含了Java的各种开发工具、编译工具(javac.exe)、打包工具(jar.exe)等,也包含了Java的运行环境JRE。所以我们在安装JDK之后,其实就不用再单独安装JRE了,JDK中自带JRE。
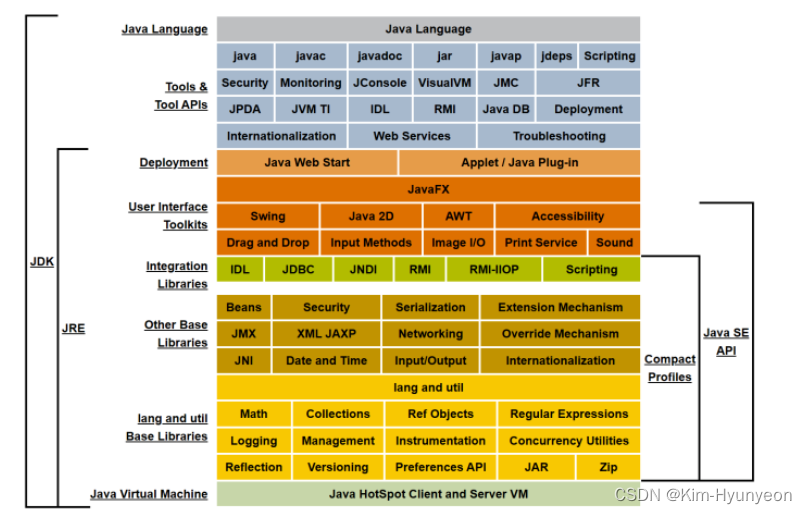
在JDK的各种开发工具里,我们比较常用的是Java编译器(javac.exe)、Java运行时解释器(java.exe)、Java文档化工具(javadoc.exe)等。
2.JRE
JRE:Java RunTime Environment,Java运行时环境,主要负责运行Java项目。 JRE包括JVM虚拟机,和Java程序所需要的各种核心类库等。如果我们不做Java开发,只是想运行一个已经开发好的Java程序,电脑上其实只要安装JRE就行了。
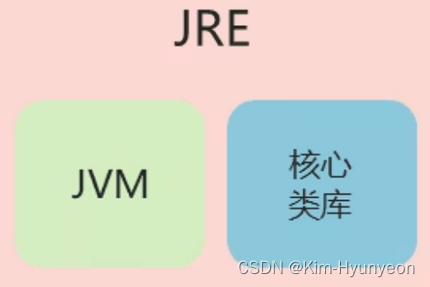
展开来说,JRE有3个核心功能:
加载代码:由类加载器(class loader)完成;
校验代码:由字节码校验器(bytecode verifier)完成;
执行代码:由运行时解释器(runtime interpreter)完成。
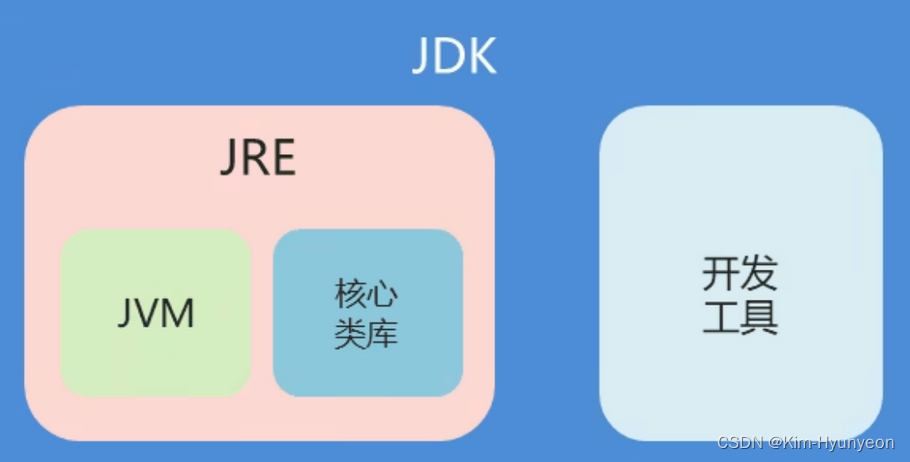
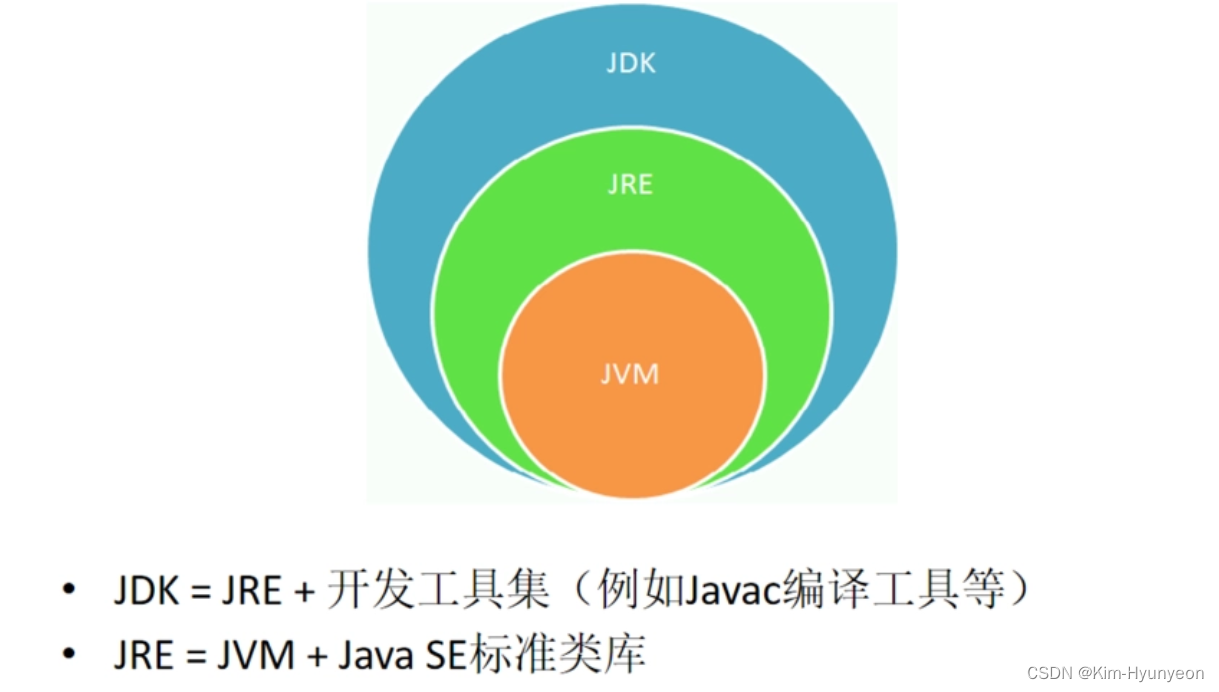
3.JDK、JRE、JVM的关系
Windows配置Java环境变量
在高级系统设置的环境变量中分别设置三个环境变量:JAVA_HOME、PATH、CLASSPATH
注意:一定要在【系统变量】中设置,而不是在【用户变量】中创建。
补充:
环境变量分为系统环境变量和用户环境变量
正常所说的环境变量是指系统环境变量,对所有用户起作用,而用户环境变量只对当前用户起作用,如果此电脑登入了另外个用户账号,那之前账号配置的用户环境变量就对另外个用户账号不起作用。
例如你要在命令行窗口用java,那么你把java的bin目录加到系统变量的path变量下面,那么它就是系统环境变量。无论哪个用户登录,在命令行(cmd)输入java都会有java的帮助信息显示出来。而如果你在用户变量的path下新建一个变量,那么它就只对当前用户有用,当你以其他用户登录时这个变量就和不存在一样。那么当然的,在命令行窗口也就无法使用java命令了。
Linux配置Java环境变量
前言:常见Linux系统
- 国外:Red Hat(红帽);CentOS(Community Enterprise Operating System,中文意思是社区企业操作系统)—— 常用作服务器、常用版本:7,现已停更; ⛓ Ubuntu —— 常用作客户端【⛓分割前后两组的主要区别是内核不同】
- 国内:红旗;深度👍(私企);麒麟(国家主推)
Java基础
类型
八大基本数据类型
数值型
- 整数型:byte、short、int、long;
- 浮点型:float、double
浮点数可表示的范围非常大,float类型可最大表示3.4x1038,而double类型可最大表示1.79x10308;但是在实际开发中,几乎不采用浮点型数据来表示小数,而是用BigDecimal类来表示。因为用浮点型来表示小数会存在丢失精度的问题。
原因:🚩
非数值型
- 字符型:char;
- 布尔型:boolean
在实际开发中,很少使用char来表示字符,因为会出现缓存问题。一般使用String类来代替char表示字符。
原因:🚩
范围对比
不同的数据类型之所以取值范围不同,就好比每种类型都是不同的房型,有大有小,如下图所示:
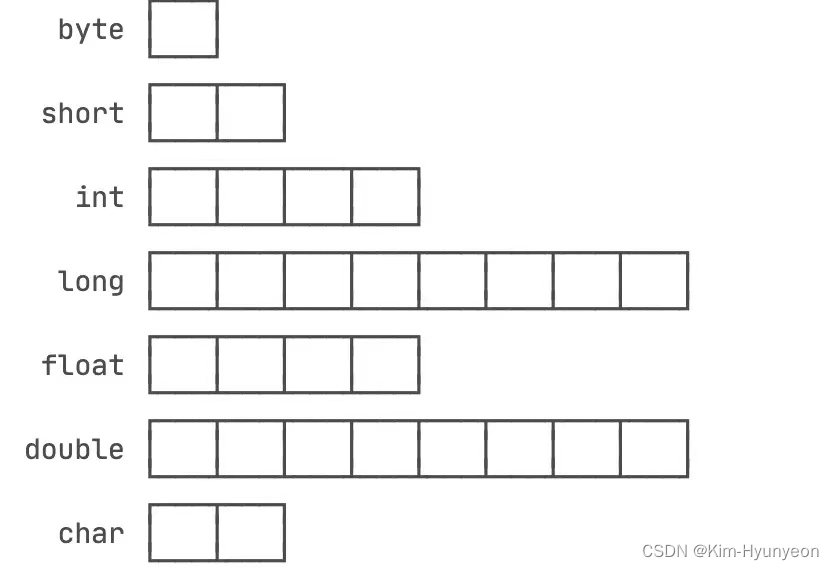
这些不同的类型,占用的字节大小不同,所以取值范围自然也不一样。
0.前提说明
Java中只定义了带符号的整型,因此最高位的bit表示正负符号,0表示正数,1表示负数,如:
- 1(十进制) = 0000 0001(二进制);
- 127(十进制) = 0111 1111(二进制);
- -128(十进制) = 1000 0000(二进制)
关于原反补码内容请关注另一篇博客:《原反补码》
1.byte
byte是字节类型,1个byte占1个字节8位,代表有符号的、以二进制补码表示的整数,具有如下特点:
- 最小值是 -128(-2^7);
- 最大值是 127(2^7-1);
- 默认值是 0
2.short
short 是短整型,占2个字节16 位,代表有符号的、以二进制补码表示的整数,具有如下特点:
- 最小值是 -32768(-2^15);
- 最大值是 32767(2^15 - 1);
- 默认值是 0
3.int
int 是整型,占4个字节32位,代表有符号的、以二进制补码表示的整数,如有如下特点:
- 整数的默认类型是int类型;
- 最小值是 -2,147,483,648(-2^31);
- 最大值是 2,147,483,647(2^31 - 1);
- 默认值是 0 ;
- 我们在开发时,一般都是用int表示整型变量
4.long
long 是长整型,占8个字节64 位,代表有符号的、以二进制补码表示的整数,如有如下特点:
- 最小值是 -9,223,372,036,854,775,808(-2^63);
- 最大值是 9,223,372,036,854,775,807(2^63 -1);
- 默认值是 0L,“L"理论上不区分大小写,但若写成小写的"l”,容易与数字"1"混淆,不容易分辩,所以最好写成大写的“L”
5.float
float 是单精度的浮点类型,占4个字节32位,是符合IEEE 754标准的浮点数,具有如下特点:
- 默认值是 0.0f,"f"理论上不区分大小写;
- float浮点数不能用来表示精确的值,如不能用float来表示货币等
6.double
double 是双精度的浮点类型,占8个字节64 位,是符合 IEEE 754 标准的浮点数,具有如下特点:
- 浮点数的默认类型为 double 类型;
- 默认值是 0.0d,"d"理论上不区分大小写;
- double类型同样不能表示精确的值,如货币
7.char
char是一种表示字符的类型,占2个字节16位。Java的char类型除了可以表示标准的ASCII,还可以表示一个Unicode字符,代表一个单一的16位 Unicode 字符,具有如下特点:
- 最小值是 \u0000(十进制等效值为 0);
- 最大值是 \uffff(即为 65535)
字符的三种表现形式:
1.字符 ‘a’ 、‘中’
2.数字 97、20;
3.十六进制 ‘\u0041’。
8.boolean
boolean是布尔类型,该类型只表示一位信息。布尔类型是关系运算的计算结果,具有如下特点:
- 布尔类型只有两个值:true 和 false;
- 默认值是 false;
在上面的范围对比中,关于boolean类型所占的字节大小,在表格中并没有说明。这是因为根据官方文档描述, boolean类型经过编译之后采用int来定义(所以此时boolean占4字节,32位),但如果是boolean数组则占1字节(8 位)。 详见下图红色标注:

注意:浮点数的默认类型为 double 类型,所以定义float类型数据时必须要加f;而整数的默认类型是int类型,long类型的范围比int类型的大,只要定义的是在int类型范围内的数据都可以隐式自动转成long型,所以定义long不用加后缀(只局限在int表示的数据范围内)【不加’L’默认是int型,int转为long是安全的,所以会自动转,能编译通过;当变量值超过了int的表示范围时,必须添加’l’或’L’,否则编译不通过,会报错!】
范围小->范围大 安全
范围大->范围小 不安全
void
实际上,java中还有另外一种基本类型 void,它也有对应的包装类 java.lang.Void。但我们无法对它们直接进行操作,所以一般不把它们当做基本类型对待。
引用数据类型
引用数据类型:https://blog.csdn.net/yuandfeng/article/details/128738973
引用数据类型大致包括:类、 接口、 数组、 枚举、 注解、 字符串等。
它和基本数据类型的最大区别就是:
- 基本数据类型是直接保存在栈中的
- 引用数据类型在栈中保存的是一个地址引用,这个地址指向的是其在堆内存中的实际位置。(栈中保存的是一个地址,而实际的内容是在堆中,通过地址去找它实际存放的位置)
上述两种类型变量的区别是指在方法中定义的基本类型变量和引用类型变量的区别。因为方法中的变量是在调用方法时才生成的。即,在调用某个方法时,JVM会将该方法放入某个栈帧中。而类中的属性变量实际上是属于某个实例对象的,即当创建某个实例对象时,该实例对象变量在栈中保存的是一个地址引用,而其指向的堆内存中的实际位置中存的是这个实例对象的属性[1]
[1]
🚩
运算符
位运算符
在Java语言中,提供了7种位运算符,分为位逻辑运算符和位移运算符。位逻辑运算符有按位与(&)、按位或(|)、按位异或(^)和取反(~);而位移运算符有左移(<<)、带符号右移(>>)和无符号右移(>>>)。
这些运算符当中,仅有~是单目运算符,其他运算符均为双目运算符。
位运算符是对long、int、short、byte和char这5种类型的数据进行运算的,我们不能对double、float和boolean进行位运算操作。
凡是位运算符,都是把值先转换成二进制,再进行后续的处理(因为位运算是针对二进制数进行的一种运算,对于十进制这些数值的位运算来说,会先将其转为二进制,再对其进行位运算,之后将运算结果再转为十进制。)
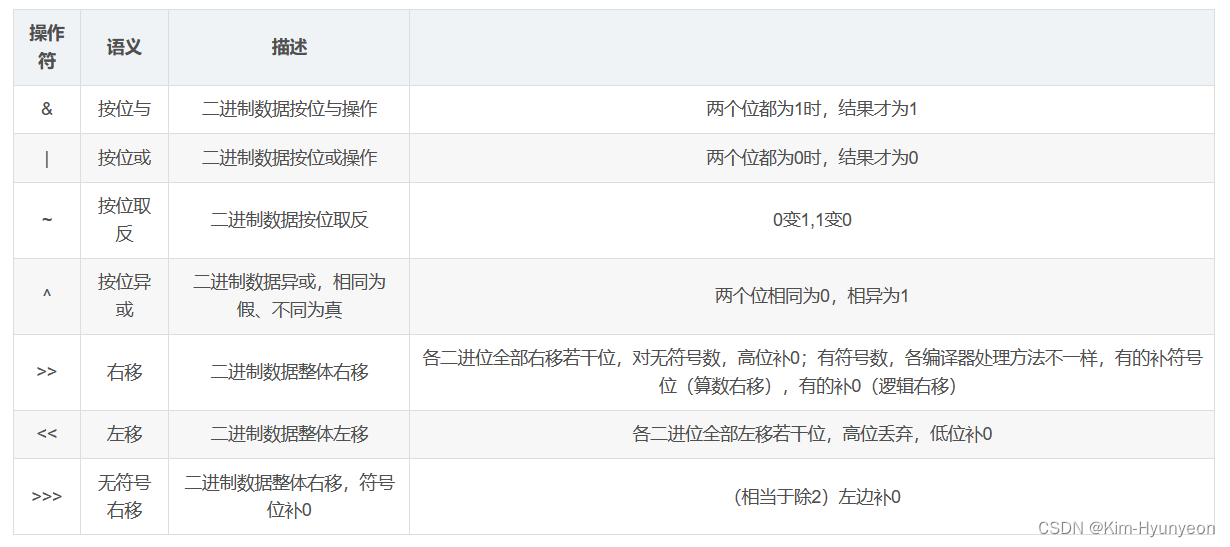
在IDEA中左移是带符号位的,即保留最高位后其他高位丢弃并在低位补0
eg: int i = -1;
System.out.println(i<<1);
输出:-2
扩展:有一种说法是【左移一位是最快乘2的方法】
其他
注意:
除法(‘/’)运算结果类型会选取除数与被除数的类型中范围更大的那一个
eg: ① int a=8; System.out.println(a/3); >> 2
② int a=8; System.out.println(a/3.0); >> 2.6666666666666665
基本结构
- 顺序结构
- 分支结构(选择结构)
// switch 关键字后面小括号里表达式必须为 byte,short,int,char类型;不可以为long类型
switch(表达式){
case 值1:
语句块1;
break;
case 值2:
语句块2;
break;
…
case 值n:
语句块n;
break;
default:
语句块n+1;
break;
}
switch(x)语句括号中的表达式 x 的类型:
JDK 1.5以前:x 只能是byte, short, char, int;
JDK 1.5之后:x 的类型也可以是枚举类型;
JDK 1.7之后:x 的类型又多了一个String类型
其实,准确的说,数值型的只可以是 int 类型,但是 byte, short, char 都可以自动(隐式)转换成 int 类型,所以 x 也可以是byte, short, char。这也是为什么不支持long类型的原因,因为long无法隐式转换为int类型。当然了,对应的包装类也是可以自动转换,所以 x 也可以是包装类型的。
一定要注意:无论哪个版本的JDK,都是不支持 long,float,double和boolean类型的!
- 循环结构
for:常用于执行次数确定的循环。先判断,后执行;
while:当型循环,常用于循环次数不确定时。先判断,后执行;
do-while:直到型循环,常用于循环次数不确定时。先执行,后判断;
foreach/for-in:增强for循环,常用于对数组或集合的遍历。

表达式
表达值类型:返回什么类型就是什么表达式
方法
好处:封装、复用性(主)
注意:void不是无返回类型,而是空类型;验证:可以在返回类型为void的方法体内写return语句,只不过return后不接任何数据。真正的无返回类型方法是构造方法。
类
Java:一切皆在类中
实例(对象)
构造方法(构造器)的实际作用:实例化对象
this关键字
指向当前对象
- this. 调用当前对象的方法或属性;
- this() 调用当前类的构造方法
== & equals
== 是一个比较运算符
- ==:既可以判断基本类型,又可以判断引用类型
- ==:如果判断基本类型,判断的是值是否相当
- ==:如果判断引用类型,判断的是地址是否相等,即判定是不是同一个对象
equals方法
- equals:是Object类中的方法,只能判断引用类型;
- 默认判断的是地址是否相等,子类中往往重写该方法,用于判断内容是否相等
继承
好处:公用
例子:B是A的子类,有下面这样一条语句:A a = new B();
在这里,实例对象a编译类型是A,运行类型是B,故a只能在正常使用父类的基础上,若子类有对父类进行覆盖的属性或方法,则使用的是子类的属性或方法;且无法调用子类扩展的方法。所以继承是有缺陷的。因此,我们要尽量遵循里氏代换原则:即,要保证子父类中属性和方法一致
super关键字
指向父类对象
- super. 调用父类对象的方法或属性;
- super() 调用父类的构造方法
重载
在同一类中,方法名相同,参数(类型或个数)不同。 重载对返回类型没有特殊的要求,不能根据返回类型进行区分。
重写
子类重写父类方法,要求方法必须完全一样!!!范围修饰符要求子类的方法修饰符修饰的范围大于等于父类的方法修饰符修饰的范围。
为什么Java子类方法的访问修饰符要比父类方法的访问修饰符的范围要大?
Java中子类继承父类的是基于子类的对象可以被当做父类的对象使用,即子类对象可以替代父类对象使用。如果子类方法的访问修饰符比父类的小,那么在子类对象被当做父类对象使用时,父类对象可能无法访问子类方法,从而破坏了继承的特性。因此,为了保证子类对象可以完全替代父类对象使用,子类方法的访问修饰符必须大于等于父类的。
组合-聚合-关联
组合表示 has - a 语义;而继承表示 is - a 语义
抽象(abstract)
- 修饰类和方法;
- 抽象类不能被直接实例化;
- 抽象方法没有方法体;
- 抽象方法只能定义在抽象类中
抽象类为什么能有构造方法?
原因:🚩
抽象类为什么不能被直接实例化?
原因:🚩
抽象方法为什么不可以是private的?
原因:🚩
接口(interface)
- 一个类实现多接口;
- 接口可以继承接口-多继承;
- 接口没有构造器;
- 接口不可实例化;
- 接口中的方法默认public abstract;
- 接口中的属性默认public static final;
- JDK8的新特性:接口中可以定义有方法体的方法。(默认、静态)
final关键字
终态&不可变
- 类不能被继承;
- 方法不能被重写;
- 变量(属性和方法变量)必须赋初值且不能被改变。除了在声明时就赋初值外还可以选择在构造方法中赋初值,但两者只能选其一
public class Test {
private final String name;
Test(){
name = "Kim";
}
}
枚举(enum)
- 已知实例个数的时候,采用枚举;
- 枚举不可实例化
- 不能继承类或其他枚举,也不能被类或其他枚举所继承,但是可以实现接口;
- valueOf(String name) 通过字符串名称,获得相对应的枚举实例
- values() 获取所有枚举实例
用enum关键字定义一个枚举类为什么会默认其为一个final类?
🚩
异常
Throwable
Error
Exception
RuntimeException 运行时异常(非检查异常)
【除RuntimeException及其子类的其他异常类均为 编译时异常(检查异常)】
总结
- 继承 提高代码的复用性
- 封装 类体现了封装性
- 多态 父类引用指向子类对象;方法的重载和重写
Java常用工具类
一、Object
- getClass():返回类的Class对象
- hashCode():返回对象的哈希码值
- equals():指示一些其他对象是否等于此
- clone():创建并返回此对象的副本
- toString():返回对象的字符串表示形式
- finalize():当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法
补充:
1.hashCode方法
1)提高具有哈希结构的容器的效率
2)两个引用,如果指向的是同一个对象,则哈希值肯定是一样的
3)两个引用,如果指向的是不同对象,则哈希值是不一样的(不是绝对的,也有可能发生碰撞,但概率很低)
4)哈希值主要根据地址号来的!但不能完全将哈希值等价于地址
5)在集合中,如若需要hashCode,还会进行重写
2.toString方法
1)默认返回:全类名+@+哈希值的十六进制,子类往往重写toString方法,用于返回对象的属性信息
2)重写toString方法,打印对象或拼接对象时,都会自动调用该对象的toString形式
3)当直接输出一个对象时,toString方法会被默认的调用,比如System.out.println(monster);就会默认调用monster.toString()
3.finalize方法
1)当对象被回收时,系统自动调用该对象的finalize方法。子类可以重写该方法,做一些释放资源的操作
2)什么时候被回收:当某个对象没有任何引用时,则jvm就认为这个对象是一个垃圾对象,就会使用垃圾回收机制来销毁该对象,在销毁该对象前,会先调用finalize方法
3)垃圾回收机制的调用,是由系统来决定(即有自己的GC算法),也可以通过System.gc()主动触发垃圾回收机制(但是也不是一定能够触发起来,还要取决于系统的其他原因,一般来说是可以的)
提示:在实际开发中,几乎不会运用finalize方法,更多的是为了应付面试
重写finalize示例代码:
package com.hspedu.object_;
//演示 Finalize的用法
public class Finalize_ {
public static void main(String[] args) {
Car bmw = new Car("宝马");
//这时 car对象就是一个垃圾,垃圾回收器就会回收(销毁)对象, 在销毁对象前,会调用该对象的finalize方法
//,程序员就可以在 finalize中,写自己的业务逻辑代码(比如释放资源:数据库连接,或者打开文件..)
//,如果程序员不重写 finalize,那么就会调用 Object类的 finalize, 即默认处理
//,如果程序员重写了finalize, 就可以实现自己的逻辑
bmw = null;
System.gc();//主动调用垃圾回收器
System.out.println("程序退出了....");
}
}
class Car {
private String name;
//属性, 资源。。
public Car(String name) {
this.name = name;
}
//重写finalize
@Override
protected void finalize() throws Throwable {
System.out.println("我们销毁 汽车" + name );
System.out.println("释放了某些资源...");
}
}
二、包装类Byte、Short、Integer、Long、Float、Double、Character、Boolean
装箱/拆箱
- compareTo():比较两个对象的值
- equals():与参数比较值
- parseXXX():将String类型参数转换为XXX类型对象
- valueOf():参数为String类型时,将该对象转换为String类型的值
- toString():返回一个该类型的值的String对象
三、Math
- abs():返回绝对值
- max():返回较大的
- min():返回较小值
- sqrt():返回参数的正确舍入的正平方根
- addExact():返回参数的和
- subtraExact():返回参数的差
- multiplyExact():返回参数的乘积
四、String
- charAt():传入一个int类型参数,返回指定位置的字符
- compareTo()与参数比较,相同返回0,小于返回-1,大于返回1
- concat():将参数字符串连接到字符串串尾
- contains() :查找字符串中是否包含某字符
- equals():字符串值比较
- intern():返回对象的值(调用该方法时,返回值在常量池中)
- length():返回字符串的长度
- isEmpty():判断是否是空字符串
- toLowerCase():将所有字符串转换为小写
- toUpperCase():将字符串所有字符转换为大写
- trim():返回字符串副本,忽略首部和尾部空白
- equalsIgnoreCase():与equals类似,忽略大小写
- substring():截取字符串
- toCharArray():将字符串转换为字符数组
- split():以指定字符分割字符串
- getBytes():将字符串以字节数组返回
- replace() : 替换任意字符串
- replaceAll() : 替换任意字符串,支持正则
- replaceFirst() : 替换第一个符合条件的字符串
五、StringBuffer和StringBuilder
- append():在字符串后面添加字符,可以是大部分数据类型
- charAt():传入一个int类型参数,返回指定位置的字符
- delete():删除指定区间的字符
- insert():在指定位置插入元素
- setCharAt():替换指定位置字符,参数为char类型
- reverse():字符串反转
- replace():替换指定区间字符
六、System
- exit:退出当前程序
- arraycopy:复制数组元素,比较适合底层调用,一般使用Arrays.copyOf完成复制数组
- currentTimeMillens:返回当前时间距离1970-1-1 的毫秒数(long类型)
- gc:运行垃圾回收机制 System.gc();
示例代码:
package com.hspedu.system_;
import java.util.Arrays;
/**
* @author 韩顺平
* @version 1.0
*/
public class System_ {
public static void main(String[] args) {
//exit 退出当前程序
// System.out.println("ok1");
// //老韩解读
// //1. exit(0) 的()中的参数表示程序退出时的状态
// //2. 0 表示程序正常退出
// System.exit(0);//
// System.out.println("ok2");
//arraycopy :复制数组元素,比较适合底层调用,
// 一般使用Arrays.copyOf完成复制数组
int[] src={1,2,3};
int[] dest = new int[3];// dest 当前是 {0,0,0}
//老韩解读
//1. 主要是搞清楚这五个参数的含义
//2.
// src: 源数组
// * @param src the source array.
// srcPos: 从源数组的哪个索引位置开始拷贝
// * @param srcPos starting position in the source array.
// dest : 目标数组,即把源数组的数据拷贝到哪个数组
// * @param dest the destination array.
// destPos: 把源数组的数据拷贝到 目标数组的哪个索引
// * @param destPos starting position in the destination data.
// length: 从源数组拷贝多少个数据到目标数组
// * @param length the number of array elements to be copied.
System.arraycopy(src, 0, dest, 0, src.length);
// int[] src={1,2,3};
System.out.println("dest=" + Arrays.toString(dest));//[1, 2, 3]
//currentTimeMillens:返回当前时间距离1970-1-1 的毫秒数
// 老韩解读:
System.out.println(System.currentTimeMillis());
}
}
七、BigInteger和BigDecimal类
- BigInteger:适合保存比较大的整型
- BigDecimal:适合保存精度很高的浮点型(小数)
BigInteger示例代码:
package com.hspedu.bignum;
import java.math.BigInteger;
/**
* @author 韩顺平
* @version 1.0
*/
public class BigInteger_ {
public static void main(String[] args) {
//当我们编程中,需要处理很大的整数,long 不够用
//可以使用BigInteger的类来搞定
// long l = 23788888899999999999999999999l; // 会出现编译错误:Long number too large.
// System.out.println("l=" + l);
BigInteger bigInteger = new BigInteger("23788888899999999999999999999");
BigInteger bigInteger2 = new BigInteger("10099999999999999999999999999999999999999999999999999999999999999999999999999999999");
System.out.println(bigInteger);
//老韩解读
//1. 在对 BigInteger 进行加减乘除的时候,需要使用对应的方法,不能直接进行 + - * / // 会出现编译错误:Operator '+' cannot be applied to 'java.math.BigInteger', 'int'
//2. 可以创建一个 要操作的 BigInteger 然后进行相应操作
BigInteger add = bigInteger.add(bigInteger2);
System.out.println(add);//
BigInteger subtract = bigInteger.subtract(bigInteger2);
System.out.println(subtract);//减
BigInteger multiply = bigInteger.multiply(bigInteger2);
System.out.println(multiply);//乘
BigInteger divide = bigInteger.divide(bigInteger2);
System.out.println(divide);//除
}
}
BigDecimal示例代码:
package com.hspedu.bignum;
import java.math.BigDecimal;
/**
* @author 韩顺平
* @version 1.0
*/
public class BigDecimal_ {
public static void main(String[] args) {
//当我们需要保存一个精度很高的数时,double 不够用
//可以使用 BigDecimal
// double d = 1999.11111111111999999999999977788d;
// System.out.println(d);
BigDecimal bigDecimal = new BigDecimal("1999.11");
BigDecimal bigDecimal1 = new BigDecimal("1999.11111111111999999999999977788");
BigDecimal bigDecimal2 = new BigDecimal("3");
System.out.println(bigDecimal);
//老韩解读
//1. 如果对 BigDecimal进行运算,比如加减乘除,需要使用对应的方法 // 会出现编译错误:Operator '+' cannot be applied to 'java.math.BigDecimal', 'double'
//2. 创建一个需要操作的 BigDecimal 然后调用相应的方法即可
System.out.println(bigDecimal.add(bigDecimal2));
System.out.println(bigDecimal.subtract(bigDecimal2));
System.out.println(bigDecimal.multiply(bigDecimal2));
//System.out.println(bigDecimal.divide(bigDecimal2));//可能抛出异常ArithmeticException
//解决方案: 在调用divide 方法时,指定精度即可. BigDecimal.ROUND_CEILING
//如果有无限循环小数,就会保留 分子 的精度
System.out.println(bigDecimal.divide(bigDecimal2, BigDecimal.ROUND_CEILING));
}
}
八、Date
- getTime():获取当前时间距离原点时间的毫秒数
- setTime():设置时间,参数为long类型,可以将时间设置为距原点时间参数毫秒后的时间
- toLocaleString():创建一个固定格式的对象,方便看懂,但是已经弃用
九、SimpleDateFormat
- SimpleDateFormat():无参时创建一个使用默认的格式的对象,传入“yyyy-MM-dd HH:mm:ss”这种规定格式时创建一个规定格式的对象
- format():传入一个date类型的参数,然后返回一个一个转换后的字符串
- parse;(): 字符串时间转换
十、Calendar
注:该类为抽象类,没有构造方法,以下是本类中一些特定的名称
YEAR:年
MINUTE:分
DAY_OF_WEEK_IN_MONTH:某月中第几周
MONTH:月
SECOND/MILLISECOND:秒/毫秒
WEEK_OF_MONTH:日历式的第几周
DATE :日
DAY_OF_MONTH:日
DAY_OF_YEAR:一年的第多少天
HOUR_OF_DAY:时
DAY_OF_WEEK:周几
WEEK_OF_YEAR:一年的第多少周
- getInstance():通过类名点该方法获取Calender对象
- set():根据给定的参数设置年月日时分秒
- get():参数为int类型,根据参数返回指定字段的值,比如参数为1返回年
- getTime():返回一个Date类型的值(相当于Calander->Date
- setTime():传入一个Date类型的变量,返回一个Calander值(相当于Date->Calander)
- add():参数为指定字段(年月日等等,通过int或者Calander.XXX传入),另一个参数为改变的量,无返回值
十一、集合类
泛型
(类或方法)的类型参数
泛型定义:<> T,E,K,V
extends 使用?和extends关键字的类实例,不能添加,一般用于方法参数
suppr 使用?可添加super后类的元素,获取时无类型限制,一般用于方法返回值
阈值:过大容易增大哈希冲突
IO流
BIO(传统的 Java IO编程)- 同步阻塞
可以借助IO流实现深拷贝
相关类:
Entity类:
package org.example.entity;
import java.io.Serializable;
/**
* @author xhh
* @version 1.0
* @since 1.0
*/
public class Entity implements Serializable {
private static final long serialVersionUID = 1L;
private Integer id;
private transient String name;
private Subassembly subassembly;
public Entity() {
}
public Entity(Integer id, String name, Subassembly subassembly) {
this.id = id;
this.name = name;
this.subassembly = subassembly;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Subassembly getSubassembly() {
return subassembly;
}
public void setSubassembly(Subassembly subassembly) {
this.subassembly = subassembly;
}
@Override
public String toString() {
return "Entity{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
Subassembly类:
package org.example.entity;
import java.io.Serializable;
import java.util.Date;
/**
* @author xhh
* @version 1.0
* @since 1.0
*/
public class Subassembly implements Serializable {
private Date time;
private int status;
public Date getTime() {
return time;
}
public void setTime(Date time) {
this.time = time;
}
public int getStatus() {
return status;
}
public void setStatus(int status) {
this.status = status;
}
}
- 1.通过序列化后再反序列化回来得到的对象就是序列化对象深拷贝后的结果,即,即使对象中存在引用类型属性,两个对象中的该属性也不会指向同一个地址
package org.example;
import org.example.entity.Entity;
import org.example.entity.Subassembly;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Entity> list = Arrays.asList(
new Entity(1, "test1", new Subassembly()),
new Entity(2, "test2", new Subassembly())
);
serialize(list, "/Users/xhhbrilliant/list.dat");
Object o = dserialize("/Users/xhhbrilliant/list.dat");
List<Entity> l = (List)o;
System.out.println(list.get(0).getSubassembly() == l.get(0).getSubassembly());
}
public static void serialize(Object src, String dist) {
ObjectOutputStream oos = null;
try {
oos = new ObjectOutputStream(new FileOutputStream(dist));
oos.writeObject(src);
oos.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static Object dserialize(String dist){
ObjectInputStream ois = null;
Object o = null;
try {
ois = new ObjectInputStream(new FileInputStream(dist));
o = ois.readObject();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
try {
ois.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return o;
}
}
- 2.如若我们利用上述方式去进行深拷贝,在每次进行深拷贝时还需要创建一个中间介质,比较麻烦。故,我们还可以用另一种方式达到深拷贝,即利用ByteArrayOutputStream类来接受序列化的结果(相当于用ByteArrayOutputStream类实例化对象代替文件,也就是流代替文件来存储写入的数据,再通过读取流来获取数据)
package org.example;
import org.example.entity.Entity;
import org.example.entity.Subassembly;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
import java.util.List;
public class Main {
public static void main(String[] args) {
Entity entity = new Entity(1, "test1", new Subassembly());
Entity o = deepClone(entity);
System.out.println(entity.getSubassembly() == o.getSubassembly());
}
public static<T> T deepClone(T o) {
T returnVal = null;
ObjectOutputStream oos = null;
ObjectInputStream ois = null;
try {
// 这里相当于往baos流中写入数据
ByteArrayOutputStream baos = new ByteArrayOutputStream();
oos = new ObjectOutputStream(baos);
oos.writeObject(o);
oos.flush();
// ByteArrayOutputStream类有无参构造器,而ByteArrayInputStream类没有,故必须要指定一个字节数组大小。由于在上面已经完成了将数据写入到流的工作,所以这里实例化的ByteArrayInputStream对象只需要给一个上面写入的数据的字节数组大小即可,故传入baos.toByteArray()【toByteArray是ByteArrayOutputStream类中的一个方法,该方法会将ByteArrayOutputStream类中用于接收数据的属性buf(字节数组)再复制一份儿返回回去】
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
ois = new ObjectInputStream(bais);
returnVal = (T)ois.readObject();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
try {
ois.close();
oos.close();
} catch (IOException e){
e.printStackTrace();
}
}
return returnVal;
}
}
NIO(Java Non-Blocking IO)- 同步非阻塞
NIO是java1.4之后才有的,虽然其效率高但由于使用起来很复杂,故用的人并不是很多。
NIO同BIO一样,主要是用于处理设备之间的数据传输,如读写文件(硬盘)和网络通信。要会使用NIO技术对文件进行基本的读写操作;而网络通信方面则了解即可,因为大多数涉及网络部分都会通过Netty框架中的技术取解决,即不用自己写。
Netty:
Netty是由JBOSS提供的一个java开源框架,现为 Github上的独立项目。Netty提供异步的、事件驱动的网络应用程序框架和工具,用以快速开发高性能、高可靠性的网络服务器和客户端程序。
也就是说,Netty 是一个基于NIO的客户、服务器端的编程框架,使用Netty 可以确保你快速和简单的开发出一个网络应用,例如实现了某种协议的客户、服务端应用。Netty相当于简化和流线化了网络应用的编程开发过程,例如:基于TCP和UDP的socket服务开发。
“快速”和“简单”并不用产生维护性或性能上的问题。Netty 是一个吸收了多种协议(包括FTP、SMTP、HTTP等各种二进制文本协议)的实现经验,并经过相当精心设计的项目。最终,Netty 成功的找到了一种方式,在保证易于开发的同时还保证了其应用的性能,稳定性和伸缩性。
- Java NIO原理:与传统Java IO流不同,其不再以程序(内存)为基准,而是以Buffer(缓冲区)为基准
- Java NIO通常对二进制文件进行处理,基本不会对文本文件进行处理
- Java NIO中Buffer:
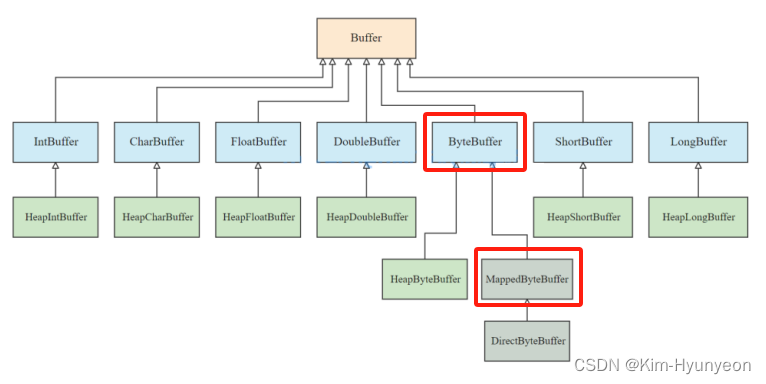
Buffer的分配:
ByteBuffer.allocate(1024); // 分配堆内内存
ByteBuffer.allocateDirect(1024); // 分配堆外内存
ByteBuffer.wrap(“data”.getBytes(StandardCharsets.UTF_8)); // 分配堆内内存
- MappedByteBuffer:采用内存映射的方式进行读写
零拷贝:指CPU不需要参与数据的搬运复制,而内存映射就是实现零拷贝的一种方案。
AIO(Asynchronous IO)- 异步非阻塞
在Java中,AIO代表异步I/O(Asynchronous I/O),它是Java NIO的一个扩展,提供了更高级别的异步I/O操作。AIO允许应用程序执行非阻塞I/O操作,而无需使用Selector和手动轮询事件的方式。
与传统的BIO和Java NIO相比,AIO最大的特点是它的异步I/O操作模式。在AIO中,当I/O操作完成时,操作系统会通知应用程序,而不需要应用程序主动查询或等待操作完成。
由于AIO技术是刚刚兴起的,适用场景并不多,故先不作深入了解。
网络编程
TCP
UDP
HTTP
- GET
- POST
- 远程调用:一个应用发给另一个,像手机的发给服务器一个请求
多线程
反射
反射是较好的解决通用的方式。虽然其效率较低,但不是说低到不能用。
Java新特性
JDBC
- PreparedStatement 执行语句效率要比 Statement 执行语句效率较快。其原因是由于 PreparedStatement 执行语句时利用了数据库中的缓存。即在第一次执行完某个语句后该语句就放入了数据库缓存中,如若再次执行该语句,数据库就会直接执行缓存中的那个语句,从而提高的效率
- 批处理(Batch):当数据量过多时,批量处理会出现的问题:
① 内存溢出
② 数据库执行会慢- 调用存储过程
若在Java中调用数据库中的存储过程虽然执行速度会变快,但随之而来的是程序的可移植性就变差了;
不用Mysql中的存储过程的原因:Mysql存储过程的语法很别扭,所以几乎不怎么创建mysql存储过程还是不怎么调用?;
Java调用Oracle存储过程两种方法:
①
② 针对性较强,版本低,Mysql都不行


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









