







数据库相关概念:
DB: 数据库(database),存储数据的“仓库”,它保存了一系列有组织的数据。
DBMS: 数据库管理系统(database management system),数据库是通过DBMS创建和操作的容器。
SQL: 结构化查询语言(structure query language),专门用来与数据库通信的语言。
请记住,SQL语言对大小写不敏感,但是对关键字还是建议使用大写,分号是在数据库系统中分隔每条 SQL 语句的标准方法,这样就可以在对服务器的相同请求中执行一条以上的 SQL 语句。切记!!!
数据库存储数据的特点
- 将数据存到表中,表再放到库中。
- 一个数据库可以有多个表,每个表都有一个自己的名字,用来标识自己,表名具有唯一性。
- 表具有一些特性,这些特性定义了数据在表中如何存储,类似java类的设计。
- 表由列组成,也成为字段,所有表都是由一个或多个字段组成,类似java类中的属性。
- 表中数据都是按行存储的,每一行数据类似于java中的对象。
MYSQL服务启动与停止
- 通过 计算机管理->服务->找到MySQL选择启动(或停止)MySQL;
- 以管理员身份运行命令提示符,输入net start mysql启动MySQL,net stop mysql停止MySQL。
MySQL登录与退出
- 在win+r键输入cmd,在窗口中输入 mysql 【-h主机名 -p端口号,如果是本机就可以省略】-uroot -p你的密码 登录。
- 在窗口输入exit或ctrl+c退出。
MySQL常见命令
- 查看当前所有数据库:show databases;
- 打开指定的库:use 库名;
- 查看当前库的所有表:show tables;
- 查看其他库的所有表:show tables from 库名;
- 查看表结构:desc 表名;
- 查看MySQL服务器的版本: ①:登录到MySQL服务端,输入select version();没有登录就在windows服务端输入mysql -V;
DQL语言
DQL(Data QueryLanguage), 数据查询语言,关键字:SELECT 、FROM 、 WHERE。
语法格式:
SELECT 【查询列表】
FROM 【表名】;
注意:
- 查询列表可以是表中的字段,常量值,表达式,函数。
- 查询的结果是一个虚拟的表格
查询表中的多个字段 :
查询表中所有字段:
- 将表中所有字段罗列
查询列表的每个字段用逗号隔开。SELECT 【字段1,字段2,字段3...】 FROM 【表名】; - 用通配符【*】代替所有字段
SELECT * FROM 【表名】;
起别名:
有时候为了方便,以及要查询的字段由重名的情况,可以用别名来区分。在要起别名的字段、表等后面加上【AS 别名】;也可以不加AS直接空格+别名。
- 语法格式:
#加AS SELECT 字段 AS 【别名】 FROM 【表名】 AS 【别名】; #不加AS SELECT 字段 【别名】 FROM 【表名】 【别名】;
去重:
-
关键词 DISTINCT 用于返回唯一不同的值。DISTINCT 必须放在查询列表开头。
SELECT DISTINCT【查询列表】 FROM 【表名】;如表t_test
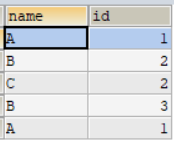
-
作用于单列:每个数据只出现一次;
SELECT DISTINCT name FROM t_test;结果如图,本来有2个‘B’,去重后只有一个’B‘;
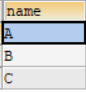
-
作用于多列:多列联合的数据只出现一次;
SELECT DISTINCT name,idFROM t_test;结果如图,只有name,id同时相等才能去重.
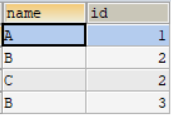
"+"号的作用:
SQL语言中的’+'只有运算符的作用!!!
- 如果’+'两边都为数值型:直接做加法运算;
- 如果’+'两边有一边不为数值型:会试图将其转换为数值型,成功则进行假发运算,否则将其转换为0再进行加法运算。
- 如果有一方为NULL,那么结果也为NULL。
条件查询:
如需有条件地从表中选取数据,可将 WHERE 子句添加到 SELECT 语句。
-
语法格式:
SELECT 查询列表 FROM 表名称 WHERE 筛选条件; -
分类:
-
按条件表达式筛选

再补充一个运算符 安全等于:<=>,既可以判断NULL值又可以判断普通数值,只是可读性较低. -
按逻辑表达式筛选
- 逻辑与:AND (两个条件都为真,结果才为真)
- 逻辑或:OR (两个结果只要有一个为真,则结果为真)
- 取反:NOT (条件本身为真,则结果为假,否则为真)
-
模糊查询
-
LIKE :一般与SQL通配符一起配合使用,常见的通配符有’%’(替代一个或多个字符,包含0个),’_’(仅替代一个字符);
- 举例说明:
#查询table 表中name中有'a'字符的 SELECT name FROM table name where LINK('%a%'); #查询table 表中name中第二个字符是'a'字符的 SELECT name FROM table name where LINK('_a%'); #查询table 表中name中最后一个字符是'a'字符的 SELECT name FROM table name where LINK('%a');
- 举例说明:
-
BETWEEN 【下限】AND【上限】
- 举例说明:
#查询table表中salary大于等于10000小于等于20000的员工信息 SELECT 员工信息 salary >= 10000 AND salary <= 20000; SELECT 员工信息 salary BETWEEN 10000 AND 20000; #两者完全等价 #这个是可行的 SELECT 员工信息 salary <= 20000 AND salary >= 10000; #这个是错误的 SELECT 员工信息 salary BETWEEN 20000 AND 10000;
- 举例说明:
-
IN:判断某一字段的值是否属于IN列表中的某一项
- 举例说明:
#找出student表中所有家乡(hometown)在湖北或河北或海南的学生 SELECT 学生信息 FROM student WHERE hometown IN('湖北','河北','海南');
- 举例说明:
-
IS NULL
=、<>、!=不能用于判断NULL值,而IS NULL 和 IS NOT NULL可以;- 举例说明:
#在员工表(employees)中查询奖金率(commission_pct)为NULL的员工的信息 SELECT * FROM employees WHERE commission_pct IS NULL; #在员工表(employees)中查询奖金率(commission_pct)不为NULL的员工的信息 SELECT * FROM employees WHERE commission_pct IS NOT NULL;
- 举例说明:
-
-
ORDER BY语句:
-
用于对结果集按照一个列或者多个列进行排序。默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,可以使用 DESC 关键字。
-
语法格式:
SELECT 【查询列表】 FROM 【表名】 WHERE 【筛选条件】#WHERE 子句不需要可以不加 ORDER BY 【排序列表】 【DESC 或者 ASC】 -
举例说明:
#将employees表按salary升序排列 SELECT * FROM employees ORDER BY salary ASC; #将employees表按salary降序排列 SELECT * FROM employees ORDER BY salary DESC; #将employees表按salary降序排列,如果salary相等的再按照年龄升序排序 SELECT * FROM employees ORDER BY salary DESC,age; -
注意事项:
①:ORDER BY 排列时,不写明ASC DESC的时候,默认是ASC。
②:DESC或者 ASC 只对它紧跟着的第一个列名有效,其他不受影响,仍然是默认的升序。
单行函数
-
字符函数
- LENGTH() :获取参数的字节个数;
- CONCAT():拼接字符,可变长参数;
语法格式:SELECT CONCAT('A','B','C');#ABC - UPPER():将字符改为大写;
语法格式:SELECT UPPER('abcd');#ABCD - LOWER():将字符改为小写;
SELECT LOWER('ABCD');#abcd - SUBSTR()或SUBSTRING():截取字符
语法格式:#索引从1开始 #截取指定索引后所有字符 SELECT SUBSTR('hello database',7);#database #截取从指定索引处开始到截取指定长度 SELECT SUBSTR('hello database',7,4);#data - INSTR(),获取字符第一次出现的索引
语法格式:SELECT INSTR('ABCABCD','BC');#2,索引是从1开始 - TRIM():去除前后空格,也可以去除指定;
语法格式:#去除前后空格 SELECT TRIM(' AB CD E ');#AB CD E #去除指定字符语法格式 SELECT TRIM(指定字符 FROM 目标字符); #去除前后'a'字符 SELECT TRIM('a' FROM 'aaabcdesfaaa');#bcdesf - LPAD():用指定的字符对目标字符实现指定长度的左填充
语法格式:SELECT LPAD(目标字符,长度,指定字符); #举例说明: SELECT LPAD('ABC',10,'*')# *******ABC - RPAD():用指定的字符对目标字符实现指定长度的右填充
语法格式:SELECT LPAD(目标字符,长度,指定字符); #举例说明: SELECT LPAD('ABC',10,'ab')# ABCabababa
注意:LPAD()和RPAD()如果目标字符的字符数>=指定长度,则不会填充;
- REPLACE():替换
语法格式:SELECT REPLACE(目标字符,要替换的字符,用来替换的字符); #举例说明: SELECT REPLACE('hello world','world','database');#hello database SELECT REPLACE('hello world','l','*');#he**o wor*d
-
数学函数
-
ROUND():四舍五入
语法格式:SELECT ROUND(1.49)#1 #第二个参数是保留几位小数 SELECT ROUND(1.357,2)#1.36 -
CEIL():向上取整,返回大于等于该参数的最小整数
语法格式:SELECT CEIL(1.001);#2 SELECT CEIL(1.000);#1 -
FLOOR():向下取整,返回小于等于该参数的最大整数
语法格式:SELECT FLOOR(0.999);# 0 SELECT FLOOR(2.000);# 2 -
TRUNCATE():截断指定位数
语法格式:SELECT TRUNCATE(1.9999,3);#1.999 SELECT TRUNCATE(1.99,5);#1.99000 -
MOD(a,b):取余,对应公式 a-a/b*b
语法格式:SELECT MOD(-10,3); #-1 SELECT MOD(-10,-3); #-1 SELECT MOD(-10,-3); # 1
-
-
日期函数
- NOW():返回当前系统日期及时间
语法格式:SELECT NOW(); # 年-月-日 时:分:秒 - CURDATE():返回当前系统日期,不包含时间
语法格式:SELECT CURDATE();# 年-月-日 - CURTIME():返回当前系统时间,不包括日期
语法格式:SELECT CURTIME();# 时:分:秒 - 获取指定部分的YEAR(年)、MONTH(月)、DAY(日)、HOUR(时)、MINUTE(分)、SECOND(秒)
语法格式:SELECT YEAR(NOW()); SELECT MONTH(NOW()); SELECT DAY(NOW()); SELECT HOUR(NOW()); SELECT MINUTE(NOW()); SELECT SECOND(NOW()); - STR_TO_DATE():将日期格式的字符转换为指定格式的日期

语法格式:
SELECT STR_TO_DATE('5-28-2021','%c-%d-%Y');# 2021-05-28- DATE_FORMAT():将日期转换成字符
SELECT DATE_FORMAT('2020/5/28','%Y年%c月%d日');# 2021年5月28日 #把‘%c/%d/%Y’格式转换成‘%Y年%c月%d日’ SELECT DATE_FORMAT(STR_TO_DATE('5/28/2021','%c/%d/%Y'),'%Y年%c月%d日');#- DATEDIFF(参数1,参数2):返回参数1-参数2的结果,以天数为单位,只考虑日期,不考虑时间;
语法格式:SELECT DATEDIFF('2021-01-10','2021-01-11');#-1 SELECT DATEDIFF('2021-01-12','2021-01-11');# 1
- NOW():返回当前系统日期及时间
-
流程控制函数
- IF(参数1,参数2,参数3),类似于if else 参数1为真返回参数2,否则返回参数3;
语法格式:SELECT IF(100>5,'真','假');#真 SELECT IF(100<5,'真','假');#假 - CASE(),类似switch语句
语法格式:#第一种: CASE 【要判断的字段或表达式】 WHEN 常量1 THEN 要显示的值1或表达式1 WHEN 常量2 THEN 要显示的值2或表达式2 ... ELSE 要显示的值或表达式 END #分数等级为A的是优秀,分数等级为B的是良好,其它的是待进步 SELECT name CASE level WHEN 'A' THEN '优秀' WHEN 'B‘ THEN '良好' ELSE '待进步' END FROM student;#第二种: CASE WHEN 表达式1 THEN 要显示的值1或表达式1 WHEN 表达式1 THEN 要显示的值2或表达式2 ... ELSE 要显示的值或表达式 END #如果员工工资>20000的是级别A,<=20000并且>15000的是级别B,<=15000并且>10000的是级别C,其它的是级别D; SELECT name CASE WHEN salary>20000 THEN 'A' WHEN salary>15000 THEN 'B' WHEN salary>10000 THEN 'C' ELSE 'D' END FROM employees;
- IF(参数1,参数2,参数3),类似于if else 参数1为真返回参数2,否则返回参数3;
-
其他函数
- SELECT VERSION():查看当前MySQL服务器版本
- SELECT DATEBASE():查看当前所在库
- SELECT USER():查看当前用户
分组函数
用作统计使用,又称聚合函数、组函数。
为了后续翻阅,column_name 代表列名、字段;table_name 代表表名;aggregate_function 代表分组函数、聚合函数;
- MAX():返回指定列的最大值。
语法格式:SELECT AVG(column_name) FROM table_name; #查询员工中最高的工资 SELECT MAX(salary) FROM employees; - MIN():返回指定列的最小值.
语法格式:SELECT MIN(column_name) FROM table_name; #查询员工中最低的工资 SELECT MIN(salary) FROM employees; - AVG():返回数值列的平均值.
语法格式:SELECT AVG(column_name) FROM table_name; #查询员工的平均工资 SELECT AVG(salary) FROM employees; - SUN():返回数值列的总数。
SELECT SUM(column_name) FROM table_name; #查询所有员工的工资总和 SELECT SUM(salary) FROM employees; - COUNT():返回匹配指定条件的行数。
语法格式:#COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入): SELECT COUNT(column_name) FROM table_name; #COUNT(*) 函数返回表中的记录数 SELECT COUNT(*) FROM table_name; #COUNT(DISTINCT column_name) 函数返回指定列的不同值的数目: SELECT COUNT(DISTINCT column_name) FROM table_name;
注意事项:
①:SUM(),AVG()一般用于处理数值型;MAX(),MIN(),COUNT()可以处理任何类型。
②:这五个分组函数都忽略NULL值。
③: 和分组函数一起查询的字段要是GROUP BY 后的字段。
GROUP BY语句:
GROUP BY 语句用于结合聚合函数(分组函数),根据一个或多个列对结果集进行分组。
语法格式:
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE 筛选条件
GROUP BY column_name
HAVING 分组后筛选条件;
#求各部门平均工资(department_id:部门编号,salary:工资)
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id;
#求各部门男性平均工资(department_id:部门编号,salary:工资,gender:性别,men:男性)
SELECT department_id, AVG(salary)
FROM employees
WHERE gender = men
GROUP BY department_id;
#查询各部门男性平均工资大于10000的部门编号(department_id:部门编号,salary:工资,gender:性别,men:男性)
SELECT department_id, AVG(salary) avg_sal
FROM employees
WHERE gender = men
GROUP BY department_id
HAVING avg_sal > 10000;
按多个字段分组
SELECT column_name1,column_name2, aggregate_function(column_name)
FROM table_name
WHERE 筛选条件
GROUP BY column_name1,column_name2...#(不分前后顺序)
HAVING 分组后筛选条件;
ORDER BY 排序列表
#查询每个部门每个职位的平均工资(department_id:部门编号 ,job_id:职位编号 salary:工资)
SELECT department_id,job_id,AVG(salary)
FROM employees
GROUP BY department_id,job_id;
#还可以对各部门各职位的平均工资进行排序
SELECT department_id,job_id,AVG(salary) avg_sal
FROM employees
GROUP BY department_id,job_id
ORDER BY avg_sal DESC;
注意事项:
①:分组前筛选以原始表为数据源通过WHERE关键字进行筛选;
②:分组后筛选以分组后的结果集为数据源通过HAVING关键字进行筛选;
③:能分组前就筛选的就优先考虑使用WHERE筛选;
连接查询
又称多表查询,当查询的数据来自于多个表时,就会用到多表查询;如果多表查询时,没有有效的连接条件,就会出现笛卡尔乘积现象(假如A表有n条数据,B表有m条数据,连接查询后会出现n*m条数据)。
分类:
-
按语法年代进行分类:
-
SQL92:
优点:
条件和表连接写在一处方便简洁;
多表连接操作简单缺点:
条件和连接混合,易读性较差
连接条件支持有限,不支持左连接右连接等高级操作 -
SQL99:
优点:
功能强大,左右连接外连接等强力支持
条件连接分开,易读性好缺点:
多表连接时需要仔细选择表顺序和连接条件
连接语句很长,书写麻烦
-
-
按功能分类:
-
内连接:关键字INNER可以省略不写;
-
等值连接
#SQL92语法: SELECT 查询列表 FROM 表1,表2... WHERE 连接条件; #SQL99语法: SELECT 查询列表 FROM 表1 INNER JOIN 表2 ON 连接条件 WHERE 筛选条件;举例说明:查询每个员工的姓名和部门名
(name:员工姓名,department_name:部门名,employees(起别名 e) :存放员工数据的表,departments(起别名 d) :存放部门数据的表)
注意:如果为表起了别名,那么查询的字段就不能使用原来的表名去限定。#SQL92: SELECT e.name,d.department_name FROM employees e,departments d #表的顺序可以调换,2个以上的表也可以 WHERE e.department_id = d.department_id ; #SQL99: SELECT e.name,d.department_name FROM employees e INNER JOIN departments d ON e.department_id = d.department_id ; -
非等值连接
与等值连接的区别就是将表的连接条件由等值变成了非等值;
举例说明:查询员工(employees)的工资(salary)对应工资等级表(sal_level)的等级(level)。假设在sal_level表中lower表示这个等级的工资下限,upper表示这个等级的工资上限。#SQL92: SELECT s.level FROM employees e,sal_level s WHERE e.salary BETWEEN lower AND upper; #SQL99: SELECT s.level FROM employees e INNER JOIN sal_level s ON e.salary BETWEEN lower AND upper; -
自连接
自连接可以将自身表的一个镜像当作另一个表来对待,从而能够得到一些特殊的数据。
语法格式:SELECT 查询列表 FROM 表1 起别名(a) INNER JOIN 表1 起别名(b) ON 连接条件;举例说明:查询所有领导的姓名,每一个员工都有一个领导,除了顶级boss其余领导也是员工,employee_id :员工编号 ,manager_id领导编号同时也是员工编号。
SELECT DISTINCT e.name FROM employees e inner join employees m on e.employee_id = m.manager_id;
-
-
外连接: 关键字OUTER可以省略不写;外连接的查询结果为主表中的所有记录,如果从表中有和它匹配的,则显示那个值,否则显示NULL;外连接显示结果=内连接显示结果+主表中有而从表中没有的记录。
-
左外连接: 关键字是OUTER LEFT JOIN,关键字前面的表是主表,后面的表是从表。
语法格式:SELECT 查询列表 FROM 主表 LEFT OUTER JOIN 从表 ON 连接条件如图表一是woman_table表,表二是man_table表,bor_friend_id男朋友id,girl_friend_id女朋友id。
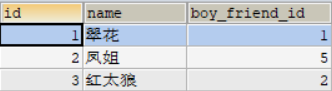
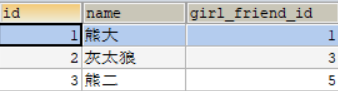
举例说明:查询女性的男朋友姓名;
SELECT w.name,m.name 男朋友 FROM woman_table w LEFT OUTER JOIN man_table m ON w.boy_friend_id = m.id;结果如图所示:

左外连接查询结果集示意图:

-
**右外连接:**关键字是OUTER RIGHTJOIN,关键字前面的表是从表,后面的表是主表。
语法格式:SELECT 查询列表 FROM 从表 RIGHT OUTER JOIN 主表 ON 连接条件举例说明:查询男性的女朋友姓名(还使用上图的woman_table和man_table);
SELECT m.name,w.name 女朋友 FROM woman_table w RIGHT OUTER JOIN man_table m ON w.boy_friend_id = m.id;结果如图:

右外连接查询结果集示意图:

-
**全外连接:**FULL OUTER JOIN 关键字只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行,结合了 LEFT JOIN 和 RIGHT JOIN 的结果。
语法格式:SELECT 查询列表 FROM 表1 FULL OUTER JOIN 表2 ON 连接条件MySQL不支持全外连接,这里就不进行举例说明了。
-
-
交叉连接:
仅仅只是用来显示笛卡尔乘积现象,没什么用。
语法格式:SELECT 查询列表 FROM 表1 CROSS OUTER JOIN 表2;
-
子查询
出现在其他语句中的SELECT语句称为子查询或者内查询;内部嵌套其他SELECT查询语句的称为外查询或者主查询。
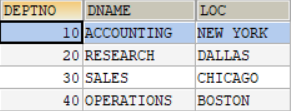
为了后续举例说明,假设有表salgrade如图1所示,表employees如图2所示,表departments如图3所示:
图1
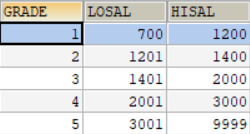
图2

图3
分类:
- 按子查询出现的位置:
-
SELECT 后面(只支持标量子查询)
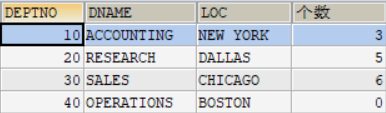
举例说明:查询每个部门的员工人数和部门信息SELECT d.*( SELECT COUNT(*) FROM employees e WHERE e.DEPTNO = d.DEPTNO ) 个数 FROM departments d ;结果如图所示:
-
FROM 后面(一般是表子查询,当作临时表使用)
举例说明:查询每个部门的平均工资的工资等级SELECT t.deptno,t.avg_sal,s.grade FROM ( SELECT AVG(sal) avg_sal,deptno FROM emp GROUP BY deptno) t LEFT OUTER JOIN salgrade s ON t.avg_sal BETWEEN s.losal AND hisal;结果如图所示:
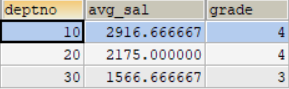
-
WHERE 后面 或者 HAVING 后面(支持标量子查询,列子查询,行子查询)
特点:
①:一般放在小括号内;
②:一般放在条件右侧;
③:标量子查询一般搭配单行操作符使用;(>,<,=,<>,!=,<=,>=)
④:列子查询一般配合多行操作符使用(IN,SOME,ANY,ALL)

举例说明:
1、 查询工资(sal)比SCOTT高的员工信息SELECT * FROM employees WHERE sal>( SELECT sal FROM employees WHERE ename='SCOTT' );结果如图所示:

-
EXISTS 后面(相关子查询,一般是表子查询)
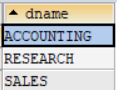
举例说明:查询有员工的部门名;SELECT dname FROM departments d WHERE EXISTS ( SELECT deptno FROM employees e WHERE e.deptno = d.deptno );查询结果如图所示:
-
- 按结果集的行列数不同:
- 标量子查询(又称单行子查询,结果集只有一行一列)
- 列子查询(又称多行子查询,结果集是一列多行)
- 行子查询(结果集是一行多列)
- 表子查询(结果集一般为多行多列)
分页查询
当我们需要查询结果集进行分页显示的时候就会使用到分页查询了,关键字是LIMIT offset,size;索引是从0开始,其中offset是要显示条目的起始索引,size是要显示的条目数,缺省offset表示查询结果集的前size条数据。LIMIT语句是放在查询语句的最后,
语法格式:
SELECT 查询列表
FROM 表名
LIMIT 起始索引,显示条目数;
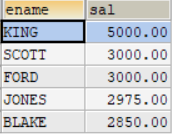
举例说明:查询工资最高的前5名员工
SELECT ename,sal
FROM employees
ORDER BY sal DESC
LIMIT 0,5;
查询结果如图所示:
联合查询
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型(可以隐式转型)。同时,每个 SELECT 语句中的列的顺序必须相同。
语法格式:
SELECT语句1
UNION
SELECT语句2
举例说明:查询工资等级是1或者没有上级的员工信息;
(#查询工资等级是1的员工
SELECT ENAME
FROM employees
INNER JOIN (
#查询工资等级是1的LOSAL和HISAL
SELECT LOSAL,HISAL
FROM salgrade
WHERE GRADE=1
) t
ON sal BETWEEN t.LOSAL AND t.HISAL)
UNION
(#查询没有上级的员工
SELECT ENAME
FROM employees
WHERE MGRIS IS NULL
);
UNION 和 UNION ALL的区别:
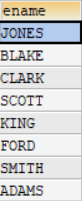
#查询工资在2000以上或者部门编号是20的员工信息
#UNION
SELECT ename FROM employees WHERE sal > 2000
UNION
SELECT ename FROM employees WHERE DEPTNO = 20;
#UNION ALL
SELECT ename FROM employees WHERE sal > 2000
UNION ALL
SELECT ename FROM employees WHERE DEPTNO = 20;
UNION查询结果如图所示:
UNION ALL查询结果如图所示:
可以看出,UNION是默认去重的,而UNION ALL可以包含重复项。
DML语言:
DML(Data Manipulation Language),数据操纵语言,在SQL语言中,负责对数据库对象运行数据访问工作的指令集,以INSERT、UPDATE、DELETE三种指令为核心,分别代表插入、更新与删除。
- INSERT INTO
用于向表中插入新记录。
语法格式:
方式一支持多行插入方式二不支持,方式一支持子查询,方式二不支持;#方式1: #需要指定列名和被插入的值(列可以调换顺序,但是要和值一一对应) INSERT INTO 表名(列名1...) VALUES(值1...); #插入多行,每个VALUES()以逗号隔开 INSERT INTO 表名(列名1...) VALUES(值1...),VALUES(值1...)...; #无需指定要插入数据的列名,只需提供被插入的值即可(默认所有列,而且顺序要和表中列的顺序一致): INSERT INTO 表名 VALUES(值1...); #插入多行,每个VALUES()以逗号隔开 INSERT INTO 表名 VALUES(值1...),VALUES(值1...)...; #方式2: INSERT INTO 表名 SET 列名=值,列名=值... - UPDATE
- 修改单表
语法格式:UPDATE 表名 SET 列名=值,列名=值,... WHERE 筛选条件; - 修改多表
语法格式:UPDATE 表1 连接类型【INNER,LEFT OUTER,RIGHT OUTER】 JOIN 表2 ON 连接条件 SET 列名=值,列名=值,...
- DELETE
单表删除:
语法格式:
多表删除:DELETE FROM 表名 WHERE 筛选条件;
语法格式:
举例说明:(以上面的工资等级表(salgrade)和员工表(employees),删除工资等级为1的员工信息)DELETE 表名(要删除那个表的就写那个,也可以写多个) FROM 表1 连接类型【INNER,LEFT OUTER,RIGHT OUTER】 JOIN 表2 ON 连接条件 WHERE 筛选条件;
TRUNCATE语句DELETE e FROM employees e INNER JOIN salgrade s ON e.`SAL` BETWEEN s.`LOSAL` AND s.`HISAL` WHERE s.`GRADE`=1;
语法格式:TRUNCATE TABLE 表名;
DELETE和TRUNCATE区别:
- DELETE可以加WHERE语句,TRUNCATE不能;
- 如果要删除的表中有自增长列,用DELETE删除,再插入数据,自增长列的值从断电开始,而用TRUNCATE删除后再插入数据,自增长列的值是从1开始。
- DELETE删除有返回值,TRUNCATE删除,没有返回值。
- TRUNCATE删除不能回滚,而DELETE删除可以回滚。
DDL语言
DDL(Data Definition Language),数据定义语言,用于库和表的管理。
- 库的创建
语法格式:
#如果要创建的库名已存在,会报错
CREATE DATABASE 库名;
#如果没有这个库就创建,有就不创建,容错率高,建议使用
CREATE DATABASE IF NOT EXISTS 库名;
-
库的修改
-
修改库名
注意:这条语句已经废弃,因为不安全,可能造成数据丢失。如果真的要改关闭DBMS后直接在DBMS的文件夹下找的要修改的库(文件夹),重命名即可。RENAME DATABASE 库名 TO 新库名; -
更改库的字符集
ALTER DATABASE 库名 CHARACTER SET 字符集;
-
-
库的删除
语法格式:
#如果没有这个库会报错
DROP DATABASE 库名;
#如果存在才删除,这种写法容错率更高,建议使用。
DROP DATABASE IF EXISTS 库名;
后面创建表格需要用到数据类型,常见的SQL数据类型如图所示:
SQL数据类型:

注意(小细节):
- CHAR保存固定长度的字符串(可包含字母、数字以及特殊字符),不指定大小默认为1,VARCHAR和它的区别是VARCHAR是可变长的,且值如果大于255会转换成TEXT类型,必须指定最大字符长度;
- 数值类型是可以指定显示长度的,但对于存储空间都是一样的,如INT(3),INT(5),INT(9)都是占用4byte的存储空间.
- 对于数值类型如果不设置是无符号还是有符号,默认是有符号,设置无符号关键字是UNSIGNED;
- 对于整形,插入数据时如果超出了整形范围会报异常,并且插入临界值;
- 对于小数类型,指定(M,D),其中M是小数点前后一共显示的位数,D是小数点后的位数,如果插入的数小数点前的位数<=(M-D),小数点后不足D位就补领,否则四舍五入;如果这个数小数点前的位数>(M-D)报异常,超出范围;
- TIMESTAMP支持的范围较小,DATETIME范围较大(上面表格有具体范围);TIMESTAMP和实际时区有关,而DATETIME只能反映处插入时当地时区;
- 表的创建
语法格式:
CREATE TABLE 表名(
列名 类型,
列名 类型,
列名 类型,
....
);
- **表的修改:**核心语法时ALTER TABLE 表名…
- 修改表名
语法格式:ALTER TABLE 表名 RENAME TO 新表名; - 修改列名
在对列名进行修改时必须带上类型,也就是还可以修改类型。
语法格式 :#COLUMN可以省略 ALTER TABLE 表名 CHANGE COLUMN 旧列名 新列名 类型; - 修改列的类型
语法格式:ALTER TABLE 表名 MODIFY COLUMN 列名 新类型; - 添加新列
语法格式:ALTER TABLE 表名 ADD COLUMN 列名 类型; - 删除列
语法格式:ALTER TABLE 表名 DROP COLUMN 列名;
- 修改表名
还有对列的约束的修改放在约束的知识点讲解。
-
表的复制
- 只复制表的结构
语法格式:CREATE TABLE 表名 LIKE 表名【已存在的表】 - 复制表结构加数据
语法格式:CREATE TABLE 表名 SELECT语句;
#只复制部分结构及数据 CREATE TABLE 表名 SELECT语句【查询列表是要复制的列,不要数据就让筛选条件恒不成立,如1=2】; - 只复制表的结构
-
表的删除
语法格式:DROP TABLE 表名; #还是建议下面这种写法 DROP TABLE IF EXUSTS 表名;
约束
- NOT NULL:非空约束,强制列不接受 NULL 值,约束强制字段始终包含值。这意味着,如果不向字段添加值,就无法插入新记录或者更新记录。
- UNIQUE:唯一性约束,约束唯一标识数据库表中的每条记录,具有UNIQUE约束的列的值在这一列具有唯一性。
- PRIMARY KEY:主键约束,有自定义的UNIQUE和NOT NULL约束,并且每个表只有一个主键.
- FOREIGN KEY:外键约束,指向另一个表中的 UNIQUE(唯一约束的键)。
- CHECK:检查约束,用于限制列中的值的范围,如果对一个表定义 CHECK 约束,那么此约束会基于行中其他列的值在特定的列中对值进行限制。MySQL不支持。
- DEFAULT:约束用于向列中插入默认值。如果没有规定其他的值,那么会将默认值添加到所有的新记录。
- 列级约束:
-
创建表时添加列级约束:
语法格式:CREATE TABLE IF NOT EXISTS 表名( 列名 类型 约束, 列名 类型 约束, 列名 类型 约束 );举例说明:创建有students表,如下要求,ID列作为表的标识列,NAME不能为空,如果没有爱好(HOBBY),就默认是读书,姓名只能是男和女,年龄(age)只能是>10&&<16;
CREATE TABLE IF NOT EXISTS students( id INT(10) PRIMARY KEY,#主键约束 NAME VARCHAR(20) NOT NULL,#非空约束 hobby VARCHAR(255) DEFAULT '读书',#默认约束 gender CHAR(1) CHECK(gender='男' OR gender='女'), #检查约束 age INT CHECK(age>10 AND age<16) );
- 表级约束
表级约束不支持非空约束和默认约束。- 在创建表时添加表级约束:
语法:
举例说明:CREATE TABLE IF NOT EXISTS 表名( 列名 类型, 列名 类型, 列名 类型, CONSTRAINT 约束名 约束类型(列名),#CONSTRAINT,约束名可以省略 CONSTRAINT 约束名 约束类型(列名), ... );
设计表,有字段emp_id 员工表的主键,dept_id 部门表的主键,员工表的外键,建表时要先建部门表。
联合主键:CREATE TABLE IF NOT EXISTS employees( emp_id INT(10), job VARCHAR(20), name VARCHAR(20), gender CHAR(1), sal DOUBLE(7,2), dept_id INT, CONSTRAINT PK PRIMARY KEY(emp_id),#主键,在MySQL中主键的约束名无法修改 CONSTRAINT fk_employees_departments FOREIGN KEY(dept_id) REFERENCES departments(id)#外键,约束名一般包含两张表的表名 #如下写法也可以 # PRIMARY KEY(emp_id), # FOREIGN KEY(dept_id) REFERENCES departments(id) );
就是当作为主键的字段可能存在重复值,无法确定这条数据的唯一性时,再加上一个字段,两个字段联合起来确定这条数据的唯一性。
语法格式:PRIMARY KEY(字段1,字段2)
- 在创建表时添加表级约束:
主键和唯一键的区别:
- 主键一张表中只有一个,而唯一键可以有多个;
- 主键不允许为NULL,唯一键可以为NULL;
- 两者都可以组合,但不推荐
- 两者都保证唯一性
注意:
创建a表时需要b表的字段1作为a表的外键列,那么b就是主表,a就是从表;而且主表必须先存在,删除时要先删除从表才能删主表。
外键的特点:
- 从表的外键列的类型和主表的关联列的类型要求一致或兼容;
- 主表的关联列必须是键,一般是唯一键或者主键;
- 插入数据时,先插入主表再插入从表,删除数据时,先删除从表再删除主表;
修改表时添加约束:
列级约束语法:
ALTER TABLE 表名 MODIFY COLUMN 列名 类型 约束类型;
表级约束写法:
ALTER TABLE 表名 ADD 约束类型(列名);
因为MySQL不支持检查约束,所有下面就不写了。
1. 添加非空约束
ALTER TABLE 表名 MODIFY COLUMN 列名 类型 NOT NULL;
2. 添加默认约束
ALTER TABLE 表名 MODIFY COLUMN 列名 类型 DEFAULT 值;
3. 添加主键
#方式一:列级约束的写法
ALTER TABLE 表名 MODIFY COLUMN 列名 类型 PRIMARY KEY;
#方式二:表级约束的写法
ALTER TABLE 表名 ADD PRIMARY KEY(列名);
4. 添加唯一约束
#方式一:列级约束的写法
ALTER TABLE 表名 MODIFY COLUMN 列名 类型 UNIQUE;
#方式二:表级约束的写法
ALTER TABLE 表名 ADD UNIQUE(列名);
5.添加外键
#列级约束不支持外键就不写了
ALTER TABLE 表名 ADD FOREIGN KEY(外键列列名) REFERENCES 主表(联合列列名);
修改表时删除约束:
1.删除非空约束
ALTER TABLE 表名 MODIFY COLUMN 列名 类型;
2.删除默认约束
ALTER TABLE 表名 MODIFY COLUMN 列名 类型;
3.删除唯一约束
ALTER TABLE 表名 DROP UNIQUE 键名;
4.删除主键
ALTER TABLE 表名 DROP PRIMARY KEY;
5.删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 键名;
标识列(自增长列)
在插入数据时,不需要用户自己插入值,系统提供默认的序列值.关键字时AUTO _INCREMENT。
特点:
①:要求自增长列是一共key;
②:一个表至多只有一个标识列;
③:标识列的类型只能是数值型;
④:可以通过【SET AUTO_INCREMENT_INCREMENT=值】来设置步长;也可以通过手动插入值来设置起始值;
-
创建表时设置标识列;
语法格式:CREATE TABLE 表名( 列名 类型 约束 AUTO_INCREMENT, ... ); -
修改表是设置标识列:
1.设置标识列 ALTER TABLE 表名 MODIFY COLUMN 列名 类型 约束 AUTO_INCREMENT;#约束看需求添加与否 2.删除标识列 ALTER TABLE 表名 MODIFY COLUMN 列名 类型 约束;
TCL语言
TCL(Transaction Concrol Language),事务控制语言。
事务
由一条或一组SQL语句组成一个执行单元;
特点(ACID):
- 原子性(atomicity),一个事务是一个不可分割的工作单位,事务中的操作要么都执行,要么都不执行。
- 一致性(consistency),事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
- 隔离性(isolation),一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持久性(durability),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
事务的创建:
隐式事务:事务没有明显的开启和结束的标记。例如DELETE,INSERT,UPDATA语句。
显示事务:事务具有明显的开启和结束的标记。
- 将事务自动提交功能禁用;
- 开启事务
- 执行成功提交事务,失败回滚事务;
语法格式:
SET AUTOCIMMIT=0;#关闭自动提交功能
START TRANSACTION;#开启事务,可以不写,关闭自动提交功能后默认开启事务
SQL语句;#执行事务中的SQL语句
成功提交事务:COMMIT;
失败回滚事务:ROLLBACK;
事务并发问题:
- 脏读:对于两个事务A和B,事务A读取了事务B更新了但是还没有提交的数据,之后,若B回滚,那么A读取的就是无效的。
- 不可重复读:对于两个事务A和B,事务A读取了一条记录,然后B更新了该条记录,之后,A再去读取这条记录,但是值却不一样了。
- 幻读:对于两个事务A和B,A先从表中读取了多条记录,然后B在这个表中插入了Y条记录,当A再次以同样条件在这个表中读取数据时,却比上次读取多出了几条记录。
事务隔离级别:事务与事务隔离的程度称为隔离级别。
- READ UNCOMMITTED(读未提交),允许事务读取未被其他事务提交的数据,脏读,不可重复读,幻读的问题都可能会出现。
- READ COMMITTED(读已提交),只允许事务读取被其他事务提交的数据,但是不可重复的和幻读问题仍可能出现。
- REPEATABLE READ(可重复读),确保事务可以在一个字段读取相同的值,在这个事务持续期间,禁止其他事务对这个字段进行更新,可以避免脏读和不可重复读问题,当时幻读问题还是可能出现。
- SERIALIZABLE(串行化),确保一个事务可以从一个表中读取相同的行,在这个事务进行期间,禁止其他事务对该表进行增删改等操作,所有并发问题都可避免,但是性能较低。
查看当前隔离级别:
SELECT @@tx_isolation;
设置隔离级别:
SET SESSION(或GLOBAL) TRANSACTION ISOLATION LEVEL 隔离级别;
回滚点SAVEPOINT和ROLLBACK TO:
事务执行失败可以回滚到回滚点;
SET AUTOCOMMIT=0;
SQL语句 1;
SAVEPOINT a;
SQL语句 2;
ROLLBACK TO a;
如果事务执行失败,可以回滚到回滚点a处,SQL语句1造成的后果不可回滚,SQL语句2可以回滚;
视图
视图是基于 SQL 语句的结果集的可视化的表。视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。只保存SQL逻辑,不保存查询结果 。一般用于会在多个地方用到同样的查询结果,或者该查询结果使用的SQL语句较复杂。
创建视图语法:
#方式一:
CREATE VIEW 视图名 AS 查询语句;
#方式二:
CREATE OR REPLACE VIEW 视图名
AS
查询语句;
修改视图语法:
#方式一:这个视图没有就创建,有就修改
CREATE OR REPLACE VIEW 视图名
AS
查询语句;
#方式二:
ALTER VIEW 视图名
查询语句;
删除视图语法:
#可以连续删除多个视图
DROP VIEW 视图名1,视图名...;
查看视图:
#查看视图的结构
DESC 视图名;
#查看创建视图的逻辑
SHOW CREATE VIEW 视图名;
视图更新:
视图的增删改与表的语法一致;
具有一下任一特点的视图不允许更新:
- 创建视图的SQL语句中包含一下关键字:分组函数,DISTINEC,GROUP BY,HAVING,UNION ,UNION ALL;
- 创建视图的查询结果是连接查询的结果;
- FROM后是一个不可更新的视图;
- 常量视图;
- SELETE语句中包含子查询;
- WHERE 子句中的子查询引用了FROM后的表;
变量
-
系统变量:有系统提供的,服务器层面的;根据其作用域分为全局变量和会话变量;
- 全局变量:服务器每次启动将为所有的全局变量赋初始值,针对于所有会话(连接)有效,但是不能跨重启。如果要想每次启动也修改,则需要修改配置文件。
- 会话变量:仅仅针对于当前会话(连接)有效,并且有默认值。
查看所有的系统变量:
#查看所有全局变量 SHOW GLOBAL VARIABLES; #查看所有会话变量,SESSION可以省略 SHOW SESSION VARIABLES;查看符合条件的系统变量:
#LIKE 后就是模糊查询用法一致 SHOW GLOBAL(或SESSION) VARIABLES LIKE '%%';查看指定的系统变量的值:
SELECT @@系统变量名 #查看指定的全局变量 SELECT @@GOLBAL.系统变量名 #查看指定的会话变量,【SESSION.】可以省略 SELECT @@SESSION.系统变量名为系统变量赋值:
#为全局变量赋值 SELECT @@GOLBAL.系统变量名=值; #为会话变量赋值,【SESSION.】可以省略 SELECT @@SESSION.系统变量名=值;
注意:
如果是全局级别,则需要加global,如果是会话级别,则需要加session,如果不写,则默认session。
- 自定义变量:用户自定义的,不是系统提供的;
-
局部变量:针对于当前会话(连接)有效,同于会话变量的作用域,应用在任何地方,也就是begin end里面或begin end外边。
声明:DECLARE 变量名 类型 ; DECLARE 变量名 类型 DEFAULT 值;更新:
SET 变量名=值; SET 变量名:=值; SELECT @局部变量名:=值; #查询结果只能是一行一列 SELECT 字段 INTO 变量名 FROM 表名; -
用户变量:仅仅在定义它的begin end中有效,应用在begin end中的第一句话。
声明并初始化:SET @用户变量名=值; SET @用户变量名:=值; SELECT @用户变量名:=值;更新用户变量的值:
SET @用户变量名=值; SET @用户变量名:=值; SELECT @用户变量名:=值; #查询结果只能是一行一列 SELECT 字段 INTO 变量名 FROM 表名;
-
存储过程
存储过程,是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,它存储在数据库中,一次编译后永久有效,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象。在数据量特别庞大的情况下利用存储过程能达到倍速的效率提升。
创建语法:
#设置存储过程结束标记,一次连接设置一次即可
DELIMITER 符号
#创建存储过程
CREATE PROCEDURE 存储过程名(参数列表)
BEGIN
SQL 语句集
END 结束标记符
#一个参数由参数模式,参数名,参数类型组成,如果SQL 语句集只有一条语句,那么BEGIN END可以省略,且每天SQL语句后都要以分号结尾
参数模式:
IN: 其对应的参数可以作为输入,也就是该参数需要调用方传入值;
OUT : 其对应的参数可以作为出,也就是该参数可以作为返回值;
INOUT : 其对应的参数既可以作为输入又可以作为输出,也就是该参数既要传入值,也可以返回值;
调用语法:
#参数可以是定义的变量也可以是常量
CALL 存储过程名 (参数列表);
举例说明:
-
有user(username【INT】,password【VARCHAR】)表,根据用户输入的username,password判断登录成功与否;
#设置存储过程结束符 DELIMITER $ #创建存储过程 CREATE PROCEDURE myp(IN username INT,IN `password` VARCHAR(20),OUT result CHAR(2)) BEGIN #定义变量 DECLARE num INT DEFAULT 0; #如果要返回多个变量,就是 【字段1,字段2... INTO 变量1,变量2...】 SELECT COUNT(*) INTO num FROM user WHERE user.username=username AND user.password=password; SET result:=IF(num=1,'成功','失败'); END $ #调用存储过程 CALL myp1(username ,'password',@result)$ SELECT @result $ -
输入两个数交换并且放回
#设置存储过程结束符 DELIMITER $ #创建存储过程 CREATE PROCEDURE myp(INOUT a INT,INOUT b INT) BEGIN #定义变量 DECLARE temp INT DEFAULT a; SET a:=b; SET b:=temp; END $ #调用存储过程 SET @a:=10$ SET @b:=20$ CALL myp(@a,@b)$ SELECT @a,@b $
删除存储过程:
#不能像视图一样连续删除
DROP PROCEDURE 存储过程名;
查看存储过程信息:
SHOW CREATE PROCEDURE 存储过程名;
函数
一组预先编译好的SQL语句的集合,可以理解成批处理语句;
- 提高了代码的复用性;
- 简化操作;
- 减少了编译次数并且减少了和数据库服务器的连接次数,提高了效率;
存储过程与函数的区别:
存储过程可以有0个及以上返回值,而函数必须且只能有一个返回值.
创建语法:
DELIMITER 结束标记符
CREATE FUNCTION 函数名(参数列表) RETURNS 返回类型
BEGIN
SQL语句集;
END 结束标记符
#参数包含参数名和参数类型
调用语法:
SELECT 函数名(参数列表);
举例说明:
员工表(employees)有字段工资(salary,DOUBLE),姓名(name,VARCHAR(20))具有唯一性。
- 查询公司有多少员工;员工表(employees)
#设置结束标志符
DELIMITER $
#创建函数
CREATE FUNCTION getNumber() RETURNS INT
BEGIN
DECLARE num INT DEFAULT 0;
SELECT COUNT(*) INTO num
FROM employees;
RETURN num;
END $
#调用函数
SELECT getNumber();
- 根据给的员工姓名,返回其工资
#设置结束标志符
DELIMITER $
#创建函数
CREATE FUNCTION getSalary(name VARCHAR(20)) RETURNS DOUBLE
BEGIN
DECLARE sal DOUBLE;
SELECT salary INTO sal
FROM employees e
WHERE e.name=name;
RETURN sal;
END $
#调用函数,查找张三的工资
SELECT getSalary('张三');
函数的查看:
SELECT CREATE FUNCTION 函数名;
函数的删除:
DROP FUNCTION 函数名;
分支结构
语法:
IF 条件1 THEN 语句1;
ELSEIF 条件2 THEN 语句2;
...
ELSE 语句;
END IF;
举例说明:
1. 根据分数返回对应的等级(90~100->A,70 ~ 89->B,60 ~ 69 ->C,其它D)
#设置结束标志符
DELIMITER $;
#创建函数
CREATE FUNCTION getLevel(INT score) RETURNS CHAR
BEGIN
IF score>=90 AND score<=100 THEN RETURN 'A';
ELSE IF score>=70 THEN RETURN 'B';
ELSE IF score>=60 THEN RETURN 'C';
ELSE RETURN 'D';
END IF;
/*
还可以使用下面这种CASE结构写法
CASE score
WHEN score>=90 AND score<=100 THEN RETURN 'A';
WHEN score>=70 THEN RETURN 'B';
WHEN score>=60 THEN RETURN 'C';
ELSE RETURN 'D';
END CASE;
*/
END $
#调用函数
SELECT getLevel(70);
循环结构
两个循环控制结构关键字ITERATE相当于java中的continue;LEAVE相当于java中的break;用在下面语法当中标签的位置。
- WHILE:先判断后执行,类似java中的while循环;
语法:【标签:】WHILE 循环条件 DO 循环体; END WHILE【标签】; - LOOP:没有条件的死循环,一般搭配LEAVE使用;
语法:【标签:】LOOP 循环体; END LOOP【标签】; - REPEAT:先执行后判断,类似java当中的do while循环;
语法:【标签:】REPEAT 【循环体】 UNTIL 循环结束的条件; END REPEAT【标签】;
举例说明:
- 往根据用户输入的数num往number中插入num条记录;
WHILE实现:
LOOP实现:DELIMITER $; CREATE PROCEDURE insertData(IN num INT) BEGIN DECLARE i INT DEFAULT 1; WHILE i<=num DO INSERT INTO number VALUES(i); SET i:=i+1; END WHILE; END $ CALL insertData(100) $;
REPEAT实现:DELIMITER $; CREATE PROCEDURE insertData(IN num INT) BEGIN DECLARE i INT DEFAULT 1; a:LOOP IF i>num THEN LEAVE a; END IF; INSERT INTO number VALUES(i); SET i:=i+1; END LOOP a; END $ CALL insertData(100) $;DELIMITER $; CREATE PROCEDURE insertData(IN num INT) BEGIN DECLARE i INT DEFAULT 1; REPEAT INSERT INTO number VALUES(i); SET i:=i+1; UNTIL i>num END REPEAT; END $ CALL insertData(100) $;
数据库设计三范式
数据库设计范式,将一个有异常数据操作的关系分解成更小的、结构良好的关系,使该关系有最小的冗余或没有冗余。关系规范化给设计者提供了对关系属性进行合理定义的指导。有了规范化关系设计,我们对数据库可以实现高效的、正确的操作。
- 第一范式:数据库表中不能出现重复记录,每一行必须唯一,就是任何一张表都应该有主键,并且每一个字段具有原子性,不可再分;
- 第二范式:建立在第一范式之上,所有非主键字段必须完全依赖主键,不能产生部分依赖;
- 第三范式:建立在第二范式之上,要求所有非主键字段直接依赖主键,不要产生传递依赖。
一对一关系:
对于一个用户,有一个账户名,和该账户对于的唯一的密码,而这个用户又有更加详细的信息;
①:主键共享
CREATE TABLE login(
ID INT PRIMARY KEY,
user_name INT UNIQUE,
password VARCHAR(20) NOT NULL
);
CREATE TABLE user_information(
ID INT PRIMARY KEY,
...
FOREIGN KEY(ID) REFERENCES login(ID)
);
②:外键唯一
CREATE TABLE login(
ID INT PRIMARY KEY,
user_name INT UNIQUE,
password VARCHAR(20) NOT NULL
);
CREATE TABLE user_information(
ID INT PRIMARY KEY,
...
userName INT UNIQUE,
FOREIGN KEY(userName) REFERENCES login(user_name)
);
一对多关系:
一个班级有多名学生,但是一名学生只能有一个班级;
一对多,两张表,多的表加外键;
#班级表
CREATE TABLE classes(
ID INT PRIMARY KEY,
...#其他字段
);
#学生表
CREATE TABLE student (
ID INT PRIMARY KEY,#学生id作为学生表主键
...#其他字段
#怡班级表的主键ID作为学生表的外键
class_id INT,
FOREIGN KEY(class_id) REFERENCES classes(id)
);
多对多关系:
一个老师可以教多个学生,而一个学生也可以有多个科任老师;
多对多,三张表,关系表两个外键;
#学生表
CREATE TABLE student(
ID INT PRIMARY KEY,
... #其他字段
);
#老师表
CREATE TABLE teacher(
ID INT PRIMARY KEY,
... #其他字段
);
#学生与老师关系表
CREATE TABLE student_teacher_relation(
ID INT PRIMARY KEY,
student_id,#以学生表主键作为关系表外键
teacher_id,#以老师表主键作为关系表外键
FOREIGN KEY(student_id) REFERENCES student(id),
FOREIGN KEY(teacher_id) REFERENCES teacher(id)
);















 2117
2117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









