







【摘要】
原生的K8S集群系统架构优化——可用性优化,针对负载的漂移和故障转移失败,进行梳理优化。
【案例正文】
【背景】
公司在政务云环境部署了一个系统,同事自建的K8S集群V1.19.0,面板管理和展示用Kuboard
v2.0.5.1。系统分正式环境和测试环境,均为一个控制节点+两个工作节点,节点均为虚拟机部署在政务云公共服务域(与互联网隔离)。
K8S云原生系统架构优化_xuyijing0103的博客-CSDN博客 https://blog.csdn.net/weixin_53439529/article/details/132565188
https://blog.csdn.net/weixin_53439529/article/details/132565188
【问题】
采用混沌工程的思路轮流宕机两个工作节点node1和node2,基本都会产生大量微服务不可用,kuboard一片红色的样子。但是受影响的微服务都不一样,而且不可用的原因也都不一样。整体来看:
1.Node1宕机影响更大,几乎所有的后端全都不可用;Node2宕机影响较小。两个节点是同样配置的物理机,为什么影响范围不一样?
2.Node1和Node2宕机都会出现大量无状态负载无法漂移问题,而有状态负载全都无法自动故障转移(这两种负载原理不一样,必须要分开看);
3.节点宕机后所有在上面运行的副本全都是删除状态,但是始终都无法删掉,就算是成功调度的无状态负载也能看到有前一个副本一直在删除中。
4.部分负载会不断在该节点宕机后重复调度,每分钟都会重新拉起一个副本,但是马上又删除然后就卡在删除中,导致副本在一个节点上堆积,堆到极限。
【过程与结果】
【初步解决思路】
首先声明,我知道集群高可用的概念,这个优化项严格来说不是高可用。但是在本文中只关注这个K8S集群中负载的可用性,尤其是pod无法漂移的问题,完全就没体现K8S的优势,比较严重,也算是可用性的一个表现吧。
OK,进入正题。
四个大问题分类只是表象,其实根本原因是:架构设计不合理。直接原因当然就多了,可以说是五花八门,下面详细分析一下。
【问题成因分析】
【原理】
我们都知道,K8S的调度能力很厉害,因为在节点宕机后可以重新调度到其他可用节点。其实原理是这样的:
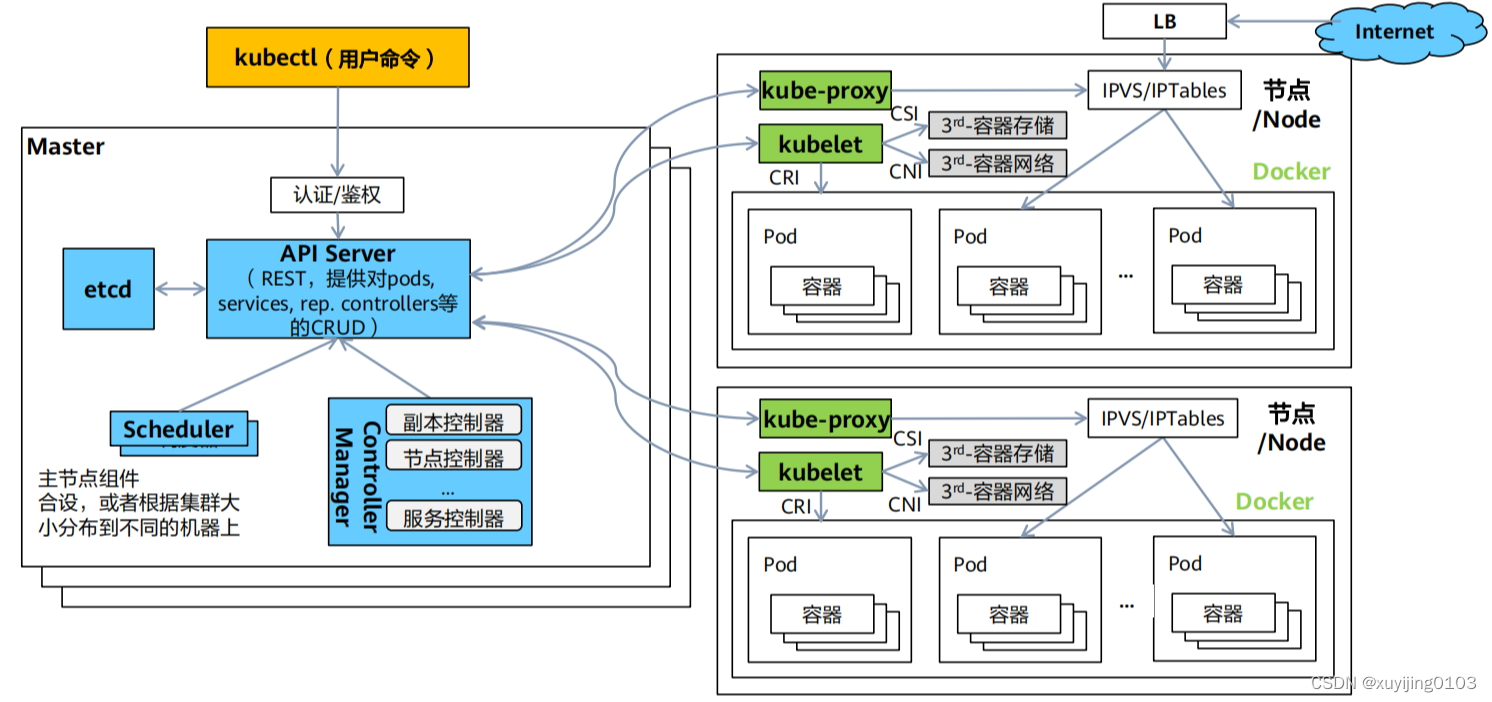
上图是K8S的工作流程,可以看到在Node节点上运行两个组件:Kube-proxy和kubelet。Kube-proxy是一个简单的网络代理组件,后面再介绍。重点是kubelet,它处理master节点下发到本节点的任务,工作核心就是一个控制循环,即:SyncLoop。这个循环的开始就是探测node的状态,并且定期向主节点报告节点的状态。如果主节点长时间无法收到节点的心跳信号,将判断该节点不可用。一旦节点被标记为不可用,master上的控制器将其所有运行中的Pod标记为"删除"状态,并阻止在该节点上调度新的Pod。调度器将根据Pod的调度策略和资源要求,在其他可用的节点上重新调度被标记为"删除"的Pod。这可能会创建一个新的Pod副本,并在新的节点上启动。
通过这个机制,Kubernetes确保了应用程序的高可用性和弹性,即使某个节点发生故障或关机,也能迅速在其他节点拉起一个副本并运行。
总结一下,整个过程有5个关键点:上报标记
删除
调度
启动。以上任何一个点不满足都会导致弹性能力不可用,表现出来就是pod不能自动故障转移。而我们作为观测者只能看到界面上的“一片红”,于是我们认为是K8S的调度能力不行,其实跟K8S的调度机制和我们自己的配置都有关系。
上面总结的4个问题大类,正好就能覆盖整个过程的所有关键点。
1.Node1和Node2宕机影响范围不一样
因为系统后端使用的数据库不是云数据库而是本地数据库,该数据库部署在Node1节点,当Node1宕机不可用后数据库也不可用,所有使用数据库的后端容器全都无法启动。这也解释了无状态负载无法漂移问题,其实是已经调度到其他可用节点了,只是容器无法启动。容器启动不存在问题的话就正常漂移,所以少量不用数据库的前端服务都成功漂移了。
还有一类微服务是漂移多个副本,但只能启动一个,其他的就报错。怎么说?能漂,但只能漂一点点......原因是yaml里面的配置有问题,配置了hostport,导致容器在启动时会通过主机的某个特定端口映射,主机端口只有一个,所以只能启动一个副本,其他的会端口冲突启动不了。
这类问题是属于:调度成功而启动失败。
2.有状态负载全都无法自动故障转移
有状态负载运行在某个节点而节点突然宕机的话,这个有状态负载是不能自动故障到其他可用节点的。K8S的官方文档说是可以,但是只是理论上可以,实践中验证了华为云CCE(也是基于K8S封装的云容器引擎),如果宕机一个节点,无状态负载可以自动故障转移但是有状态负载不可,可能跟K8S调度的原理和有状态负载的设定有关系。
StatefulSet 运行时每个 Pod 都会被赋予一个唯一的标识符,并且具有稳定的网络标识符。在节点失败或宕机时,Kubernetes 调度器会自动将具有相同标识符的 Pod 调度到其他可用的节点上。这样可以确保有状态负载的持久性和可靠性。而如果一个有状态负载的Pod状态一直是 “Terminating”,就不会触发自动故障转移了。当一个 Pod 需要终止时,Kubernetes 会按照一定的顺序执行终止操作,例如发送终止信号给容器、断开网络连接等。这些终止操作可能需要一些时间来完成。只有当 Pod 完全终止后,它才会被从节点中移除并允许重新调度到其他可用节点上。
为了验证这个想法,用华为云CCE部署了一个有状态负载mysql数据库,然后在调度节点上宕机测试,发现该负载的pod虽然标记了删除但实际上一直是运行状态,然后进入容器查看,mysql数据库已经停了,service mysql status 返回没有服务,相关的目录均已删除。但是这个容器并没有停止和删除,甚至网络通信还是通的。不过看日志是看不出来什么的,这些过程都没有跑日志。
因此可以确定,当节点突然宕机后,StatefulSet是不可能自动故障转移的,不管是原生的K8S还是云服务,这其实是K8S对StatefulSet的一种保护机制。如果是用StatefulSet部署数据库或者redis之类的,宕机就麻烦了,甚至会让用数据库的服务也都启动不了。
这类问题是属于:删除不掉而无法调度。
3.所有的pod全都标记删除但删不掉
因为K8S调度的过程在一开始就说了,是需要kubelet向主节点报告节点的状态,而且控制器通过Kubernetes API与集群进行交互。当节点宕机,其上运行的组件也都无法与控制器通信了,控制器是可以将pod标记为删除,但是后续的状态完全不知道了。所以我们会看到pod标记为删除中,然后就没有然后了......
这类问题是属于:标记成功而无法删除。
4.重复调度导致副本在一个节点上堆积,堆到极限
这个现象的产生原因是调度的策略不合理,当节点宕机后控制器本来应该调度到其他正常节点,但是在部署时指定了调度节点,又设置了滚动更新,于是控制器不停地在这个宕机节点拉起副本,但是节点又不可用,于是拉起就删掉,删掉又拉起......最终堆满。
这类问题是属于:调度失败且无法删除。
【解决方案】
1.调度成功而启动失败问题
能漂移一个的无状态负载改yaml去掉Hostport即可,这个配置最好不要用。yaml中的端口类型有好几种,容器端口、服务端口、主机端口、节点端口,各自都有不同的作用,不要用混。
要解决这类数据库导致无法启动的问题,首先要问:为什么要使用本地数据库?另外,因为后端服务都是研发同事自己部署的,大家的部署习惯都不一样,有用Nacos转发的,有直接写在启动参数的,还有用环境变量的,但是终归都是用同一个本地数据库,可是这种部署习惯很不利于自动化和排错(好在没有直接写死在后端服务框架里面的,要不真的完蛋了)。
所以要抛弃本地部署数据库,一定要本地部署那么数据库要备份并且保持数据同步,这样主数据库出问题的话迅速切备用。
——该方案没有通过:数据库已经占用了很多存储空间,再做备份资源紧张;且数据同步要么定期备份还原,要么用同步工具,要么应用做双写,都没有人做emmmm。其实根本原因还是资源太紧张啦,就算做备份一共就两个服务器节点,万一都宕机了捏。
plan B:将有状态存储托管给云,同时还能提升一下serverless成熟度。
——该方案也没有通过:用有状态服务部署mysql倒是可以,但是部署完之后需要做数据库迁移,没有人做;做数据双写和同步都需要改业务,还是没人做;业务每秒都在用数据库,缺少割接机会;另外那个有状态负载无法故障转移的问题还没解决,就算有状态托管给云也没用;最关键的是,有状态负载部署数据库一定要配合持久化存储,要不数据丢失就完了,可是我们也没有云硬盘来做持久化存储,都是存储到本地做共享目录,那一旦服务器宕机共享存储也不能用了,数据库可读不可写会丢数据,综上over。
plan C:云数据库
——这个方案大家都同意,只是现阶段没法购买资源,等后续项目可以这么设计。
2.调度失败且无法删除问题
这个好解决,所以优先解决。
重复调度到一个节点,改yaml里面一个字段就行了spec.nodeName或spec.node或spec.nodeSelector,都是指定调度到某个节点,只是匹配机制不一样。去掉就行,当然要先跟后端同学确认这个指定调度是否有什么特殊原因。
顺带一提其他的调度策略,Node Affinity和podAffinity是亲和性,podAntiAffinity是反亲和性,能让Pod被调度到一类特定的节点上;污点(Taint)使节点排斥一类特定的Pod(由容忍度决定),从而避免Pod调度到该节点上,配合容忍度(Tolerations)使用。具体怎么用可以查官方文档,也跟K8S的版本有关系,幸好我们的环境只用了比较简单的Taint&Tolerations,没啥影响。
3.标记成功而无法删除问题
这个是解决有状态负载无法故障转移的前提。
已知节点宕机后其上的组件都无法与控制器通信,那么标记删除而无法删除的后续是不能操作的,所以应该换个思路,就是不去管这个pod后面怎么样了,直接强制删除它。
K8S的yaml中有个字段terminationGracePeriodSeconds默认是30,有说法是该字段设置强制删除时间,其实不是,这个字段是优雅终止时间,意思是在终止pod之前会等待30s,但是依然不改变标记删除的流程,所以没用。
真正强制删除的参数是--force,命令:kubectl delete pod my-pod --grace-period=0 --force
该命令无法添加在yaml中,如果要批量删除必须通过脚本或编程写方法。Shell脚本参考:
#!/bin/bash
# 查找状态为 "Terminating" 的 Pod
terminating_pods=$(kubectl get pods --all-namespaces --field-selector=status.phase=Running --output=json | jq -r '.items[] | select(.metadata.deletionTimestamp) | .metadata.namespace + "/" + .metadata.name')
# 强制终止每个找到的 Pod
for pod_with_namespace in $terminating_pods; do
namespace=$(echo $pod_with_namespace | cut -d'/' -f1)
pod=$(echo $pod_with_namespace | cut -d'/' -f2)
echo "pod: $pod"
echo "namespace: $namespace"
#在这里使用namespace和pod进行操作
kubectl delete pod $pod -n $namespace --grace-period=0 --force
done
解释一下脚本的意思:用get pods获取所有状态为 “Running” 的 Pod,并使用 jq 工具过滤出带有 deletionTimestamp 字段的 Pod,即被标记为 “Terminating” 的 Pod。这句可以先执行测试一下,没有jq工具的yum install先装一个。jq必须装,--output=json参数指定以 JSON 格式获取所有符合条件的 Pod 的列表,jq是json分析的工具。后面用for做了一个循环,在循环中通过变量扩展展开为每个 Pod 的命名空间/名称,删掉过滤出来的每个namespace下的pod。
4.删除不掉而无法调度问题
可以将脚本设置为定时任务 crontab -e 创建任务,然后输入如下代码设置每10min执行一次:
*/10 * * * * /labfile/deployfile/Terminatepod.sh经测试,当节点宕机后短时间内无法终止掉有状态负载,定时任务会通过脚本强制删除,有状态负载就可以重新在其他节点拉起啦。
5.安装工具缺乏yum源问题
插入一个小技巧:我们是政务云行政域网段,与互联网是隔离的,所以用yum之类的比较麻烦,但是发现用代理就可以,命令http_proxy=http://XXXX https_proxy=http://XXXX yum install jq
在测试环境设置完之后,成功把测试环境调度问题解决了,除了用数据的服务其他服务成功拉起。打算把同样的解决方案复制到正式环境,因为正式环境不能宕机,所以把某个前端服务优雅终止时间改成600,然后任务时间改成1min,结果发现没作用,真是绝绝子。
测试脚本执行发现是kubectl get pods这句就没结果,单执行这条语句提示没有jq工具,于是用代理yum install jq结果也没用,报错could not open file ......:
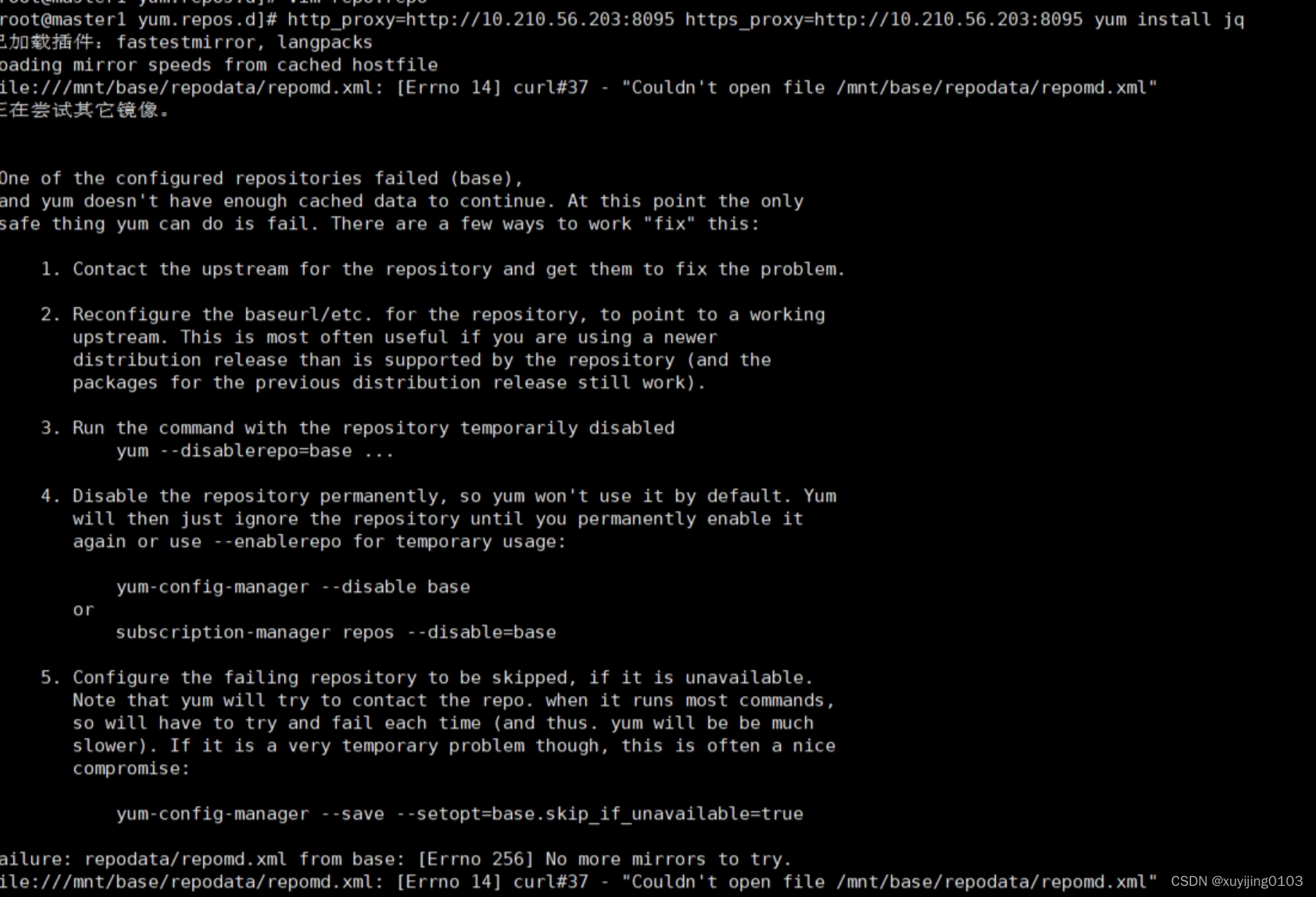
这类报错都是因为yum源配置有问题,因为缺少必要的yum源文件,可以用scp命令或者xftp把正常的yum源拷贝过来,缺哪个就拷贝哪个。
不幸的是这个环境是物理机,登录都是用的堡垒机,不能访问本机ip的,所以scp和xftp都不能用了,只能手动vim。yum源配置完之后又报错如下:

报错的意思是缺少rpm的公钥,同样拷贝正常环境的公钥就行,就是缺的有点多,一个一个vim比较费时费力。最终安装成功就可以了。


















 1915
1915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









