







数据库 database
-- 库操作
- show databases; 查看所有库,默认有一个 '_internal' 库
- create database test; 创建一个库
- drop database test; 删除一个库
- use test; 选中一个库
- clear database|db; 清除当前上下文的库
表 measurement
注意:表不能显示创建,插入数据时自动插入表中数据。
-- 表操作
- show measurements; 查看所有表
- drop measurement "test"; 删除一个表 # 注意:删除表的时候,表名字最好加入双引号
插入数据
-- 基本语法
- insert [<retention policy>] measurement,tagKey=tagValue fieldKey=fieldValue [timestamp]
- 如:insert user,name=xw,phone=10086 sex="男",age=24,email="isxuewei@qq.com"
从上面的输出,简单小结一下插入的语句写法:
insert + measurement + "," + tag=value,tag=value + + field=value,field=value- tag 与 tag 之间用逗号分隔;field 与 field 之间用逗号分隔
- tag 与 field之间用空格分隔
- tag 都是 string 类型,不需要引号将 value 包裹
- field 如果是 string 类型,需要加引号
- <retention policy> 表示存储策略,可选,后面会详细解释
InfluxDB 不允许根据时间去删除数据,只能使用 <retention policy> 按照策略去自动删除
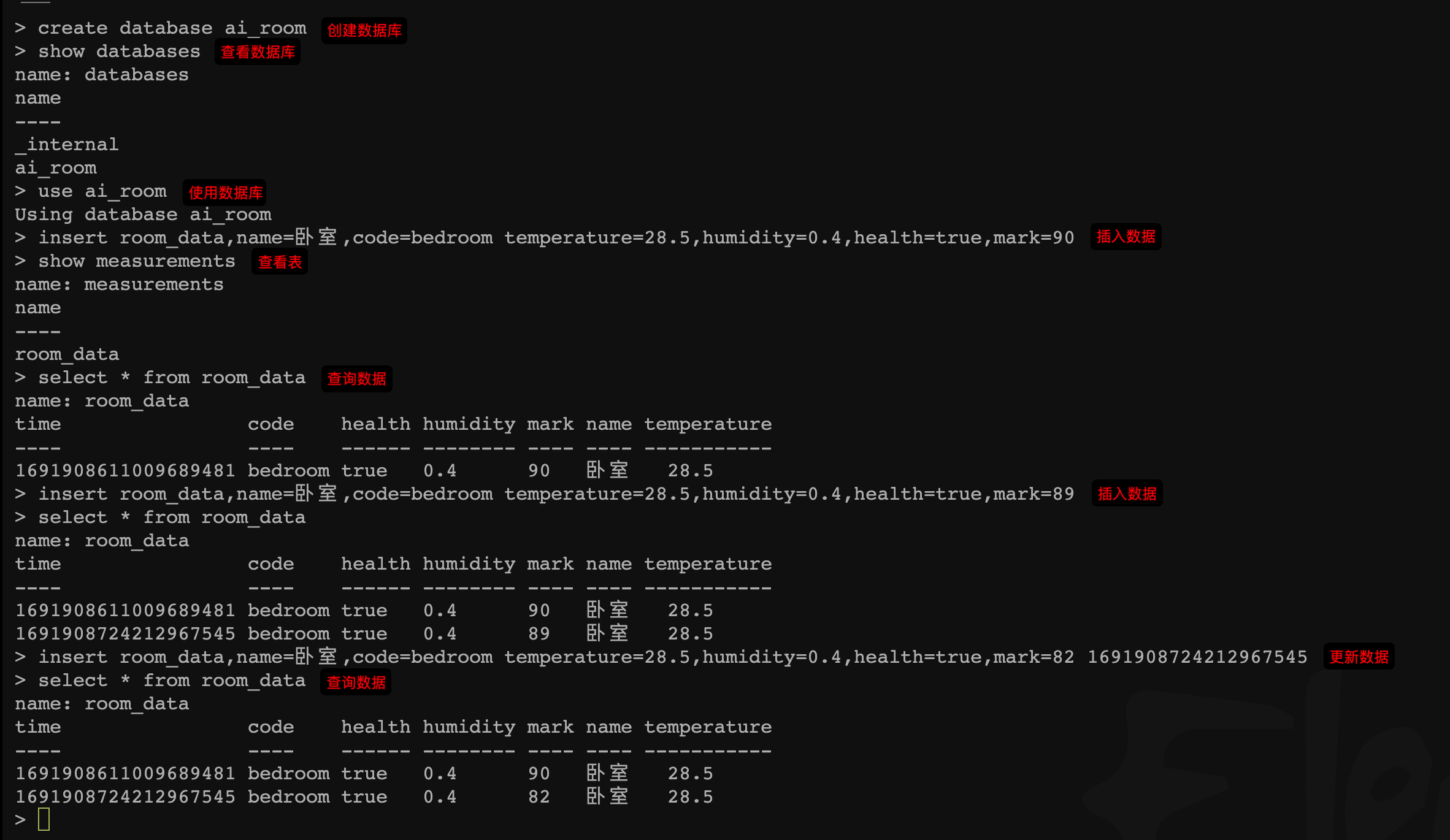
更新数据
如果在插入数据时,插入的数据的时间和 tags 与原有数据一致,则更新当前数据。
查询数据
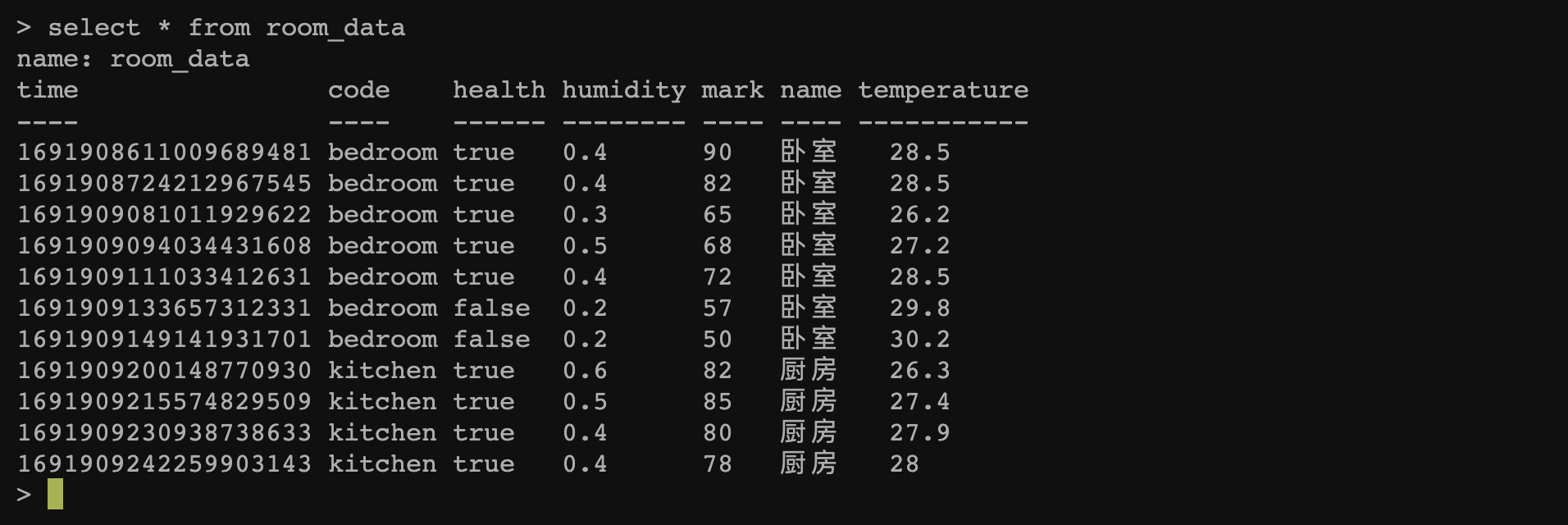
测试数据如下图所示:
普通查询
-- 查询全部数据
SELECT * FROM room_data;
-- 根据 tag 过滤
SELECT * FROM room_data WHERE "code" = 'bedroom' ;
SELECT * FROM room_data WHERE "name" = '厨房';
-- 根据 field 过滤
SELECT * FROM room_data WHERE "health" = false;
-- 查询所有的 field,不查 tag
SELECT *::field FROM room_data;
-- InfluxDB 不允许只查询 tag,至少也要携带一个 field 查询
SELECT *::tag, mark FROM room_data;
-- 模糊查询,注意=后面的为正则表达式,必须紧挨着=,前缀匹配:code 字段中以‘bed’开头的数据
SELECT * FROM room_data WHERE "code" =~/^bed/;
-- 模糊查询,注意=后面的为正则表达式,必须紧挨着=,后缀匹配:code 字段中以‘room’结尾的数据
SELECT * FROM room_data WHERE "code" =~/room$/;
-- 模糊查询,注意=后面的为正则表达式,必须紧挨着=,包含匹配:code 字段中包含‘e’的数据
SELECT * FROM room_data WHERE "code" =~/e/;
聚合函数
聚合函数只能对 field 字段进行操作,不能对 tag 字段操作,否则查询出来的列表是空的。不过可以使用子查询的方式解决这个问题。
-- DISTINCT 去重:对 tag 字段进行去重操作
SELECT DISTINCT("name") from (select * from room_data);
SELECT DISTINCT("code") from (select * from room_data);
-- DISTINCT 去重:对 field 字段进行去重操作
SELECT DISTINCT("humidity") from room_data;
-- COUNT 统计:查询某个 field 字段的中的非空值数量
SELECT COUNT("mark") from room_data;
-- MEAN 平均:查询某个 field 字段的中的平均值
SELECT MEAN("mark") from room_data WHERE "code" = 'bedroom';
-- MEDIAN 中位数:排序查询某个 field 字段的中的中位数,如果是奇数返回一个值,如果是偶数返回中间两个数的平均数
SELECT MEDIAN("humidity") from room_data WHERE "code" = 'bedroom';
-- SPREAD 极差:返回某个 field 字段的中的最大值与最小值的差值
SELECT SPREAD("mark") from room_data WHERE "code" = 'bedroom';
-- SUM 求和
SELECT SUM("mark") from room_data WHERE "code" = 'bedroom';
-- MAX 最大值
SELECT MAX("mark") from room_data WHERE "code" = 'bedroom';
-- MIN 最小值
SELECT MIN("mark") from room_data WHERE "code" = 'bedroom';
-- BOTTOM 返回最小的 n 个值
SELECT BOTTOM("mark", 3) from room_data WHERE "code" = 'bedroom';
-- FIRST 最早:返回某个 field 最早保存的值
SELECT FIRST("mark") from room_data WHERE "code" = 'bedroom';
-- LAST 最晚:返回某个 field 最晚保存的值
SELECT LAST("mark") from room_data WHERE "code" = 'bedroom';
分组聚合
-- 查询所有数据,并对其划分为每200毫秒一组,如果对应的分组结果没有数据,那么会显示为 NULL
select MEAN("mark") from room_data WHERE "code" = 'bedroom' group by time(200ms);
-- 查询所有数据,并对其划分为每2秒一组,如果对应的分组结果没有数据,那么会显示为 NULL
select MEAN("mark") from room_data WHERE "code" = 'bedroom' group by time(2s);
-- 查询所有数据,并对其划分为每2分钟一组,如果对应的分组结果没有数据,那么会显示为 NULL
select MEAN("mark") from room_data WHERE "code" = 'bedroom' group by time(2m);
-- 查询所有数据,并对其划分为每2小时一组,如果对应的分组结果没有数据,那么会显示为 NULL
select MEAN("mark") from room_data WHERE "code" = 'bedroom' group by time(2h);
-- 查询所有数据,并对其划分为每2星期一组,如果对应的分组结果没有数据,那么会显示为 NULL
select MEAN("mark") from room_data WHERE "code" = 'bedroom' group by time(2d);
-- 查询所有数据,并对其划分为每200毫秒一组,如果对应的分组结果没有数据,那么会显示为 NULL
select MEAN("mark") from room_data WHERE "code" = 'bedroom' group by time(2w);
分页查询
LIMIT 用法有 2 种:
1. limit 10:查询前 10 条数据
2. limit size offset N:size 表示每页大小,N 表示第几条记录开始查询,从 0 开始
# 查询前 10 条数据
- select * from room_data limit 10
# 分页,pageSize 为每页显示大小,pageIndex 为查询的页数
pageIndex = 1
pageSize = 10
- select * from room_data limit pageSize offset (pageIndex-1)*pageSize
排序
# 升序
select * from room_data order by time asc
# 降序
select * from room_data order by time desc
in 查询
InfluxDB 想要实现 in 的效果,可以使用正则表达式的方式。














 698
698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









