







补充:按值删除操作:删除某个特定的结点p。算法如下:
bool LocateDel(LNode *p,ElemType &e){
if(p == NULL);
return false; //p无效
LNode *q = p->next; //找到p的后一个结点
e = p->data;//用e返回被删除的函数值
p->data = q->data; //将被删结点p后一个结点的数据域赋给p
p->next = q->next; /断链操作
free(q);//释放后继结点的存储空间
return true;
}G、求表长操作:求表长操作就是记录数据结点中数据结点的个数(不包括头结点)
int Length(LinkList L){
int len = 0; //计数器,统计表长
LNode *p = L;
while (P->next != NULL){ //从头往下寻找,找到空指针时停止
P = P->next;
len++;
}
return i;
}总结:除了在特定结点之前插入结点和删除特定结点的操作时间复杂度是O(1)外,其余操作的时间复杂度都是O(n),分析过程略。
(2)双链表的定义
单链表结点中只有一个指向后继的指针,这使得单链表只能从前往后依次遍历,在插入和删除操作时时间复杂度为O(n)。
因此,为了克服单链表的这一缺点,引入了双链表。
双链表结点有两个指针prior和next,分别指向双链表的前驱结点和后继结点,如下图所示:
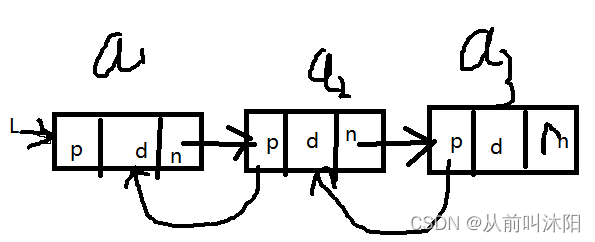
双链表中结点类型的描述如下:
typedef struct DNode{ //定义双链表结点类型
ElemType data; //数据域
struct DNode *prior,*next; //前驱和后继指针
}DNode,*DLinkList;
A、双链表的插入操作 :在p结点之后插入s结点。算法如下:
bool InsertDNode(DNode*p,DNode*s){
if(p == NULL || s== NULL)
return false; //非法参数
s->next = p->next; //插入结点s在结点p之后
p->next->prior = s;
s->prior = p;
p->next = s;
return true;
}B、双链表的删除操作:删除p结点的后继结点q。操作算法如下:
bool DelNextNode(DNode *p){
if(p == NULL || p->next == NULL) //p为无效结点或者后继结点为 空
return false;
LNode *q = p->next; //q结点指向p结点的后一个结点
p->next = q->next;
p->next->prior = p;
free(q); //释放q结点所占的空间
return 0;
}总结:时间复杂度都为O(1)。
(3)循环链表的定义
1、循环单链表
循环单链表的定义与单链表的定义一致,唯一的不同之处是循环单链表的最后一个结点的指针域不是指向空指针,而是指向头结点,从而使得整个链表都形成了一个环。如下图所示:
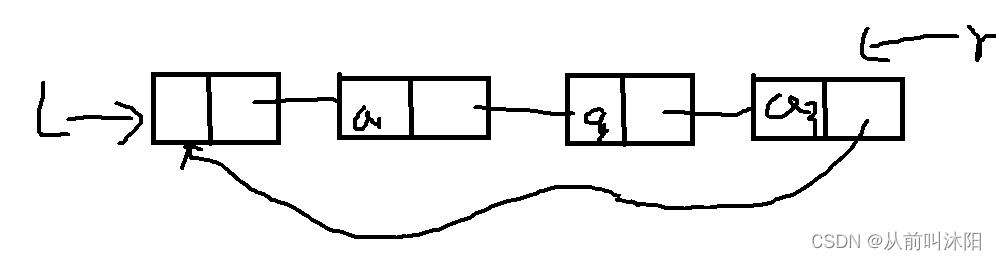 循环单链表的基本操作与单链表的基本操作几乎是相同的。值得注意的是,如果对单链表的操作经常是在表头和表尾进行,此时对循环单链表不设头指针而只设尾指针,操作效率更高。
循环单链表的基本操作与单链表的基本操作几乎是相同的。值得注意的是,如果对单链表的操作经常是在表头和表尾进行,此时对循环单链表不设头指针而只设尾指针,操作效率更高。
2、循环双链表
循环双链表表头结点的前驱结点指向表尾,表尾结点的后继结点指向头结点。如下图所示:
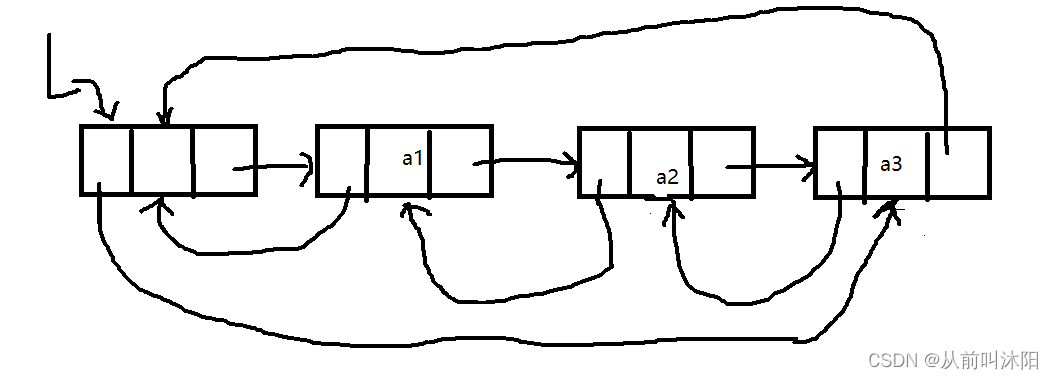
初始化循环双链表的,其头结点的前驱和后继都指向头结点
L->prior = L;
L->next = L;
(4)静态链表
使用数组的方式实现的链表,使用时,需要分配一整片连续的存储空间,将各个结点集中安置。数组定义为数据元素+下一个结点的数组下标。
三、顺序表和链表的比较
| 顺序表 | 链表 | |
| 存取(读写方式) | 顺序存取、随机存取 | 顺序存取 |
| 增删改查操作 | 按值查找时:无序:O(n);有序:O(logn) 按序号查找时:随机存取O(1) 插入、删除:O(n) | 查找:O(n) 插入、删除:O(n) |
| 空间分配 | 预先分配好 | 只在需要时申请分配 |
四、经典题目分享
1、对于一个线性表,既要求能够较快的进行插入和删除操作,有要求存储结构能反应数据之间的逻辑关系,应当采用()
A.顺序存储方式 B.链式存储方式 C.散列存储方式 D.以上均可以
答案:B.链式存储用指针表示逻辑结构,而指针的设置是任意的,故可以很方便的表示各种逻辑结构。
2、已知头指针 `h` 指向一个带头结点的非空单循环链表,结点结构为 `data | next`,其中 `next` 是指向直接后继结点的指针,`p` 是尾指针,`q` 是临时指针。现要删除该链表的第一个元素,正确的语句序列是:
A. `h->next=h->next->next; q=h->next; free(q);`
B. `q=h->next; h->next=h->next->next; free(q);`
C. `q=h->next; h->next=q->next; if (p!=q) p=h; free(q);`
D. `q=h->next; h->next=q->next; if (p==q) p=h; free(q);`答案:D。画图理解。还是比较基础的。
3、设L为带头结点的单链表,编写算法实现从尾到头反向输出每个结点的值。
分析:考虑使用递归 的思想,每当访问一个结点时,先递归输出它的下一个结点,在输出该结点自身,这样这个结点就反向输出了。
void R_Print(LinkList L){ //递归
if(L->next != NULL)
R_Print(L->next);
if(L != NULL)
print(L->data); //从尾到头输出单链表每个结点的值
}
void Print(LinkList L){ //输出函数
if(L->next != NULL)
R_Print(L->next);
}















 1926
1926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









