








🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、快速发展的AI世界:为何关注Gemma 3?
🔍 什么是 Gemma 3?
Gemma 3 是 Google DeepMind 在开源小模型方向推出的新一代轻量级语言模型,属于其 Gemma 系列的一部分。该系列旨在提供开源、强性能、高安全性的语言模型,适合企业和开发者在本地私有部署。
🚀 为什么要关注 Gemma 3?
1️⃣ 高性能轻量模型
Gemma 3 在模型压缩和推理效率方面表现优异,即便在小参数量(例如 2B、7B)的模型中,也能达到接近 GPT-3.5 甚至逼近 GPT-4 的性能水准。
2️⃣ 开源且可商用
Gemma 3 模型使用了Apache 2.0 许可证,可放心用于商业项目,与 Meta 的 LLaMA 模型(限制较多)不同,极大降低了使用门槛。
3️⃣ 强大的多语言能力
得益于 Google 的大规模语料和训练体系,Gemma 3 在多语言能力、逻辑推理、编程代码等任务上表现更加均衡,非常适合构建本地化应用。
4️⃣ 可部署在本地设备
Gemma 3 支持部署在:
-
CPU / GPU / TPU 环境
-
Google Cloud Vertex AI
-
Hugging Face、Kaggle、Colab、NVIDIA NeMo 甚至可以在高性能笔记本上本地推理,非常适合对数据隐私敏感的场景。
5️⃣ 生态和工具链完备
-
与 Gemini 系列模型共享架构设计
-
已适配 Google 的 Axlearn、JAX、TensorFlow、Triton 等工具
-
支持与 LangChain、LlamaIndex 等生态集成
🎯 Gemma 3 适用场景
| 场景 | 说明 |
|---|---|
| 本地知识库问答 | 企业文档、知识库私有化部署 |
| 多语言客服助手 | 覆盖亚洲、欧洲多语种交互 |
| 隐私敏感任务 | 医疗、金融等无法上云的AI应用 |
| AI 教育助手 | 在教育场景中快速部署、成本低廉 |

2、Gemma 模型的背景:Google 的开源承诺
🌐 背景起源:开源之路的延续
Google 长期以来都是 AI 领域开源运动的重要推动者,以下几个重要事件奠定了 Gemma 系列的基础:
| 年份 | 事件 | 意义 |
|---|---|---|
| 2015 | 开源 TensorFlow | 构建了全球最受欢迎的 AI 框架之一 |
| 2017 | 发布 Transformer 论文 | 奠定现代大语言模型技术基础 |
| 2019 | 推出 T5(Text-to-Text Transfer Transformer) | 开放多任务语言理解能力 |
| 2023 | 推出 Gemini 模型系列 | 进入多模态智能新时代 |
| 2024 | 发布 Gemma 开源模型 | 响应社区呼声,强调小模型、私有部署、安全性 |
💡 Gemma 的定位
Gemma 不同于 Google 更强大的 Gemini 系列(闭源),它的使命是:
为研究人员、开发者、中小企业提供一个可商用、可部署的高性能小模型平台。
它聚焦 2B、7B 等轻量模型规模,强调易部署、低门槛、隐私友好,填补了企业无法使用闭源大模型的空白。

二、Gemma 3 基础:什么是 Gemma?
1、Gemma 模型的诞生和设计理念
🌱 诞生背景:AI 不应只有巨头能用
尽管大型模型如 GPT-4、Gemini 1.5 令人惊艳,但它们常常伴随着:
-
高部署门槛(需要强算力)
-
高成本(订阅/调用费用)
-
隐私顾虑(数据需上传云端)
-
闭源黑盒(无法调试、定制)
Gemma 应运而生,目标是解决上述问题,让更多开发者、企业、研究者 自由、安全、高效地使用语言模型技术。
✨ 设计理念:为现实世界而生的“小而强”模型
1. 轻量化
-
提供 2B 和 7B 两种规模
-
可在消费级 GPU、本地服务器上运行
-
面向边缘计算、本地部署友好场景
2. 高性能
-
源于 Gemini 模型的核心架构设计
-
具备强大的理解与生成能力
-
在多个基准测试中媲美或超越 LLaMA、Mistral 等同量级模型

2、Gemma 模型的优势与特点
✅ 1. 轻量化设计:适合本地与边缘部署
-
提供 2B 和 7B 参数版本,资源占用小
-
支持在消费级 GPU(如 RTX 3090、A100)或 TPU 上运行
-
非常适合本地部署、私有云、嵌入式设备、边缘计算等场景
✅ 2. 高性能表现:媲美甚至超越同类模型
-
源于 Google Gemini 的架构优化,性能优于同规模的 LLaMA 2、Mistral、Command-R 等
-
在 MMLU、HellaSwag、ARC 等基准测试中表现突出
-
推理速度快,适合实时交互类应用
✅ 3. 完全开源,灵活授权
-
开源模型权重、代码、训练方法
-
使用 Apache 2.0 许可证,可免费商用
-
可在 Hugging Face、Kaggle、Colab 上一键体验
✅ 4. 高度兼容与易集成
-
支持 JAX 与 PyTorch,兼容 Transformer 库(如 Transformers、Axolotl、ggml)
-
可转换为 ONNX、TensorRT、TFLite 等格式,用于各类推理框架
-
可与 LangChain、LoRA、QLoRA 等生态工具无缝配合
Gemma 模型 = 小巧 + 高性能 + 商用友好 + 安全可靠,是未来开源 LLM 领域的新基准。
🔍 与其他模型的对比(7B 为例)
| 特性 | Gemma 7B | LLaMA 2 7B | Mistral 7B |
|---|---|---|---|
| 性能表现 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 商用授权 | ✅ 免费可商用 | ❌ 需申请许可 | ✅ |
| 安全机制 | ✅ 对抗性过滤 | ❌ | ❌ |
| 开发环境支持 | JAX, PyTorch | PyTorch | PyTorch |
| 社区活跃度 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |

三、Gemma 3 技术深度解析
1、Gemma 3 的架构
🚀 Gemma 3 的架构解析
🧠 模型结构:解码器(Decoder-only Transformer)
Gemma 3 采用与 Gemini 系列一致的 Decoder-only 架构,与 GPT、LLaMA 类似,适用于语言生成任务。其特点包括:
-
全自回归生成结构
-
Masked Multi-head Self Attention
-
高效的并行处理能力
-
可扩展的深度和宽度配置
✅ 优势:推理效率高、生成文本质量优秀、训练和微调成本更可控。
🧬 核心技术组件
| 组件 | 描述 |
|---|---|
| RoPE(旋转位置编码) | 支持更长上下文的建模,替代传统位置编码 |
| SwiGLU 激活函数 | 替换 ReLU 或 GELU,提高表达能力和收敛速度 |
| 多 Query Attention | 降低推理延迟,特别适用于多请求并发场景 |
| NormFormer / RMSNorm | 提升稳定性,优化训练收敛过程 |
| 分组注意力机制(GQA) | 高效处理大规模输入,减少显存消耗 |
📦 支持的推理与训练框架
Gemma 3 将支持如下主流框架,方便开发者灵活部署与使用:
-
PyTorch / JAX
-
Hugging Face Transformers
-
ONNX、TensorRT、ggml、MLC LLM(用于本地/移动端推理)
-
支持 LoRA / QLoRA 微调
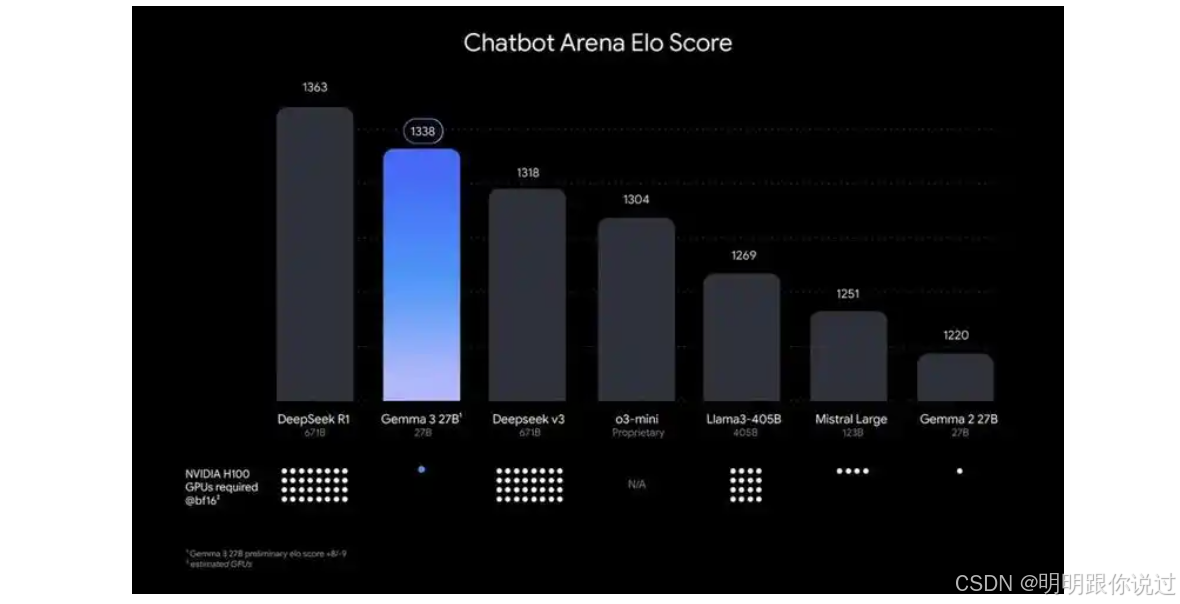
2、模型训练与优化
🧠 数据集与预训练
- 大规模数据集: Gemma 3 在一个非常大型的文本和代码数据集上进行预训练。 这个数据集包括:
- 网络文本: 包含了来自互联网内容的广泛数据。
- 书籍: 海量书籍数据,提供了更深层次的知识和语义理解。
- 代码: 包含来自 GitHub 等平台的大量代码,提升了模型在代码生成和理解方面的能力。
- 数据清理和过滤: Google 投入了大量精力进行数据清理和过滤,以移除低质量、有害或偏见的内容,确保模型的训练数据更安全、可靠。
- 数据多样性: 强调数据多样性,包括不同语言、写作风格和主题,以提高模型的泛化能力。
- Tokenization: 使用了 SentencePiece 分词器,这是一种基于子词的分词方法,能够在处理罕见词和词形变化时表现更好。
🚀 训练过程
- 分布式训练: 使用大规模分布式训练,利用数千个加速器进行训练,以缩短训练时间。
- 混合精度训练 (Mixed Precision Training): 结合了 FP16 和 BF16 两种精度,平衡了训练速度和内存使用。
- 优化器: 采用了AdamW优化器,并使用学习率调度策略 (Learning Rate Scheduling) 来稳定训练过程, 提升最终模型性能。
- 模型大小: 提供多种模型大小选择,包括 2B 和 7B 参数版本,以适应不同的计算资源和部署需求。

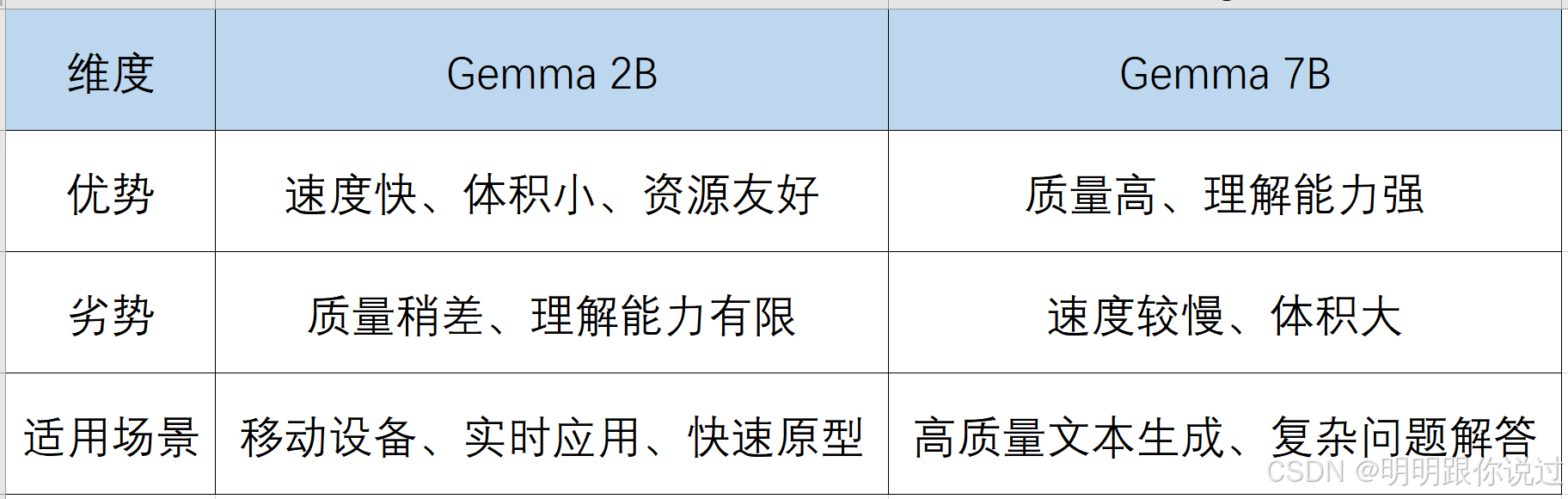
3、不同尺寸 Gemma 模型对比
- Gemma 2B: 参数较少、体积较小的模型,适合在资源受限的环境中使用,例如移动设备或边缘计算设备。在推理速度和效率方面表现出色。
- Gemma 7B: 参数更多、体积更大的模型,在理解和生成文本方面具有更强的能力,通常能提供更高质量的输出。
技术规格对比:

理解能力 (Understanding):
- Gemma 2B: 在理解复杂查询和指令的能力上相对有限。可能需要精细的提示设计才能获得令人满意的结果。
- Gemma 7B: 理解能力更强,能够更好地理解复杂的指令和上下文,从而生成更准确和相关的回复。
生成能力 (Generation):
- Gemma 2B: 生成的文本质量通常不如 Gemma 7B,有时可能不够连贯或缺乏创意。
- Gemma 7B: 生成的文本质量更高,更连贯、更流畅,更具创意。
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











