







Java和大数据系列
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天和大家分享一下Java通过properties文件方法实现JDBC代码案例
#博学谷IT学习技术支持#
前言
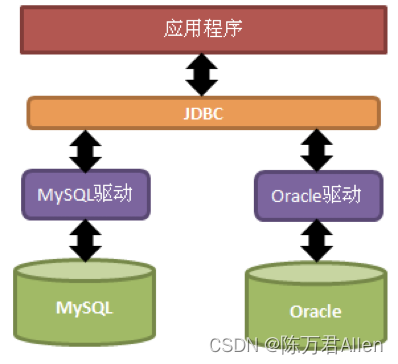
JDBC(Java DataBase Connectivity,java数据库连接)是一种用于执行SQL语句的Java API。JDBC是Java访问数据库的标准规范,可以为不同的关系型数据库提供统一访问,它由一组用Java语言编写的接口和类组成。
JDBC规范(掌握四个核心对象):
- DriverManager:用于注册驱动
- Connection: 表示与数据库创建的连接
- Statement: 操作数据库sql语句的对象
- ResultSet: 结果集或一张虚拟表
JDBC是接口,驱动是接口的实现,没有驱动将无法完成数据库连接,从而不能操作数据库!每个数据库厂商都需要提供自己的驱动,用来连接自己公司的数据库,也就是说驱动一般都由数据库生成厂商提供。
一、使用步骤
1.Maven导包
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.iteheima</groupId>
<artifactId>jdbc</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.30</version>
</dependency>
</dependencies>
</project>
2.案例实现
这里aaa是数据库名字,employee是表名,大家根据自己的情况修改一下
package pack01;
import java.sql.*;
public class demo02 {
public static void main(String[] args) throws Exception {
//注册驱动.这里是mysql 8.0的版本
Class.forName("com.mysql.cj.jdbc.Driver");
//获得连接.
Connection connection =
DriverManager.getConnection("jdbc:mysql://localhost:3306/aaa", "root", "12345678");
//获得执行sql语句的对象
Statement statement = connection.createStatement();
//执行sql语句,并返回结果
ResultSet resultSet = statement.executeQuery("select * from employee");
//处理结果
ResultSetMetaData metaData = resultSet.getMetaData();
int columnCount = metaData.getColumnCount();
while (resultSet.next()){
for (int i = 1; i <= columnCount; i++) {
Object object = resultSet.getObject(i);
System.out.print(object + "\t");
}
System.out.println();
}
//释放资源
statement.close();
connection.close();
}
}
二、代码优化
上面写的代码案例太过简单,是初级入门水平,下面对代码进行封装优化一下,高内聚,低耦合。
1.定义jdbc.properties文件
把需要传递的参数和sql代码都写在配置文件中,这样后期就不用在代码中进行修改了。
DriverClass=com.mysql.cj.jdbc.Driver
Url=jdbc:mysql://localhost:3306/aaa
Username=root
Password=12345678
Sql=select * from employee
2.定义JDBCUtils类
封装一个JDBCUtils类,把配置文件中的代码通过Properties传参过来,这样代码更整洁了。
package pack02;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
public class JDBCUtils {
private static Properties map;
private static String driverClass;
private static String url;
private static String username;
private static String password;
private static String sql;
private JDBCUtils(){}
//封装注册驱动.这里是mysql 8.0的版本
static {
try {
InputStream inputStream =
JDBCUtils.class.getClassLoader().getResourceAsStream("jdbc.properties");
map = new Properties();
map.load(inputStream);
driverClass = map.getProperty("DriverClass");
url = map.getProperty("Url");
username = map.getProperty("Username");
password = map.getProperty("Password");
sql = map.getProperty("Sql");
Class.forName(driverClass);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
//封装获得连接
public static Connection getConnection(){
try {
return DriverManager.getConnection(url, username, password);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
//封装获得执行sql语句的对象
public static ResultSet getResult(Statement statement,Connection connection){
try {
return statement.executeQuery(sql);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
//封装处理结果
public static void printResult(ResultSet resultSet){
try {
ResultSetMetaData metaData = resultSet.getMetaData();
int columnCount = metaData.getColumnCount();
while (resultSet.next()){
for (int i = 1; i <= columnCount; i++) {
Object object = resultSet.getObject(i);
System.out.print(object + "\t");
}
System.out.println();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
//封装释放资源
public static void closeAll(Statement statement,Connection connection){
try {
statement.close();
connection.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
3.最后定义测试类
有了封装类之后,直接通过调静态方法的方式使用就可以了
package pack02;
import java.sql.*;
public class demo01 {
public static void main(String[] args) throws Exception {
//注册驱动.这里是mysql 8.0的版本
//获得连接.
Connection connection = JDBCUtils.getConnection();
//获得执行sql语句的对象
Statement statement = connection.createStatement();
//执行sql语句,并返回结果
ResultSet resultSet =
JDBCUtils.getResult(statement,connection);
//处理结果
JDBCUtils.printResult(resultSet);
//释放资源
JDBCUtils.closeAll(statement,connection);
}
}
总结
今天通过一个小案例和大家分享了一下JDBC的使用方法,并且通过properties文件方法优化了代码,避免了hard coding问题。实现了高内聚,低耦合。















 2936
2936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









