







1.爬 虫
本节主要是采用Python方法对“重庆九区二手房”页面进行爬取与保存
1.1爬虫分析
1.1.1爬虫类型:
爬虫可以在许多语言中实现。由于python的易用性,python的功能。这里使用程序:爬一个域名下的所有网页,网页之间的指向关系存储在一个字典。可以通过设置域名领域,通过深度和深度可以设置。网络爬虫按照实现的技术和结构可以分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫和深层网络爬虫。实际的网络爬虫系统通常是由这几种爬虫组合而成。
❶通用网络爬虫: 别名全网爬虫。该类型的爬虫获取的目标资源在整个互联网中,其目标数据量庞大,爬行的范围广泛。比如:百度蜘蛛
❷聚焦网络爬虫: 别名主题网络爬虫,是一种按照预先定义好的主题有选择的进行网页爬取的网络爬虫。与通用网络爬虫相比,它的目标数据只和预定义的主题相关,爬行的范围相对固定。主要用于特定信息的获取。
❸增量式网络爬虫: 是指对已下载网页采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面。和周期性爬行和刷新页面的网络爬虫相比,增量式爬虫只会在需要的时候爬行新产生或发生更新的页面 。
❹深层网络爬虫: 是一种用于爬取互联网中深层页面的爬虫程序。和通用网络爬虫相比,深层页面的爬取,需要想办法自动填写对应的表单,因而,深层网络爬虫的核心在于表单的填写。
1.1.2程序的原则:
❶使用打开网页,使用BeautifulSoup解析打开网页;
❷使用函数来找到web页面中的链接,然后保存列表中的链接;
❸步骤1,继续打开web页面,重复深度次。
1.1.3程序点:
❶(非常重要)打开一个网页设置一个时间间隔。你不能马上打开,然后下一个。否则,一方面,你可能会被列入黑名单的网站,从而拒绝您的web页面请求,另一方面,它将导致网站服务器网页的压力造成不必要的麻烦;
❷记录爬行网页的路径,以避免重复爬行。
❸有必要区分爬记录是否内部网页的网站,这是一个常见的一个。情况是,当你爬,你不知道在哪里爬。平均而言,大型网站将有成千上万的在每个页面的链接。如果你不爬边界,抓取页面的数量将成倍增加。这是我们不想要的;
❹尽管有许多链接看起来不同,他们实际上是相同的web页面。
1.2爬虫实现
爬虫原理
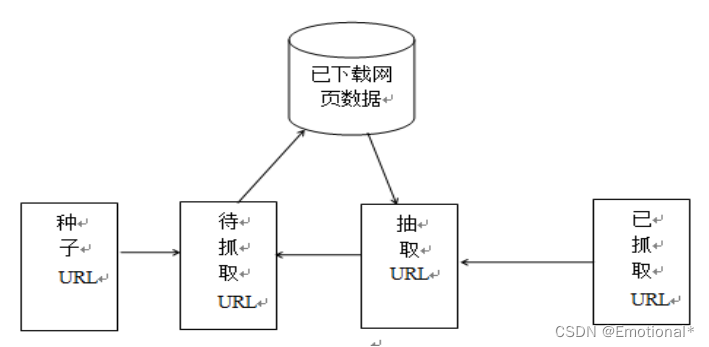
实现思路:本次设计方案主要使用request库爬取网页信息和beautifulSoup库来提取分类信息网站排行榜的信息。
1.2.1准备工作:
通常,我们在爬取一个站点之前,需要对该站点的规模和结构进行大致的了解。站点自身的robots.txt和sitemap文件都能够为我们了解其构成提供有效的帮助。
❶robots文件
一般情况下,大部分站点都会定义自己的robots文件,以便引导网络蜘蛛按照自己的意图爬取相关数据。
❷sitemap文件
站点提供的sitemap文件呈现了整个站点的组成结构。它能够帮爬虫根据用户的需求定位需要的内容,而无须爬取每一个页面。
❸估算站点规模
目标站点的大小会影响我们爬取的效率。通常可以通过百度搜索引擎的site关
键字过滤域名结果,从而获取百度爬虫对目标站点的统计信息。
1.2.2数据描述
数据来源:重庆主城九区二手房数据
数据获取:Python爬虫爬取网页获取数据
1.2.3使用工具
Python是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言,它拥有一个强大的基本类库和数据众多的第三方扩展
1.2.4数据获取步骤
第一步:从网页上获取HTML内容,编写相应的Python程序
第二步:分析网页内容并提取有用数据,采用列表存储重庆主城九区二手房的表单数据
第三步:将获取的数据写入CSV文件里
1.3数据保存
从文件中追加数据,保存到以“h1.csv”命名的文件夹里

打开h1.csv文件夹示例如下:


2.总 结
网上的任何东西都可以看成资源,一个网站可能就是一段html+css,一张图片可能就是某个地址下的XXX.jpg文件,无数的网络资源存放在互联网上,人们通过地址(URL,统一资源定位符)来访问这些资源,大致过程如下:
用户在浏览器中输入访问地址,浏览器向服务器发送HTTP(或者HTTPS)请求(其中请求资源常用get请求,提交数据常用post请求,post也可做数据请求)。服务器接收到了这些请求之后找到对应的资源返回给浏览器,再经过浏览器的解析,最终呈现在用户面前。
这就是用户上网的一个简单的过程。那么,如果我们需要大量的从网上请求数据,依靠人工一个个得机械操作显然是不现实的,这时候爬虫就起作用了。
一开始先要搞清楚什么是爬虫。其实本质上来说爬虫就是一段程序代码。任何程序语言都可以做爬虫,只是繁简程度不同而已。从定义上来说,爬虫就是模拟用户自动浏览并且保存网络数据的程序,当然,大部分的爬虫都是爬取网页信息(文本,图片,媒体流)。但是人家维护网站的人也不是傻的,大量的用户访问请求可以视为对服务器的攻击,这时候就要采取一些反爬机制来及时阻止人们的不知道是善意的还是恶意的大量访问请求。
附 录
爬虫获取数据代码如下:
import requests#请求,来访问网络,模拟浏览器
from bs4 import BeautifulSoup #对网站进行解析(机械码->代码)
import time#可以调用系统时间
import pandas as pd#数据分析与处理,保存数据
#from pymysql import times
#字典。下面的代码用来设置虚拟浏览器的
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}#虚拟浏览器
a=[]
def get_info(url):
wb_data = requests.get(url,headers=headers)#request包请求获取整个网页内容
soup = BeautifulSoup(wb_data.text,'lxml')#以文本形式解析成lxml形式
区域 = soup.select('body > div:nth-child(12) > div > div.position > dl:nth-child(2) > dd > div:nth-child(1) > div:nth-child(1) > a.selected')
标题 = soup.select('#content > div.leftContent > ul > li> div.info.clear > div.title > a')
面积= soup.select('#content > div.leftContent > ul > li> div.info.clear > div.address > div')
价格 = soup.select('#content > div.leftContent > ul > li > div.info.clear > div.priceInfo > div.totalPrice.totalPrice2 > span')
位置 = soup.select('#content > div.leftContent > ul > li> div.info.clear > div.flood > div > a:nth-child(3)')
for aer,in zip(区域):
region = {
'区域':aer.get_text().strip()
}
for title,zhandi,price,local, in zip(标题,面积,价格,位置):
str1 = zhandi.get_text().split('|')#分成几个字符串,split()函数为剪切函数
#print(str1)
if len(str1)==7:
data={
'标题': title.get_text().strip(),
'户型':str1[0].strip(),
'面积': str1[1].strip(),
'朝向': str1[2].strip(),
'装修程度': str1[3].strip(),
'楼层': str1[4].strip(),
'初始时间': str1[5].strip(),
'版型': str1[6].strip(),
'价格':price.get_text().strip(),
'位置':local.get_text().strip()
}
data.update(region)
a.append(data)
else:
data = {
'标题': title.get_text().strip(),
'户型': str1[0].strip(),
'面积': str1[1].strip(),
'朝向': str1[2].strip(),
'装修程度': str1[3].strip(),
'楼层': str1[4].strip(),
'版型': str1[5].strip(),
'价格': price.get_text().strip(),
'位置': local.get_text().strip()
}
data.update(region)
a.append(data)
if __name__=='__main__':#只有自己模块执行的时候才执行的代码(其他代码调用此模块是无法运行的)
aer=['jiangbei','yubei','beibei','jiulongpo','shapingba','nanan','banan','yuzhong','dadukou']
for i in range(len(aer)):
urls=['https://cq.lianjia.com/ershoufang/{}/pg{}/'.format(aer[i],str(j)) for j in range(2,10)]
for url in urls:
get_info(url)#自定义函数,传网页
time.sleep(2)#休眠2秒,避免反爬
df=pd.DataFrame(a,columns=['区域','标题','户型','面积','朝向','装修程度','楼层','初始时间','版型','价格','位置'])
print(a)
df.to_csv('h1.csv')
各部分代码运行示例:
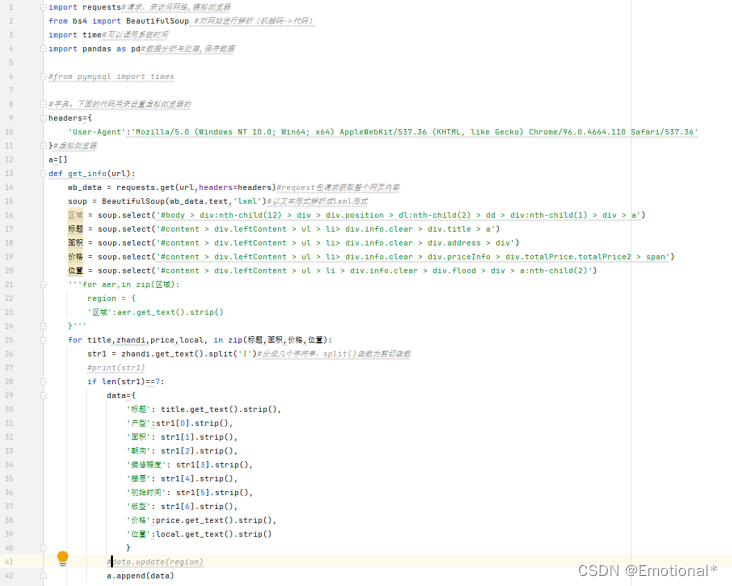
1.实现单个二手房页面的标题、面积、价格、位置的信息爬取(其中有户型、面积、朝向、装修程度、楼层、初始时间和版型的切割爬取)
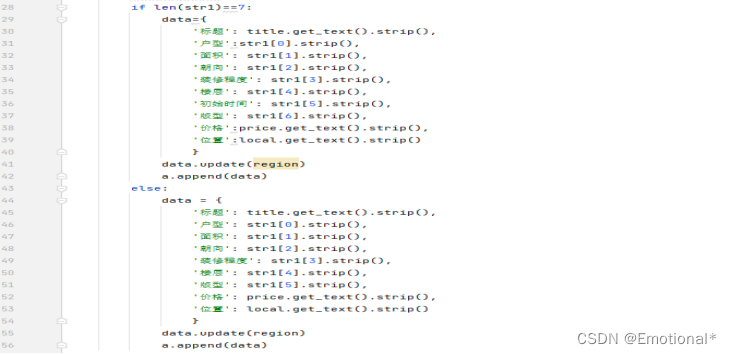
2.对部分初始时间的处理(有初始时间的则显示,无初始时间的则为空不显示)

3.将所爬取的信息存入以“h1.csv”命名的文件夹中,让其以表格的形式呈现出来


4.也就是最关键的一步,完成重庆九区的各个二手房页面的爬取,不再是单一页面或者其中一个

在合适位置添加上区域的相应代码,最终爬取会在“h1.csv”中显示,结果如下:


















 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









