






排序算法
STL中排序
std::sort(),接受容器开始和终端标记,以及一个可选的比较器,但不能保证相等选项的原有顺序(不稳定)std::stable_sort可以保证稳定性(稳定)- STL中采用的是快速排序
排序原理
1.一些简单排序算法的下界
成员为数的数组的逆序:具有性质i<j但是a[i]>a[j]的序偶;逆序对的个数正好是需要插入排序执行的交换次数;
定理1:N个互异的元素的数组的平均逆序数是N(N-1)/4
定理2:通过交换相邻元素进行排序的任何算法平均都需要O(N2)的时间,因为逆序数平均是那啥,每次值减少一个
这个定理说明,需要高效的算法每次不知删除一个逆序
2. 排序算法的一般下界
- 任何只用到比较的排序算法,在最坏的情况下都需要O(N*logN),也就是堆排序、归并算法是最优的
- 只用到比较的排序算法,平均都需要O(N*logN)次比较,这也就是快排是最优的
3.常见排序的比较
n较小的时候,用简单排序更好;n越大,用改进排序

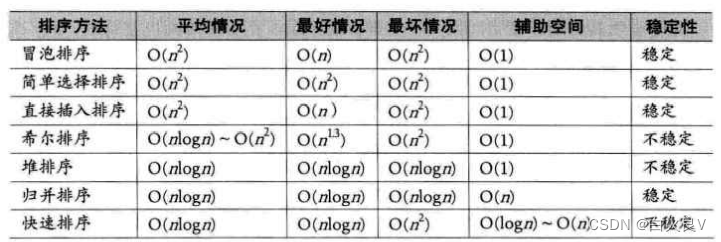
常用排序算法
1. 插入排序
原理
默认位置0到p-1的元素以及排过序了,从当前数往前循环,比当前数大的往后移move,最后当前数补上空位
std::move的作用:
右值引用的出现,是用来减少对象构造和析构操作,达到提高程序效率的目的;
使用std::move(),意味着放弃所有权,可以用来将其转化为右值引用;
int i=22;int& j=i;j=11;//左值引用,j引用i的存储位置,修改j就是改变i的值 int& i=22//错误, const int& j=20//常量引用,相当于生成变量等于20,在引用这个变量 int&& j=22//右值引用右值引用的写法为 T&& val,两个地址符要挨在一起,在模板中被称为万能引用
注意左值引用和右值引用的使用区别,其实本质都是为了减少无效的拷贝
std::move() 函数会转移对象的所有权,转移操作之后将左值转为右值引用,原对象不可再直接使用
可以使用 is_reference、 is_rvalue_reference、 is_lvalue_reference 来判断引用类型move的源码:并没有实际的“移动”操作,只是在内部进行了强制类型转换,返回一个相关类型的右值引用
/**
- @brief Convert a value to an rvalue.
- @param __t A thing of arbitrary type.
- @return The parameter cast to an rvalue-reference to allow moving it.
*/
templateconstexpr typename std::remove_reference<_Tp>::type&& move(_Tp&& __t) noexcept { return static_cast<typename std::remove_reference<_Tp>::type&&>(__t); }
代码
template<typename T>
void insertSort(vector<T>& a) {
//直接从1位置开始
for (int p=1;p<a.size();p++)
{
T temp = std::move(a[p]);//把p位置上的元素移动到temp上
int j;
//所有比temp大的元素都被向右移动一个位置
//由于循环迭代,只需要按一步一步往前看,因为前部分已经是有序数列
for (j=p;j>0&&temp<a[j-1];--j)
{
//将数往后移,这个位置空出来了,被掏空了
a[j] = std::move(a[j - 1]);
}
//找到插入的位置插进去a[p]
a[j] = std::move(temp);
}
}
分析
- 由于两层嵌套循环,因此插入排序的时间复杂度为O(N2)
- 如果预先排完了则为O(N),因为内存for一下子就失败了,所以常用于几乎被排序的数列
- 大多数情况和其他排序算法一样,都是O(N2)
2. 希尔排序
原理
-
也叫缩减增量排序;
-
利用一个增量序列,h1,h2,h3,h4…ht,相距同等增量hk;完成增量排序后,实现了增量序列的有序性;最后缩减增量;
-
实际上每一趟hk排序的作用就是对hk个独立的子数组执行一次插入排序;
-
增量序列比较流行的选择的是选用ht=[N/2]和hk=[h(k+1)/2],但是并不好,一下用该增量序列演示
代码
template<typename T>
void shellsort(vector<T>& a)
{
for (int gap=a.size()/2;gap>0;gap/=2)
{ //这里从gap开始,对应插入排序的1位置
//每次选定增量后,相当于做一次插入排序
for (int i=gap;i<a.size();++i)
{
T temp = std::move(a[i]);
int j = i;
for (;j>=gap&&temp<a[j-gap];j-=gap)
{
a[j] = std::move(a[j - gap]);
}
a[j] = std::move(temp);
}
}
}
分析
- 以上的希尔排序最坏情况是O(N2);
- Hibbard的增量序列形如1,3,7,。。。,2的k次-1,最坏复杂度为O(N1.5);
- 增量序列最希尔排序运行时间的改进很重要,但是要高等数论和组合数学来证明
- 希尔排序的性能是可接受的,编程简单的特性让它成为适度的大量的输入数据常用的算法
- 增量排序的最后一个增量必须为1
3. 堆排序
- 之前总结过时间复杂度较稳定O(N*logN),O(1)空间复杂度
- 不能保证相等选项的原有顺序(不稳定)
- 初始构建所需次数较多,不适合排序个数较小的情况
4. 归并排序
原理
- 递归的合并两个已排序的表,到第三个表,当有输入表用完,将另一个表的剩余部分复制到第三个表中;
- 首先要递归的分治,然后归并,时间复杂度为O(N*logN)
代码
/**
* 归并排序算法
*/
template<typename Comparable>
void mergeSort(vector<Comparable>& a)
{
vector<Comparable> tempArray(a.size());
mergeSort(a, tempArray, 0, a.size() - 1);
}
/**
* 进行递归调用的内部方法
* a为Comparable的数组
* left为子数组最左元素的下标
* right为子数组最右元素的下标
*/
template<typename Comparable>
void mergeSort(vector<Comparable>& a,vector<Comparable> tempArray,int left,int right)
{
if (left<right)
{
int mid = (left + right) / 2;
mergeSort(a, tempArray, left, mid);
mergeSort(a, tempArray, mid + 1, right);
merge(a, tempArray, left, mid + 1, right);
}
}
/**
* 合并子数组已经排序完成的两部分
* a为Comparable项的数组
* tempArray为防止归并结果的数组
* leftPos为子数组最左元素的下标
* rightPos为后半部分七点的下标
* rightEnd为子数组最右元素的下标
*/
template<typename Comparable>
void mergeSort(vector<Comparable>& a, vector<Comparable> tempArray, int leftPos,int rightPos, int rightEnd)
{
int leftEnd = rightPos - 1;
int tempPos = leftPos;
int numElements = rightEnd - leftPos + 1;
//主循环
while (leftPos<=leftEnd&&rightPos<=rightEnd)
{
if (a[leftPos] <= a[rightPos])
tempArray[tempPos++] = std::move(a[leftPos++]);
else
tempArray[tempPos++] = std::move(a[rightPos++]);
}
//复制剩余的子串
while (leftPos <= leftEnd)
tempArray[tempPos++] = std::move(a[leftPos++]);
while (rightPos <= rightEnd)
tempArray[tempPos++] = std::move(a[rightPos++]);
//将排序完成的数组复制回原数组a
for (int i = 0; i < numElements; ++i, --rightEnd)
a[rightEnd] = std::move(tempArray[rightEnd]);
}
分析
- 每次合并时间是N-1,分治的时间每次是T(N)=T(N/2)+N,所以整个算法的时间复杂度是O(N*logN+N),也就是O(N*logN)
- 需要存原始序列的N存储空间和递归时logN栈空间,因此空间复杂度为O(N+logN)
- 整个算法中花费数据复制到临时数组在复制回来的附加工作,明显减慢了排序的速度;而且需要线性的附加内存作为临时数组;
- 与其他O(N*logN)排序算法相比,归并排序的时间严重依赖于比较元素和所在数组中移动元素的相对开销,这些开销与语言相关:
3.1在Java中执行比较多的排序很昂贵(因为比较不容易内敛使用,动态开销大),但是移动元素很省时,而且归并中比较相对少,是Java库中泛型排序使用的算法;
3.2在C++中,拷贝对象很昂贵,但是编译器主动执行内敛优化,对象的比较相对省时间,并且用数据移动更快了,所以有理由让算法使用个更多的比较,通常用快排算法;
5. 快速排序
原理
- C++中最快的泛型排序算法,平均运行时间是O(N*logN),最坏情况是O(N2),但是极难出现
- 经典的快排:选取S中任一元素v,作为枢纽元;比较大小分成三个集合,递推划分;再合并为原数组,向上回归
- 俺的理解是对于归并排序的(分治+合并的比较部分)替换成(划分为大小三个集合),划分过程中已经判断好了大小
代码-经典快排
/**
* 经典快排
*/
template<typename Comparable>
void quickSort(vector<Comparable>& items)
{
if (items.size()>1)
{
vector<Comparable> smaller;
vector<Comparable> same;
vector<Comparable> larger;
Comparable chosenItem = items[items.size() / 2];
//划分为三个集合
for (auto& i:items)
{
if (i < chosenItem)
smaller.push_back(std::move(i));
else if (i > chosenItem)
larger.push_back(std::move(i));
else
same.push_back(std::move(i));
}
//递归
quickSort(smaller);
quickSort(larger);
//插入
std::move( );
std::move(begin((same), end(same), begin(items)+smaller.size());
std::move(begin((larger), end(larger), end(items)-larger.size());
}
}
分析
枢纽元的选择
- 不要选用第一个元素,因为可能序列预先排序,劣质分割导致O(N2);
- 安全做法是用随机器选择枢纽元;
- 数组的中位数是最好的,但是你不知道是多少,所以常常采用的是左端、右端、中心位置的三个元素的中位数
代码-现代快排
- 对于小数组,插入排序更好,截止范围N=10;
- 一趟序列将待排记录分割为独立的两部分,其中一部分比另一部分小,递推划分,导到整列有序的目的
/**
* 实际快排历程
*/
template<typename Comparable>
void quickSort(vector<Comparable>& items)
{
quickSort(a, 0, a.size() - 1);
}
/**
* 返回left, right, center三项的中位数,
* 将他们排序并隐匿枢纽元
*/
template<typename Comparable>
const Comparable& median3(vector<Comparable>& a, int left, int right)
{
// 三项排序
int center = (left + right) / 2;
if (a[center]<a[left])
std::swap(a[left], a[right]);
if (a[right] < a[left])
std::swap(a[right], a[left]);
if (a[right] < a[center])
std::swap(a[right], a[center]);
//枢纽元放置到right-1处
std::move(a[center], a[right]);
return a[right];
}
/**
* 递归调用的内部快排方法
* 三数中位数分割法,截止范围10的截止技术
* a是Comparable项的数组
* left为子数组最左元素下标
* right为子数组最右元素下标
*/
template<typename Comparable>
void quickSort(vector<Comparable>& a, int left, int right)
{
if (right - left > 10)
{
//选定枢纽元
const Comparable& pivot = median3(a, left, right);
int i = left, j = right - 1;
//做分割
//for循环是针对一个枢纽元排序,while是为了移动至大于或小于枢纽元的位置
for (;;)
{
while (a[++i] < pivot);
while (pivot < a[--j]);
if (i < j)
std::swap(a[i], a[j]);
else
}
//恢复枢纽元
std::swap(a[i], a[right-1]);
//将大于和小于枢纽元的元素分别排序
quickSort(a, left, i - 1);
quickSort(a, i + 1, right);
}
else //子数组插入排序
insertSort(a);
}
分析:
- 最坏的情况是O(N2),平均情况是O(N*logN)
应用-快速选择
选择集合S中第k个最小元的算法;
俺的理解是一个枢纽元完成for循环后,最终会回到他应在的位置,这个位置是正确的,也就是i位置就是第i小的元素,用i和k比就行
/**
* 递归调用的内部选择方法
* 使用三数终止分割法,截止范围是10的截止技术
* 第k个最小项放在a[k-1]出
*/
template<typename Comparable>
void quickSelect(vector<Comparable>& a, int left, int right, int k)
{
if (right - left > 10)
{
//选定枢纽元
const Comparable& pivot = median3(a, left, right);
int i = left, j = right - 1;
//做分割
//for循环是针对一个枢纽元排序,while是为了移动至大于或小于枢纽元的位置
for (;;)
{
while (a[++i] < pivot);
while (pivot < a[--j]);
if (i < j)
std::swap(a[i], a[j]);
else
break;
}
//恢复枢纽元
std::swap(a[i], a[right-1]);
if (k <= i)
quickSelect(a, left, i - 1, k);
else if(k>i+1)
quickSelect(a, i + 1, right, k);
//如果k=i+1,那么枢纽元就是第k个最小元,可以作为答案返回
}
else //子数组插入排序
insertSort(a);
}
纽元排序,while是为了移动至大于或小于枢纽元的位置
for (;;)
{
while (a[++i] < pivot);
while (pivot < a[--j]);
if (i < j)
std::swap(a[i], a[j]);
else
break;
}
//恢复枢纽元
std::swap(a[i], a[right-1]);
if (k <= i)
quickSelect(a, left, i - 1, k);
else if(k>i+1)
quickSelect(a, i + 1, right, k);
//如果k=i+1,那么枢纽元就是第k个最小元,可以作为答案返回
}
else //子数组插入排序
insertSort(a);
}















 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









