









数据分析——matplotlib
matplotlib折线图
from matplotlib import pyplot as plt
x = range(2, 26, 2)
y = [15, 13, 14.5, 17, 20, 25, 36, 36, 24, 22, 18, 15]
#设置图片大小,dpi为像素,figsize为尺寸(宽和长)
plt.figure(figsize=(15, 8), dpi=100)
#绘图
plt.plot(x, y)
#可以用数组的是来调节x轴的刻度; 也可以用range(2,15,2)来调节
a = [i/2 for i in range(2, 49)]
#设置x轴的刻度
plt.xticks(a[::3])
#设置y轴的刻度
plt.yticks(range(min(y), max(y)+1))
#保存图片,也可以保存为svg这种矢量图格式,方法后不会有锯齿--"./sig_size.png"
#保存图片应该在plt.show()之前 否则保存一张空白的白图
plt.savefig("./ti_size.png")
#展示图形
plt.show()
练习(1):表示十点到十二点的每一份中的气温
from matplotlib import pyplot as plt
import random
x = range(0, 120)
y = [random.randint(10, 35) for i in range(120)]
plt.plot(x, y)
plt.xticks(range(0, 121, 10))
plt.show()
#练习(2):表示十点到十二点的每一份中的气温 的x轴改进变成十点几分(字符串)
from matplotlib import pyplot as plt, font_manager
import random
x = range(0, 120)
#20-35随机取值
y = [random.randint(10, 35) for i in range(120)]
#设置宽和长以及像素
plt.figure(figsize=(18, 10), dpi=100)
#用plot绘图
plt.plot(x, y)
#x轴要用字符串表示 用{}作为占位符则 .format(字符)
a = ["10点{}分".format(i) for i in range(60)]
a += ["11:{}".format(i) for i in range(60)]
#设置字体的方式,首先导入font_manager
#C:/Windows/Fonts/STZHONGS.TTF为系统中字体的路径
my_font = font_manager.FontProperties(fname="C:/Windows/Fonts/STZHONGS.TTF")
#用x-ticks调整X轴,因为X轴要去步长,所以把x转换为列表
#数字和字符串一一对应,数据长度一样([::3]),rotation为调整角度
#因为有中文,所以要添加fontproperties = my_font
plt.xticks(list(x)[::3], a[::3], rotation=45, fontproperties=my_font)
#设置字体的方式,首先导入font_manager
#添加描述信息
#因为有中文,所以要添加fontproperties = my_font
plt.xlabel("时间", fontproperties=my_font)
plt.ylabel("温度 单位(℃)", fontproperties=my_font)
plt.title("十点到十二点每分钟的气温变化情况", fontproperties=my_font)
#展示
plt.show()
练习(3):统计出来从11岁到30岁每年交满盆友的数量如列表a,绘制折线图 a =[1,0,1,1,3,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
要求:y轴表示个数 x轴表示岁数,比如 11岁,21岁等
from matplotlib import pyplot as plt, font_manager
my_font = font_manager.FontProperties(fname="C:/Windows/Fonts/STZHONGS.TTF")
x = range(11, 31)
y = [1, 0, 1, 1, 3, 2, 4, 2, 3, 4, 4, 5, 6, 5, 4, 3, 3, 1, 1, 1]
a = ["{}岁".format(i) for i in x]
plt.figure(figsize=(18, 10), dpi=80)
plt.xlabel('年龄 单位:岁', fontproperties=my_font)
plt.ylabel('数量 单位:个', fontproperties=my_font)
plt.title("情感状况", fontproperties =my_font)
plt.xticks(x, a, fontproperties=my_font)
plt.yticks(y, fontproperties=my_font)
plt.plot(x, y)
# 绘制网格用grid() 根据X轴和Y轴的值的数量来画的(多少条横线,多少条竖线)
# 如果觉得网格太重了 则设置透明度---alpha(0~1)
# 在plot()中添加color=“ ”来设置线条颜色
# 在plot()中添加linestyle=“:”来设置线条样式 :为全虚线
plt.grid(alpha=0.1)
# 添加图例(显示哪条是自己哪条是同桌)
# 1.在plt.plot()中添加 lable=“ ”
# 2.需要plt.legend()来添加图例
# 3.因为有中文,这个特殊用prop=my_font来设置中文
# 4.如果想要调整图例显示的位置则在plt.legend()中添加loc="upper left"
plt.legend(prop=my_font, loc="upper left")
plt.show()
# 如果想绘制两个折线图则继续plot
利用plot来画数学函数图像
# 利用plot不仅可以画着线图 也可以画各种数学函数图像
from matplotlib import pyplot as plt, font_manager
# 利用numpy来准备数据
# np.linspace()来生成 -1到1之间的1000个数 特别密集就变得平滑了
import numpy as np
x = np.linspace(-1, 1, 1000)
y = 2*x*x
plt.plot(x, y)
plt.grid(alpha=0.5)
plt.show()

总结


matplotlib常用统计图
常用的图形
- 折线图plot
- 散点图scatter (关系规律)
- 柱状图bar(统计 对比)
- 直方图hist(分布状况)
- 饼图pie(占比)
绘制散点图
# 绘制散点图
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname="C:/Windows/Fonts/STZHONGS.TTF")
a_3 = [11, 12, 13, 14, 15, 16, 17, 17, 18, 17, 16, 15, 14, 13, 15, 16, 17, 18, 18, 14, 15, 17, 13, 14]
b_10 = [12, 15, 16, 17, 16, 15, 14, 17, 11, 19, 11, 17, 19, 14, 13, 18, 12, 16, 15, 14, 13, 13, 15, 12]
x = range(1, 25)
# 为了防止两个图像重合,则重新绘制x轴
x_10 = range(50, 74)
# 设置图像大小,
plt.figure(figsize=(18, 10), dpi=80)
# 绘制散点图 使用scatter来绘制散点图 label为添加图例
plt.scatter(x, a_3, label="三月份")
# 绘制另一个散点图(scatter),传入新的x轴
plt.scatter(x_10, b_10, label="十月份")
# 调整x轴的刻度,因为有字符串则数字和字符串一一对应
_x = list(x)+list(x_10) # 如果用range则中间有空着的数,所以用加法
c = ["3月{}日".format(i) for i in x]
c += ["10月{}日".format(i) for i in x_10]
plt.xticks(_x[::3], c[::3], fontproperties=my_font, rotation=45)
# 添加图例 注意:中文 位置
plt.legend(prop=my_font)
# 添加图片信息
plt.xlabel("时间", fontproperties=my_font)
plt.ylabel("温度", fontproperties=my_font)
plt.title("三月份与十月份的天气气温对比", fontproperties=my_font)
# 展示
plt.show()
绘制竖着的柱状图
#绘制竖着的条形图
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname="C:/Windows/Fonts/STZHONGS.TTF")
# 如果长度较长则加上\n
a = ["李浩", "王艺晓", "欧向媛", "吴嘉欣", "董泽龙"]
y = [55, 67, 34, 23, 23]
plt.figure(figsize=(15, 10), dpi=80)
# x轴为字符串 这种写法要注意
# 绘制竖着的条形图要用bar
plt.bar(range(len(a)), y, width=0.3)
plt.xticks(range(len(a)), a, fontproperties=my_font, rotation=45)
plt.figure(figsize=(15, 10), dpi=80)
绘制横着的柱状图
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname="C:/Windows/Fonts/STZHONGS.TTF")
# 如果长度较长则加上\n
a = ["李浩", "王艺晓", "欧向媛", "吴嘉欣", "董泽龙"]
y = [55, 67, 34, 23, 23]
plt.figure(figsize=(15, 10), dpi=80)
# 绘制网格
plt.grid(alpha=0.3)
# 添加信息
plt.xlabel("数量", fontproperties=my_font)
plt.ylabel("姓名", fontproperties=my_font)
plt.title("爱情匹配", fontproperties=my_font)
# x轴为字符串 这种写法要注意
# 绘制横着的条形图要用bar
plt.barh(range(len(a)), y, height=0.3, color="green")
plt.yticks(range(len(a)), a, fontproperties=my_font)
plt.figure(figsize=(15, 10), dpi=80)
plt.show()
在同一图中绘制多条
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname="C:/Windows/Fonts/STZHONGS.TTF")
a = ["你好李焕英", "战狼2", "无名之辈"]
b_14 = [11, 12, 13]
b_15 = [13, 12, 12]
b_16 = [12, 11, 14]
# 设置宽度,在不会发生重叠
bar_wide = 0.2
x_14 = list(range(len(a)))
# x
x_15 = [i+bar_wide for i in x_14]
x_16 = [i+bar_wide*2 for i in x_14]
plt.bar(range(len(a)), b_14, width=bar_wide, label="9月14号")
plt.bar(x_15, b_15, width=bar_wide, label="9月15号")
plt.bar(x_16, b_16, width=bar_wide, label="9月16号")
# 设置图例 在绘制时要用label设置信息,再用plt.legend()实现 中文prop 位置loc 等
plt.legend(prop=my_font, loc="upper left")
# 在 plt.xticks 中设置x轴的文字 x_15 与 a 的个数要一致 以为x轴有文字了
plt.xticks(x_15, a, fontproperties=my_font)
plt.show()

from matplotlib import pyplot as plt, font_manager
my_font = font_manager.FontProperties(fname="C:/Windows/Fonts/STZHONGS.TTF")
# 设置c,将第二个柱状图王后移动,避免重合
c = 0.2
a = ["你好李焕英", "战狼2", "无名之辈", '李浩', '王艺晓']
b = [12, 11, 14, 12, 14]
b1 = [13, 12, 11, 15, 17]
plt.figure(figsize=(20, 8), dpi=80)
# 设置x轴 添加字符串
x = ['{}'.format(i) for i in a]
# [i+0.1 for i in range(len(a))]将x轴的字符串说明显示在两个柱状图之间
plt.xticks([i+0.1 for i in range(len(a))], x, fontproperties=my_font)
# 绘制柱状图 range(len(a))与b的长度要箱等
# width是设置每一个柱状图的宽度
# bar的第一个参数是横轴类别个数
plt.bar(range(len(a)), b, width=0.2, label="五月份")
# [(i+c) for i in range(len(a))] 往后移动避免重叠
plt.bar([(i+c) for i in range(len(a))], b1, width=0.2, label="3月份")
# prop显示图例字体
plt.legend(prop=my_font)
plt.show()

绘制直方图
import matplotlib.pyplot as plt
a = [123, 254, 325, 432, 143, 214, 321, 342, 143, 243, 214, 321, 432]
# 设置组距
b = 7
# 计算组数
group_num = int((max(a)-min(a))/b)
plt.figure(figsize=(20, 8), dpi=80)
# plt.hist的第一个参数是指定每个bin(箱子)分布的数据,对应x轴
# bins : integer or array_like, optional
# 这个参数指定bin(箱子)的个数,也就是总共有几条条状图
plt.hist(a, group_num)
# 调整x轴刻度 b是组距
plt.xticks(range(min(a), max(a)+7, b))
plt.show()

绘制饼图
plt.pie(x,labels=,autopct=,colors)
- x:数量,自动化计算
- labels:每部分名称
- autopct:占比显示指定%1.2f%%
- color:每部分的颜色
import matplotlib.pyplot as plt
import matplotlib
from matplotlib import font_manager
my_font=font_manager.FontProperties(fname="C:/Windows/Fonts/STZHONGS.TTF")
fig = plt.figure()
labels = ["你好李焕英", "战狼2", "无名之辈", '不二神探', '谢文东']
data = [12, 11, 14, 12, 14]
# 解决汉字乱码问题
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 使用指定的汉字字体类型(此处为黑体)
plt.pie(data, labels=labels, autopct='%1.2f%%') # autopct='%1.2f%%'输出各块饼状图所占百分比并保存两位小数
# 使图像显示的长宽相等
plt.axis('equal')
# 因为有labels了直接显示图例就可以了,
plt.legend(prop=my_font)
plt.show()

总结

数据分析——Numpy(用于快速处理任意维度的数组运算)
为什么可以运用循环实现这样的存储,而非得用Numpy?
- Numpy中的方法计算速度快,节省了很多时间。
ndarray的属性
shape
- ndim(维度)
- size
dtype
- itemsize(字节大小)
import numpy as np
# 将数据存入矩阵
score = np.array([[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6]])
print(score)
'''
[[1 2 3 4 5]
[2 3 4 5 6]]
'''
print(score.shape)
'''
(2, 5)
'''
print(score.ndim)
'''
2
'''
print(score.size)
'''
10
'''
print(score.dtype)
'''
int32
'''
print(score.itemsize)
'''
4
'''
生成数组的方法
#(1)生成1和0
print(np.zeros((3, 4)))
'''
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
'''
# 可指定类型
print(np.ones((3, 4), dtype="int64"))
'''
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
'''
# (2)从现有数组中生成
'''
np.array() np.copy 深拷贝
np.asarray() 浅拷贝
'''
# (3) 生成固定范围的数组
'''
np.linspace() 就是生成多少到多少的多少个数 等距离的 左右都闭
np.arange(a , b, c) 与range相似
'''
print(np.linspace(0, 10, 5)) # [ 0. 2.5 5. 7.5 10. ]
print(np.arange(0, 11, 2)) # [ 0 2 4 6 8 10]
# (4)生成随机数组
# 均匀分布
a = np.random.uniform(-1, 1, 100000) # 返回列表
plt.hist(a, 1000)
plt.show()
# 正态分布 使用normal loc代表平均值 scale代表方差 size代表多少分
data2 = np.random.normal(loc=1.75, scale=0.1, size=1000000)
plt.hist(data2, 1000)
plt.show()


切片索引与形状改变
import numpy as np
data = np.random.normal(0, 1, (8, 10))
print(data)
print("aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa")
data2 = np.random.uniform(-1, 1, (10, 10))
# 打印第一行前三个
print(data2[0, :3])
# 创建一个三维数组
data = np.array([[[1, 2, 4], [2, 3, 4]],
[[3, 4, 5], [2, 4, 3]]])
print(data.shape) # (2, 2, 3)
data = np.random.normal(0, 1, (8, 10))
# (1)形状修改 reshape 重新分割不是将行列进行转换 原始数据没有改变
print(data.reshape(10, 8))
print(data.shape) # (8, 10)
# (2)形状改变 resize 没有返回值 改变原始数据
print(data.resize(10, 8))
print(data.shape) # (10, 8)
# (3)形状改变 .T 行变成列 列变成行
print(data.T)
print(data.shape) # (10, 8)
类型修改与数组去重
import numpy as np
data = np.random.uniform(-1, 1, 1000)
# 类型修改
# (1)ndarray.astype(type) 可以转化为任意类型
print(data)
print(data.astype('int32'))
# (2)序列化
print(data.tostring())
# 数组的去重 (1) 使用np.unique
#
data2 = np.array([[11, 22, 33],
[22, 33, 44]])
print(data2)
print(np.unique(data2)) # [11 22 33 44]
# (2) 现将数组比变为一维的 使用flatten() 在使用set去重 set只可以处理一维的
print(set(data2.flatten())) # {33, 11, 44, 22}
逻辑运算
注意: Numpy中的与(np.logical_and)和或(np.logical_or)
统计运算
统计指标函数
- min max mean median var
- 使用方法:np.函数名 ndarray.方法名
返回最大值最小值的所在位置
- np.argmax(temp, axis=)
- np.argmin(temp, axis=)
import numpy as np
a = np.arange(1, 13).reshape(3, 4)
print(a)
# 按列求最大值 axis=0 列 两种使用方式
print(np.max(a, axis=0)) # [ 9 10 11 12]]
print(a.max(axis=0)) # [ 9 10 11 12]
print(a.argmax(axis=0)) # [2 2 2 2]
数组间运算
从左向右写出 行数 列数 几维
- 数组与数组的运算
需要满足的条件:维度相等
shape(其中相对应的一个地方为1)
a(2, 6) a1(2,1)
满足对应维度为一(1和6) 维度都为2 都要满足
import numpy as np
# 数组与数的运算
a = np.arange(1, 13).reshape(2, 6)
a1 = np.array([[1], [3]])
print(a + 1) # 原生列表不可以这样操作
'''
[[ 2 3 4 5 6 7]
[ 8 9 10 11 12 13]]
'''
# 数组与数组的运算
# 需要满足的条件:维度相等
# shape(其中相对应的一个地方为1)
# a(2, 6) a1(2,1)
# 满足对应维度为一(1和6) 维度都为2
print(a+a1)
'''
[[ 2 3 4 5 6 7]
[10 11 12 13 14 15]]
'''
矩阵运算
矩阵必须是二维的
import numpy as np
# 用np.array存储矩阵
a = np.array([[1, 2, 3],
[2, 3, 4]])
print(a)
'''
[[1 2 3]
[2 3 4]]
'''
print(type(a)) # <class 'numpy.ndarray'>
# 使用np.mat来存储矩阵
b = np.mat([[1, 2, 3],
[2, 3, 4]])
print(b)
'''
[[1 2 3]
[2 3 4]]
'''
print(type(b)) # <class 'numpy.matrix'>
# 矩阵的乘法运算
# 形状:第一个矩阵的列数 = 第二个矩阵的行数 (m,n)*(n,l)=(m,l)
# 运算规则:第一个矩阵的第一行*第一个矩阵的第一列 求和
# 矩阵乘法:
# 1.使用np.array()来存储的:
# (1)np.matmul
# (2)np.dot
# (3)使用 @ 运算符
# 2.使用np.mat()来存储的:
# 直接使用*相乘
合并和分割
合并
- 水平分割:np.hstack((a ,b))
- 竖直分割:np.vstack((a, b))
- 自定义分割:np.concatenate((a, b),axis=) 使用axis=来确定方向
分割
- np.split(x,3) 3代表把X分成三分
- np.split(x, [2,3,5,7]) 第二个参数也可以是列表 即按照列表的数字为索引进行分割
IO操作与数据处理
如何处理缺失值?
- 数据多的话直接删除
- 数据少的话则求着一 列 的平均值填入即可
- nan 是float类型的
总结


Pandas(数据处理)
核心数据结构
- DateFrame
- panel
- Series
DataFrame的属性和方法
结构
- DataFrame对象既有行(index)索引,又有列(columns)索引
属性
- shape
- index
- colunms
- values
- .T
方法
- head()
- tail()
import pandas as pd
import numpy as np
# 创建一个符合正态分布的10个股票5天的涨跌幅数据
# normal 的参数(平均值,标准差,(行数,列数))
a = np.random.normal(0, 1, (10, 5))
# 默认生成行和列索引
# print(pd.DataFrame(a))
'''
0 1 2 3 4
0 -1.207717 -1.248797 -0.640382 0.168145 -2.214614
1 1.604770 0.532246 2.217270 -0.533791 -0.104601
2 -0.064688 -1.221546 -2.160536 0.230165 0.572828
3 -0.214652 0.013347 -1.372295 -0.861707 0.415961
4 -0.639762 0.248045 -0.559596 -1.733083 0.256867
5 -2.970197 -0.920252 -0.309204 1.187057 -1.695835
6 -1.172035 0.016540 1.302866 -0.429265 -1.184477
7 0.837860 -1.680493 1.581194 1.357324 -0.104305
8 0.857267 0.730812 -0.360741 -0.089482 -0.453699
9 0.327756 -2.357339 -1.212887 0.062610 -2.159198
'''
# 添加行索引
stock = ['股票{}'.format(i) for i in range(10)]
# index 为行索引
print(pd.DataFrame(a, index=stock))
'''
0 1 2 3 4
股票0 0.059980 0.826409 -0.223063 -0.928418 0.674813
股票1 1.095684 0.325544 -0.551691 0.427019 0.856845
股票2 0.189529 -1.466617 -0.564167 -1.189819 -2.278880
股票3 -0.376953 -1.912115 -0.854864 -0.569774 -0.488165
股票4 -0.013032 0.781855 -1.295934 0.170208 -0.376939
股票5 0.045266 1.002288 -0.230473 -0.469611 0.800717
股票6 -1.142104 -0.527628 0.785824 -0.918758 -0.933966
股票7 -1.111547 -1.682823 1.180121 -0.008195 -0.625462
股票8 -0.121307 0.218556 0.075264 -1.231691 -0.253801
股票9 -0.506841 0.748017 -1.062414 -0.706850 -0.534222
'''
# 添加列索引 使用pd.data_range(start=,periods=,)
# 使用columns 为列索引
r = pd.date_range(start="20200211", periods=5, freq="B")
# start:开始时间 end:结束时间 periods:时间天数 freq:递进单位 默认是一天 “B”默认略过周末
data = pd.DataFrame(a, index=stock, columns=r)
print(pd.DataFrame(a, index=stock, columns=r))
'''
2020-02-11 2020-02-12 2020-02-13 2020-02-14 2020-02-17
股票0 0.473406 -0.713013 0.530705 1.395440 -0.106743
股票1 0.833059 0.078465 1.556920 0.136347 -0.236517
股票2 0.083847 -0.604731 -1.012644 -1.295942 -1.794573
股票3 0.139216 -1.560970 0.385182 -1.122589 0.064502
股票4 -1.208188 1.778695 -0.311338 1.967918 -0.169568
股票5 1.014347 -1.465112 -0.228816 -0.497649 -1.615723
股票6 -0.861362 1.172299 -0.459407 -0.365274 -0.881251
股票7 1.197690 0.108827 0.627654 -0.181689 -0.078830
股票8 -1.519303 -0.687538 2.117792 0.077629 -1.369787
股票9 -2.175760 -0.739745 0.005733 -1.221873 1.785287
'''
# 属性
print(data.shape)
'''
(10, 5)
'''
print(data.index)
'''
Index(['股票0', '股票1', '股票2', '股票3', '股票4', '股票5', '股票6', '股票7', '股票8', '股票9'], dtype='object')
'''
print(data.columns)
'''
DatetimeIndex(['2020-02-11', '2020-02-12', '2020-02-13', '2020-02-14',
'2020-02-17'],
dtype='datetime64[ns]', freq='B')
'''
# 打印值
print(data.values)
# 使用 .T 进行翻转
print(data.T)
# 方法
# 返回data中的前几行 默认是前五行
print(data.head(2))
'''
2020-02-11 2020-02-12 2020-02-13 2020-02-14 2020-02-17
股票0 -0.530954 1.186140 -0.749949 0.368391 -0.805679
股票1 1.633176 -0.681874 -0.167886 0.296961 -1.658655
'''
# 返回data中的后几行 默认是后五行
print(data.tail(2))
'''
2020-02-11 2020-02-12 2020-02-13 2020-02-14 2020-02-17
股票8 -0.355958 -0.443451 -0.115205 1.262788 1.560764
股票9 0.462510 -0.108966 -0.403830 -0.340286 0.742552
'''
DataFrame的索引设置
修改行列索引值
- **注意:**不能单独修改某一个索引名,必须统一进行修改
重设索引
- reset_index(drop=False)
- 设置新的下标索引
- drop:默认为False,不删除原来的索引,如果为true,删除原来的索引值
print(data.reset_index())
'''
index 2020-02-11 00:00:00 ... 2020-02-14 00:00:00 2020-02-17 00:00:00
0 股票0 -0.662236 ... -0.548053 -1.331190
1 股票1 0.335827 ... 1.784294 -0.767156
2 股票2 2.484586 ... -1.328786 -0.116147
3 股票3 -0.371153 ... -0.765087 -0.423251
4 股票4 -0.647133 ... 0.549469 -1.411637
5 股票5 -0.028942 ... -1.036370 -0.000349
6 股票6 -0.579712 ... -1.736054 1.058744
7 股票7 0.742626 ... -0.086749 2.156802
8 股票8 0.709755 ... 0.126285 -1.539763
9 股票9 0.049199 ... 1.742230 -0.016433
'''
print(data.reset_index(drop=True))
'''
2020-02-11 2020-02-12 2020-02-13 2020-02-14 2020-02-17
0 -1.794034 -0.396872 -0.808918 0.490704 -0.734046
1 0.680201 0.702601 1.739025 0.144146 -0.315151
2 -0.368717 1.024773 0.706208 -0.535971 0.652453
3 -0.127670 -0.697536 0.571598 1.051648 0.056980
4 -0.045461 0.681752 1.750805 0.479889 -1.699287
5 -0.418098 -0.298092 0.816836 -1.430173 -1.537106
6 0.752113 0.003148 -0.469096 -1.472685 2.148855
7 -1.542997 -0.824122 -0.412857 0.617622 0.633481
8 0.933861 0.028433 0.242712 0.026916 1.118974
9 1.607081 1.134164 -0.509641 0.195169 2.069185
'''
设置新索引
- 以某列的值设置为新的索引
- set._index(keys, drop=True)
- keys:列索引名或者列索引名称的列表
- drop:boolean,default,true. 当做新的索引,删除原来的索引
# 用字典来创建DataFrame
df = pd.DataFrame({'month': [1, 2, 3, 4],
'year': [12, 34, 56, 78],
'sale': [1, 2, 3, 4]})
print(df)
'''
month year sale
0 1 12 1
1 2 34 2
2 3 56 3
3 4 78 4
'''
# 将月份(一个)设置为新的索引
print(df.set_index("month")) # 默认的是True 删除原先的
'''
year sale
month
1 12 1
2 34 2
3 56 3
4 78 4
'''
print(df.set_index("month", drop=False)) # 如果为False则不删除原先的
'''
month year sale
month
1 1 12 1
2 2 34 2
3 3 56 3
4 4 78 4
'''
# 将月份,年份(多个)设置为新的索引
print(df.set_index(['year', 'month']))
'''
sale
year month
12 1 1
34 2 2
56 3 3
78 4 4
'''
print(df.set_index(['year', 'month'], drop=False))
'''
month year sale
year month
12 1 1 12 1
34 2 2 34 2
56 3 3 56 3
78 4 4 78 4
'''
m = df.set_index(['year', 'month'], drop=False)
print(m.index)
'''
MultiIndex([(12, 1),
(34, 2),
(56, 3),
(78, 4)],
names=['year', 'month'])
索引变为了MultiIndex
'''
MultiInndex与Panel
MultiInndex
- names:levels的名称
- levels:每个level的元组值
print(m.index.names) # ['year', 'month']
print(m.index.levels) # [[12, 34, 56, 78], [1, 2, 3, 4]]
Panel(存储三维数组)(DataFrame的容器)

Series(带索引的一维数组)
属性
- index
- values
# 创建
print(pd.Series(np.arange(3,14)))
'''
0 3
1 4
2 5
3 6
4 7
5 8
6 9
7 10
8 11
9 12
10 13
dtype: int32
'''
# 指定特定索引
print(pd.Series(np.arange(3, 14, 2), index=["a", 'b', 'c', 'd', 'e', 'f']))
'''
a 3
b 5
c 7
d 9
e 11
f 13
dtype: int32
'''
# 可以用字典进行创建Series
四种索引操作
读取文件
删除不需要的列
 1.直接进行索引(先列后行)
1.直接进行索引(先列后行)

2.按名字进行索引(loc)

3.按数字索引:如果要想像Numpy一样直接使用数字索引,则需要使用 iloc

4.组合索引(数字和名字混用)则使用 ix

ix 的方法可以用loc与iloc来替代
 赋值与排序
赋值与排序
赋值

对内容排序

第一个参数的两个值:首先看high进行排序,如果有相同的则按照第二个进行排序

对索引排序


对Series内容进行排序则不需要指定字段,直接选择升序降序就可以了

对Series索引进行排序则不需要指定字段,直接选择升序降序就可以了

算术运算和逻辑运算
算术运算(Series)
- 统一加上三

- 使用add()的方法 显示前几行
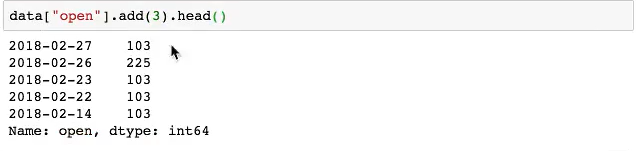
算术运算(DataFrame)
- 求和

- 一 一对应的相减

逻辑运算
- 返回布尔值

- 可以做布尔索引
(把>2 的数据都打印出来)
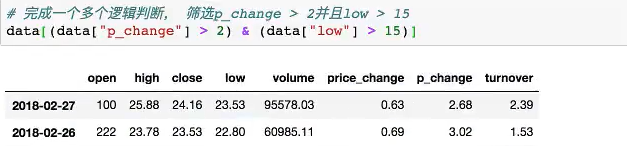
逻辑运算函数
- query() 查找字符串

- isin() 判断一组数中是否含有某些值


统计运算和自定义运算
统计运算 (max min mean median var std)
describe() 一次性得出上面这些,不需要一个一个调用了


统计函数

返回最大值最小值的所在位置

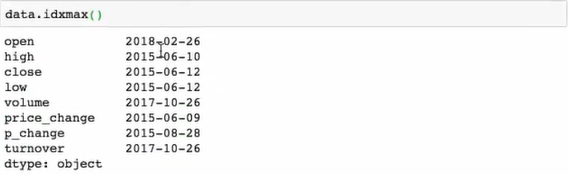
累计统计函数
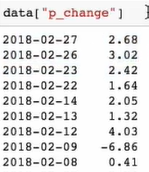
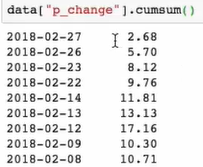
因为他是一个Series所以直接进行 .plot 进行画图

自定义运算

Pandas画图

文件的读取与存储
csv文件的读取与存储(usecols是显示读取的列)

注意: 遇到没有行列索引直接是数据的 需要使用names = [’ ', ’ '…] 添加字段

columns=[“open”] 是就保存open那一列
index = False 是不要行索引
model = “a” 是追加
header = False 是省略追加的头部(open)

-hdf5文件的读取和存储
-json文件的读取和存储
总结




















 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









