






TCP/IP协议栈源代码分析
一、实验目的
- inet_init是如何被调用的?从start_kernel到inet_init调用路径
- 跟踪分析TCP/IP协议栈如何将自己与上层套接口与下层数据链路层关联起来的?
- TCP的三次握手源代码跟踪分析,跟踪找出设置和发送SYN/ACK的位置,以及状态转换的位置
- send在TCP/IP协议栈中的执行路径
- recv在TCP/IP协议栈中的执行路径
- 路由表的结构和初始化过程
- 通过目的IP查询路由表的到下一跳的IP地址的过程
- ARP缓存的数据结构及初始化过程,包括ARP缓存的初始化
- 如何将IP地址解析出对应的MAC地址
- 跟踪TCP send过程中的路由查询和ARP解析的最底层实现
二、实验环境配置
1、安装相关工具
2、下载Linux内核源代码

3、配置Linux内核选项
这里需要修改
make defconfig # Default configuration is based on 'x86_64_defconfig'
make menuconfig# 打开debug相关选项
修改里面的如下配置:
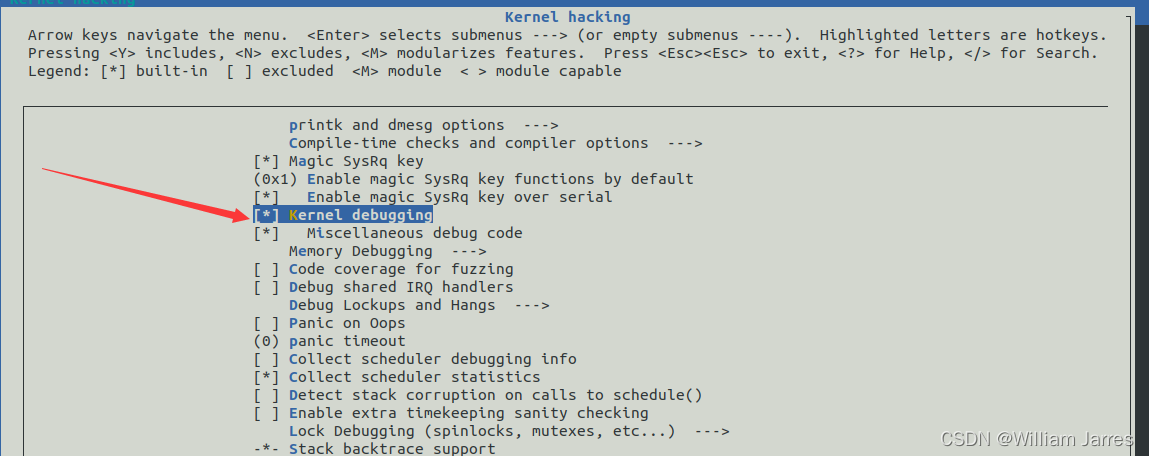
Kernel hacking --->
Compile-time checks and compiler options --->
[*] Compile the kernel with debug info
[*] Provide GDB scripts for kernel debugging
[*] Kernel debugging
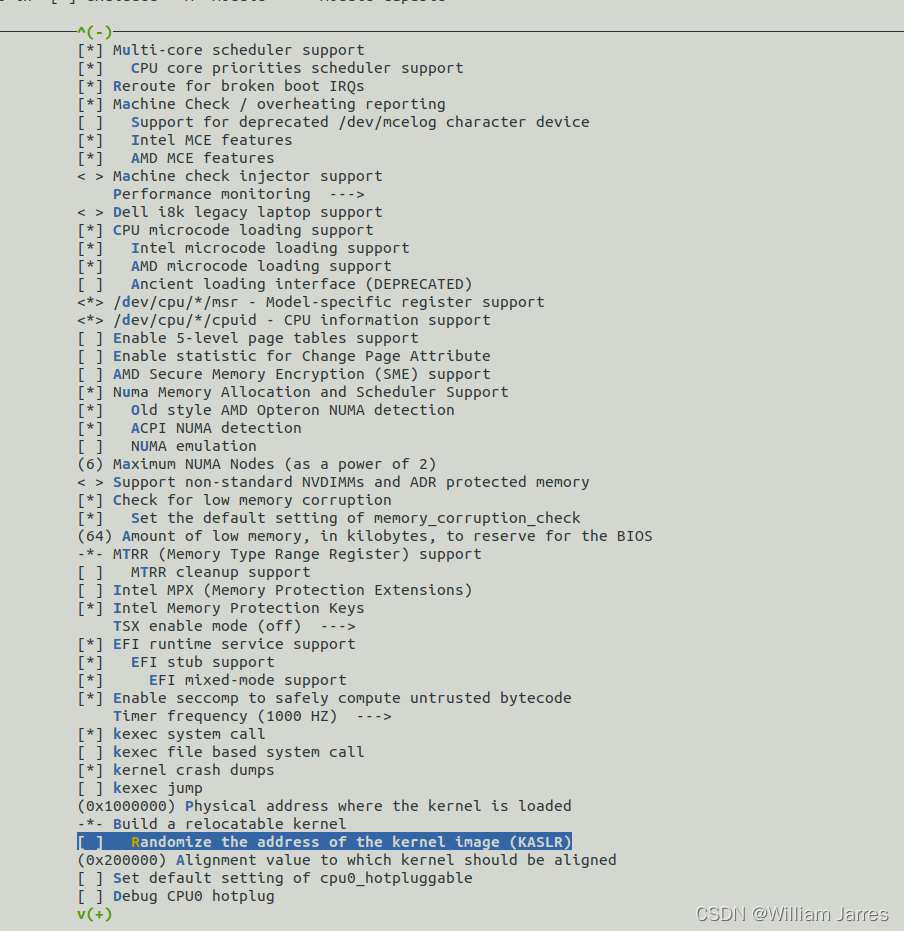
# 关闭KASLR(随机地址),否则会导致打断点失败。这样调试器就可以跟踪到源代码,之所以设置随机地址为了防止黑客攻击:
Processor type and features ---->
[ ] Randomize the address of the kernel image (KASLR)

4、编译运行Linux内核
make -j$(nproc) # nproc gives the number of CPU cores/threads available
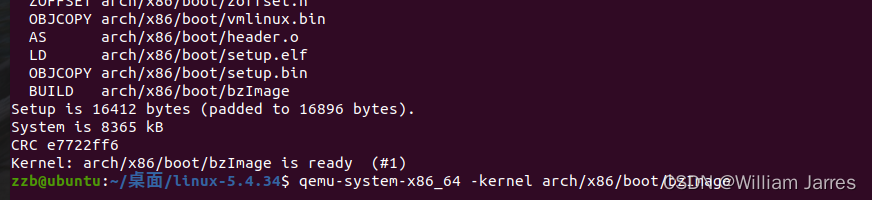
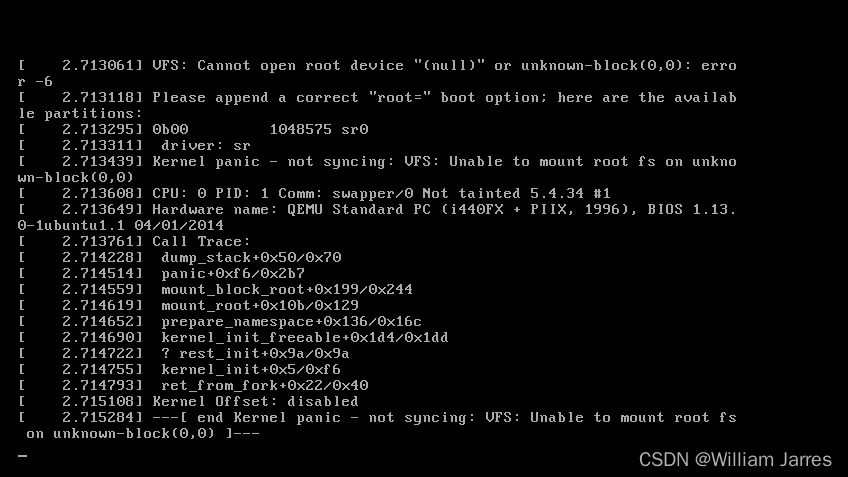
# 测试一下内核能不能正常加载运行,因为没有文件系统最终会kernel panic
qemu-system-x86_64 -kernel arch/x86/boot/bzImage
5、制作根文件系统
如果直接采用老师的方式会报错,这里可以采用打补丁的方式:[busybox编译报错undefined reference to `stime‘ make: *** Makefile:716: busybox_unstripped] Error 1_o_alpha的博客-CSDN博客
打个补丁即可,这里采用的是下载下一个版本代替,这样更简单一点,操作如下:
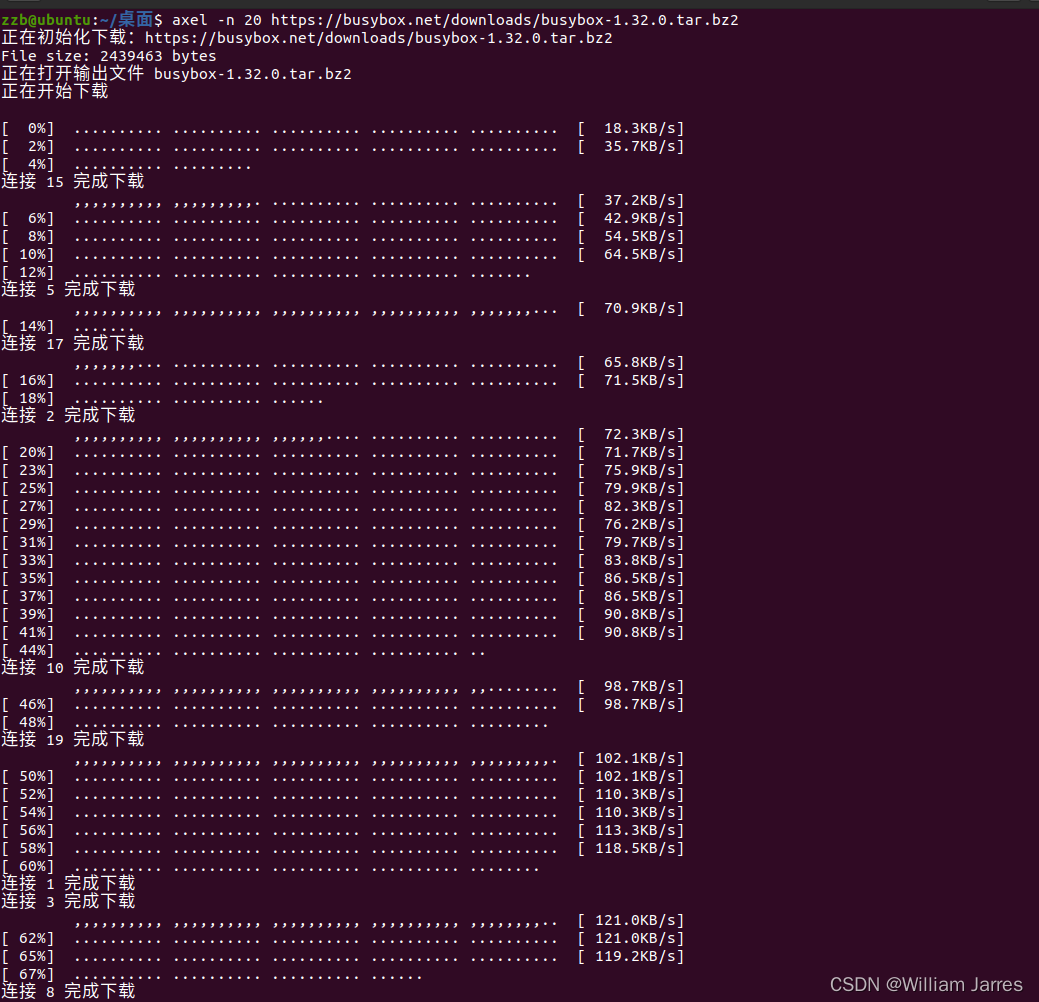
axel -n 20 https://busybox.net/downloads/busybox-1.32.0.tar.bz2 #这里从31.1改为32.0
tar -jxvf busybox-1.32.0.tar.bz2
cd busybox-1.32.0
编译运行:
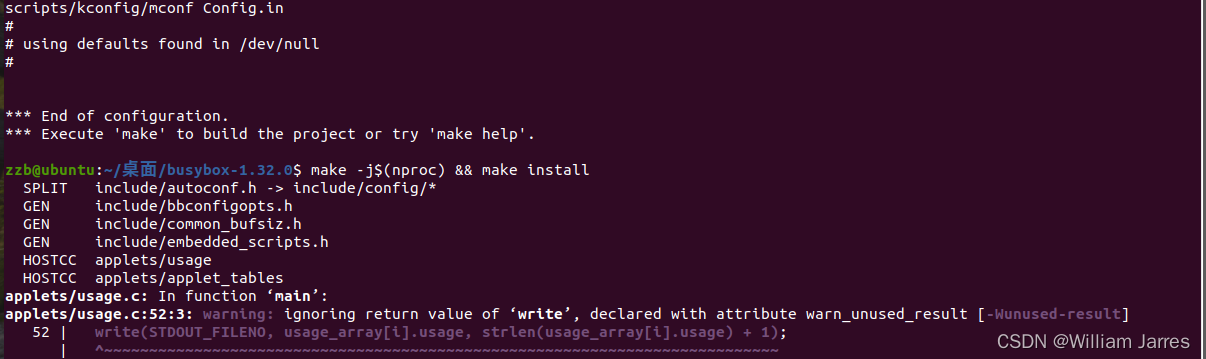
make menuconfig
#记得要编译成静态链接,不用动态链接库。
然后编译安装即可:
make -j$(nproc) && make install
然后利用busybox制作根文件目录:
mkdir rootfs
cd rootfs
cp ../busybox-1.32.0/_install/* ./ -rf
mkdir dev proc sys home
sudo cp -a /dev/{null,console,tty,tty1,tty2,tty3,tty4} dev/

然后还需要创建一个init文件。内容如下:
#!/bin/sh
mount -t proc none /proc
mount -t sysfs none /sys
echo "Welcome YouYouOS!"
echo "--------------------"
cd home
/bin/sh
接下来对脚本添加可执行权限:
chmod +x init

使用静态编译的程序,并把静态编译的server和client拷贝到rootfs/home/目录下。
打包成内存根文件系统镜像。使用如下命令将rootfs目录打包成rootfs.cpio.gz文件。
find . -print0 | cpio --null -ov --format=newc | gzip -9 > ../rootfs.cpio.gz
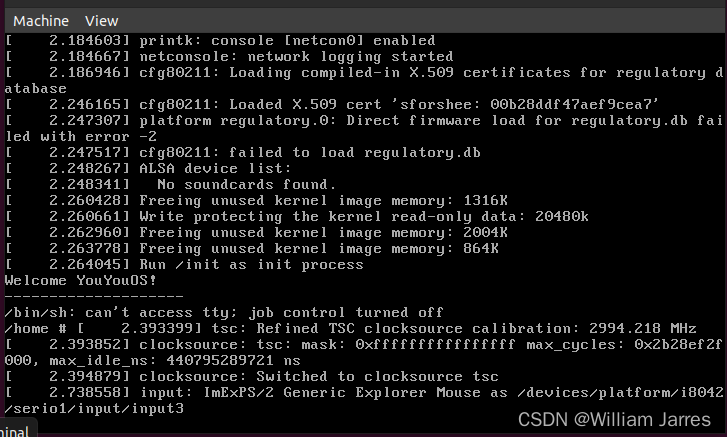
测试挂载根文件系统,看内核启动完成后是否执行 init 脚本
qemu-system-x86_64 -kernel linux-5.4.34/arch/x86/boot/bzImage -initrd rootfs.cpio.gz
6、初始化Linux系统的网络功能
(1)激活网络设备接口配置IP地址
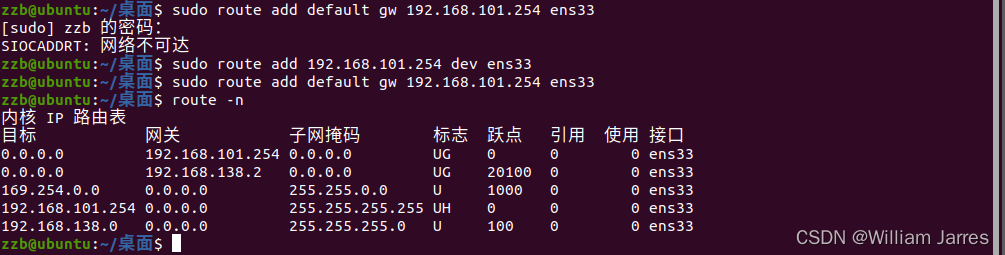
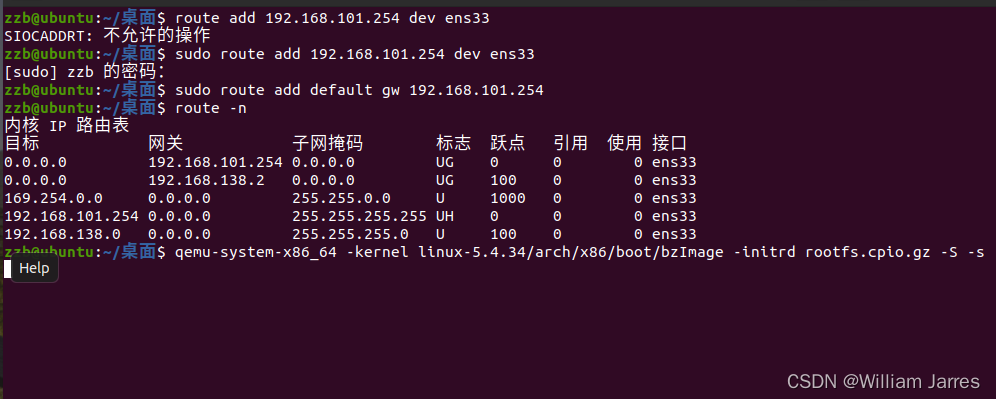
(2)配置默认网关
手动增加一条路由 route add default gw 192.168.101.254,即添加一条默认网关,但是却发现下面的错误
SIOCADDRT: No such process
这是因为我要添加的192.168.101.254跟我主机不在同一个网段,需要添加一下
route add 192.168.101.254 dev ens33
然后再执行一下上面的命令就可以了, route -n一下就能看到结果。
(3)配置DNS
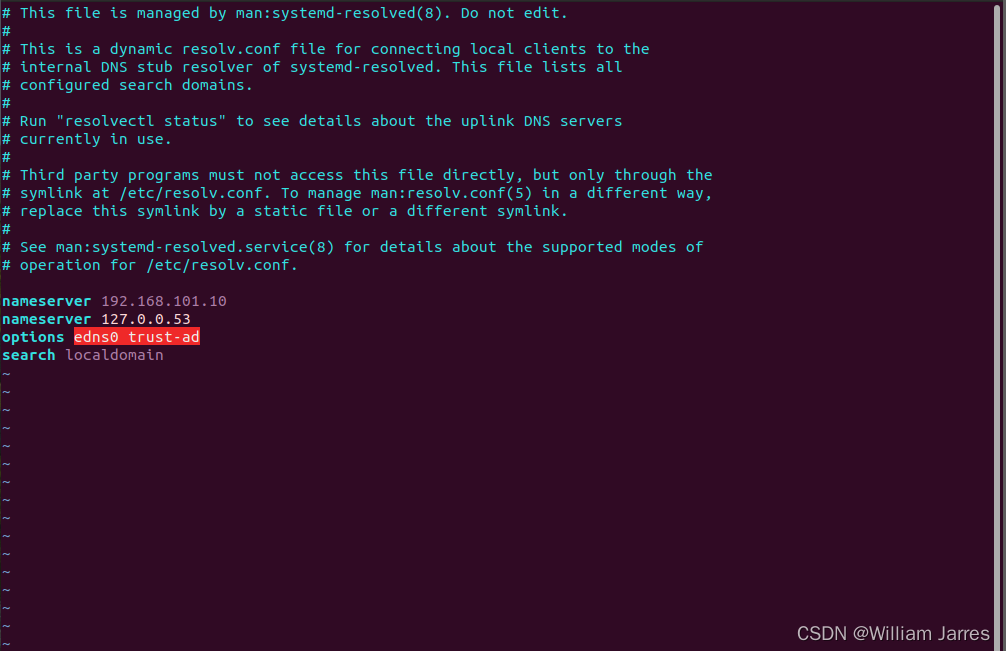
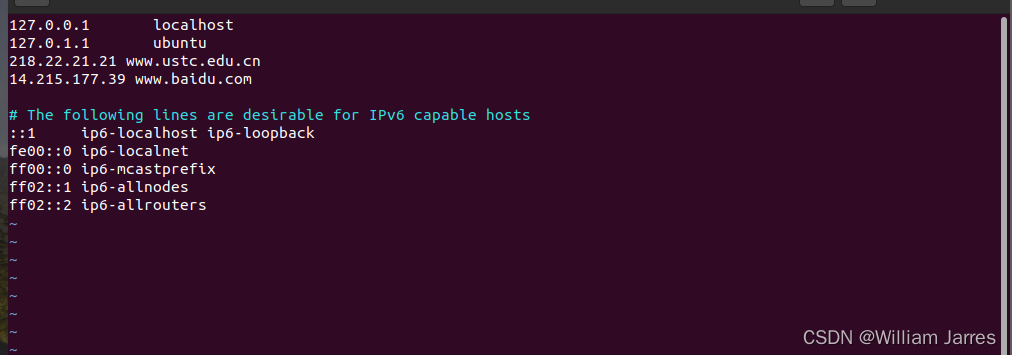
7、跟踪调试Linux内核网络代码
下面具体看看如何使用 gdb 跟踪调试 Linux 内核网络代码。使用 gdb 跟踪调试内核,加两个参数,一个是-s,意思是在 TCP 1234 端口上创建了一个 gdb-server。可以另外打开一个窗口,用 gdb 把带有符号表的内核镜像 vmlinux 加载进来,然后连接 gdb server,设置断点跟踪内核。若不想使用 1234 端口,可以使用-gdb tcp:xxxx 来替代-s 选项),另一个是-S 代表启动时暂停虚拟机,等待 gdb 执行 continue 指令(可以简写为 c)。
# 窗口环境下启动QEMU虚拟机
qemu-system-x86_64 -kernel linux-5.4.34/arch/x86/boot/bzImage -initrd rootfs.cpio.gz -S -s
# 纯命令行下启动QEMU虚拟机
qemu-system-x86_64 -kernel /home/mengning/linux-code/linux-5.4.34/arch/x86/boot/bzImage -initrd ../rootfs.cpio.gz -S -s -nographic -append "console=ttyS0"
由于我的linux-5.4.34、roofts都在桌面,所以指令改为
qemu-system-x86_64 -kernel linux-5.4.34/arch/x86/boot/bzImage -initrd rootfs.cpio.gz -S -s -nographic -append "console=ttyS0"
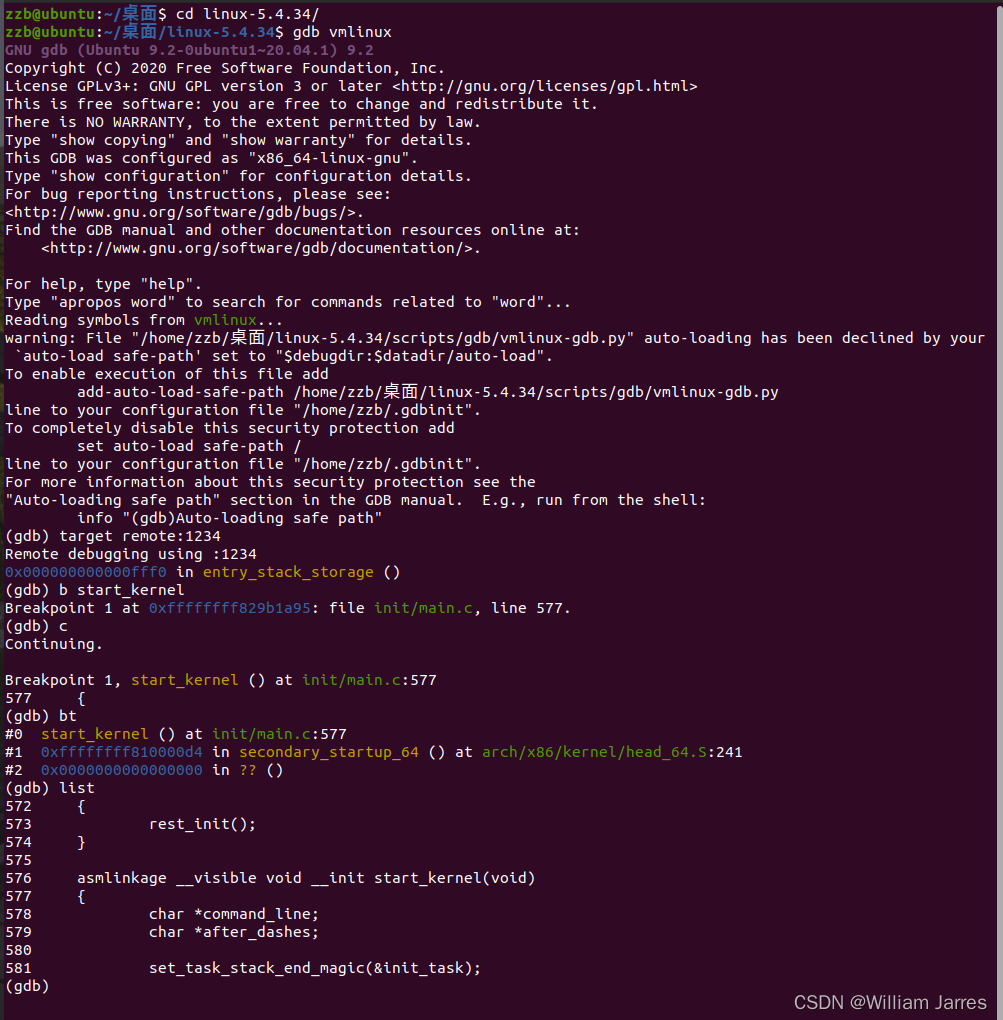
再打开一个窗口,启动 gdb vmlinux,或进入gdb命令行后使用file vmlinux把内核符号表加载进来,然后通过target remote:1234建立连接。
cd linux-5.4.34/
gdb vmlinux
...
(gdb) target remote:1234
Remote debugging using :1234
0x000000000000fff0 in entry_stack_storage ()
(gdb) b start_kernel
Breakpoint 1 at 0xffffffff829aeabb: file init/main.c, line 577.
(gdb) c
Continuing.
Breakpoint 1, start_kernel () at init/main.c:577
577 {
(gdb) bt
#0 start_kernel () at init/main.c:577
#1 0xffffffff810000d4 in secondary_startup_64 ()
at arch/x86/kernel/head_64.S:241
#2 0x0000000000000000 in ?? ()
(gdb) list
572 {
573 rest_init();
574 }
575
576 asmlinkage __visible void __init start_kernel(void)
577 {
578 char *command_line;
579 char *after_dashes;
580
581 set_task_stack_end_magic(&init_task);
(gdb
三、问题分析
1、inet_init是如何被调用的?从start_kernel到inet_init调用路径
从调用栈中,我们可以看到调用链:
kernel_init()
|
kernel_init_freeable()
|
do_basic_setup()
|
do_initcalls()
|
do_initcall_level()
|
do_one_initcall()
|
inet_init()
从下向上进行分析:
(1)do_one_initcall()调用inet_init():在 init/main.c 文件中,有一个 do_one_initcall 函数, 它接受一个函数指针作为参数,并调用该函数。
(2) do_initcall_level()调用 do_one_initcall():do_initcall_level 函数用于执行一个特定级别的初始化函数,该级别由 level 参数指定。
(3)do_initcalls()调用do_initcall_level():do_initcalls 函数负责按照预定义的顺序执行不同级别的初始化函数,其中包括 device_initcall、early_initcall、core_initcall 等。
(4)do_basic_setup()调用do_initcalls():do_basic_setup 是 Linux 内核启动的一个基本设置阶段。
2、跟踪分析TCP/IP协议栈如何将自己与上层套接口与下层数据链路层关联起来的?
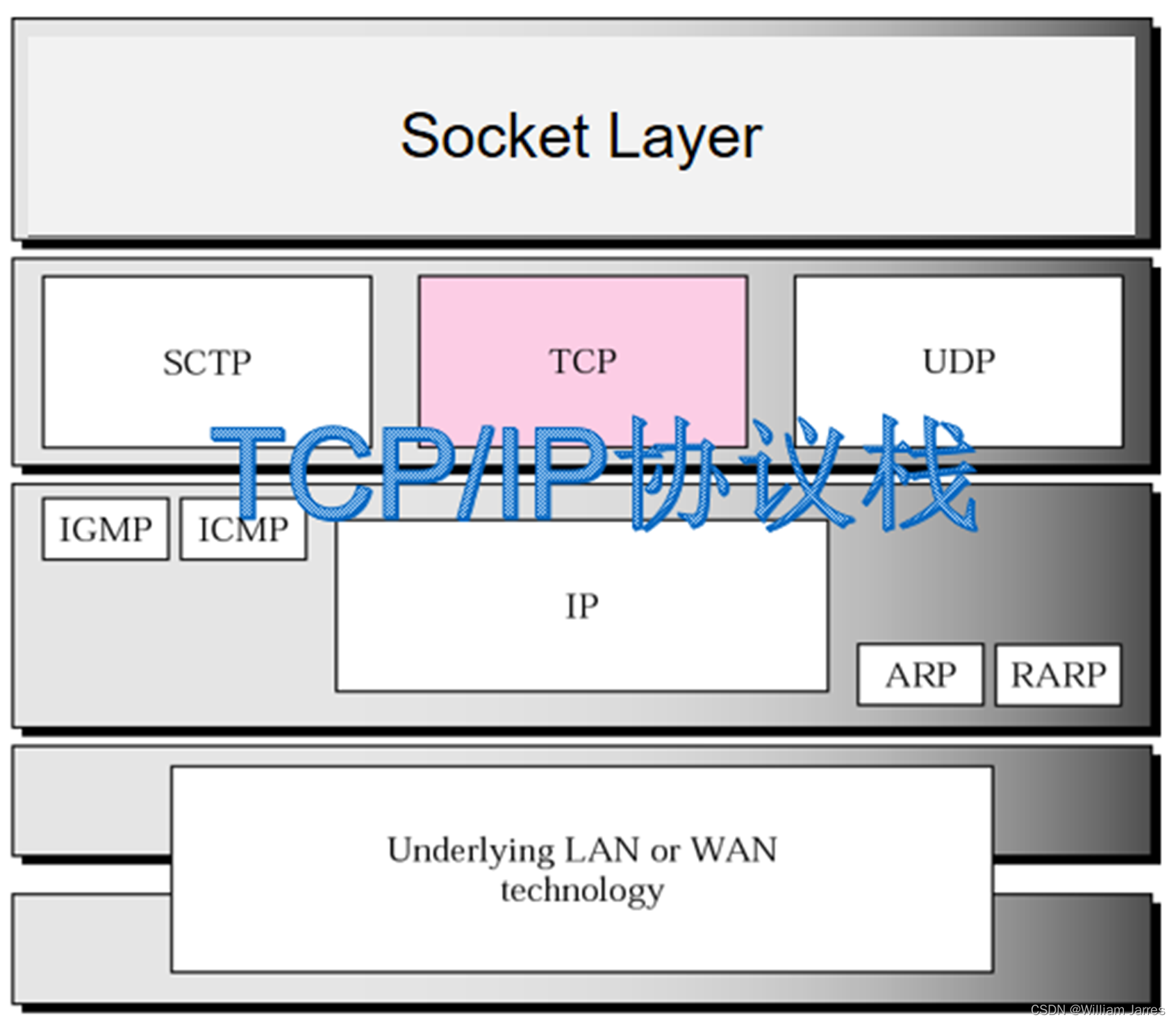
网络协议层次如图,TCP/IP协议栈通过使用套接口(Socket)来与上层应用程序关联,而与下层数据链路层关联则通过网络接口卡(NIC)和驱动程序来实现。
在Linux内核中,TCP/IP协议栈是通过注册回调函数的方式与上层套接口和下层数据链路层相关联的。当上层套接口需要发送或接收数据时,它会调用协议栈的回调函数。反过来,协议栈也会注册自身的回调函数,以便在数据链路层接收到数据时,能够正确地处理。这种关联方式使得协议栈能够与上层套接口和下层数据链路层进行互动,完成数据的发送和接收。
3、TCP的三次握手源代码跟踪分析,跟踪找出设置和发送SYN/ACK的位置,以及状态转换的位置
从用户程序的角度看,tcp三次握手就是客户端和服务端要建立起连接所完成的工作,在内核socket接口层这两个socket API函数对应着sys_connect和sys_accept函数,进一步对应着sock->opt->connect和sock->opt->accept两个函数指针,这两个函数指针对应着tcp_v4_connect函数和inet_csk_accept函数。
tcp_v4_connect函数的主要作用就是发起一个TCP连接,它调用了IP层提供的一些服务,比如ip_route_connect和ip_route_newports,并设置了 TCP_SYN_SENT,进一步调用了tcp_connect(sk)来构造SYN然后发送出去。tcp_connect负责构造一个携带SYN标志位的TCP头并发送,同时还设置了计时器超时重发。
服务端调用inet_csk_accept会从请求队列中取出一个连接请求,如果队列为空则通过inet_csk_wait_for_connect阻塞住等待客户端的连接。connect之后将连接请求发送出去,accept等待连接请求,connect启动到返回和accept返回之间就是三次握手的时间。
inet_init函数完成TCP/IP协议栈的初始化过程,其中有tcp_protocol结构体变量,tcp_protocol的handler被赋值为tcp_v4_rcv。接收TCP连接请求及进行三次握手处理过程也是在这里为起点,从tcp_v4_rcv能够找到对SYN/ACK标志的处理(三次握手),连接请求建立后并将连接放入accept的等待队列。
三次握手中的第一次握手在客户端的层面完成,报文到达服务端,由服务端处理完毕后,第一次握手完成,客户端socket状态变为TCP_SYN_SENT。下面我看服务端的处理。
数据到达网卡的时候,TCP协议要经过这个一个调用链:
网卡驱动 → netif_receive_skb() → ip_rcv() → ip_local_deliver_finish() → tcp_v4_rcv()
数据到达客户端网卡,经过以下调用链:
网卡驱动 → netif_receive_skb() → ip_rcv() → ip_local_deliver_finish() → tcp_v4_rcv() → tcp_v4_do_rcv(),客户端socket的状态为TCP_SYN_SENT,所以直接进入tcp_rcv_state_process,接着延时发送或立即发送确认ack,直接发送确认ack,调用tcp_send_ack,构造报文,再交给网络层发送,第二次握手完成,客户端sock状态变为TCP_ESTABLISHED,第三次握手开始。
之前服务端的sock的状态为TCP_NEW_SYN_RECV,报文到达网卡经过以下调用链:网卡驱动 → netif_receive_skb() → ip_rcv() → ip_local_deliver_finish() → tcp_v4_rcv(),完成第三次握手。
4、send在TCP/IP协议栈中的执行路径
(1)应用层
网络应用调用Socket API socket创建一个 socket,最终调用 sock_create() 方法,返回被创建好了的那个 socket 的 描述符。
对于 TCP socket ,应用调用 connect()函数,使客户端和服务器端通过该 socket 建立一个连接。建立连接之后然后可以调用send函数发出一个 message 给接收端。sock_sendmsg 被调用,调用相应协议的发送函数。
(2)传输层
先调用tcp_sendmsg 函数,把用户层的数据填充到skb中。在tcp_sendmsg_locked中,将数据整理成发送队列,数据创建之后调用tcp_push()来发送,tcp_push函数调用tcp_write_xmit()函数,将调用发送函数tcp_transmit_skb,所有的SKB都经过该函数进行发送。最后进入到ip_queue_xmit到网络层。
(3)网络层
ip_queue_xmit(skb)会检查skb->dst路由信息,如果没有则使用ip_route_output()选择一个路由。填充IP包的各个字段,比如版本、包头长度、TOS等。ip_fragment 函数进行分片,会检查 IP_DF 标志位,如果待分片IP数据包禁止分片,则调用 icmp_send()向发送方发不可达ICMP报文,并丢弃报文,即设置IP状态为分片失败,释放skb,返回消息过长错误码。
(4)数据链路层
数据链路层在不可靠的物理介质上提供可靠的传输。该层的作用包括:物理地址寻址、数据的成帧、流量控制、数据的检错、重发等。从dev_queue_xmit函数开始,位于net/core/dev.c文件中。
5、recv在TCP/IP协议栈中的执行路径
(1)应用层
应用调用 read 或者 recvfrom 时,该调用会被映射为/net/socket.c 中的 sys_recv 系统调用,并被转化为 sys_recvfrom 调用,然后调用 sock_recgmsg 函数。
TCP 调用 tcp_recvmsg。该函数从 socket buffer 中拷贝数据到 user buffer。
(2)传输层
tcp_v4_rcv函数为TCP的总入口,数据包从IP层传递上来,进入该函数,其中handler设置为tcp_v4_rcv,tcp_v4_rcv函数作用:设置TCP_CB、 查找控制块、根据控制块状态做不同处理,包括TCP_TIME_WAIT状态处理,TCP_NEW_SYN_RECV状态处理、TCP_LISTEN状态处理、接收TCP段
(3)网络层
IP层的入口函数在 ip_rcv 函数,然后 packet 调用已经注册的 Pre-routing netfilter hook ,完成后最终到达 ip_rcv_finish 函数。
ip_rcv_finish 函数会调用ip_route_input函数,进入路由处理环节。会调用 ip_route_input 来更新路由,然后查找 route,决定该会被发到本机还是会被转发还是丢弃。如果是发到本机的话,调用 ip_local_deliver 函数,可能会做 de-fragment,然后调用 ip_local_deliver 函数。如果需要转发 ,则进入转发流程,调用 dst_input 函数。
(4)链路层
物理网络适配器接收到数据帧时,会触发一个中断,并将通过 DMA 传送到位于 linux kernel 内存中的 rx_ring。终端处理程序经过简单处理后,发出一个软中断,通知内核接收到新的数据帧,进入软中断处理流程,调用 net_rx_action 函数。包从 rx_ring 中被删除,进入 netif _receive_skb ,netif_receive_skb根据注册在全局数组 ptype_all 和 ptype_base 里的网络层数据报类型,把数据报递交给不同的网络层协议的接收函数。
6、路由表的结构和初始化过程
在linux的路由系统主要保存了三种与路由相关的数据:
(1)neighbour结构:neighbour_table是一个包含和本机所连接的所有邻元素的信息的数据结构。该结构中有个元素是neighbour结构的数组,数组的每一个元素都是一个对应于邻机的neighbour结构,系统中由于协议的不同,会有不同的判断邻居的方式,每种都有neighbour_table{}类型的实例。在neighbour结构中,包含有与该邻居相连的网络接口设备net_device的指针,网络接口的硬件地址,邻居的硬件地址。
(2)FIB结构 在FIB中保存的是最重要的路由规则,通过对FIB数据的查找和换算,能够获得路由一个地址的方法。
(3)route结构:包含struct rtentry{ }、struct fib_table{ }
7、通过目的IP查询路由表的到下一跳的IP地址的过程
通过目的IP查询路由表的到下一跳的IP地址的过程,fib_lookup为起点。调用过fib_lookup后,函数会根据查找的结构进行不同的处理。一般情况是转发或者本地,这两种的情况都会先分配一个新的路由缓存结点,填充适当的值然后插入到缓存中。fib_lookup函数是路由策略数据库的查询接口,它首先查找策略表,找到一条匹配的策略,然后再查找对应的一张路由表,接下来会调用fn_hash_lookup函数进行处理。
8、ARP缓存的数据结构及初始化过程,包括ARP缓存的初始化
ARP缓存的数据结构主要涉及到 struct neighbour 结构和相关函数。ARP缓存用于存储IP地址到MAC地址的映射关系,以提高数据包的转发效率。
struct neighbour {
struct neighbour __rcu *next; // 指向下一个邻居项的指针,通过 RCU 机制进行管理
struct neigh_table *tbl; // 指向邻居表的指针,表示该邻居项所属的邻居表
struct neigh_parms *parms; // 指向邻居参数的指针,表示邻居项的参数
unsigned long confirmed; // 上一次确认邻居项的时间戳
unsigned long updated; // 上一次更新邻居项的时间戳
rwlock_t lock; // 读写自旋锁,用于对邻居项的并发访问进行保护
refcount_t refcnt; // 引用计数,用于跟踪邻居项的引用情况
unsigned int arp_queue_len_bytes; // ARP 队列长度的字节数
struct sk_buff_head arp_queue; // 用于存储 ARP 队列的 sk_buff_head 结构
struct timer_list timer; // 定时器,用于邻居项的定时操作,例如垃圾回收
unsigned long used; // 上一次使用邻居项的时间戳
atomic_t probes; // 邻居项的探测次数
__u8 flags; // 一些标志位,用于表示邻居项的状态
__u8 nud_state; // 邻居项的 NUD(Neighbor Unreachability Detection)状态
__u8 type; // 邻居项的类型
__u8 dead; // 用于标记邻居项是否已经过期
u8 protocol; // 表示邻居项所使用的网络协议
seqlock_t ha_lock; // 用于对硬件地址进行加锁的序列化锁
unsigned char ha[ALIGN(MAX_ADDR_LEN, sizeof(unsigned long))] __aligned(8); // 存储硬件地址(MAC 地址)的数组
struct hh_cache hh; // 用于存储硬件地址缓存的 hh_cache 结构
int (*output)(struct neighbour *, struct sk_buff *); // 输出操作的函数指针
const struct neigh_ops *ops; // 指向邻居操作的指针,包含了处理邻居项的函数
struct list_head gc_list; // 用于连接到垃圾回收列表的链表节点
struct rcu_head rcu; // RCU 头,用于进行 RCU 回收
struct net_device *dev; // 指向网络设备的指针,表示邻居项所属的网络设备
u8 primary_key[0]; // 一个零长度的数组,用于存储主键
} __randomize_layout; // 随机化布局,增强安全性
arp_init函数进行ARP缓存的数据结构及初始化过程
void __init arp_init(void)
{
// 初始化 ARP 表
neigh_table_init(NEIGH_ARP_TABLE, &arp_tbl);
// 向网络设备协议栈中添加 ARP 数据包处理函数
dev_add_pack(&arp_packet_type);
// 初始化 ARP 过程中的 proc 文件系统相关内容
arp_proc_init();
#ifdef CONFIG_SYSCTL
// 注册 sysctl 参数,允许用户配置 ARP 相关参数
neigh_sysctl_register(NULL, &arp_tbl.parms, NULL);
#endif
// 注册网络设备事件通知,用于监测网络设备状态的变化
register_netdevice_notifier(&arp_netdev_notifier);
}
9、如何将IP地址解析出对应的MAC地址
在TCP/IP协议栈中,将IP地址解析出对应的MAC地址是通过ARP协议来实现的。具体步骤如下:
(1)当主机需要与另一个主机通信时,它首先会在ARP缓存中查找目标IP地址对应的MAC地址。如果找到了匹配的MAC地址,则直接使用该MAC地址进行通信。
(2)如果在ARP缓存中没有找到匹配的MAC地址,则主机会在网络上发送一个ARP请求包,询问目标IP地址对应的MAC地址。
收到ARP请求包的目标主机会发送一个ARP响应包,其中包含了自身的MAC地址。主机接收到ARP响应包后,将其添加到ARP缓存中,并使用该MAC地址进行通信。
(3)如果在一定时间内没有收到ARP响应包,主机可能会重发ARP请求包或放弃等待并使用默认的MAC地址进行通信。在Linux内核中,这个过程可以通过调用dev_mc_sync函数来实现。该函数会同步ARP缓存和MAC地址表,确保ARP缓存中的MAC地址是最新的。同时,当收到ARP请求或响应包时,也会更新ARP缓存中的内容。
10、跟踪TCP send过程中的路由查询和ARP解析的最底层实现
(1)TCP发送过程中的路由查询是通过调用fib_lookup函数实现的。该函数会遍历路由表并根据目的IP地址查找最佳的路由路径。在查找过程中,会考虑多种因素,如目标网络的掩码长度、路径的成本等。最终选择一条最佳的路由路径用于数据包的发送。
(2)ARP解析是TCP发送过程中的重要步骤之一。当需要将目的IP地址解析为MAC地址时,协议栈会向网络上发送一个ARP请求包。该请求包包含了发送者的IP地址和MAC地址信息,以及目的IP地址。当收到ARP响应包时,协议栈会将响应包中的MAC地址保存到ARP缓存中,以便后续使用。在ARP缓存中,IP地址和MAC地址的对应关系被保存在struct neighbour结构体中。当需要将IP地址解析为MAC地址时,协议栈会首先检查ARP缓存中是否存在对应的记录,如果存在则直接返回MAC地址;如果不存在,则会发送ARP请求包进行解析。
(3)在TCP发送过程中,路由查询和ARP解析的实现细节涉及到了多个关键函数和数据结构。例如,fib_lookup函数用于路由表的查询;arp_send函数用于发送ARP请求包;arp_rcv函数用于处理收到的ARP响应包等。这些函数和数据结构共同协作,实现了TCP发送过程中路由查询和ARP解析的最底层机制。
四、总结
首先非常感谢孟老师,孟老师真的是一个很幽默、很有才华的老师,在孟老师的课堂上学到了很多关于网络程序设计的知识,收获颇丰。其次感谢我的同学们,他们给了很多实验上的帮助,让我顺利完成了相关实验。最后感谢提供TCP/IP协议栈相关资料的全体开发者们,让我在遇到问题时提供一些思路。
在此,我再次表示我真挚的谢意!















 1151
1151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









