






【旧文更新】基于Python的百度AI人脸识别API接口(可用于OpenCV-Python人脸识别)
关于旧文新发
为何要进行旧文新发?
因为我在2023年博客之星评选中发现 有的人转载、抄袭他人文章 稍微改动几下也能作为高质量文章入选
所以我将把我的旧文重新发一次 然后也这样做
2023年博客之星规则:

百度API
资源:
download.csdn.net/download/weixin_53403301/43644312
之前的项目:
【最新】基于OpenCV的Python人脸识别、检测、框选(遍历目录下所有照片依次识别 视频随时标注)
blog.csdn.net/weixin_53403301/article/details/119422635
基于OpenCV-Python的树莓派人脸识别及89C52单片机控制系统设计(指定照片进行识别、遍历目录下所有照片依次识别)
blog.csdn.net/weixin_53403301/article/details/118575731
直接上代码:
# -*- coding: utf-8 -*-
"""
Created on Mon May 31 23:40:16 2021
@author: ZHOU
"""
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import requests # 调用 requests的HTTP协议库
import os # 调用os多操作系统接口库
import base64 # 调用base64编码库
import json # 调用JavaScript Object Notation数据交换格式
ACCESS_TOKEN = ''
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) #去掉文件名,返回目录
# ID,KEY的配置信息
INFO_CONFIG = {
'ID': '15050553',
'API_KEY': 'rlRrtRL5oRdXGh71jgg1OmyN',
'SECRET_KEY': 'dK5TpuTAZn2nw5eVpspZLmF5Qs1Uu8A1'
}
"""
若API出错 则改为:
INFO_CONFIG = {
'ID': '15050553',
'API_KEY': 'rlRrtRL5oRdXGh71jgg1OmyN',
'SECRET_KEY': 'dK5TpuTAZn2nw5eVpspZLmF5Qs1Uu8A1'
}
或:
INFO_CONFIG = {
'ID': '15788358',
'API_KEY': 'ohtGa5yYoQEZ8Try8lnL99UK',
'SECRET_KEY': 'qaDjyuXkf5MZ28g5C8pwFngDZenhswC3'
}
"""
# URL配置
URL_LIST_URL = {
# ACCESS_TOKEN_URL用于获取ACCESS_TOKEN, POST请求,
# grant_type必须参数,固定为client_credentials,client_id必须参数,应用的API Key,client_secre 必须参数,应用的Secret Key.
'ACCESS_TOKEN_URL': 'https://aip.baidubce.com/oauth/2.0/token?' + 'grant_type=client_credentials&client_id={API_KEYS}&client_secret={SECRET_KEYS}&'.format(
API_KEYS=INFO_CONFIG['API_KEY'], SECRET_KEYS=INFO_CONFIG['SECRET_KEY']),
# 登入人脸识别机器学习库
'FACE_PLATE': 'https://aip.baidubce.com/rest/2.0/face/v3/match',
}
class AccessTokenSuper(object):
pass
class AccessToken(AccessTokenSuper): # 定义登陆API大类
def getToken(self):
accessToken = requests.post(url=URL_LIST_URL['ACCESS_TOKEN_URL']) #登入网址
accessTokenJson = accessToken.json()
if dict(accessTokenJson).get('error') == 'invalid_client':
return '获取accesstoken错误,请检查API_KEY,SECRET_KEY是否正确!'
return accessTokenJson
ACCESS_TOKEN = AccessToken().getToken()['access_token']
LICENSE_PLATE_URL = URL_LIST_URL['FACE_PLATE'] + '?access_token={}'.format(ACCESS_TOKEN)
class faceSuper(object):
pass
class face(faceSuper): # 定义图像输入大类
def __init__(self, image=None, image2=None): # 定义初始化函数
self.HEADER = {
'Content-Type': 'application/json; charset=UTF-8',
}
if image is not None: # 没有图像1
imagepath = os.path.exists(image)
if imagepath == True:
images = image
with open(images, 'rb') as images:
img1 = base64.b64encode(images.read())
else:
print("图像1不存在")
return
if image2 is not None: # 没有图像2
imagepath2 = os.path.exists(image2)
if imagepath2 == True:
images2 = image2
with open(images2, 'rb') as images2:
img2 = base64.b64encode(images2.read())
else:
print("图像2不存在")
return
self.img = img1
self.imgs = img2
self.IMAGE_CONFIG1 = {"image": str(img1, 'utf-8'), "image_type": "BASE64"}
self.IMAGE_CONFIG2 = {"image": str(img2, 'utf-8'), "image_type": "BASE64"}
self.IMAGE_CONFIG = json.dumps([self.IMAGE_CONFIG1, self.IMAGE_CONFIG2])
def postface(self): # 定义从服务器进行数据获取函数
if (self.img==None and self.imgs==None):
return '图像不存在'
face = requests.post(url=LICENSE_PLATE_URL, headers=self.HEADER, data=self.IMAGE_CONFIG)
# 登陆服务器获取数据
return face.json() # 输出结果
def facef(FA1, FA2): # 人脸识别逻辑函数
testAccessToken = AccessToken() # 获取API配置
testface = face(image=FA1, image2=FA2) # 赋值给图像输入大类
result_json = testface.postface() # 从服务器获取数据
result = result_json['result']['score'] #输出结果
print('人脸相似度:', result)
if result > 80: # 识别结果大于80则成功
print("人脸匹配成功!")
# if result < 20:
# print("未检测到人脸!")
else:
print("人脸匹配失败!")
return '人脸相似度:' + str(result), result # 输出字符串结果
快速版:
# -*- coding: utf-8 -*-
"""
Created on Mon May 31 23:40:16 2021
@author: ZHOU
"""
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import requests # 调用 requests的HTTP协议库
import os # 调用os多操作系统接口库
import base64 # 调用base64编码库
import json # 调用JavaScript Object Notation数据交换格式
ACCESS_TOKEN = ''
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) #去掉文件名,返回目录
# ID,KEY的配置信息
INFO_CONFIG = {
'ID': '15050553',
'API_KEY': 'rlRrtRL5oRdXGh71jgg1OmyN',
'SECRET_KEY': 'dK5TpuTAZn2nw5eVpspZLmF5Qs1Uu8A1'
}
"""
若API出错 则改为:
INFO_CONFIG = {
'ID': '15050553',
'API_KEY': 'rlRrtRL5oRdXGh71jgg1OmyN',
'SECRET_KEY': 'dK5TpuTAZn2nw5eVpspZLmF5Qs1Uu8A1'
}
或:
INFO_CONFIG = {
'ID': '15788358',
'API_KEY': 'ohtGa5yYoQEZ8Try8lnL99UK',
'SECRET_KEY': 'qaDjyuXkf5MZ28g5C8pwFngDZenhswC3'
}
"""
# URL配置
URL_LIST_URL = {
# ACCESS_TOKEN_URL用于获取ACCESS_TOKEN, POST请求,
# grant_type必须参数,固定为client_credentials,client_id必须参数,应用的API Key,client_secre 必须参数,应用的Secret Key.
'ACCESS_TOKEN_URL': 'https://aip.baidubce.com/oauth/2.0/token?' + 'grant_type=client_credentials&client_id={API_KEYS}&client_secret={SECRET_KEYS}&'.format(
API_KEYS=INFO_CONFIG['API_KEY'], SECRET_KEYS=INFO_CONFIG['SECRET_KEY']),
# 登入人脸识别机器学习库
'FACE_PLATE': 'https://aip.baidubce.com/rest/2.0/face/v3/match',
}
class AccessTokenSuper(object):
pass
class AccessToken(AccessTokenSuper): # 定义登陆API大类
def getToken(self):
accessToken = requests.post(url=URL_LIST_URL['ACCESS_TOKEN_URL']) #登入网址
accessTokenJson = accessToken.json()
if dict(accessTokenJson).get('error') == 'invalid_client':
return '获取accesstoken错误,请检查API_KEY,SECRET_KEY是否正确!'
return accessTokenJson
ACCESS_TOKEN = AccessToken().getToken()['access_token']
LICENSE_PLATE_URL = URL_LIST_URL['FACE_PLATE'] + '?access_token={}'.format(ACCESS_TOKEN)
class faceSuper(object):
pass
class face(faceSuper): # 定义图像输入大类
def __init__(self, image=None, image2=None): # 定义初始化函数
self.HEADER = {
'Content-Type': 'application/json; charset=UTF-8',
}
if image is not None: # 没有图像1
imagepath = os.path.exists(image)
if imagepath == True:
images = image
with open(images, 'rb') as images:
img1 = base64.b64encode(images.read())
else:
print("图像1不存在")
return
if image2 is not None: # 没有图像2
imagepath2 = os.path.exists(image2)
if imagepath2 == True:
images2 = image2
with open(images2, 'rb') as images2:
img2 = base64.b64encode(images2.read())
else:
print("图像2不存在")
return
self.img = img1
self.imgs = img2
self.IMAGE_CONFIG1 = {"image": str(img1, 'utf-8'), "image_type": "BASE64"}
self.IMAGE_CONFIG2 = {"image": str(img2, 'utf-8'), "image_type": "BASE64"}
self.IMAGE_CONFIG = json.dumps([self.IMAGE_CONFIG1, self.IMAGE_CONFIG2])
def postface(self): # 定义从服务器进行数据获取函数
if (self.img==None and self.imgs==None):
return '图像不存在'
face = requests.post(url=LICENSE_PLATE_URL, headers=self.HEADER, data=self.IMAGE_CONFIG)
# 登陆服务器获取数据
return face.json() # 输出结果
def facef(FA1, FA2): # 人脸识别逻辑函数
testAccessToken = AccessToken() # 获取API配置
testface = face(image=FA1, image2=FA2) # 赋值给图像输入大类
result_json = testface.postface() # 从服务器获取数据
result = result_json['result']['score'] #输出结果
print('人脸相似度:', result)
# if result > 80: # 识别结果大于80则成功
# print("人脸匹配成功!")
# if result < 20:
# print("未检测到人脸!")
# else:
# print("人脸匹配失败!")
return '人脸相似度:' + str(result), result # 输出字符串结果
附录:列表的赋值类型和py打包
列表赋值
BUG复现
闲来无事写了个小程序 代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
c_list[j]=a_list
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
#print(c_list,'\n')
我在程序中 做了一个16次的for循环 把列表a的每个值后面依次加上"_"和循环序号
比如循环第x次 就是把第x位加上_x 这一位变成x_x 我在输出测试中 列表a的每一次输出也是对的
循环16次后列表a应该变成[‘0_0’, ‘1_1’, ‘2_2’, ‘3_3’, ‘4_4’, ‘5_5’, ‘6_6’, ‘7_7’, ‘8_8’, ‘9_9’, ‘10_10’, ‘11_11’, ‘12_12’, ‘13_13’, ‘14_14’, ‘15_15’] 这也是对的
同时 我将每一次循环时列表a的值 写入到空列表c中 比如第x次循环 就是把更改以后的列表a的值 写入到列表c的第x位
第0次循环后 c[0]的值应该是[‘0_0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘10’, ‘11’, ‘12’, ‘13’, ‘14’, ‘15’] 这也是对的
但是在第1次循环以后 c[0]的值就一直在变 变成了c[x]的值
相当于把c_list[0]变成了c_list[1]…以此类推 最后得出的列表c的值也是每一项完全一样
我不明白这是怎么回事
我的c[0]只在第0次循环时被赋值了 但是后面它的值跟着在改变
如图:
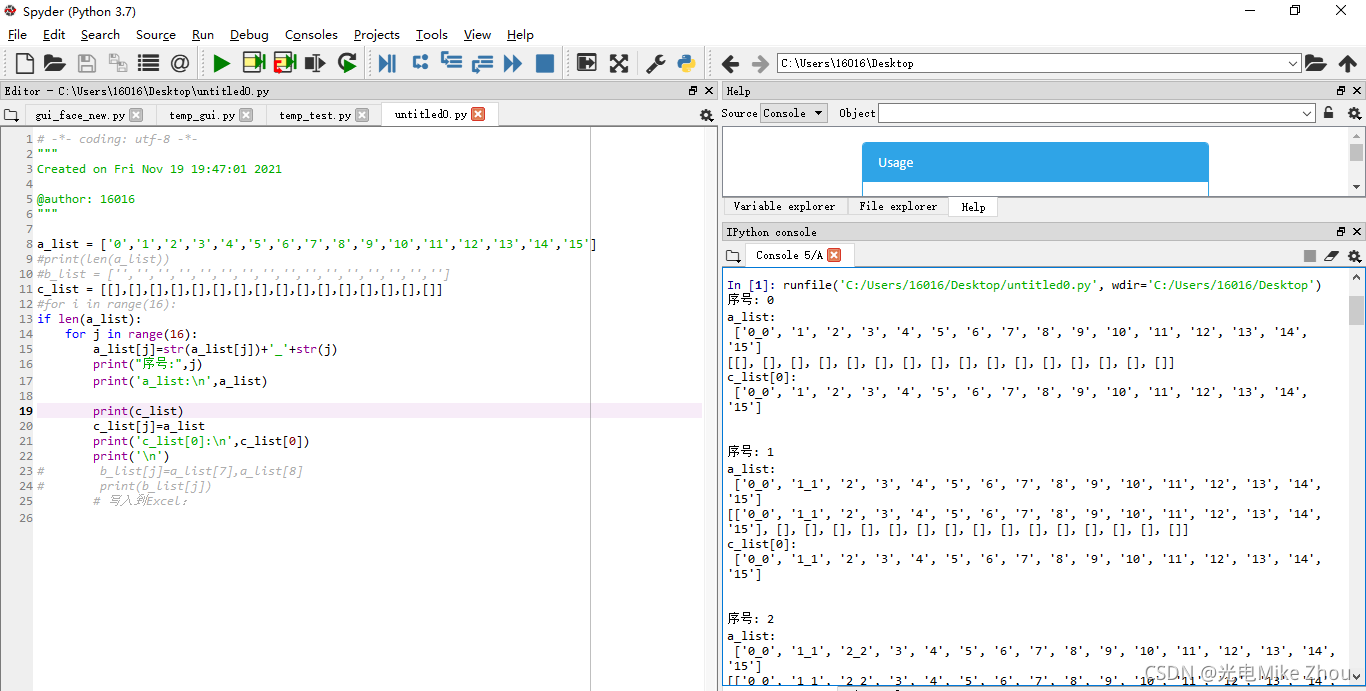
第一次老出bug 赋值以后 每次循环都改变c[0]的值 搞了半天都没搞出来
无论是用appen函数添加 还是用二维数组定义 或者增加第三个空数组来过渡 都无法解决
代码改进
后来在我华科同学的指导下 突然想到赋值可以赋的是个地址 地址里面的值一直变化 导致赋值也一直变化 于是用第二张图的循环套循环深度复制实现了
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
for i in range(16):
c_list[j].append(a_list[i])
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
print(c_list,'\n')
解决了问题
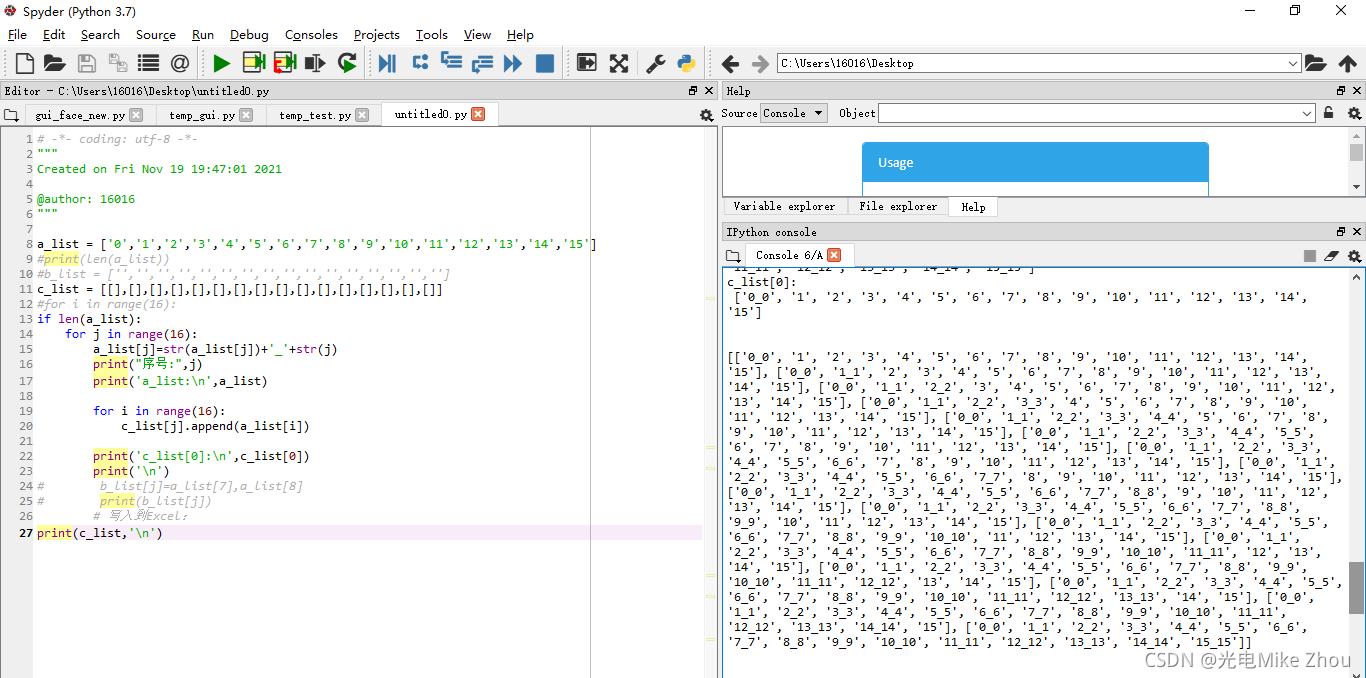
优化
第三次是请教了老师 用copy函数来赋真值
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
c_list[j]=a_list.copy()
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
#print(c_list,'\n')
同样能解决问题
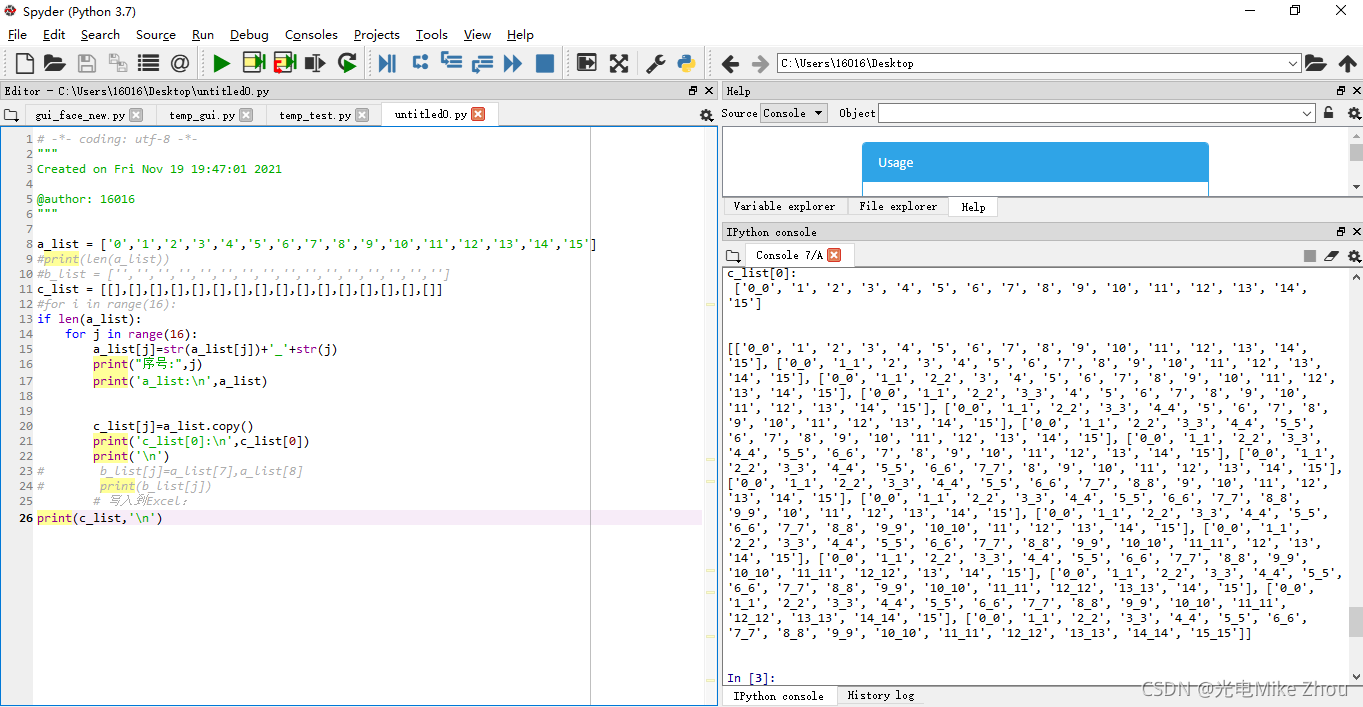
最后得出问题 就是指针惹的祸!
a_list指向的是个地址 而不是值 a_list[i]指向的才是单个的值 copy()函数也是复制值而不是地址
如果这个用C语言来写 就直观一些了 难怪C语言是基础 光学Python不学C 遇到这样的问题就解决不了
C语言yyds Python是什么垃圾弱智语言
总结
由于Python无法单独定义一个值为指针或者独立的值 所以只能用列表来传送
只要赋值是指向一个列表整体的 那么就是指向的一个指针内存地址 解决方法只有一个 那就是将每个值深度复制赋值(子列表内的元素提取出来重新依次连接) 或者用copy函数单独赋值
如图测试:
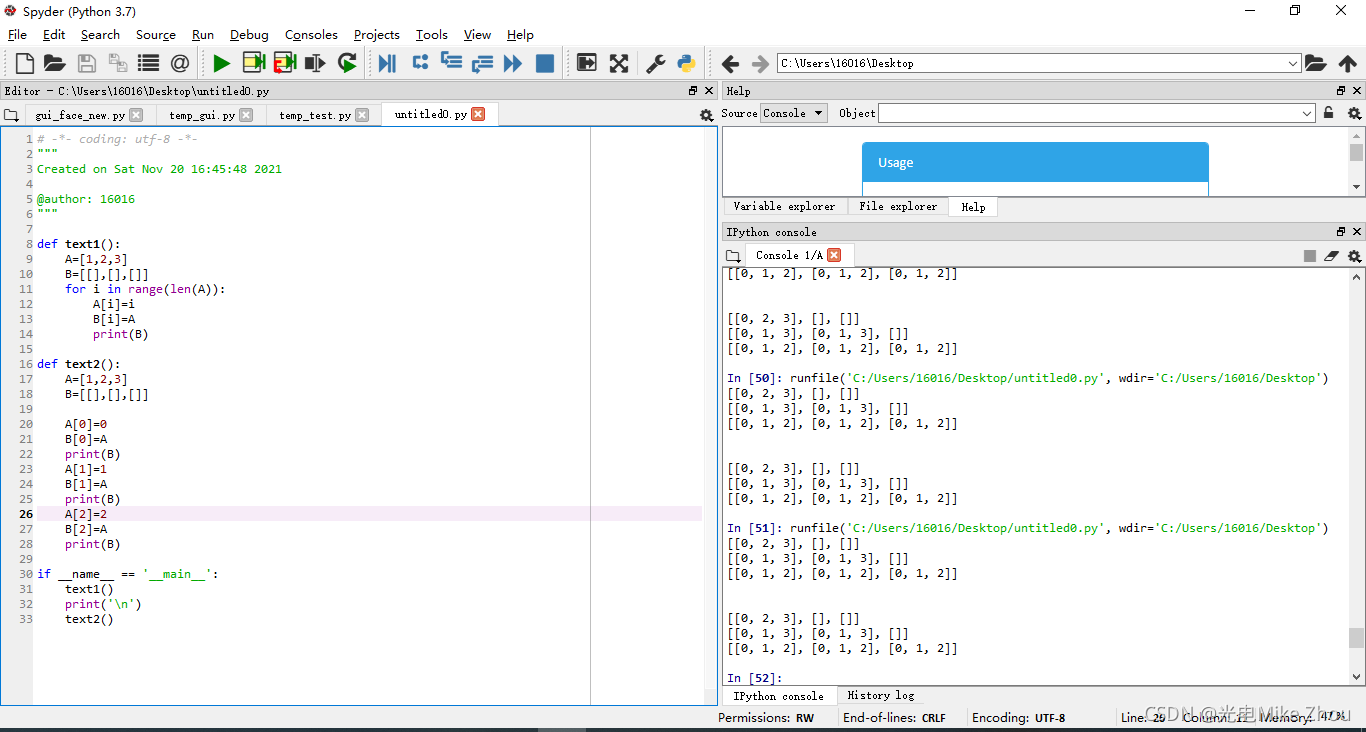

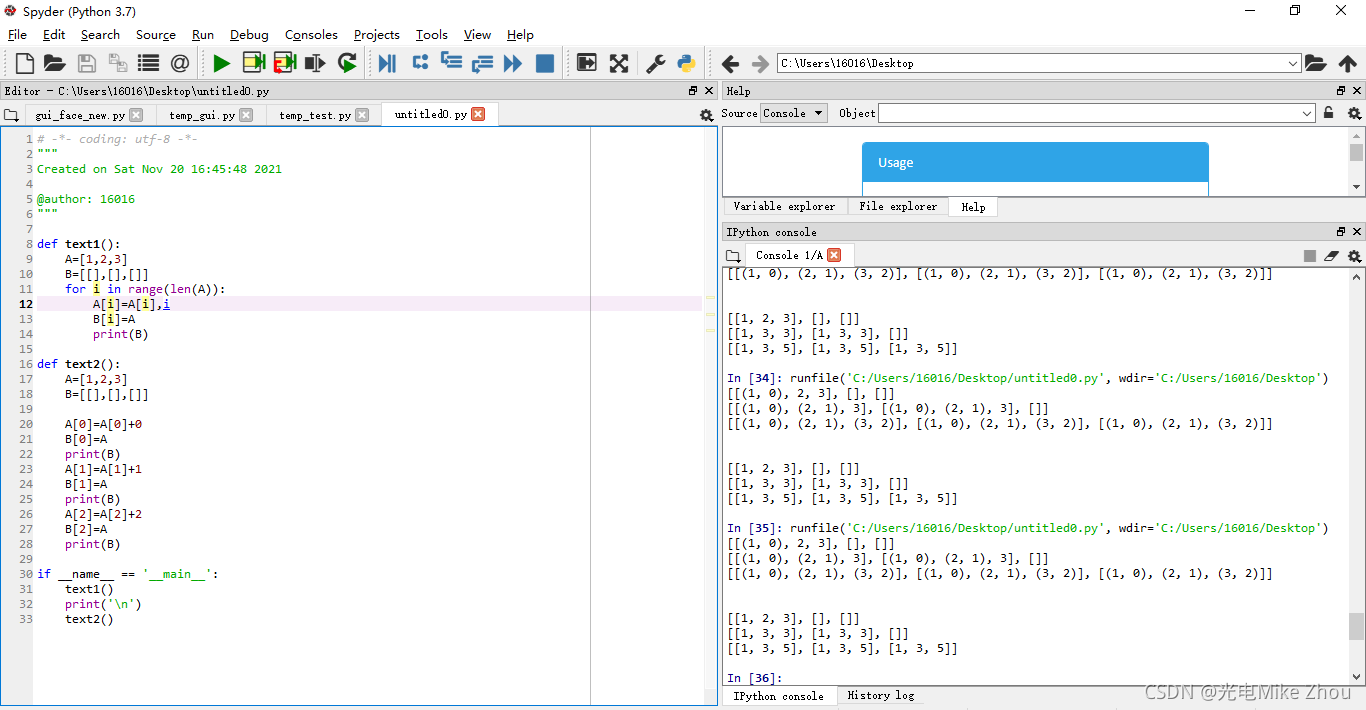
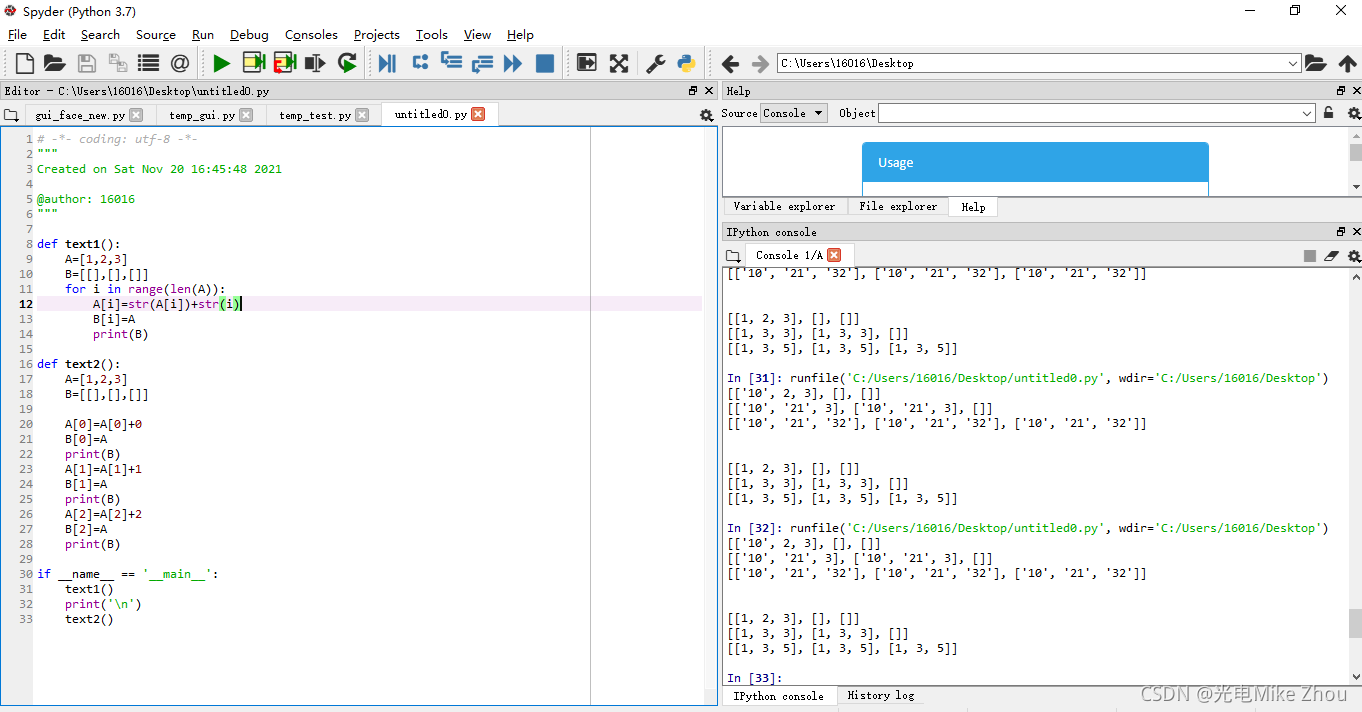
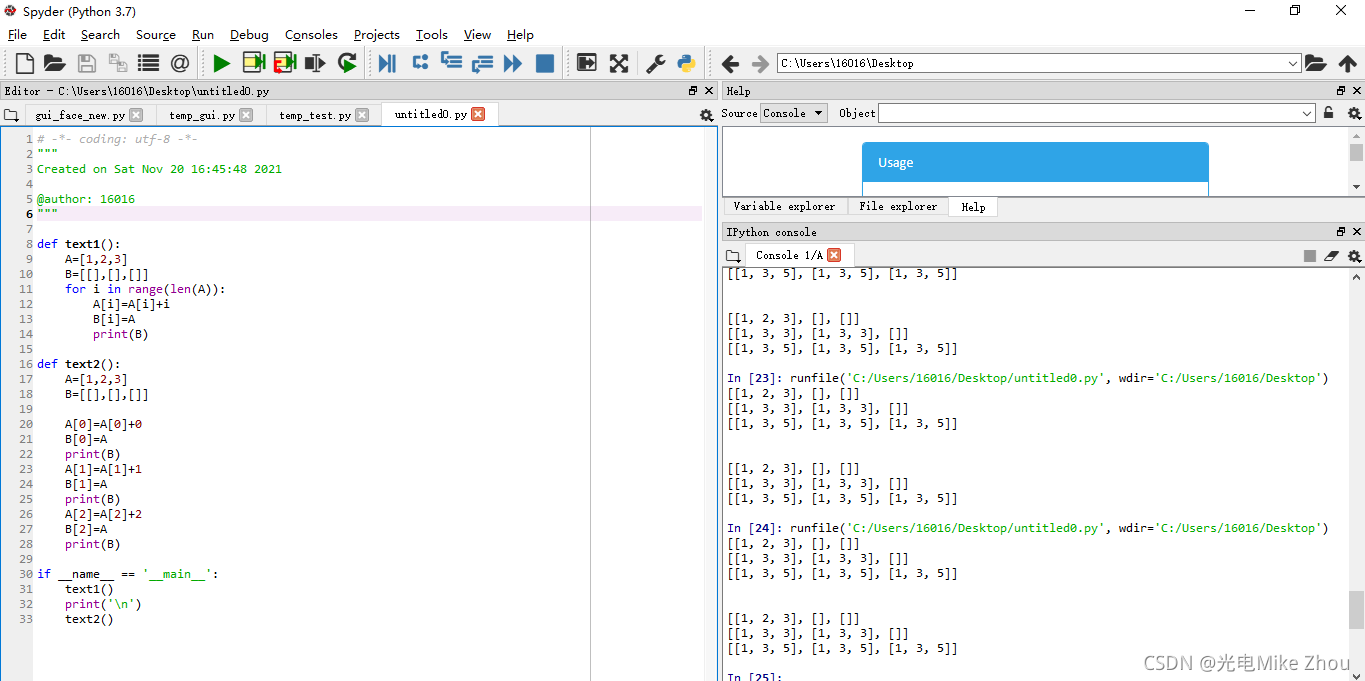
部分代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 20 16:45:48 2021
@author: 16016
"""
def text1():
A=[1,2,3]
B=[[],[],[]]
for i in range(len(A)):
A[i]=A[i]+i
B[i]=A
print(B)
def text2():
A=[1,2,3]
B=[[],[],[]]
A[0]=A[0]+0
B[0]=A
print(B)
A[1]=A[1]+1
B[1]=A
print(B)
A[2]=A[2]+2
B[2]=A
print(B)
if __name__ == '__main__':
text1()
print('\n')
text2()
py打包
Pyinstaller打包exe(包括打包资源文件 绝不出错版)
依赖包及其对应的版本号
PyQt5 5.10.1
PyQt5-Qt5 5.15.2
PyQt5-sip 12.9.0
pyinstaller 4.5.1
pyinstaller-hooks-contrib 2021.3
Pyinstaller -F setup.py 打包exe
Pyinstaller -F -w setup.py 不带控制台的打包
Pyinstaller -F -i xx.ico setup.py 打包指定exe图标打包
打包exe参数说明:
-F:打包后只生成单个exe格式文件;
-D:默认选项,创建一个目录,包含exe文件以及大量依赖文件;
-c:默认选项,使用控制台(就是类似cmd的黑框);
-w:不使用控制台;
-p:添加搜索路径,让其找到对应的库;
-i:改变生成程序的icon图标。
如果要打包资源文件
则需要对代码中的路径进行转换处理
另外要注意的是 如果要打包资源文件 则py程序里面的路径要从./xxx/yy换成xxx/yy 并且进行路径转换
但如果不打包资源文件的话 最好路径还是用作./xxx/yy 并且不进行路径转换
def get_resource_path(relative_path):
if hasattr(sys, '_MEIPASS'):
return os.path.join(sys._MEIPASS, relative_path)
return os.path.join(os.path.abspath("."), relative_path)
而后再spec文件中的datas部分加入目录
如:
a = Analysis(['cxk.py'],
pathex=['D:\\Python Test\\cxk'],
binaries=[],
datas=[('root','root')],
hiddenimports=[],
hookspath=[],
hooksconfig={},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
而后直接Pyinstaller -F setup.spec即可
如果打包的文件过大则更改spec文件中的excludes 把不需要的库写进去(但是已经在环境中安装了的)就行
这些不要了的库在上一次编译时的shell里面输出
比如:
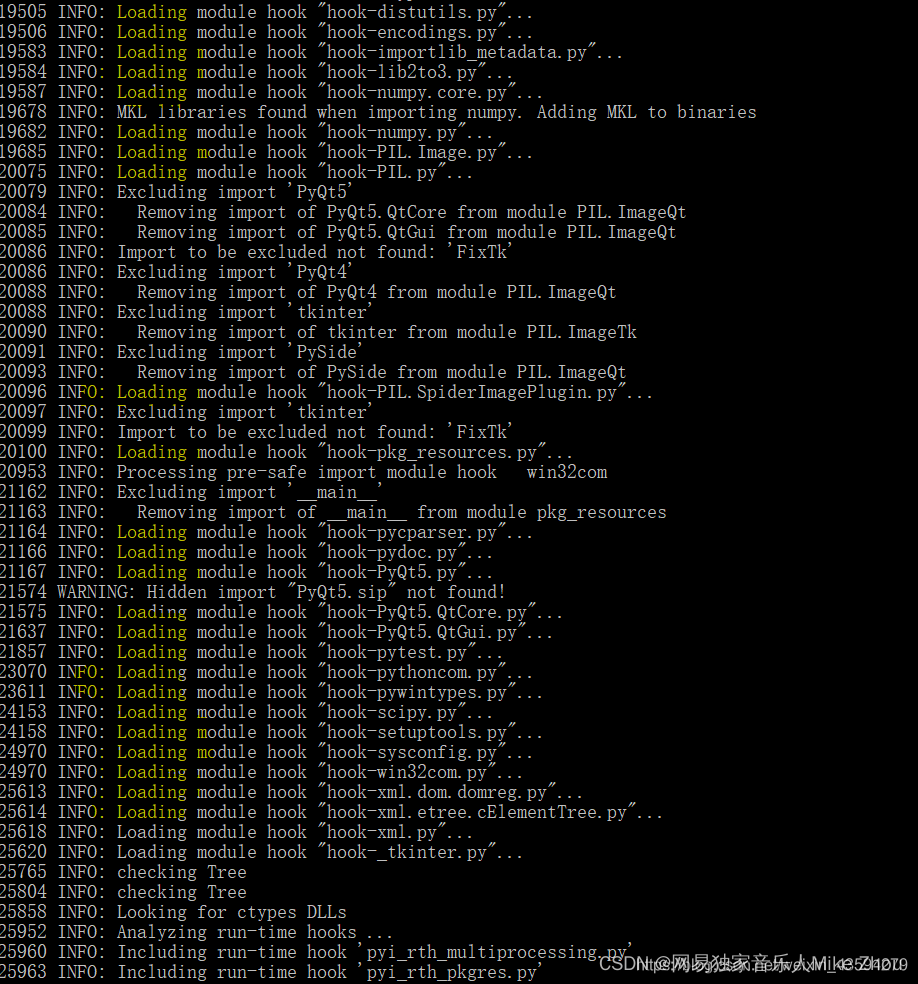

然后用pyinstaller --clean -F 某某.spec
附录:关于旧文新发
为何要进行旧文新发?
因为我在2023年博客之星评选中发现 有的人转载、抄袭他人文章 稍微改动几下也能作为高质量文章入选
所以我将把我的旧文重新发一次 然后也这样做
2023年博客之星规则:
- 自2023年1月1日起算起,平均每周创作过至少一篇高质量且非付费专栏的原创文章即可入围。由于博客之星是年度评选,所以统计时间一直截止到2023年12月17日。
- 高质量博文为80分以上原创博文,质量分查询地址:
https://www.csdn.net/qc - 入围条件补充说明:当前的入围状态为动态,一旦未达到每周平均创作过至少一篇高质量且非付费专栏的原创文章入围资格将会跳出入围资格,若当前还未入围者通过后期创作也可入围,当下并非最终结果。

















 3560
3560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











