







#AI夏令营 #Datawhale #夏令营
前情回顾: 从零入门NLP竞赛和 Task1:了解机器翻译 & 理解赛题。
本节将对baseline代码做具体解析,可以从中学会 Seq2Seq模型结构、中英文分词、循环神经网络(RNN)、门控循环单元(Gated Recurrent Unit,GRU)等。
基于 Seq2Seq 的 Baseline 详解
在 task1 中我们已经提到了,当前机器翻译任务的主流解决方案是基于神经网络进行建模,依据赛题背景中意思,也是希望我们能用神经网络解决此英文翻译中文的任务。

通常我们基于神经网络解决机器翻译任务的流程如下:
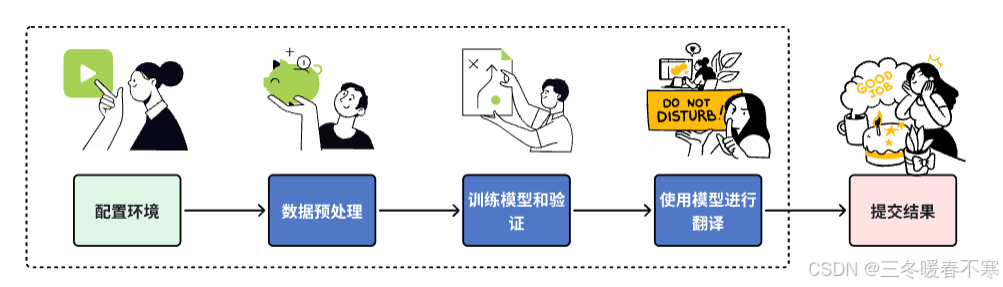
1.配置环境
运行环境我们还是基于魔搭平台进行模型训练,这里不再重复说明。另外,有几个包需要额外安装:
-
torchtext :是一个用于自然语言处理(NLP)任务的库,它提供了丰富的功能,包括数据预处理、词汇构建、序列化和批处理等,特别适合于文本分类、情感分析、机器翻译等任务
-
jieba:是一个中文分词库,用于将中文文本切分成有意义的词语
-
sacrebleu:用于评估机器翻译质量的工具,主要通过计算BLEU(Bilingual Evaluation Understudy)得分来衡量生成文本与参考译文之间的相似度
!pip install torchtext
!pip install jieba
!pip install sacrebleu-
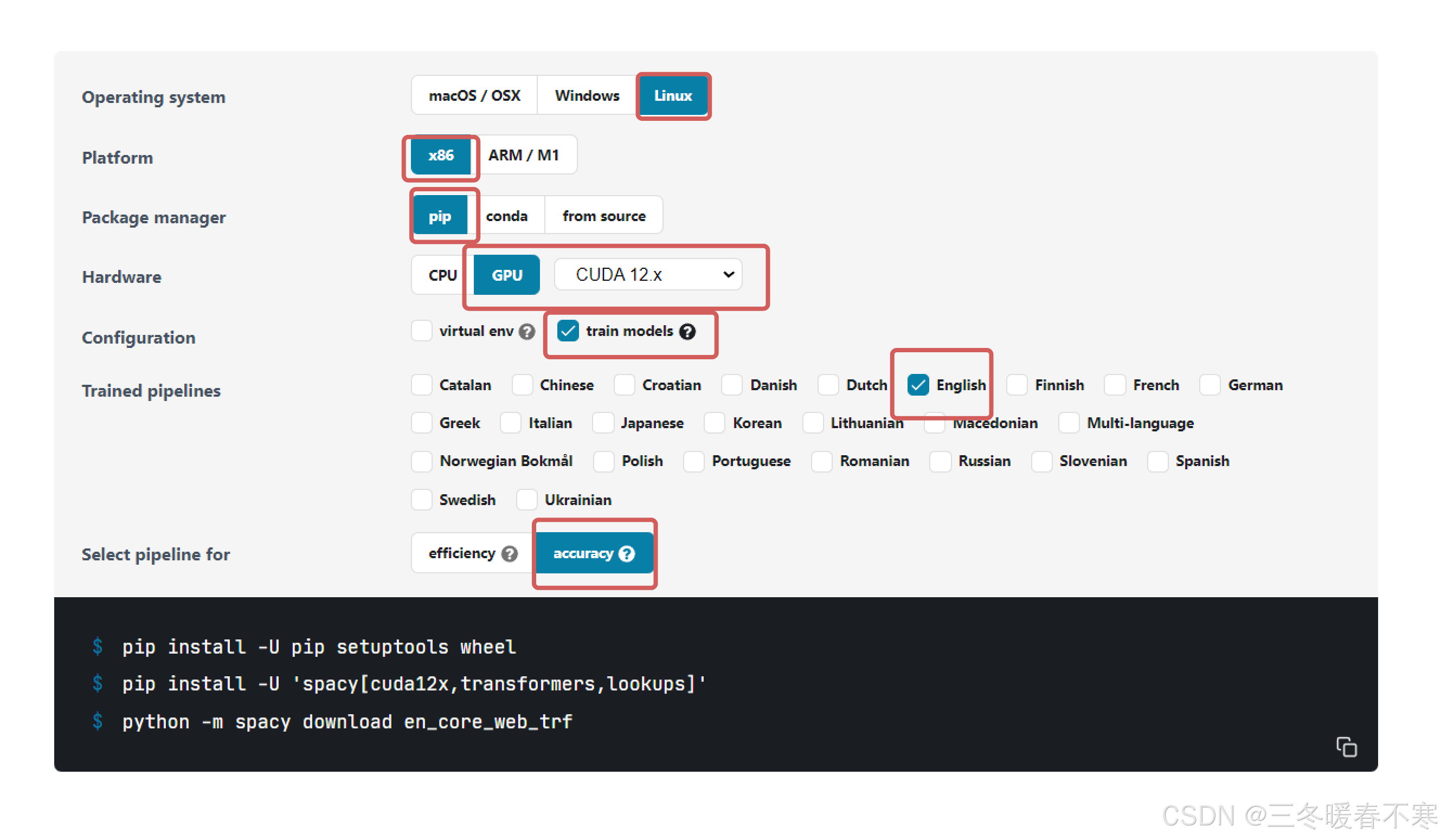
spacy:是一个强大的自然语言处理库,支持70+语言的分词与训练
即task2代码中:
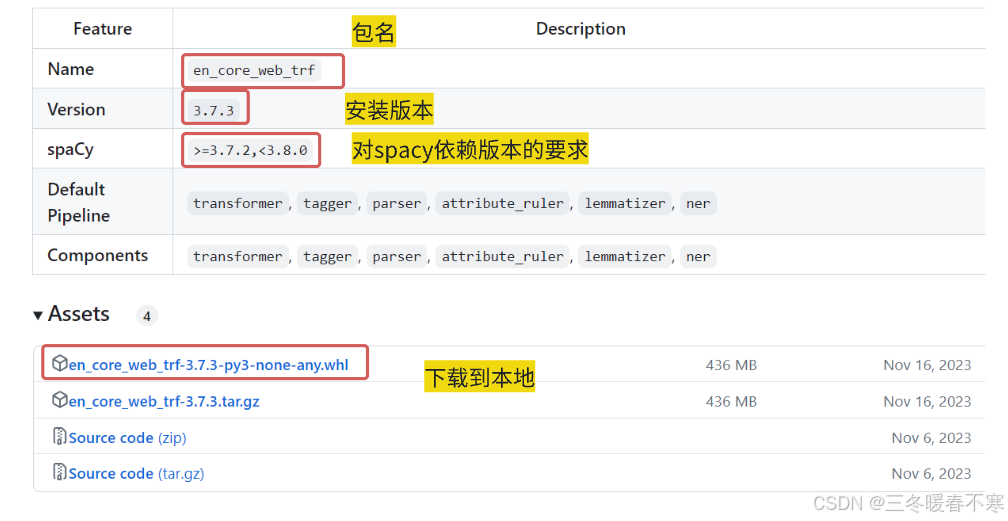
这里,我们需要安装 spacy 用于英文的 tokenizer(分词,就是将句子、段落、文章这种长文本,分解为以字词为单位的数据结构,方便后续的处理分析工作),不同环境的安装请参考:https://spacy.io/usage,如果使用魔搭平台,可按照下图中的配置进行安装:
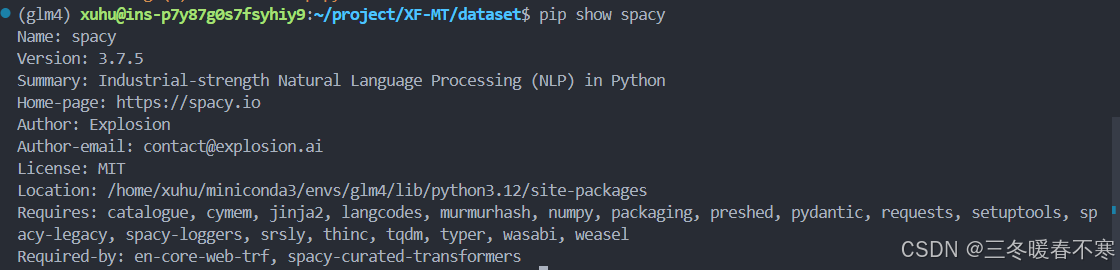
需要注意的是,使用命令!python -m spacy download en_core_web_trf安装 en_core_web_sm 语言包非常的慢,经常会安装失败,这里我们可以离线安装。由于en_core_web_sm 对 spacy 的版本有较强的依赖性,你可以使用 pip show spacy 命令在终端查看你的版本,可以看到我的是 3.7.5 版本的 spacy。
然后我们从该路径下:https://github.com/explosion/spacy-models/releases 安装对应版本的 en_core_web_trf 语言包,可以看到我的 en_core_web_trf 3.7.3 版本的要求 spaCy >=3.7.2,<3.8.0,刚好满足我的 3.7.5的 spacy!
将下载到本地的压缩包上传到你的魔搭平台上的 dataset 目录下:
![]()
然后使用 !pip install ../dataset/en_core_web_trf安装英文语言包:
!pip install -U pip setuptools wheel -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install -U 'spacy[cuda12x,transformers,lookups]' -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install ../dataset/en_core_web_trf-3.7.3-py3-none-any.whl这里在运行的时候需要注释以下行:
2.数据预处理
机器翻译任务的预处理是确保模型能够有效学习源语言到目标语言映射的关键步骤。预处理阶段通常包括多个步骤,旨在清理、标准化和转换数据,使之适合模型训练。以下是机器翻译任务预处理中常见的几个处理步骤:
-
清洗和规范化数据
-
去除无关信息:删除HTML标签、特殊字符、非文本内容等,确保文本的纯净性(本赛题的训练集中出现了非常多的脏数据,如“Joey. (掌声) (掌声) 乔伊”、“Thank you. (马嘶声) 谢谢你们”等这种声音词)
-
统一格式:转换所有文本为小写,确保一致性;标准化日期、数字等格式。
-
分句和分段:将长文本分割成句子或段落,便于处理和训练。
-
-
分词
-
分词:将句子分解成单词或词素(构成单词的基本组成部分,一个词素可以是一个完整的单词,也可以是单词的一部分,但每一个词素都至少携带一部分语义或语法信息),这是NLP中最基本的步骤之一。我们这里使用了使用
jieba对中文进行分词,使用spaCy对英文进行分词。
-
-
构建词汇表和词向量
-
词汇表构建:从训练数据中收集所有出现过的词汇,构建词汇表,并为每个词分配一个唯一的索引。
-
词向量:使用预训练的词向量或自己训练词向量,将词汇表中的词映射到高维空间中的向量,以捕捉语义信息(当前大模型领域训练的 embedding 模型就是用来完成此任务的)。
-
-
序列截断和填充
-
序列截断:限制输入序列的长度,过长的序列可能增加计算成本,同时也可能包含冗余信息。
-
序列填充:将所有序列填充至相同的长度,便于批量处理。通常使用
<PAD>标记填充。
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









