









 文章介绍了如何使用Python解析GPX运动轨迹文件,计算基础运动速度,并将结果格式化为SRT字幕。通过读取GPX文件中的时间、距离等信息,计算瞬时速度,然后按照SRT字幕格式进行编码,生成可用于视频的运动数据字幕。整个过程无需额外安装第三方库,且涉及到了文本处理和时间格式转换的知识。
文章介绍了如何使用Python解析GPX运动轨迹文件,计算基础运动速度,并将结果格式化为SRT字幕。通过读取GPX文件中的时间、距离等信息,计算瞬时速度,然后按照SRT字幕格式进行编码,生成可用于视频的运动数据字幕。整个过程无需额外安装第三方库,且涉及到了文本处理和时间格式转换的知识。
【Python文本处理】基于运动路线记录GPX文件的基础运动速度求解,并转为SRT字幕格式(不需要安装三方库)
解析
GPX文件格式
GPX文件本身其实就是坐标、海拔、时间、心率等综合性的xml文件
如图:
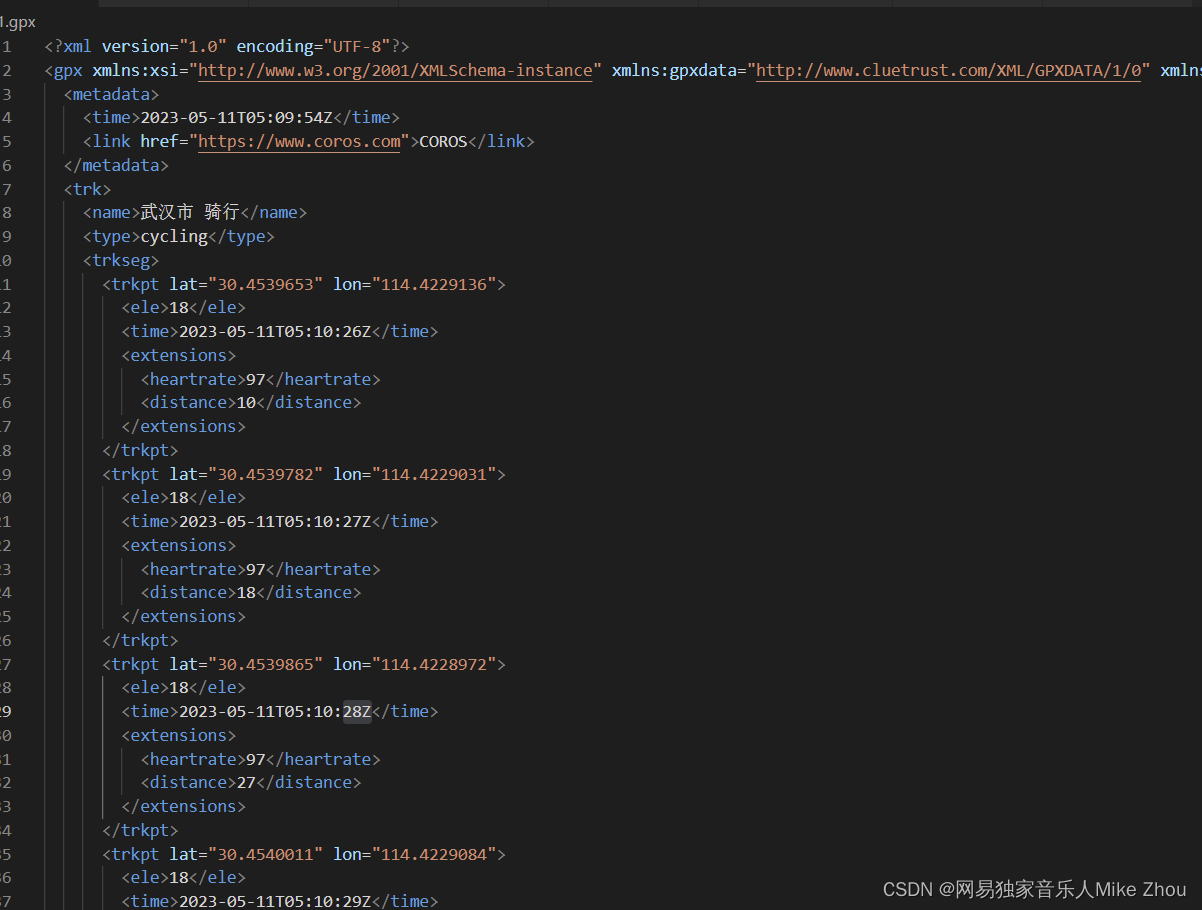
海拔:ele
时间:time
心率:heartrate
功率:power
踏频:cadence
距离:distance
一般不用距离distance 但可以根据距离求瞬时速度(前提是时间间隔均匀 最小精度不低于1s) 不过如果距离和坐标之差相差太远 则不太好确定 Strava等软件通过这个来计算瞬时速度和距离 但不用于计算赛段速度(赛段时间)
某一时刻的数据就看trkpt部分
以trkpt 为始 到 /trkpt 为止
比如:
<trkpt lat="30.3940883" lon="112.2400167">
<ele>34</ele>
<time>2023-05-12T12:26:13Z</time>
<extensions>
<heartrate>167</heartrate>
<distance>26698</distance>
</extensions>
</trkpt>
SRT基本格式
SRT字幕通常以srt作为后缀,作为外挂字幕,多数主流播放器都支持直接加载并显示SRT字幕,具体细节看参考SubRip (.SRT) subtitles support in players。
该格式是基于纯文本的格式,使用CR+LF作为换行符(Windows下常用换行符,*nix使用LF作为换行符)。每个SRT文件包含至少一个字幕段。
每个字幕段有四部分构成:
字幕序号
字幕显示的起始时间
字幕内容(可多行)
空白行(表示本字幕段的结束)
其中字幕序号一般是顺序增加的,表示字幕是一系列连续的序列。但该数值在字幕显示中不起任何作用,只是起着标记和标识的作用,方便分配翻译行数用。字幕序号的值可以随意,1和100都一样,并不会影响字幕的显示。但字幕序号也是字幕段的一部分,所以不能没有或者删去,否则在播放时,将出现错误。
字幕显示起始时间的格式如下:
hour:minute:second.millisecond --> hour:minute:second.millisecond 或
hour:minute:second,millisecond --> hour:minute:second,millisecond
后面还可以附加用于指定字幕显示位置的信息,以像素为单位,格式如下: X1:number Y1:number X2:number Y2:number。
一个典型的SRT文件如下(截取自阿凡达中英字幕):
3
00:00:39,770 --> 00:00:41,880
在经历了一场人生巨变之后
When I was lying there in the VA hospital ...
4
00:00:42,550 --> 00:00:44,690
我被送进了退伍军人管理局医院
... with a big hole blown through the middle of my life,
5
00:00:45,590 --> 00:00:48,120
那段时间我经常会梦到自己在飞翔
... I started having these dreams of flying.
6
00:00:49,740 --> 00:00:51,520
终获自由
I was free.
7
00:00:54,620 --> 00:00:55,830
而不幸的是
Sooner or later though, ...
SRT格式化设置
多数SRT支持一些特定格式化,比如斜体、粗体、下划线以及字体颜色。使用时需要基于HTML的标签,具体用法如下:
颜色
字体斜体
字体下加划线
换行
字体加粗
这些HTML可嵌套。
<font color=red>颜色</font>
<i>字体斜体</i>
<u>字体下加划线</u>
<br>换行
<b>字体加粗</b>
当然某些播放器还对SRT做了扩展,可以支持ASS/SSA中部分格式化代码。
代码实现
首先需要获取第一次开始的时间参数:
try:
ti=str((gpx[i].split("<time>")[1]).split("</time>")[0])
now_time = time.mktime(time.strptime(ti, "%Y-%m-%dT%H:%M:%SZ"))
first_time=now_time
srt_time=0
str_now_time=time.strftime("<i>%Y-%m-%d %H:%M:%S</i>\n",time.localtime(now_time))
srt=str(j)+"\n00:00:00,000 --> 00:00:01,000\n"+str_now_time+"<u>BEGIN</u>\n\n"
srt_list.append(srt)
break
except:
pass
以及每个时刻的时间参数:
try:
ti=str((gpx[i].split("<time>")[1]).split("</time>")[0])
now_time = time.mktime(time.strptime(ti, "%Y-%m-%dT%H:%M:%SZ"))
srt_time=now_time-first_time
h=int(srt_time/3600)
m=int(srt_time/60)
s=int(srt_time%60)
s2=s+1
h=trans_time(h)
m=trans_time(m)
s=trans_time(s)
s2=trans_time(s2)
srt_str_time=str(h+":"+m+":"+s+",000 --> "+h+":"+m+":"+s2+",000\n")
str_now_time=time.strftime("<i>%Y-%m-%d %H:%M:%S</i>\n",time.localtime(now_time))
srt=srt+str_now_time
except:
pass
这里用到了一个时间格式转换:
def trans_time(st):
if st<10 and st>=0:
st="0"+str(st)
else:
st=str(st)
return str(st)
在解析时 用trkpt_flag状态机表示某一时刻的数据有效性状态:
if gpx[i].count('<trkpt'):
trkpt_flag=1
trkpt_first_flag=1
j=j+1
同理 还有trkpt_first_flag 表示第一次获取到trkpt
检测到/trkpt时表示该时刻数据获取结束
if gpx[i].count('</trkpt>'):
trkpt_flag=0
检测到/trkseg时 表示所有数据获取结束
if gpx[i].count('</trkseg>'):
j=j+1
trkpt_first_flag=2
当trkpt_first_flag 为1 trkpt_flag为0时 进行数据保存:
if trkpt_first_flag==1 and trkpt_flag==0:
if not srt=="":
last_srt_time=int(srt_time)
last_distance=int(dat)
srt=str(j)+"\n"+srt_str_time+srt+"\n"
srt_list.append(srt)
srt=""
last_distance 和 last_srt_time用于配合distance计算瞬时速度
了解这些以后 我们再来进行数据解析
经纬度获取:
if gpx[i].count('<trkpt'):
srt=srt+"lat:"+gpx[i].split('"')[1]+" lon:"+gpx[i].split('"')[3]+"\n"
海拔
try:
el=str((gpx[i].split("<ele>")[1]).split("</ele>")[0])
srt=srt+"ele:"+el+"\n"
except:
pass
关键词获取 其中 当获取到distance时 进行瞬时速度计算
for key in keywords_list:
try:
dat=str((gpx[i].split("<"+key+">")[1]).split("</"+key+">")[0])
srt=srt+"<i>"+key+":"+dat+"</i>\n"
if key=="distance":
velocity_time=srt_time-last_srt_time
velocity=(int(dat)-last_distance)/velocity_time*3.6
srt=srt+"<b>"+"velocity"+":"+str(velocity)+"</b>\n"
except:
pass
最后一个时刻后 再加一行字幕
if trkpt_first_flag==2:
h=int((last_srt_time+1)/3600)
m=int((last_srt_time+1)/60)
s=int((last_srt_time+1)%60)
s2=s+1
h=trans_time(h)
m=trans_time(m)
s=trans_time(s)
s2=trans_time(s2)
srt_str_time=str(h+":"+m+":"+s+",000 --> "+h+":"+m+":"+s2+",000\n")
srt=str(j)+"\n"+srt_str_time+"<u>END</u>\n"+"\n"
srt_list.append(srt)
srt=""
break
整体代码:
# -*- coding: utf-8 -*-
"""
Created on Thu Jun 1 14:23:10 2023
@author: ZHOU
"""
import time
'''data keywords
心率 "heartrate"
踏频 "cadence"
距离 "distance"
功率 "power"
'''
def trans_time(st):
if st<10 and st>=0:
st="0"+str(st)
else:
st=str(st)
return str(st)
def gpx_to_srt(gpx):
keywords_list=["heartrate","cadence","power","distance"]
srt_list=[]
first_time=0
srt_time=0
srt=""
j=1
trkpt_flag=0
trkpt_first_flag=0
for i in range(len(gpx)):
try:
ti=str((gpx[i].split("<time>")[1]).split("</time>")[0])
now_time = time.mktime(time.strptime(ti, "%Y-%m-%dT%H:%M:%SZ"))
first_time=now_time
srt_time=0
str_now_time=time.strftime("<i>%Y-%m-%d %H:%M:%S</i>\n",time.localtime(now_time))
srt=str(j)+"\n00:00:00,000 --> 00:00:01,000\n"+str_now_time+"<u>BEGIN</u>\n\n"
srt_list.append(srt)
break
except:
pass
srt=""
srt_str_time=""
last_distance=0
srt_time=0
last_srt_time=0
for i in range(len(gpx)):
if gpx[i].count('<trkpt'):
trkpt_flag=1
trkpt_first_flag=1
j=j+1
if trkpt_flag==1:
try:
ti=str((gpx[i].split("<time>")[1]).split("</time>")[0])
now_time = time.mktime(time.strptime(ti, "%Y-%m-%dT%H:%M:%SZ"))
srt_time=now_time-first_time
h=int(srt_time/3600)
m=int(srt_time/60)
s=int(srt_time%60)
s2=s+1
h=trans_time(h)
m=trans_time(m)
s=trans_time(s)
s2=trans_time(s2)
srt_str_time=str(h+":"+m+":"+s+",000 --> "+h+":"+m+":"+s2+",000\n")
str_now_time=time.strftime("<i>%Y-%m-%d %H:%M:%S</i>\n",time.localtime(now_time))
srt=srt+str_now_time
except:
pass
if gpx[i].count('<trkpt'):
srt=srt+"lat:"+gpx[i].split('"')[1]+" lon:"+gpx[i].split('"')[3]+"\n"
try:
el=str((gpx[i].split("<ele>")[1]).split("</ele>")[0])
srt=srt+"ele:"+el+"\n"
except:
pass
for key in keywords_list:
try:
dat=str((gpx[i].split("<"+key+">")[1]).split("</"+key+">")[0])
srt=srt+"<i>"+key+":"+dat+"</i>\n"
if key=="distance":
velocity_time=srt_time-last_srt_time
velocity=(int(dat)-last_distance)/velocity_time*3.6
srt=srt+"<b>"+"velocity"+":"+str(velocity)+"</b>\n"
except:
pass
if gpx[i].count('</trkpt>'):
trkpt_flag=0
if trkpt_first_flag==1 and trkpt_flag==0:
if not srt=="":
last_srt_time=int(srt_time)
last_distance=int(dat)
srt=str(j)+"\n"+srt_str_time+srt+"\n"
srt_list.append(srt)
srt=""
if gpx[i].count('</trkseg>'):
j=j+1
trkpt_first_flag=2
if trkpt_first_flag==2:
h=int((last_srt_time+1)/3600)
m=int((last_srt_time+1)/60)
s=int((last_srt_time+1)%60)
s2=s+1
h=trans_time(h)
m=trans_time(m)
s=trans_time(s)
s2=trans_time(s2)
srt_str_time=str(h+":"+m+":"+s+",000 --> "+h+":"+m+":"+s2+",000\n")
srt=str(j)+"\n"+srt_str_time+"<u>END</u>\n"+"\n"
srt_list.append(srt)
srt=""
break
return srt_list
def save_lines(lines,path):
try:
f=open(path, 'w', encoding="utf-8")
except:
f=open(path, 'a', encoding="utf-8")
for i in lines:
f.write(i)
f.close()
if __name__ == '__main__':
path="./1.gpx"
f=open(path, 'r', encoding="utf-8")
gpx=f.readlines()
f.close()
gpx=gpx_to_srt(gpx)
save_lines(gpx,"srt_test.srt")
若有不明白的 可以联系上下文一起看
GUI界面编程
附录:列表的赋值类型和py打包
列表赋值
BUG复现
闲来无事写了个小程序 代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
c_list[j]=a_list
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
#print(c_list,'\n')
我在程序中 做了一个16次的for循环 把列表a的每个值后面依次加上"_"和循环序号
比如循环第x次 就是把第x位加上_x 这一位变成x_x 我在输出测试中 列表a的每一次输出也是对的
循环16次后列表a应该变成[‘0_0’, ‘1_1’, ‘2_2’, ‘3_3’, ‘4_4’, ‘5_5’, ‘6_6’, ‘7_7’, ‘8_8’, ‘9_9’, ‘10_10’, ‘11_11’, ‘12_12’, ‘13_13’, ‘14_14’, ‘15_15’] 这也是对的
同时 我将每一次循环时列表a的值 写入到空列表c中 比如第x次循环 就是把更改以后的列表a的值 写入到列表c的第x位
第0次循环后 c[0]的值应该是[‘0_0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘10’, ‘11’, ‘12’, ‘13’, ‘14’, ‘15’] 这也是对的
但是在第1次循环以后 c[0]的值就一直在变 变成了c[x]的值
相当于把c_list[0]变成了c_list[1]…以此类推 最后得出的列表c的值也是每一项完全一样
我不明白这是怎么回事
我的c[0]只在第0次循环时被赋值了 但是后面它的值跟着在改变
如图:

第一次老出bug 赋值以后 每次循环都改变c[0]的值 搞了半天都没搞出来
无论是用appen函数添加 还是用二维数组定义 或者增加第三个空数组来过渡 都无法解决
代码改进
后来在我华科同学的指导下 突然想到赋值可以赋的是个地址 地址里面的值一直变化 导致赋值也一直变化 于是用第二张图的循环套循环深度复制实现了
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
for i in range(16):
c_list[j].append(a_list[i])
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
print(c_list,'\n')
解决了问题

优化
第三次是请教了老师 用copy函数来赋真值
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
c_list[j]=a_list.copy()
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
#print(c_list,'\n')
同样能解决问题

最后得出问题 就是指针惹的祸!
a_list指向的是个地址 而不是值 a_list[i]指向的才是单个的值 copy()函数也是复制值而不是地址
如果这个用C语言来写 就直观一些了 难怪C语言是基础 光学Python不学C 遇到这样的问题就解决不了
C语言yyds Python是什么垃圾弱智语言
总结
由于Python无法单独定义一个值为指针或者独立的值 所以只能用列表来传送
只要赋值是指向一个列表整体的 那么就是指向的一个指针内存地址 解决方法只有一个 那就是将每个值深度复制赋值(子列表内的元素提取出来重新依次连接) 或者用copy函数单独赋值
如图测试:





部分代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 20 16:45:48 2021
@author: 16016
"""
def text1():
A=[1,2,3]
B=[[],[],[]]
for i in range(len(A)):
A[i]=A[i]+i
B[i]=A
print(B)
def text2():
A=[1,2,3]
B=[[],[],[]]
A[0]=A[0]+0
B[0]=A
print(B)
A[1]=A[1]+1
B[1]=A
print(B)
A[2]=A[2]+2
B[2]=A
print(B)
if __name__ == '__main__':
text1()
print('\n')
text2()
py打包
Pyinstaller打包exe(包括打包资源文件 绝不出错版)
依赖包及其对应的版本号
PyQt5 5.10.1
PyQt5-Qt5 5.15.2
PyQt5-sip 12.9.0
pyinstaller 4.5.1
pyinstaller-hooks-contrib 2021.3
Pyinstaller -F setup.py 打包exe
Pyinstaller -F -w setup.py 不带控制台的打包
Pyinstaller -F -i xx.ico setup.py 打包指定exe图标打包
打包exe参数说明:
-F:打包后只生成单个exe格式文件;
-D:默认选项,创建一个目录,包含exe文件以及大量依赖文件;
-c:默认选项,使用控制台(就是类似cmd的黑框);
-w:不使用控制台;
-p:添加搜索路径,让其找到对应的库;
-i:改变生成程序的icon图标。
如果要打包资源文件
则需要对代码中的路径进行转换处理
另外要注意的是 如果要打包资源文件 则py程序里面的路径要从./xxx/yy换成xxx/yy 并且进行路径转换
但如果不打包资源文件的话 最好路径还是用作./xxx/yy 并且不进行路径转换
def get_resource_path(relative_path):
if hasattr(sys, '_MEIPASS'):
return os.path.join(sys._MEIPASS, relative_path)
return os.path.join(os.path.abspath("."), relative_path)
而后再spec文件中的datas部分加入目录
如:
a = Analysis(['cxk.py'],
pathex=['D:\\Python Test\\cxk'],
binaries=[],
datas=[('root','root')],
hiddenimports=[],
hookspath=[],
hooksconfig={},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
而后直接Pyinstaller -F setup.spec即可
如果打包的文件过大则更改spec文件中的excludes 把不需要的库写进去(但是已经在环境中安装了的)就行
这些不要了的库在上一次编译时的shell里面输出
比如:


然后用pyinstaller --clean -F 某某.spec



















 1990
1990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











