







HBase
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下HBase
#博学谷IT学习技术支持
文章目录
前言
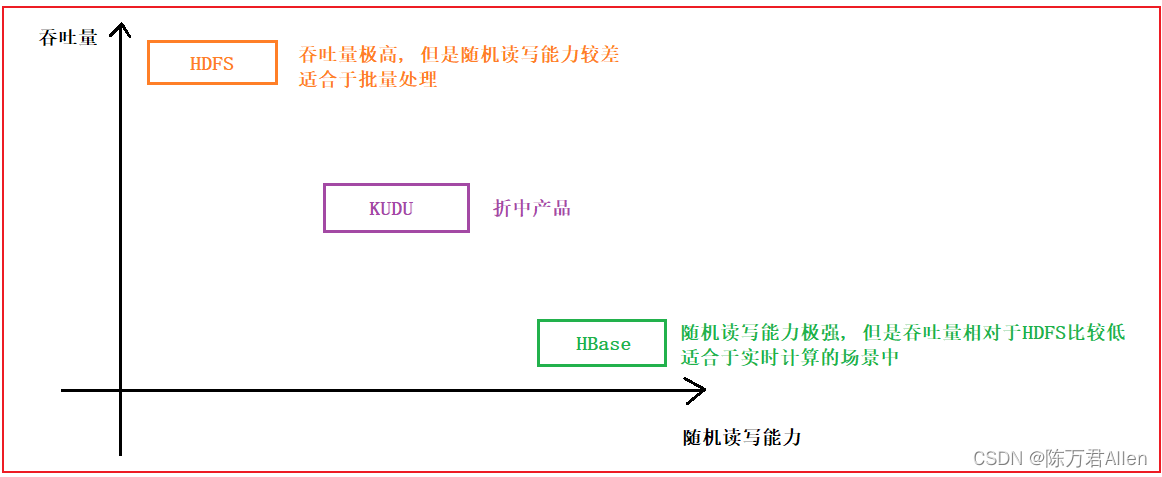
HDFS: 分布式文件存储系统
特点: 吞吐量极高, 适合于进行批量数据处理的工作, 随机的读写能力比较差(压根不支持)
但是, 在实际生产环境中, 有时候的数据体量比较大, 但是希望能够对数据进行随机的读写操作, 而且不能太慢了, 那此时怎么办呢?
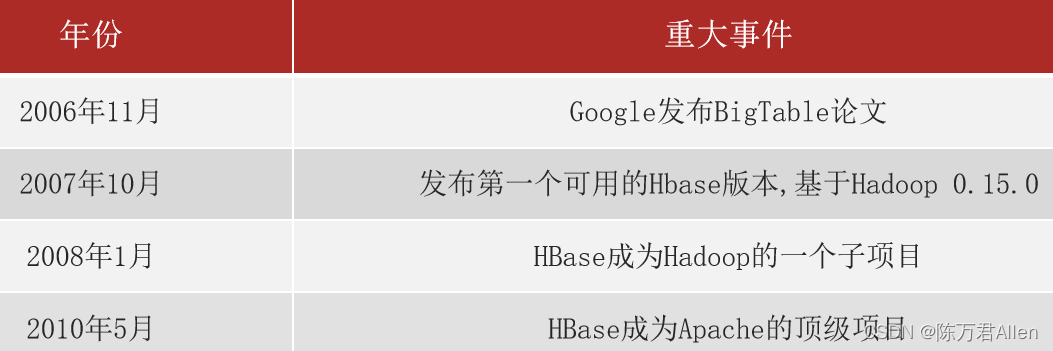
对于市场来说, 其实就迫切需要一款能够支持大规模化的数据存储以及能够进行高效的随机读写操作, 而HBase其实就是在这样的背景下, 产生了, 但是主要的思想来源于google发布的一篇论文: BigTable
一、HBase的基本介绍
1- HBase是一款NoSQL型的数据库, 不支持SQL , 没有表关系, 无法进行Join操作, 不支持事务(仅支持行级事务)
2- HBase是基于google发布BigTable这篇论文而产生的, 基于HDFS, 也就是说, 数据最终是存储到HDFS上, 如果后续想要启动HBase, 必须先启动HDFS
3- 基于Java语言开发的
4- 查询HBase的数据一般有以下几种方式:
第一种: 通过主键来检索
第二种: 通过主键的范围检索
第三中: 查询全部的数据
5- 存储的结构化数据和半结构化的数据
6- HBase的存储的都是以字节类型存储的
7- HBase表的特点:
6.1 大: 可以存储上十亿行的数据, 也可以拥有上百万个列
6.2 面向列的存储方案: 列值的是列族
6.3 稀疏性: 对于Null值, 在HBase中是不占用任何的存储空间的, 所以表可以搞的非常稀疏
二、HBase的应用场景
1- 数据是否需要进行随机读写操作
2- 数据体量比较大(建议TB级以上)
3- 数据比较稀疏
三、HBase和其他软件的区别
1.HBase和RDBMS区别
HBase: 以表的形式存储 存在主键(row key) 不支持SQL 不支持事务(支持行级事务) 无表关系 不支持Join 采用分布式存储引擎 基于HDFS文件系统, 支持存储结构化和半结构化数据
RDBMS: 以表的形式存储 存在主键(Primary Key) 支持SQL 支持事务 存在表关系 支持Join 采用单机存储引擎 基于本地文件系统,支持存储结构化数据
2.HBase和HDFS区别
HBase: 基于 HDFS, 与HDFS是一种强依赖的关系, 启动HBase, 必须先启动HDFS, 数据最终落在HDFS上, 支持高效的随机读写的特性, 吞吐量相对HDFS比较低, 适合实时处理
HDFS: 适合于批处理, 吞吐量极高的, 不支持随机读写的特性, 存储更多是一些过去已经发生过的数据
矛盾: 基于HDFS的HBase支持随机读写, 但是HDFS自己本身不支持, 既有联系, 又有矛盾,说明在HBase的上面一定是做了N多处理的, 才达到当前的这个效果
3 HBase和Hive区别
HIVE: 数据仓库的工具 主要是用于离线数据统计分析, 主要对接的离线业务, 基于 Hadoop 高延迟
HBASE: NoSQL型数据库 主要是用于数据存储工作, 主要对接实时业务, 基于Hadoop 低延迟
注意:
后续 可以让HIVE和HBASE集成在一起, 由HIVE读取HBase中数据, 进行离线统计分析操作, 本质上就是让HIVE换一个地方读取数据
四、HBase的表模型

1- rowkey: 行键,类似于MySQL中每个表的都会有主键 同样类似于 kv类型数据中key
在HBase中, 数据会默认进行排序, 排序的规则为基于rowkey进行字典序升序排序
例如: 1 3 5 2 33 11 22 245 32 51 42 100 请问, 如果按照字典升序排序是怎么样的呢?
字段升序:
1 100 11 2 22 245 3 32 33 42 5 51
规则: 先比较第一位, 如果第一位相同, 比较第二位, 没有第二位比有第二位小, 依次类推
查询方式:
第一种: 根据rowkey查询
第二种: 根据rowkey的范围查询
第三种: 扫描全部数据
2- column family: 列族(列簇)
在创建表的时候, 需要指定其列族信息, 一个表可以有多个列族
在hbase中是基于列族管理和存储的, 一个表中建议列族不要太多了, 能少则少, 能用一个解决,坚决不用多个
在一个列族下可以有多个列(列限定符号), 最大支持上百万个列
3- 列限定符号(列名): 一个列族下可以有多个列名,但是一个列名只能被一个列族所管理,列的数量可以达到上百万个, 在建表的时候不需要指定, 在插入数据的时候, 动态指定即可
4- timestamp(时间戳): 在hbase表中, 每个单元格的数据都是有时间戳的概念的, 默认为插入数据的时间,当然也可以人为指定
5- version(版本号): 在hbase中每一个单元格都是有版本号概念的, 可以基于版本管理 存储每一个单元格历史变化信息
默认版本号为1, 也就是只保留最新的版本数据
6- cell(单元格): rowkey + 列族 + 列名 + 列值
注意: 在建表的时候, 必须指定两项内容: 表名 + 列族
五. HBase的基本shell操作
#如何创建一张表 create
create '表名','列族1','列族2'...
#如何向表中添加数据: put
put '表名','rowkey值','列族:列名','值'
#如何读取某一个rowkey的数据 get
get '表名','rowkey',['列族1','列族2'...],['列族:列名'],['列族1','列族2:列名'...]
#如何删除数据: delete deleteall
delete 和 deleteall区别:
共同点: 都是用于执行删除数据操作
区别点:
1) delete 操作 只能删除表中某个列的数据, deleteall还支持删除某行数据
2) 通过delete删除某个列的数据时候, 默认只删除其最新的版本, 而deleteall直接将其所有的版本数据全部都删除
delete '表名','rowkey','列族:列名'
deleteall '表名','rowkey'[,'列族:列名']
#如何查看表的结构: describe
describe '表名'
#如何清空表: truncate
truncate '表名'
#如何删除表: disable+drop
#先禁用再删除
disable '表名'
drop '表名'
#如何查看表共计有多少行数据:count
count '表名'
#如何查询多条数据格式: scan
scan '表名',[{COLUMNS=>['列族1','列族2']} | {COLUMNS=>['列族1:列名','列族2']}| {COLUMNS=>['列族1:列名','列族2:列名']},{FORMATTER=>'toString'},{LIMIT=>N}]
范围查询:
{STARTROW=>'起始rowkey',ENDROW=>'结束rowkey'}
包头不包尾
说明:
{FORMATTER=>'toString'}: 用于显示中文
{LIMIT=>N} : 显示前N行数据
总结
今天继续和大家分享一下HBase基本操作,下次和大家分享一下一些其他的HBase,包括shell其他的api, java api。HBase的核心原理等等。
















 660
660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









