







SQL语言分类
DDL:定义
DML:操作
DCL:控制(用于定义访问权限和安全级别)
DQL:查询
Sql方言 ->sql:结构化查询语言
mysql:limit oracle:rownum sqlserver:top 但是存储过程:每一种数据库软件一样
SQL语法要求: ·SQL语句可以单行或多行书写,以分号结尾;
可以用空格和缩进来来增强语句的可读性;
关键字不区别大小写,建议使用大写;
表名,列名也不区分大小写
值可能区分,根据创建表,数据库的字节集决定
DCL
创建用户
create user zhangshan@localhost indentified by '123'
#创建用户名为张三 ,密码123 的本地用户
1396:用户名已经存在
创建一个远程用户:任何电脑都可以访问mysql服务器
用户名 : abc123 密码:123
create user abc123@'%' indentified by '123';
DCL了解
数据控制语句:DBA操作DCL:授权,撤销权限操怍
创建用户.除用户,修改用户属于DDL语句
查看某个用户有什么权限:
show grants for 用户名;
撤销权限:
revoke 权限1,权限2 on 数据库名.*/表名 from 用户 
改root用户:

DDL
-- "select * from user";
-- create database [if not exit] 数据库名称 -- 防止数据库名称存在时创建失败
-- charset :字符集 COLLATE:排列规则数据集(默认是)
-- utf8:中文占三个字节 24位的话,它的大小int类型:4个字节
-- 使用utf8mb4-- 排序规则推荐使用:utf8mb4_bin

#创建数据库
create database if not exists mydb
default character set utf8mb4
collate utf8mb4_bin
#删除数据库
drop database if exists mydb
#修改 字符集
alter database mydb character set utf8
#查看排序编码
show variables like 'collation_%'
#查看字符集
show variables like 'character_set_%'修改表:
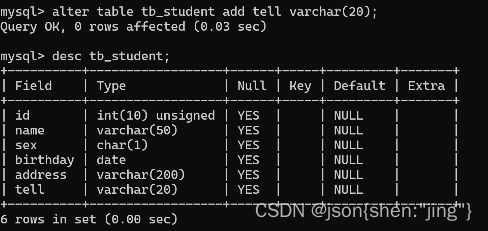
修改列名:alter tablename change tell iphone varchar(20)
删除某一列:alert tablename drop tell
修改表明:alert tablename rename to anothertablename
实际开发尽量不要修改表,尽量在表修改之前设计好
查看表结构:desc tablename;
CRUD增删改查
create table tablename(
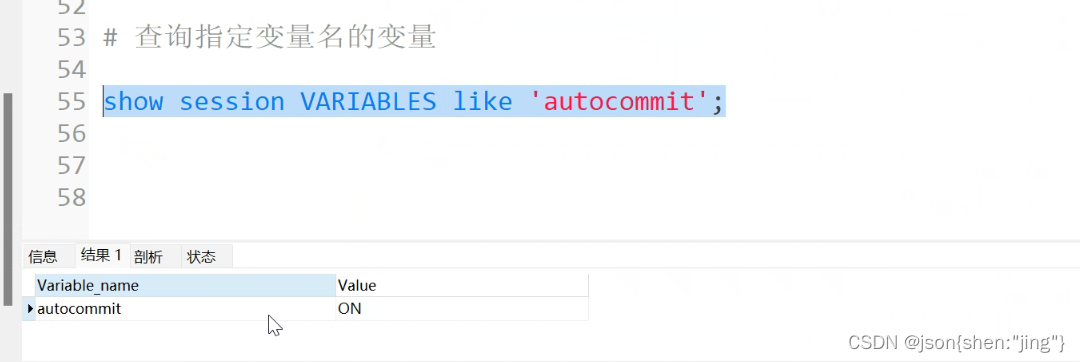
id in comment '主键',
name varchar(20) comment '姓名',
sex char(1) comment '性别',
borthday date comment '出生日期',
address varchar(200) comment '地址'
) comment '学生表';
insert into 表名 values (值1,值12,值3)
sex char(1) -> 2个字节 插入'男' 不报错,可以存下,给列赋值的顺序,跟创建表的列的顺序一致
值:char varchar date -> '',就是说字符串,日期都用''引起
日期赋值格式:1999-12-23
alter tablename modify id int not null;
#设置这一属性后,插入或者修改数据是必须要有id不为空这一准则
#修改
1.全表修改
update 表名 set 列名1 = 值1 ,列名2 = 值2......;
删除(物理删除,硬删除) ->实际开发中,你自己在软件中删除自己的账号更多的是一种软删除
物理:delete from 表名(后面没写就是全表删除)
只能一行一行的删除
加条件的删除(部分行删除)
delete from tbname where name = "李四";
DDL删除(删数据) -> 也是全表删除 但是不同于delete:1.delete是DML语句 truncate是DDL语句,delete删除表中的数据,truncate是删除表中的数据(drop table),再重新创建表,delete自增列不会还原,truncate删除表,自增列会还原,delete可以添加条件,部分删除,但是truncate只能全表删除
truncate tablename 表名;
#example:
alert table tablename modify id int primary key auto_increment ;
desc tb_name;
insert into tablename(name,sex) values ('张山','男');
insert into tablename(name,sex) values ('张山','男');
insert into tablename(name,sex) values ('张山','男');
select * from tablename;
delete from tablename;
insert into tablename(name,sex) values ('张山','男');
select * from tablename;
此时id从4开始 不会还原为1
但是truncate可以还原为id = 1
alter table;
软删除Mysql函数
-- 数值函数
select ceil(12.8);#向上取整13
select floor(-12.9);#向下取整12 注意是负数的12.9就是-13-- 四舍五入函数
select ROUND(12.4);#12
select ROUND(12.5);#13
#ROUND(x,d);#x:数值 d:保留小数位
select round(12.643,2);#12.64#返回数字的符号 可以返回正/负 可以表示数字相减的大小从而判断前一个数的大小
select SIGN(12.1);#返回1代表正数 -1代表负数
select sign(0);#返回0
select (12-13)#int compareTo()#替代这个方法#求余数
select mod(12,5);#等于2#RAND()函数 返回一个0到1的小数
select rand();select * from user;
select e.*,round(salary) from emp e;#工资数字取整
-- 查询奖金比工资高的,显示1,相等显示0,小于显示-1
select e.*,sign(ifNULL(comm,0)-salary) from emp e;#字符串函数
#查询员工信息、,以及每个员工名字的长度
#衍生题目:查询名字有几个字段组成?5个?6个
select e.*,length(e.ename) 员工名字长度
from emp e;
select *from emp e where length(empname) = 5
#查询员工信息。员工信息与姓名合并为一列
select CONCAT(empno,empname) from emp;
select CONCAT(empno,'-',empname) from emp;#INSERT(列名/值,开始位置,个数,替换的值)
#查询员工信息,把员工的姓名(敏感信息第一个字母显示) 后面全部显示为***
select insert(empname,2,length(empname) - 1,'***') from emp;#显示姓名的前三个字母
select insert(empname,3,length(empname) - 3,'')
from emp;#把员工姓名的第三个字母替换为*
select insert(empname,3,1,'*')
from emp;#insert既可以做删除也可以做替换
#insert(列名/值,开始位置,0,替换的值)插入
#截取函数
-- java是subString(开始下标,结束下标,截取个数)
#显示姓名的前一个字母/前三个字母
select left(empname,1) from emp;
select substring(empname,1,3) from emp;#法二
#显示姓名的,只显示后一个字母(倒数第一个字母)
select right(empname,1) from emp;
#显示姓名的,只显示后三个字母(倒数第3个字母)
select right(empname,3) from emp;#length(empname)表示开始位置
select substring(empname,length(empname)-2,3) from emp;#反转
select reverse(empname) from emp;#查询八月份入职的员工
select * from emp where month(hiredate) = 8;
#查询28号入职的员工
select * from emp where DAYOFMONTH(hiredate) = 8;
#昨天的日期
select subdate(now(),1);
#明天的日期
select adddate(now(),1);
-- 相隔多少天
select datediff(now(),'2001-07-08');#获取当前日期
select curdate();
#获取日期加时间
select now()
#时间
select curtime()
create table order(
id int primary key,
createtime datatime sysdate()#设置时间为系统时间
)
insert into order values(1,now());##获取日期各部分的值
select year(now()),month(now()),dayofyear(now())-1,dayofmonth(now());
#日期的加减 -- #定时推送
select adddate(date(),7)#当前日期加7天 返回的是指定天数的日期-- 日期格式化 %表示
select date_format(now(),'%年Y年%m月%d日 %H:%i:%s');
#某个日期/月最后一天的日期
#两百天的日期之后 ,该月的最后一天的日期
select last_day(addDate(now(),200))
#流程函数
三个
if ifnull case
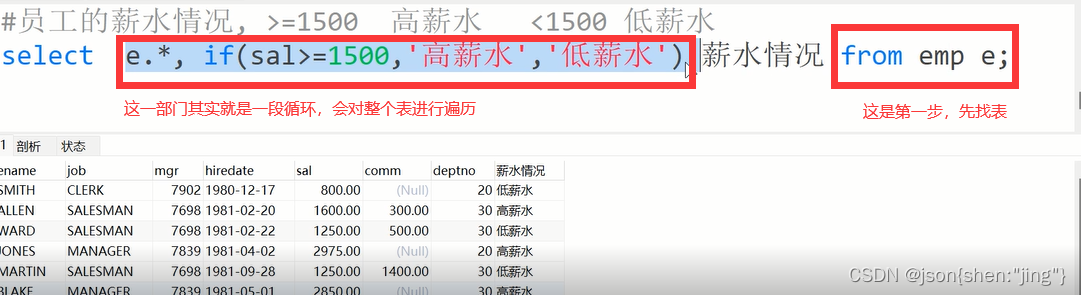
select e.*,if(sal>=1500,'高薪水','底薪水') 薪水条件 from emp;
ifnull(表达式,值) --> if(表达式 is null,值,表达式)select * from score a where a.c_id = '01' #这是一张表
select * from score b where b.c_id = '02' #这是一张表 使用自连接#查询“001”课程比“002”课程成绩高的所有学生的学号;
SELECT
c.*,
a.s_score s01,
b.s_score s02
FROM
score a,
score b,
student c
WHERE
a.c_id = '01'
and b.c_id = '02'
and a.s_id = b.s_id #a b两表连接的条件
and c.s_id = a.s_id #c a两表连接的条件
and a.s_score > b.s_score;SELECT
s.*,
t.s01,
t.s02
FROM
(
SELECT
a.s_id,
MAX(
CASE
WHEN a.c_id = '01' THEN
a.s_score
END
) s01,
MAX(
CASE
WHEN a.c_id = '02' THEN
a.s_score
END
) s02
FROM
score a
GROUP BY
a.s_id
) t,
student s
WHERE
t.s01 > t.s02
AND t.s_id = s.s_id;
#获取当前日期
select curdate();
#获取日期加时间
select now()
#时间
select curtime()
create table order(
id int primary key,
createtime datatime sysdate()#设置时间为系统时间
)
insert into order values(1,now());
##获取日期各部分的值
select year(now()),month(now()),dayofyear(now())-1,dayofmonth(now());
#日期的加减 -- #定时推送
select adddate(date(),7)#当前日期加7天 返回的是指定天数的日期
日期格式化 %表示
select date_format(now(),'%年Y年%m月%d日 %H:%i:%s');
#某个日期/月最后一天的日期
#两百天的日期 ,该月的最后一天的日期
select last_day(addDate(now(),200))
#流程函数
三个
if ifnull case
select e.*,if(sal>=1500,'高薪水','底薪水') 薪水条件 from emp;
ifnull(表达式,值) --> if(表达式 is null,值,表达式)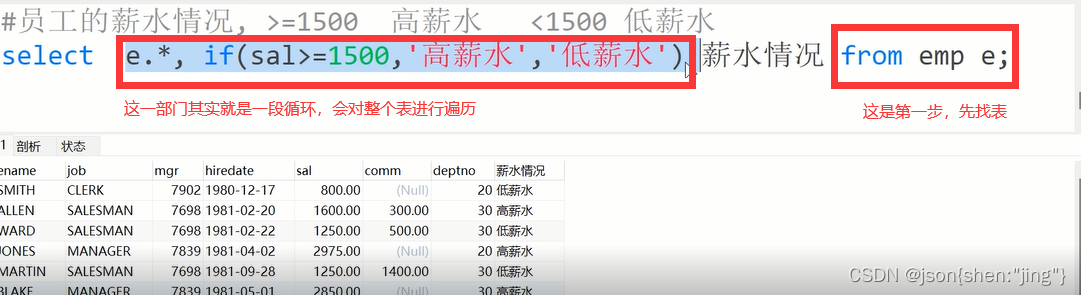




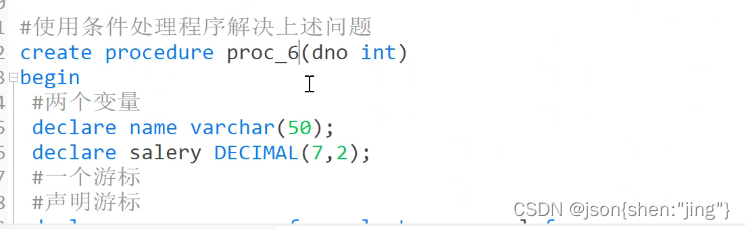
存储过程-游标-索引


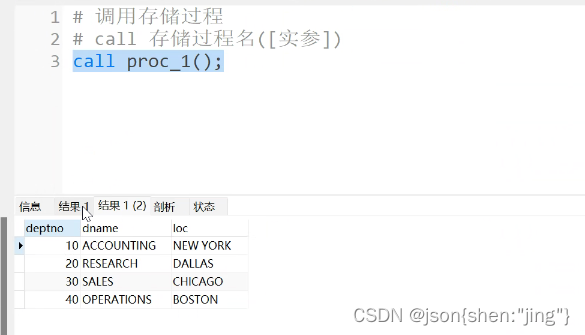
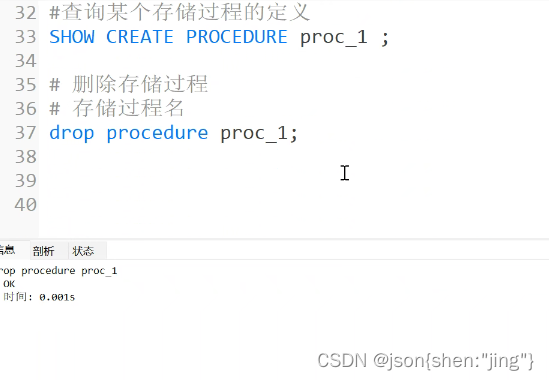

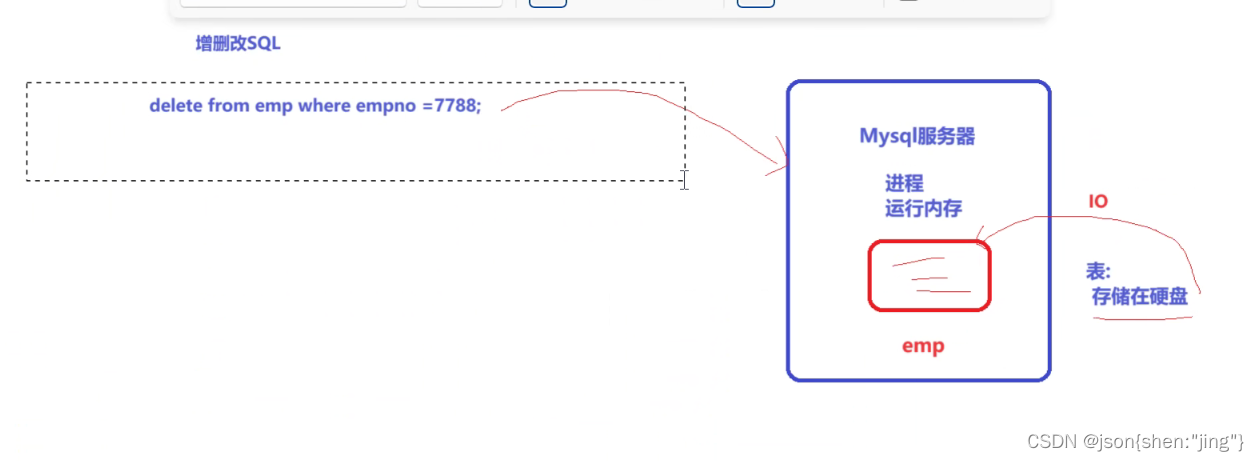
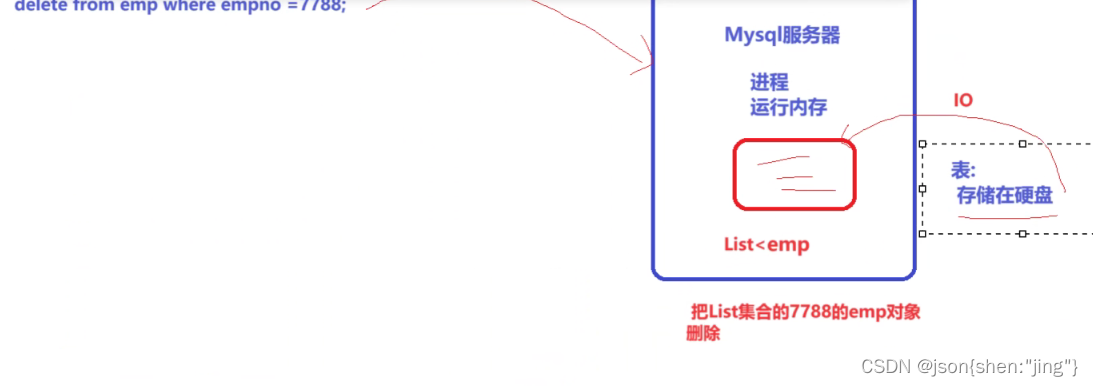
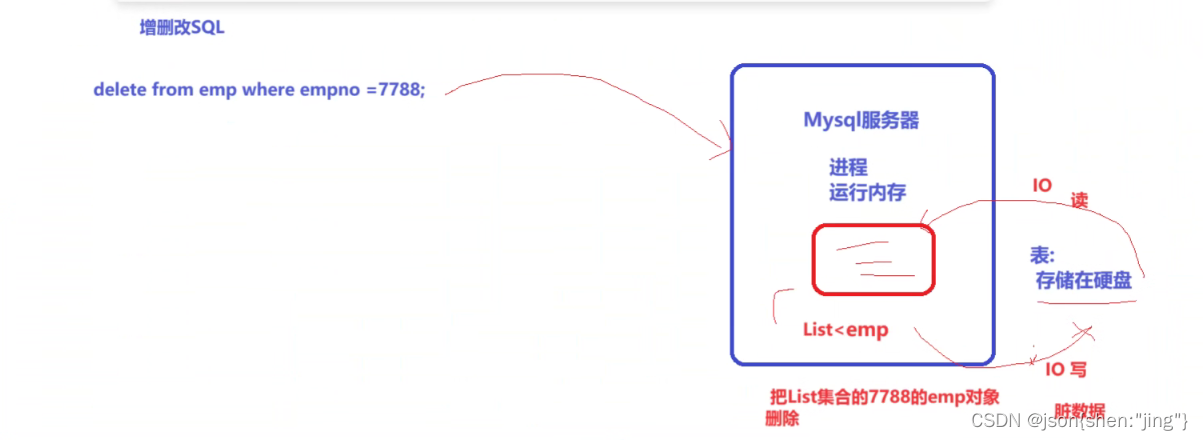
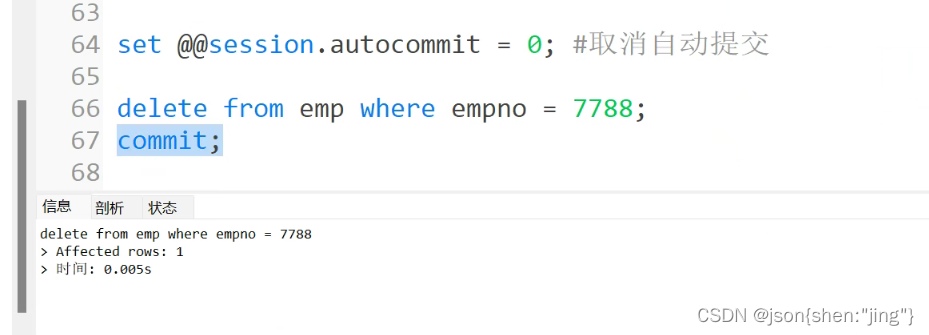
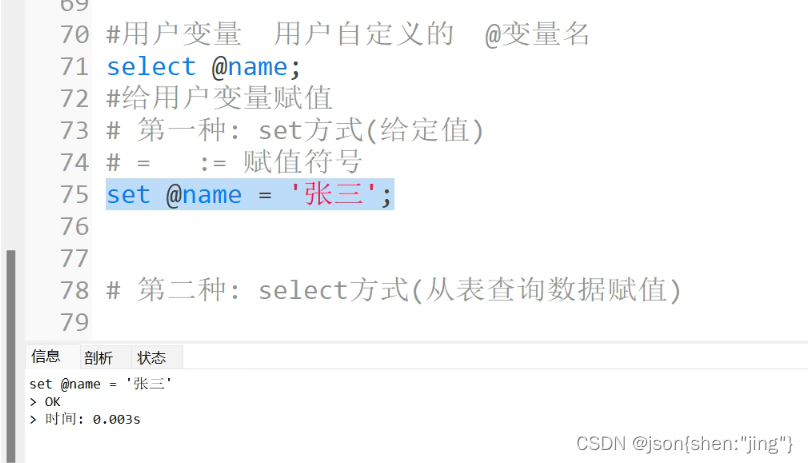
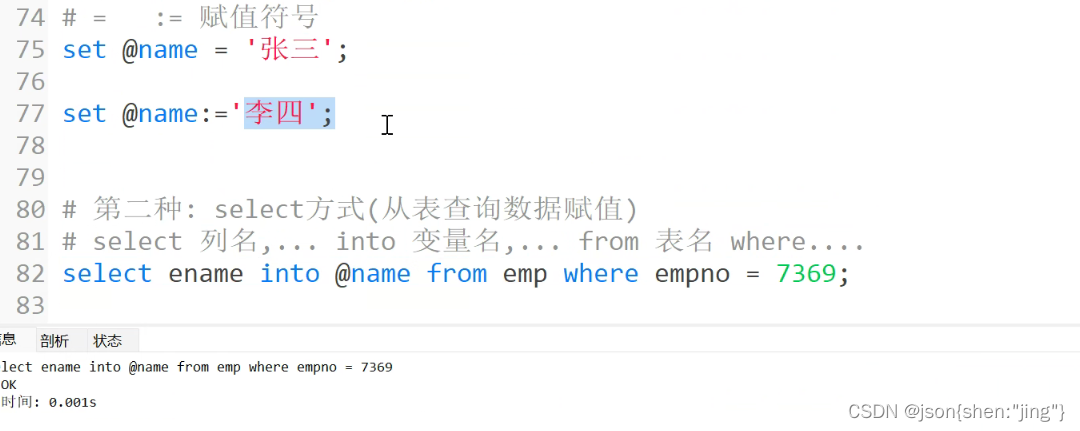






修改存储过程需要重新编译(先删除后编译)



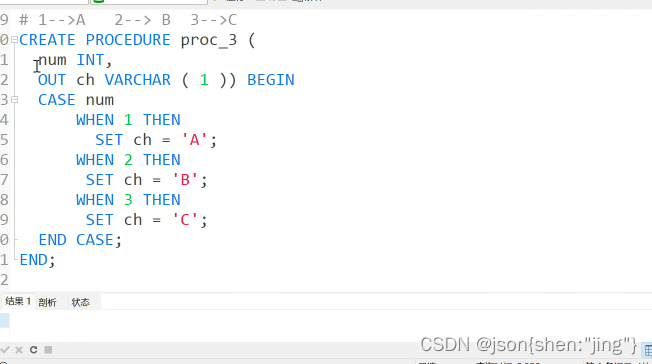
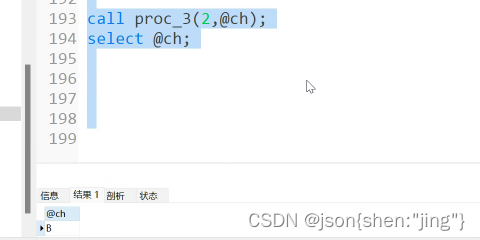
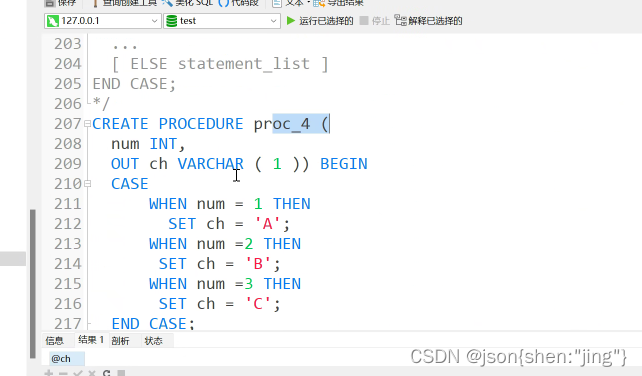
变量赋值用set

变量赋值用set

repeat
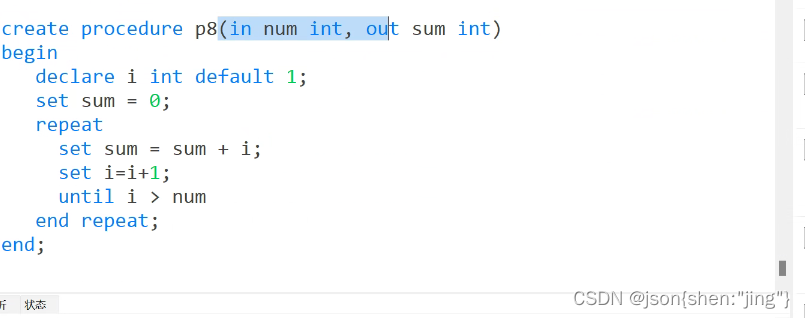
游标
游标解决(类似java迭代器):由于变量只能存一个值,不能存多个值注意!!!!



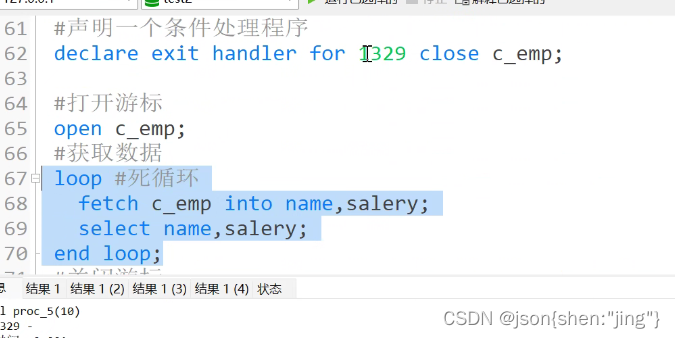
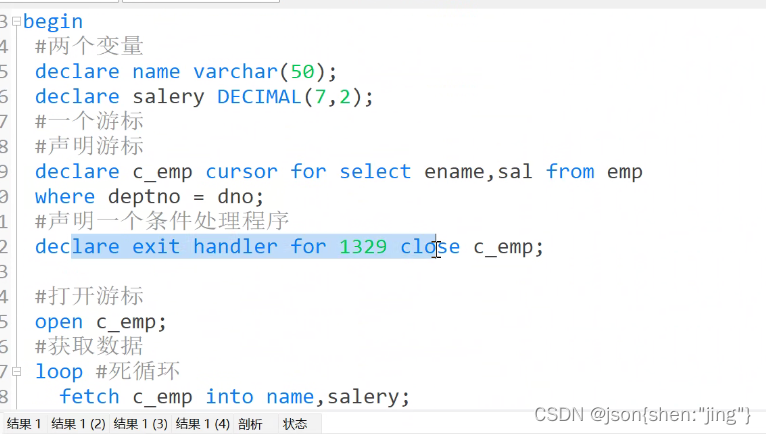

索引
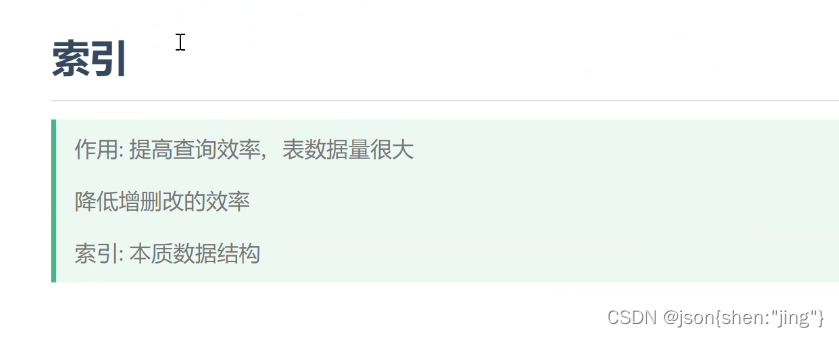
普通查询(一行一行对比,叫全表扫描)
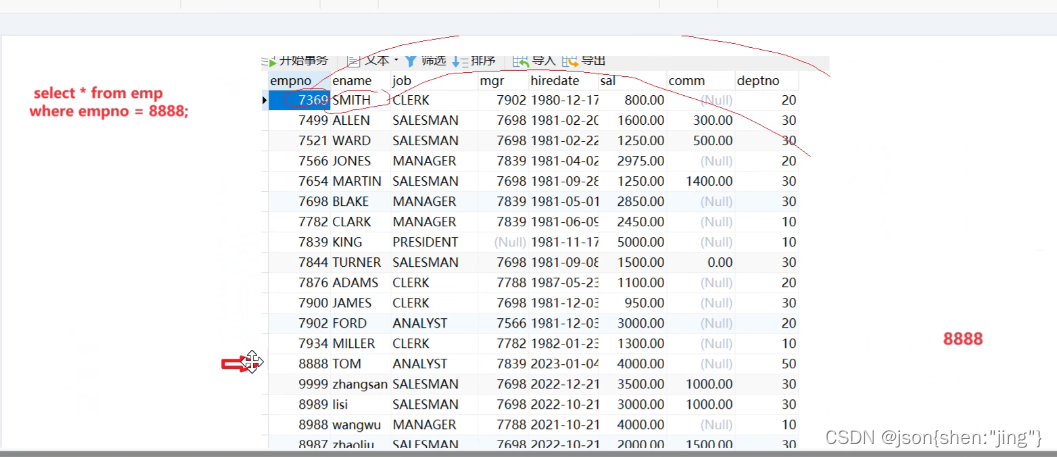
未完
多表查询
-
联合查询 交集 并集(mysql只支持这一种) 差集
-
表连接查询 内连接 外连接 自连接(内连接,外连接) 自然连接 全连接(mysql不支持)
-
子查询
-
函数查询
联合查询
把多个sql语句的结果集进行处理(交,并,差的处理) mysql只支持并集处理,但是可以sql实现差,交 交集关键字:union/union all union可以去重 union all不可以去重
select 的sq语句
union/union all
要求:要求两个sql语句的结果集有相同数量/名字字段
union:可以达到去重的目的
union可以去重复
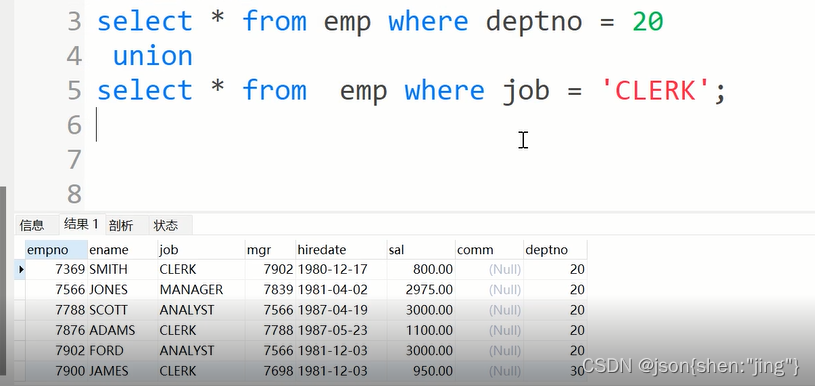
union all:不去重
交集intersect:mysql5.7不支持 -> intersect
select * from emp where deptno = 20 intersect select * from emp where job = 'CLERK'; --->不能实现,但是可以间接实现->内连接 替代法:内连接 要求:是同一张表 select * from emp where deptno = 20 and job = 'CLERK'; select * from emp where deptno = 'BM02' and empno = 'E103';
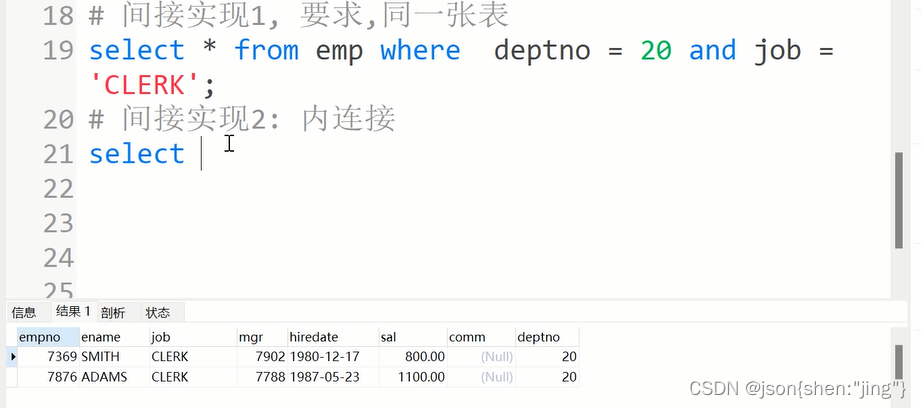

差集(mysql也不支持)
A - B:两个集合的相差 存在与A但不存在于B
间接实现:
select * from where deptno = 20 and job != 'CLERK';

联合查询结束
外连接的方式
表连接
1.自然连接 笛卡尔积
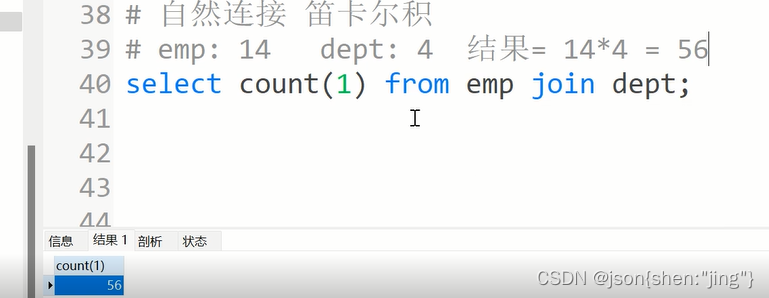
带条件的筛选:(利用笛卡尔积)
其中大部分是基于外键的等值条件
1.1内连接:
inner select *|列名from 表1(表名,查询结果集,一定取别名)
内连接:要求A中的数据,在B表中必须有一条数据对应,查筛选出来


查询员工信息以及部门信息(emp表没有) ->需要两张表(只能:要求A中的数据,在B表中必须有一条数据对应,查筛选出来)
查询所有员工信息以及部门信息(内连接就不能使用,员工可能没有对应的部门,但是内连接要求要求A中的数据,在B表中必须有一条数据对应,查筛选出来)
emp:14条 dept:4条数据 ->查出14条数据

内连接另一种写法:(主流数据库都支持)


1.2外连接
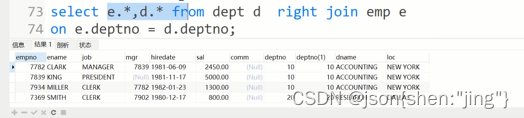
#左外连接:left[ outer] join # join左边的表的数据要全部显示,右边的表数据,满足条件才显示 #右外连接right [outer] join # join右边的表的数据要全部显示,左边的表数据,满足条件才显示 A left [outer] join B; == B right [outer] join A;
查询所有员工信息以及部门信息:
之前TOM显示不出来,因为dept=50不能对应在之前的内连接里面不成立,emp表只有10-30的数据,不能对应,这里外连接没有50对应的?怎么班,那就是null来对应

前者先显示员工,后者先显示部门
显示默认顺序可以改:
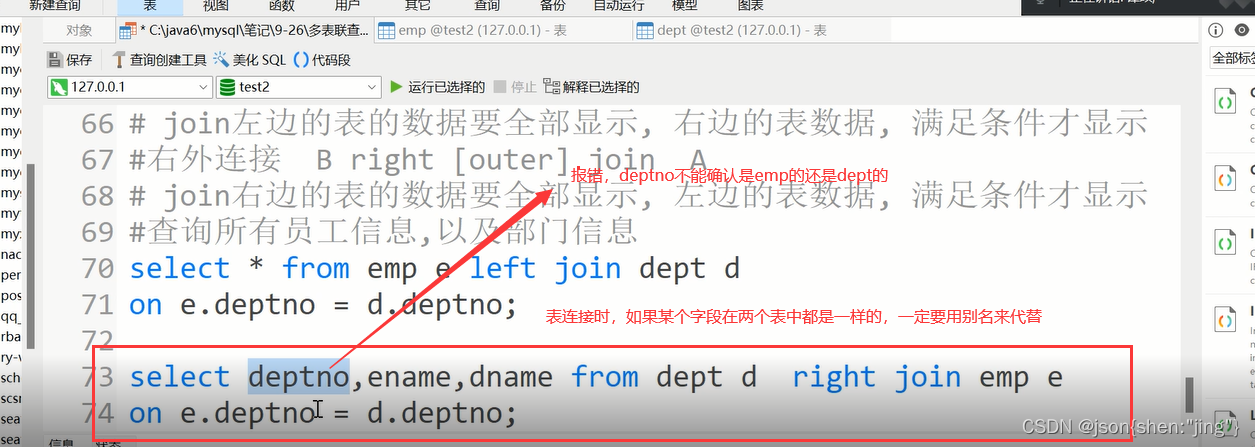
#表连接,如果某个字段在两张表名字一样,一定使用表别名.字段名区分

1.3全连接
全连接:两边表的数据要全部显示.full join在mysql不支持 间接实现 left join和right join还有union(去重) 两个左外,一个Union实现 oracle可以直接用full关键字实现


1.4自连接:自己跟自己连
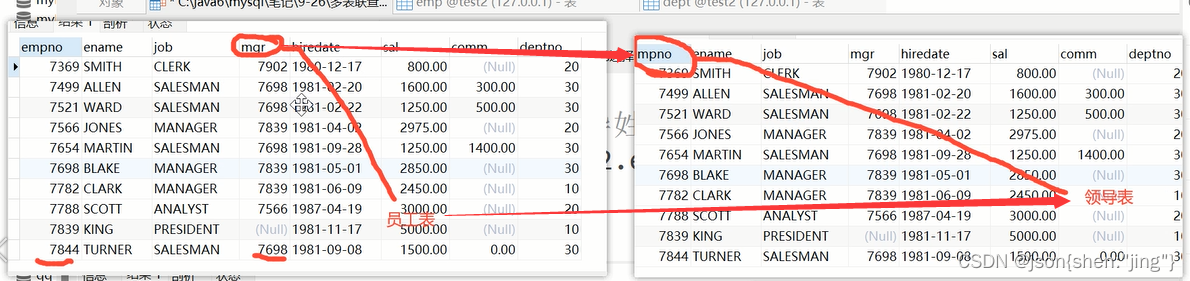
例子:查员工的领导信息
因为员工和领导的信息都在一张表里面,查员工以及他的领导信息需要用到自连接,这张表要连两次
例子:查找员工的姓名和领导的姓名
select e1.ename 员工姓名,e2.ename 领导姓名 from emp e1 join emp e2 on e1.mgr = e2.empno; 员工表的领导编号mgr对应领导表的编号empno

备份数据

分组函数分组查询
use company; -- COUNT()统计指定列不为NULL的记录行数工 -- 如果是null就会忽略,不参与计算 -- sum() avg() min() max() count() -- sum是对某一列进行求和(纵向求和) -- 聚合/分组函数是对列的运算,而不是对行的运算 #分组函数是对列的运算 对Null忽略
#查询员工的总人数,以及老板这个月要发的总工资, -- 总月开支,平均工资是多少,最高工资是谁,最低工资是谁? #count() 统计行数,指定列一定是没有null的列,使得结果准确 #如果某张表某一列都有null,可以使用常数列 select count(empno) from employee;#10行数据,只只针对一列 select e.*,1 from employee e;#每一行多加了一个1的数,形成都是1的一个列 #count(1):统计常数列1的行数
select count(1) 总人数,
sum(Salary) 总工资,
sum(salary+ifnull(comm,0))总月开支 ,
max(salary) 最高工资,
min(salary) 最低工资, avg(salary) 平均薪资 from employee e;-- sum(salary+comm)总月开支 这种写法是不对的,一旦两个值当中有null,那么null加任何值都是null -- 解决这种空的问题:sum(salary+ifnull(comm,0))总月开支 #目前这是对整张表的一个统计 我想看每个部门的呢?怎嘛办?
分组查询
-- group by 列名 -- 部门分组 岗位分组 谁是谁的领导分组 年龄分组 #如果使用了group by进行了分组 -- select 后面能写的列 -- 是分组中出现的列以及分组函数 非常重要
select * from employee group by EmpNo;
select deptNo,count(1) 总人数, sum(Salary) 总工资,
sum(salary+ifnull(comm,0))总月开支 ,
max(salary) 最高工资,
min(salary) 最低工资,
avg(salary) 平均薪资
from employee GROUP BY deptNo;
-- 10 2 7450 7450 5000 2450 3725.0000
-- 20 3 6775 6775 3000 800 2258.3333
-- 30 5 9850 12050 3000 1250 1970.0000
分组之后进行筛选
注意where是对整张表的筛选 ,可以使用表中的所有列作为条件,但是是先from 再where,
-- 还没有分组,where就没有拿到分组后的信息,所以不使用分组函数 -- 怎么办呢?所以使用having,having实现对分组之后的结果进行筛选,必须现有group by -- 再有having #having:可以使用分组中出现的列作为条件,但是无法使用到表中没有分组的的列, -- 但是他可以使用分组函数 -- 这里你看having后面就可以跟deptNo 但是empmo不能使用因为这个列没有分组,所以就是这样了
select deptNo,count(1) 总人数,
sum(Salary) 总工资,
sum(salary+ifnull(comm,0))总月开支 ,
max(salary) 最高工资,
min(salary) 最低工资,
avg(salary) 平均薪资
from employee -- where count(1) >= 4
GROUP BY deptNo having count(1) >= 4;
子查询
子查询: select查询/delete/update中包含其他select
根据子查询的结果分裂
1.1单行单列
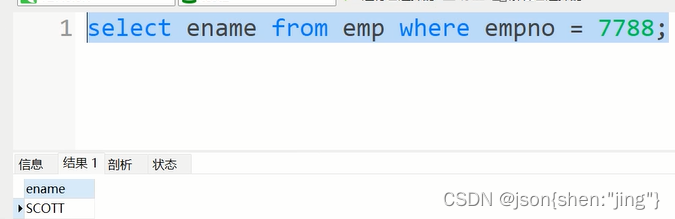
查询薪水比scott这个员工高的员工信息
1.查询scott的薪水 2.查询薪水比1结果大的数据 select sal from emp where ename = 'scott'; -> 3000 select * from emp where sal > 3000 合并:(子查询)先子查询执行,然后才是外边的查询 select * from emp where sal > (select sal from emp where ename = 'scott');
查询薪水比20号部门最高薪水都高的员工信息
select max(sal) from emp where deptno = 20; select * from emp sal > (select max(sal) from emp where deptno = 20 -> 这个结果就是一个单行单列); 单行单列作为条件来用,多行多列当做表来用
列子查询
(只有一列,但是可以有多行)
例子:查询两个部门的信息
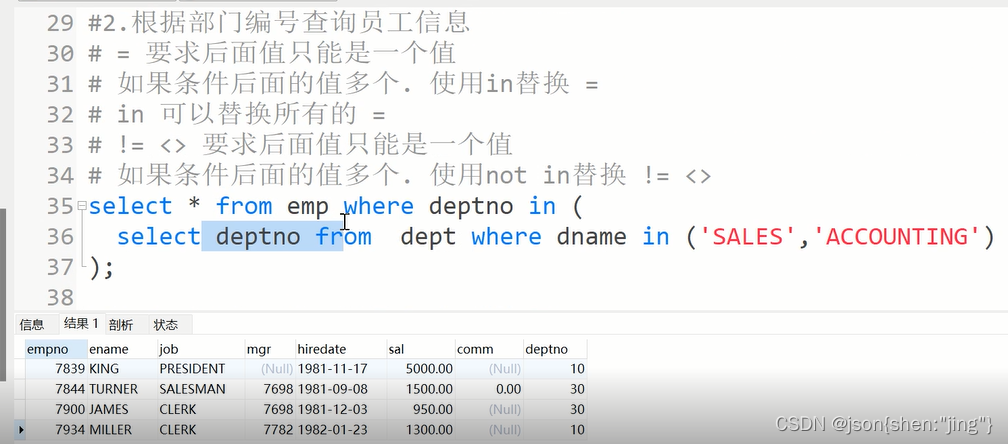


#2.根据部门编号查询员工信息 #=要求后面值只能是一个值 #如果条件后面的值多个.使用in替换= #in可以替换所有的= #!= <>要求后面值只能是一个值 #如果条件后面的值多个.使用not in替换!= <>
on后面表示条件,后面可以拼and或者加where或者e.deptno = d.deptno这种连接
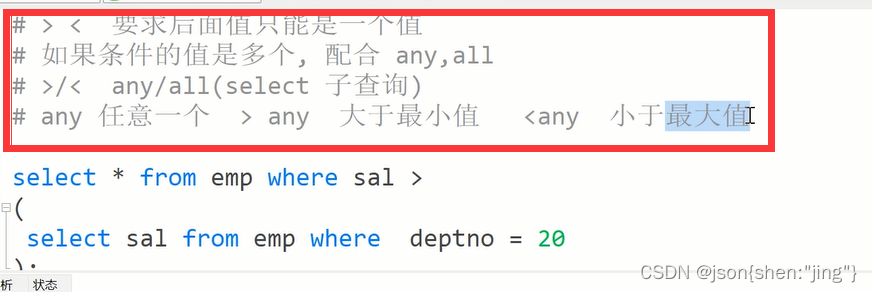
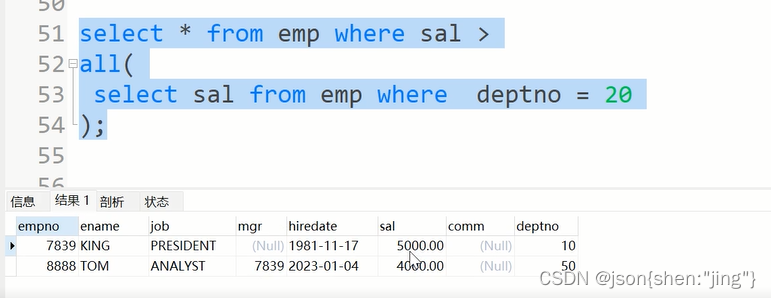
例子:查询薪水比20号部门所有员工薪水都高的员工信息
1.2 单行多列

查询岗位与薪水与martin员工一样的员工信息
注意子查询要小括号括起来
select sal,job from emp where ename = 'martin' select sal from emp where sal = ( select sal from emp where ename = 'martin' ) and job = ( select job from emp where ename = 'martin' ) and ename <> 'martin'; 优化: select * from emp where#不括号只是括号在比 (sal,job) = (select sal,job from emp where ename = 'MARTIN') and ename != 'MARTIN' #注意多个列比较,需要小括号括起来 #小括号中的列的顺序与select查询的列顺序一致
#子查询:多行多列作为表使用 #查询员工编号为7369的员工名称、员工工资、部门名称、部门地址
#查询部门名称,以及每个部门的人数,总薪水,最高薪水
select * from dept;
select count(1),sum(sal),max(sal)
from emp group by deptno;#这个查询作为一个表来用(多行多列),当然你要注意一定要给这个子查询起一个别名
优化:
select * from dept d join (
select count(1),sum(sal),max(sal)
from emp group by deptno
) t
on d.deptno = t.deptno;
#查询部门名称,以及每个部门的人数,总薪水,最高薪水 筛选人数 >= 4
表连接尽量先筛选,再进行表连接
方法一:
外:4条 内2条 -> 笛卡尔积8 效率更高一点
查人数->用having不用where
select * from dept d join (
select count(1),sum(sal),max(sal)
from emp group by deptno
having count(1) >= 4
) t
on d.deptno = t.deptno;
方法二:
外(部门表数据4条,里面的员工表也是16条,笛卡尔积是16)
select * from dept d join (
select count(1) num,sum(sal),max(sal)
from emp group by deptno
) t
on d.deptno = t.deptno
#where having count(1) >= 4;不可以,having不能独立出来,外面这个主查询没有分组(group by),
#where count(1) >= 4;更不可以where不可以跟分组查询
#where t.count(1) >= 4;t.count(1)表示一个函数,而不是一个列名
where t.num >= 4;
;
查询部门名称,以及每个部门的人数,总薪水,最高薪水 筛选人数 >= 4
1.3 多行单列

1.4多行多列
-> 作为表使用,在from后面
子查询出现的位置:
where后,作为条件的一部分;
from后,作为被查询的一条表;
select之后,作为被查询的一列;
当子查询出现在where后作为条件时,还可以使用如下关键字:
|-any
I- all
做作业:
员工表
部门表
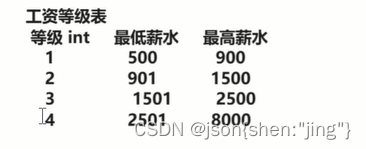
工资等级表















 44
44











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









