







昨天老板气呼呼跑到我面前问我是不是根本不懂Zookeeper分布式协调,当时气不打一出来奋笔疾书写下这篇小见解,直接让他无话可说 于是乎我今天在这里分享给大家,希望对我们各位码农们有所帮助。
官方的解释:
一个中心化的分布式协调框架,它主要是用来解决分布式应用中经常遇到的一些数据管理问题。
如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
“神马?数据管理,那不是数据库干的事情么”。如果你这么理解就对了,Zookeeper其实你暂时就可以理解为,它是一个基于内存的数据库。对于上述这些名词(统一命名服务,状态同步,集群管理,分布式应用配置项),不熟悉分布架构的同学可能会有点蒙,不过没关系,我会通过很多的案例给同学们解释清楚这些到底都是啥,以及它存在的意义。
在了解Zookeeper之前,需要对分布式相关知识有一定了解,如果有了解过可以直接忽略,什么是分布式系统呢?通常情况下,单个物理节点很容易达到性能,CPU计算或者内存容量,网络IO 的瓶颈,所以这个时候就需要多个物理节点来共同完成某项任务,一个分布式系统的本质是分布在不同网络或计算机上的程序组件,彼此通过信息传递来协同工作的系统,而Zookeeper正是一个分布式应用协调框架,在分布式系统架构中有广泛的应用场景。
先来看看Zookeeper 的两个核心概念:
1,Zookeeper 核心概念
2, 文件系统的数据模型
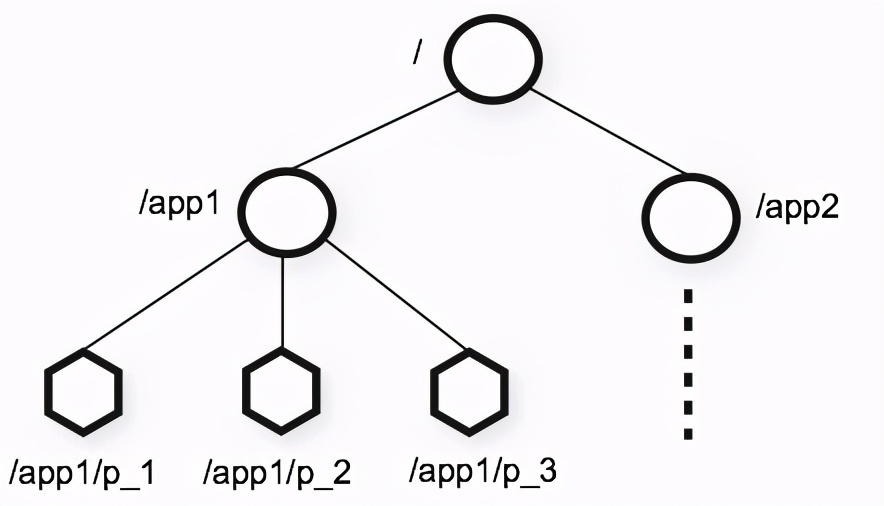
Zookeeper维护一个类似文件系统的数据模型
每个子目录项都被称作为 node(目录节点),和文件系统类似,我们能够自由的增加、删除node,在一个node下增加、删除子znode。
有6 种类型的znode:(3.5.x版本以前只有前面四种)
1)、PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只要不手动删除该节点,他将永远存在
2)、 PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3)、EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
4)、EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
5)、Container 节点(3.5.3 版本新增,如果Container节点下面没有子节点,则Container节点在未来会被Zookeeper自动清除,定时任务默认60s 检查一次)
6)、TTL 节点( 3.5.3 版本新增,默认禁用,只能通过系统配置 zookeeper.extendedTypesEnabled=true 开启,不稳定)
2, 事件监听机制
客户端注册监听它关心的任意节点,或者目录节点及递归子目录节点
1. 如果注册的是对某个节点的监听,则当这个节点被删除,或者被修改时,对应的客户端将被通知
2. 如果注册的是对某个目录的监听,则当这个目录有子节点被创建,或者有子节点被删除,对应的客户端将被通知
3. 如果注册的是对某个目录的递归子节点进行监听,则当这个目录下面的任意子节点有目录结构的变化(有子节点被创建,或被删除)或者根节点有数据变化时,对应的客户端将被通知。
注意:所有的通知都是一次性的,及无论是对节点还是对目录进行的监听,一旦触发,对应的监听即被移除。递归子节点,监听是对所有子节点的,所以,每个子节点下面的事件同样只会被触发一次。
看完上面两个特性,可能还是不知道怎么玩,那下面就一起来安装使用一下,体验一下
3,Zookeeper 安装及实操
Zookeeper的安装非常简单,它本身是使用的Java语言编写,所以只要装好jdk环境就可以了
如果使用的 3.5.x 及以上版本需要 jdk8环境,
首先用 java -version 检查jdk版本, 确认是 jdk 8 后就可以进行 zookeeper版本下载了
本次案例用 zookeeper 3.5.8 版本进行演示 ,
环境准备:OS :centos 7
1.下载安装zookeeper
进到任意目录, 如 cd /usr/local/zookeeper
1 , 执行如下脚本进行 下载, 解压,运行
a.下载
wget https://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.5.8/apache-zookeeper-3.5.8-bin.tar.gz
b.解压
tar -zxvf apache-zookeeper-3.5.8-bin.tar.gz
c.运行
cd apache-zookeeper-3.5.8-bin
bin/zkServer.sh start conf/zoo_sample.cfg
2 , 连接使用:
bin/zkCli.sh -server ip:port
如果服务器和客户端都是在本机 可以直接运行 bin/zkCli.sh
3, 停掉服务
bin/zkServer.sh stop conf/zoo_sample.cfg
当然, 别急着停 ,接下来开始实操
zk的命令不多,也非常简单很好掌握,接下来一起实战吧
- Zookeeper 客户端实操
输入命令 help 查看zookeeper所支持的所有命令
1). 创建zookeeper 节点命令
create [-s] [-e] [-c] [-t ttl] path [data] [acl]
中括号为可选项,没有则默认创建持久化节点
-s: 顺序节点
-e: 临时节点
-c: 容器节点
-t: 可以给节点添加过期时间,默认禁用,需要通过系统参数启用
(-Dzookeeper.extendedTypesEnabled=true, znode.container.checkIntervalMs : (Java system property only) New in 3.5.1: The time interval in milliseconds for each check of candidate container and ttl nodes. Default is "60000".)
创建节点:
create /test-node some-data
如上,没有加任何可选参数,创建的就是持久化节点

查看节点数据:
get /test-node

修改节点数据
set /test-node some-data-changed

查看节点状态信息
stat /test-node
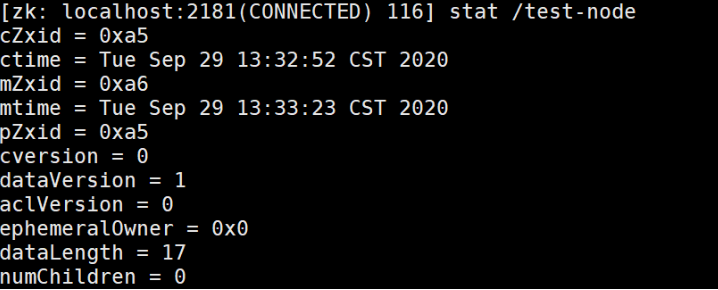
Stat: 字段含义
cZxid:创建znode的事务ID(Zxid的值)。
mZxid:最后修改znode的事务ID。
pZxid:最后添加或删除子节点的事务ID(子节点列表发生变化才会发生改变)。
ctime:znode创建时间。
mtime:znode最近修改时间。
dataVersion:znode的当前数据版本。
cversion:znode的子节点结果集版本(一个节点的子节点增加、删除都会影响这个版本)。
aclVersion:表示对此znode的acl版本。
ephemeralOwner:znode是临时znode时,表示znode所有者的 session ID。 如果znode不是临时znode,则该字段设置为零。
dataLength:znode数据字段的长度。
numChildren:znode的子znode的数量。
根据状态数据中的版本号有并发修改数据实现乐观锁的功能
比如: 客户端首先获取版本信息, get -s /node-test
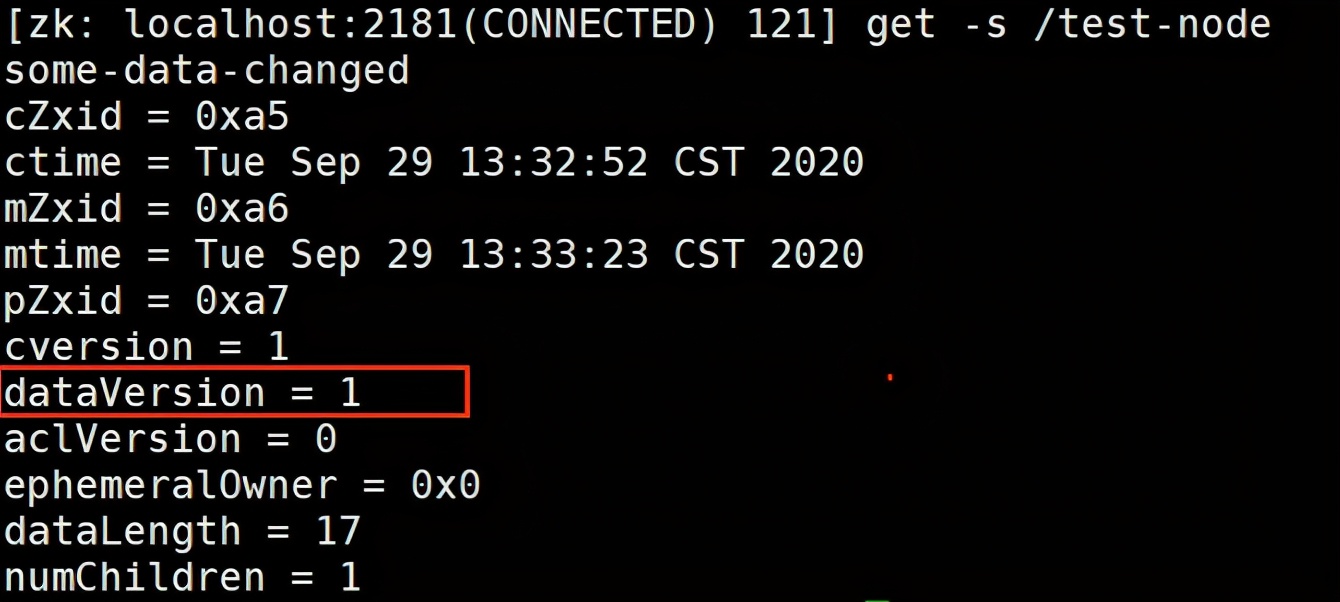
/test-node 当前的数据版本是 1 , 这时客户端 用 set 命令修改数据的时候可以把版本号带上

如果在执行上面 set命令前, 有人修改了数据,zookeeper 会递增版本号, 这个时候,如果再用以前的版本号去修改,将会导致修改失败,报如下错误

创建子节点, 这里要注意,zookeeper是以节点组织数据的,没有相对路径这么一说,所以,所有的节点一定是以 / 开头。
create /test-node/test-sub-node

查看子节点信息,比如根节点下面的所有子节点, 加一个大写 R 可以查看递归子节点列表
ls /
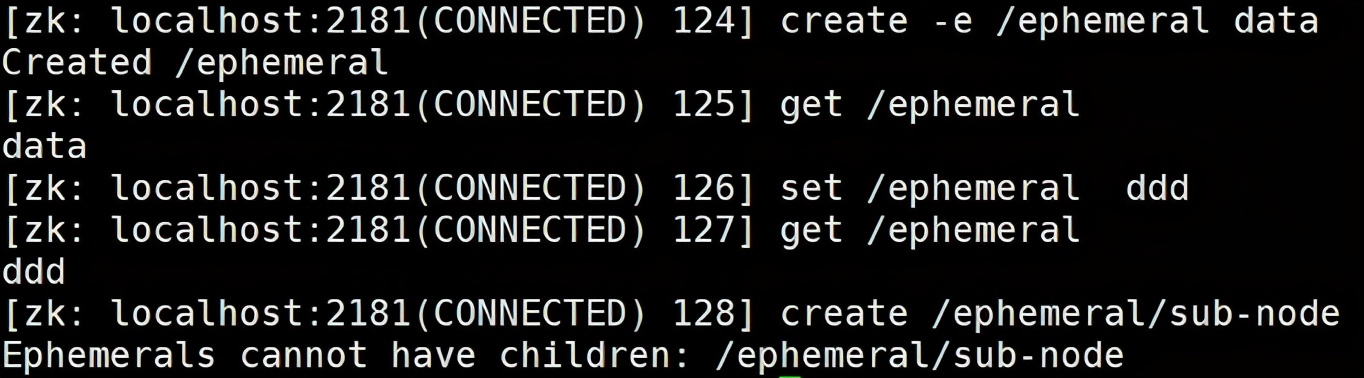
创建临时节点
create -e /ephemeral data
create 后跟一个 -e 创建临时节点 , 临时节点不能创建子节点
创建序号节点,加参数 -s
create /seq-parent data // 创建父目录,单纯为了分类,非必须 create -s /seq-parent/ data // 创建顺序节点。顺序节点将再seq-parent 目录下面,顺序递增
为了容纳子节点,先创建个父目录 /seq-parent

也可以再序号节点前面带一个前缀

创建临时顺序节点,其它增删查改和其他节点无异,不再贴图
create -s -e /ephemeral-node/前缀-
创建容器节点
create -c /container
容器节点主要用来容纳字节点,如果没有给其创建子节点,容器节点表现和持久化节点一样,如果给容器节点创建了子节点,后续又把子节点清空,容器节点也会被zookeeper删除。
2. 事件监听机制:
针对节点的监听:一定事件触发,对应的注册立刻被移除,所以事件监听是一次性的
get -w /path // 注册监听的同时获取数据
stat -w /path // 对节点进行监听,且获取元数据信息
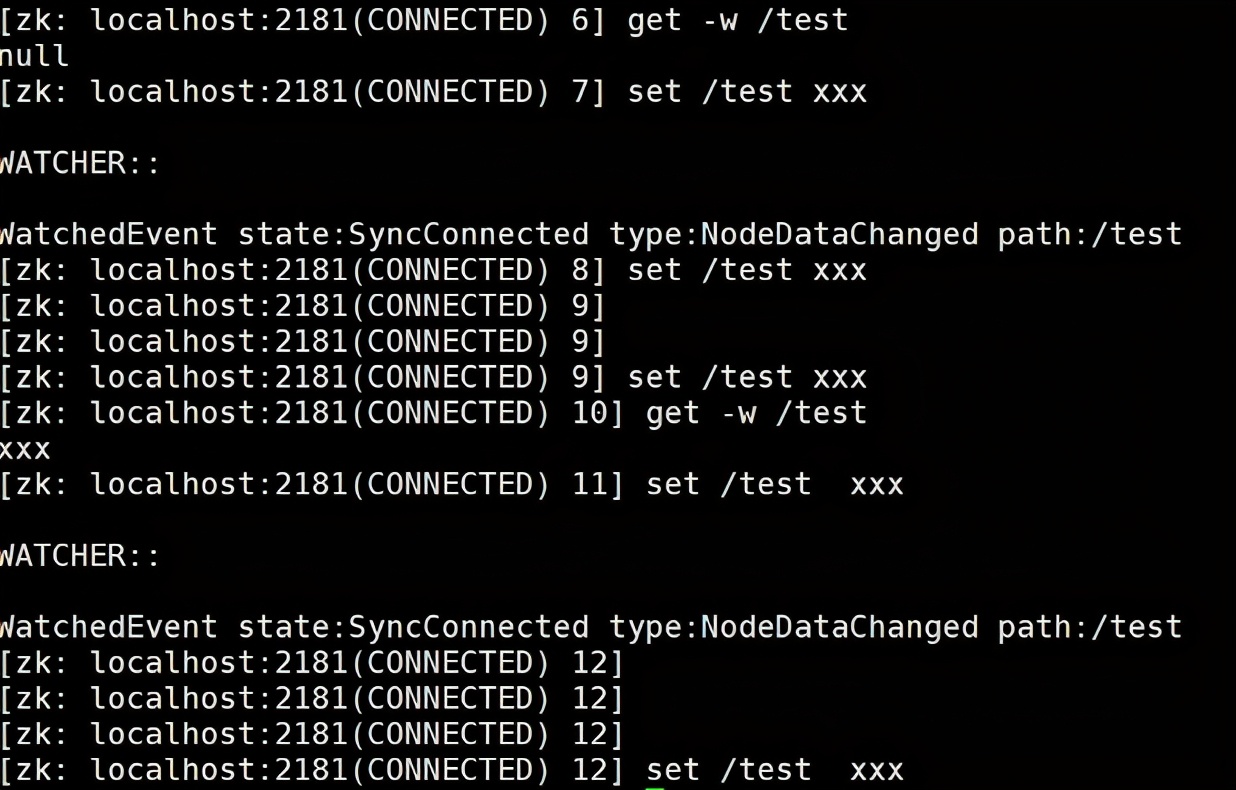
针对目录的监听,如下图,目录的变化,会触发事件,且一旦触发,对应的监听也会被移除,后续对节点的创建没有触发监听事件
ls -w /path
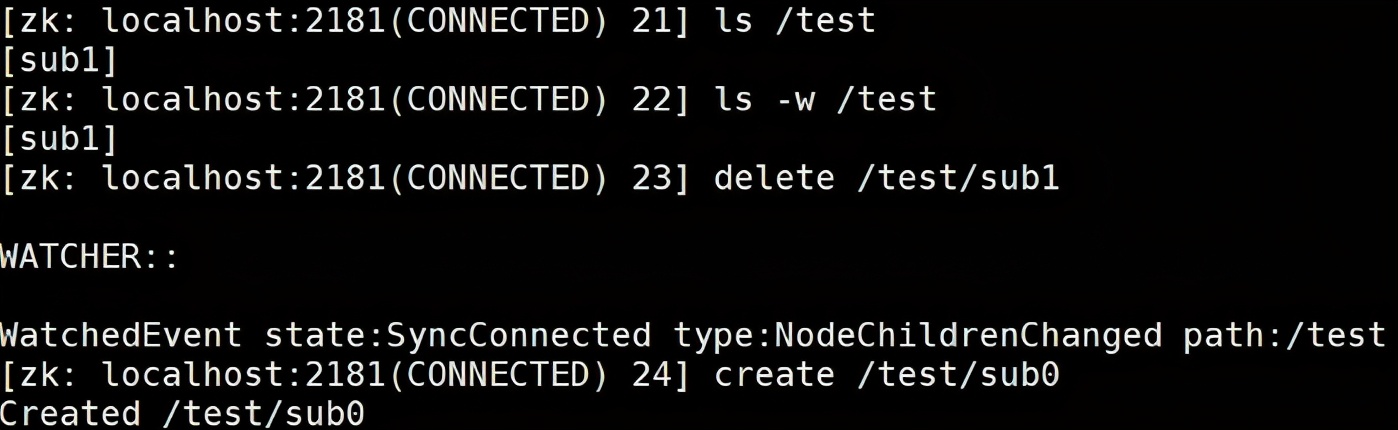
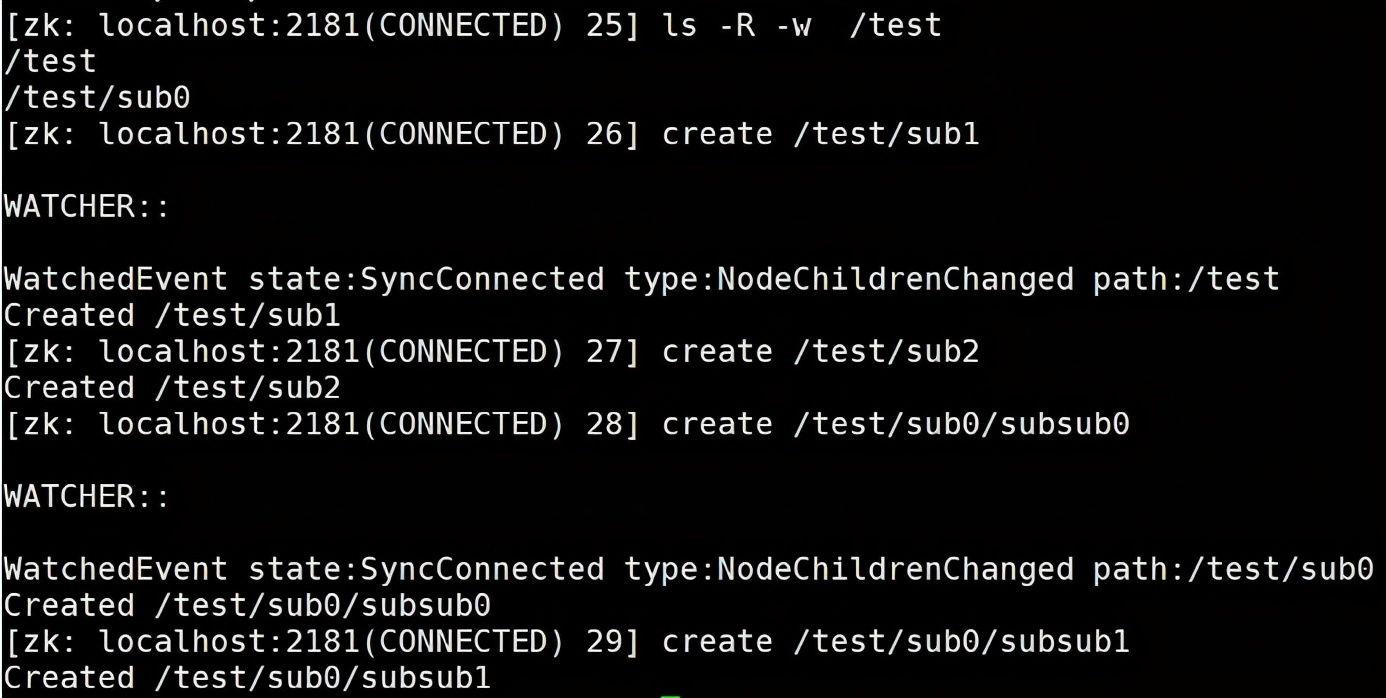
针对递归子目录的监听
ls -R -w /path : -R 区分大小写,一定用大写
如下对/test 节点进行递归监听,但是每个目录下的目录监听也是一次性的,如第一次在/test 目录下创建节点时,触发监听事件,第二次则没有,同样,因为时递归的目录监听,所以在/test/sub0下进行节点创建时,触发事件,但是再次创建/test/sub0/subsub1节点时,没有触发事件。
Zookeeper事件类型一览:
None: 连接建立事件
NodeCreated: 节点创建
NodeDeleted: 节点删除
NodeDataChanged:节点数据变化
NodeChildrenChanged:子节点列表变化
DataWatchRemoved:节点监听被移除
ChildWatchRemoved:子节点监听被移除
4, Zookeeper 客户端使用
1). 原生客户端
由于zookeeper 客户端和服务端源码是绑定在一起的,强烈建议使用和服务端代码相同版本的 客户端
引入 maven
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.8</version>
</dependency>
核心代码:
private static final int SESSION_TIMEOUT = 5000;
private static ZooKeeper zooKeeper;
private static final String ZK_NODE="/zk-node";
private static final String ZK_ADDRESS="192.168.1.100:2181";
public void init() throws IOException, InterruptedException {
final CountDownLatch countDownLatch=new CountDownLatch(1);
zooKeeper=new ZooKeeper(ZK_ADDRESS, SESSION_TIMEOUT, event -> {
if (event.getState()== Watcher.Event.KeeperState.SyncConnected &&
event.getType()== Watcher.Event.EventType.None){
countDownLatch.countDown();
log.info("连接成功!");
}
});
log.info("连接中....");
countDownLatch.await();
}
init 方法被执行后,就可以用zookeeper 实例进行操作
完整代码已提交到代码库,需要找班主任开启权限
2). curator
官网 http://curator.apache.org/
引入curator
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.0.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.8</version>
</dependency>
初始化CuratorFramework , 并且调用 start 方法后, 就可以进行 对Zookeeper服务端的操作了。
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3)
CuratorFramework client = CuratorFrameworkFactory.newClient(zookeeperConnectionString, retryPolicy);
client.start();
完整代码已提交到代码库,需要找班主任开启权限
5, 经典应用场景分析
- 配置中心
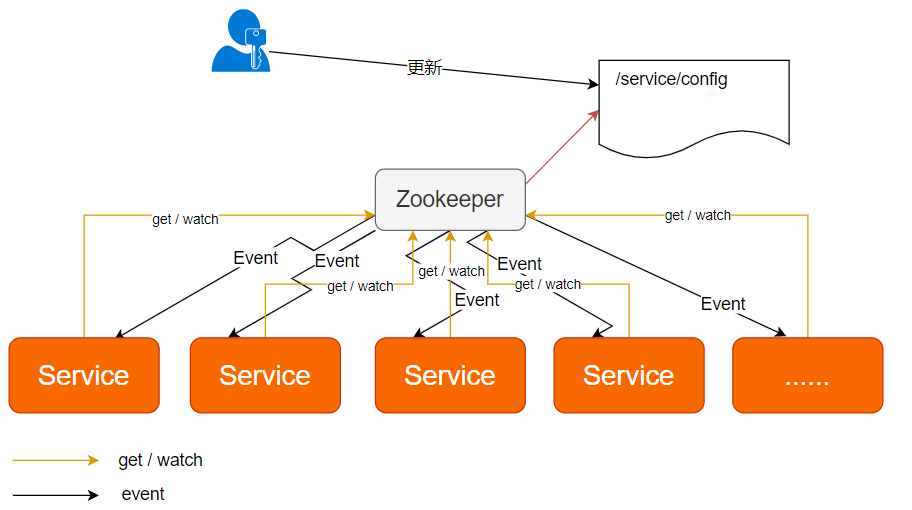
- 注册中心
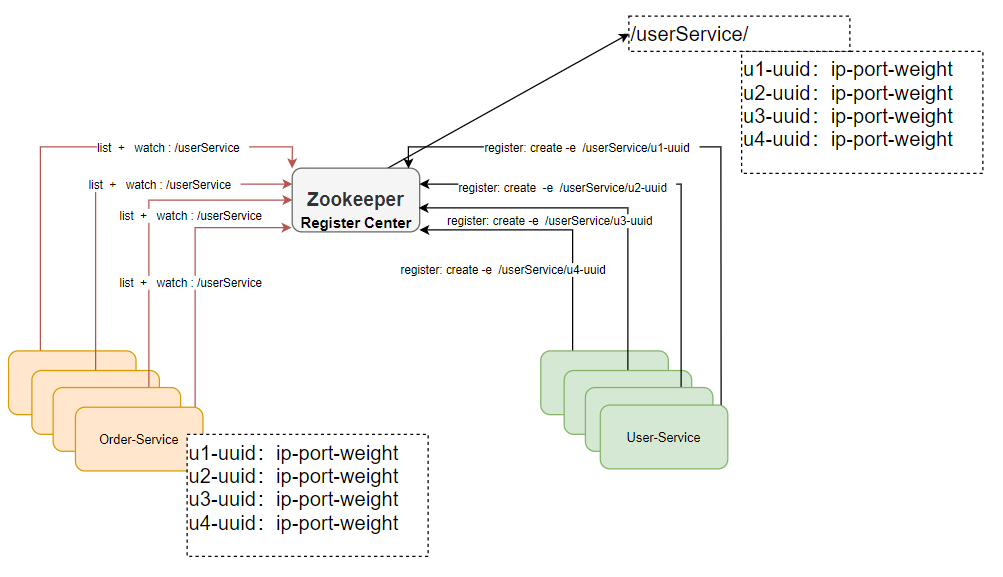
- 分布锁-非公平锁,公平锁,共享锁
1,非公平锁
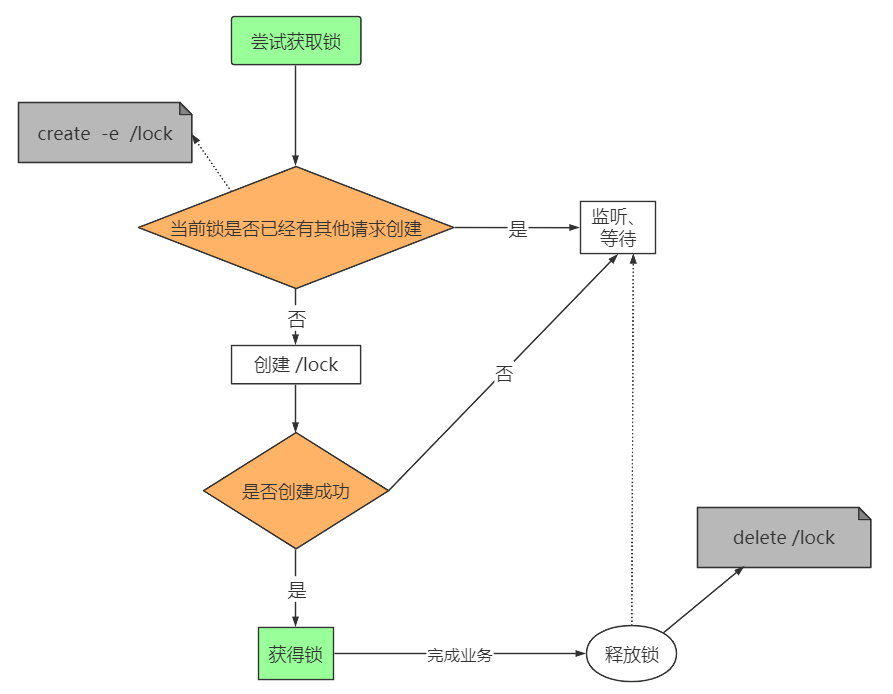
2,公平锁

- 请求进来,直接在/lock 节点下创建一个临时顺序节点
- 判断自己是不是lock节点下,最小的节点
a. 是最小的,获得锁
b. 不是。对前面的节点进行监听( watch)
- 获得锁的请求,处理完释放锁,即 delete 节点,然后后继第一个节点将收到通知,
重复第2 步判断
3,共享锁
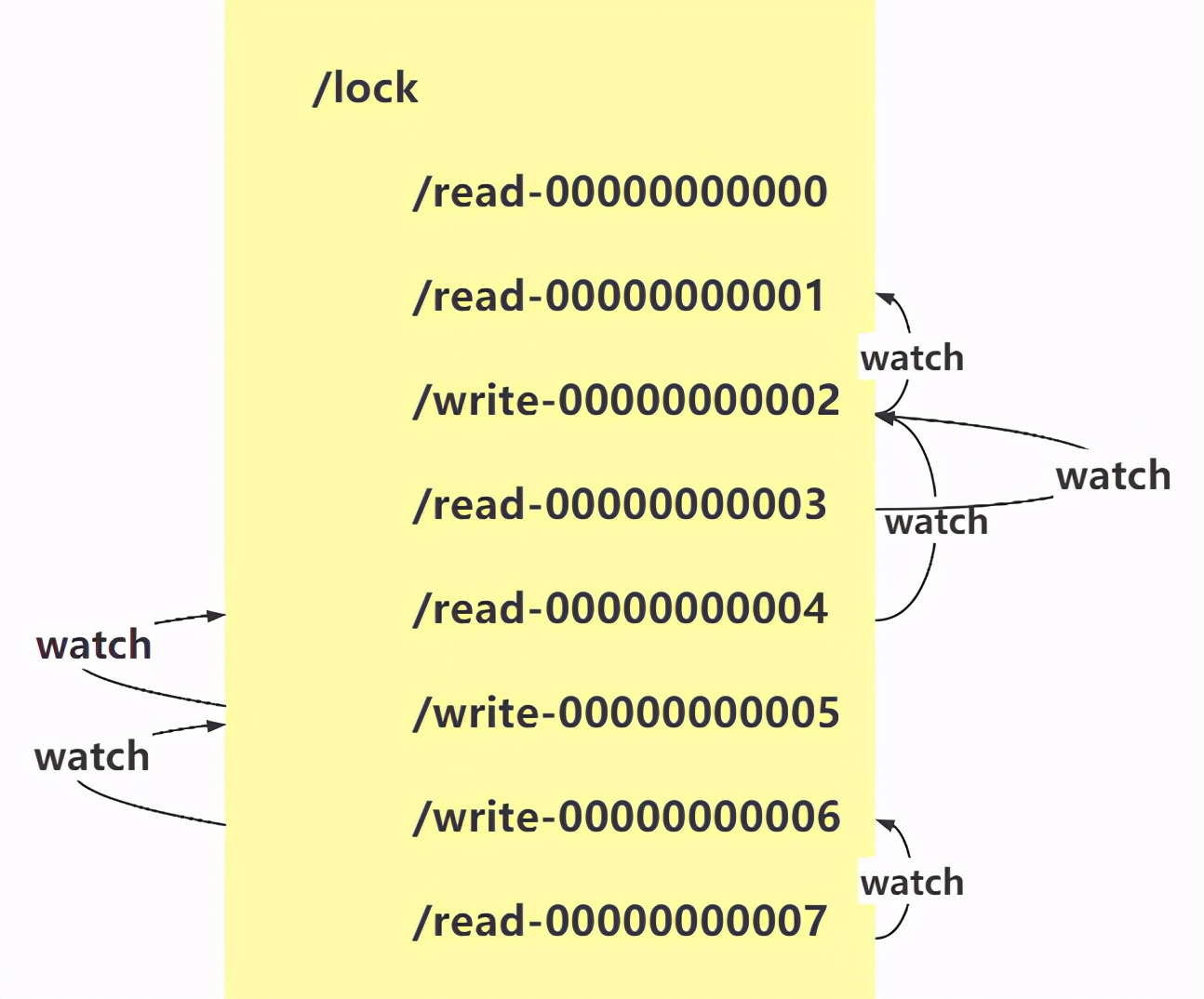
1. read 请求,如果前面的节点都是读锁,直接获取锁,如果read请求前面有写请求,
则该读请求不能获得锁,即需要对前面的写节点进行监听,如果是多个写请求,则
对最后的写请求进行监听
2. write 请求,只需要对前面的节点进行监听和互斥锁处理机制一样
6.精彩录播视频
- Redis核心源码分析
- Redis架构及集群分片原理
- 网络底层原理
- Zookeeper分布式锁
- Mysql性能优化
- Zookeeper注册中心与配置中心















 682
682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









