






一、概述
二叉树是算法中最基础和重要的数据结构,二叉树的遍历方式分为前序遍历(根左右)、中序遍历(左根右)、后序遍历(左右根)、层次遍历(按二叉树从上到下、从左到右遍历)。这些遍历方式中有递归写法和迭代二种写法,下面我们来讲解一下以上遍历方式的递归和迭代写法。
声明:以下二叉树的节点的都是如下的结构
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
二、遍历方式详解
1、前序遍历(根左右)
递归:根据前序遍历的方式根左右可以很快的写出如下代码
class Solution {
public void dfs(TreeNode root){
if(root==null){
return;
}
System.out.println(root.val+"->")//处理根节点
dfs(root.left);//递归遍历左子树
dfs(root.right);//递归遍历右子树
}
}
迭代:二叉树的迭代法可不像递归那么简单了,我们知道在计算机中的内部操作中,对递归的处理就是使用了栈(先进后出)这种数据结构,所以我们要手动的创建一个栈来模拟计算机中内部的处理过程。根据前序遍历是根左右(特别注意一下,根左右是处理节点时的逻辑顺序,处理就是我上面递归写法中的这句代码System.out.println(root+“->”)//代表正在处理根节点,注意下面会用到),每次先处理的是中间节点,那么先处理根节点,然后将右孩⼦加⼊栈,再加⼊左孩⼦。注意前面加粗的这句话,为什么要先加⼊ 右孩⼦,再加⼊左孩⼦呢? 因为栈是先入后出,这样出栈的时候才是中左右的顺序,即才是处理节点的顺序,如果不清楚看看代码就明白了。
class Solution {
public void preorderTraversal(TreeNode root) {
if(root==null){
return null;
}
Deque<TreeNode> stack=new LinkedList<TreeNode>();//这是一个栈
stack.push(root)//先将根节点入栈
while(!stack.isEmpty()){
TreeNode temp=stack.pop();//将根元素出栈
System.out.println(temp.val+"->");//处理根元素
//注意不能将下面二个处理的顺序写反了
if(temp.right!=null){
stack.push(temp.right)//处理右节点
}
if(temp.left!=null){
stack.push(temp.left)//处理左节点
}
}
}
}
2、中序遍历(左根右)
递归:根据中序遍历的方式左根右可以很快的写出如下代码
class Solution {
public void dfs(TreeNode root){
if(root==null){
return;
}
dfs(root.left);//递归遍历左子树
System.out.println(root.val+"->")//处理根节点
dfs(root.right);//递归遍历右子树
}
}
迭代:根据前序的迭代法,我们可不可以一葫芦画瓢写出中序呢,其实是不行的,因为在遍历二叉树时有二个操作,一个是访问顺序(应为二叉树都是从根开始向下的,所以不管什么遍历都是先从根开始的)和处理节点的顺序(即是遍历顺序,如中序是左根右),就拿上面介绍的前序遍历来说,访问顺序是先从根开始的,处理节点时也是根左右,所以代码比较简单。但是中序就不是了,不管什么遍历,都是从根开始的,所以访问顺序一定是根左右,而处理节点的顺序就是中序遍历的顺序(即左根右),访问顺序和处理顺序不一致,因此我们要借助指针的遍历来帮助访问节点,栈则⽤来处理节点上的元素。
class Solution {
public void preorderTraversal(TreeNode root) {
if(root==null){
return null;
}
Deque<TreeNode> stack=new LinkedList<TreeNode>();//这是一个栈
TreeNode temp=root;//借助temp指针来帮助访问节点
while(temp!=null||!stack.isEmpty()){
if(temp!=null){
stack.push(temp.left)//将左节点入栈
temp=temp.left;
//通过上面的if条件,我们可以一直向左找,直到找到最左的节点,
//并在这个过程中将二叉树的最左节点都入栈,
//这样当我们遇到空节点时就回去处理下面的逻辑,此时,
//我们看最左下脚的处理逻辑就可以看出是按我们想要的左根右处理的逻辑了
}else{
temp=stack.pop();//将根元素出栈
System.out.println(temp.val+"->");//处理根元素
temp=temp.right;//处理右节点
}
}
}
}
3、后续遍历(左右根)
递归:根据后序遍历的方式左右根可以很快的写出如下代码
class Solution {
public void dfs(TreeNode root){
if(root==null){
return;
}
dfs(root.left);//递归遍历左子树
dfs(root.right);//递归遍历右子树
System.out.println(root.val+"->")//处理根节点
}
}
迭代:根据上面的分析,中序遍历并不是那么好写,主要是访问顺序和处理节点的顺序不一致,我们分析一下后续遍历,就知道后续遍历也不好写(建议先去看看下面后续遍历的代码,在来看我的解释,看不懂没关系,过一下代码,让脑袋有点印象就可以了)。同样,后续遍历我们也需要先一直向左走**(** while(temp!=null){
stk.push(temp);//将节点放入栈中
temp=temp.left;
}),并且将走过的最左一排的节点放入栈中,当遇到空节点时,就弹出**(** temp=stk.pop();)以前压入栈中的数据,因为此时的节点是最左子节点,是一个叶子节点,所以temp.right==null为空,因此进入( if(temp.rightnull||pretemp.right){
System.out.println(temp.val+“->”)//处理根节点
pre=temp;
temp=null;
}**)**此时就引出了一个pre节点,这个节点是干什么用的呢,这个节点是用来记住当前节点的前一个已经处理过逻辑的节点的。这样当我们回溯到上一个节点时,就知道处理了上个节点没有。
class Solution {
public void postorderTraversal(TreeNode root) {
Deque<TreeNode> stk = new LinkedList<TreeNode>();
TreeNode temp=root,pre=null;
while(!stk.isEmpty()||temp!=null){
while(temp!=null){
stk.push(temp);//左节点入栈
temp=temp.left;//一直向左,碰到空返回,出栈中的数据,
//然后通过下面的代码先处理右子树,在处理中间节点.
}
temp=stk.pop();
if(temp.right==null||pre==temp.right){
System.out.println(temp.val+"->")//处理根节点
pre=temp;
temp=null;
}else{
stk.push(temp);
temp=temp.right;
}
}
}
}
4、层序遍历(从上到下、从左到右)
层序遍历一般都是迭代,递归的化要在特定的场景下,我们就先不说了。层序遍历迭代法我们与上面三种方法所借助的数据结构就不同了,上面三种是模拟递归,所以要借助栈,而我们并不是模拟递归,而根据层序遍历(从上到下、从左到右)我们就知道,我们应该要借助队列(先进先出)。下面跟着代码来分析
class Solution {
public void levelOrder(TreeNode root) {
Queue<TreeNode> queue=new LinkedList();
if(root!=null){
queue.offer(root);
}
while(!queue.isEmpty()){
int ceshu=queue.size();//用一个数,接住此时队列中数据的个数,
//即当前层的节点的个数,方便下面要从队列中到底要出几个元素。
for(int i=0;i<ceshu;i++){
TreeNode temp=queue.poll();
System.out.println(temp.val+"->")//处理节点
if(temp.left!=null){//将当前的左节点入队列
queue.offer(temp.left);
}
if(temp.right!=null){//将当前的右节点入队列
queue.offer(temp.right);
}
}
}
}
}
递归:前面说过层序遍历的递归,要和一些特定的使用场景绑定,那我们来说其中一个场景(来自力扣中的原题)。
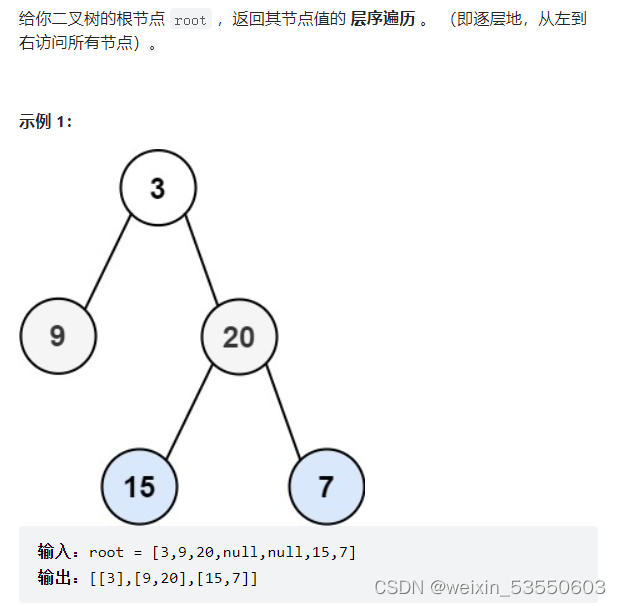
当我使用递归时,我们知道递归是深度优先,它会一条路径走到底,然后在返回到遇到分支的情况,在选择另一条一直走,所以层序遍历一般都不是用递归写法的,但是也有一些场景是可以用递归的,如上面的题目,上面的题目是让我们每一层节点都用一个数组存起来,其实二叉树递归写法我们一定会用到上面介绍的三种基本的递归写法,那用哪一种呢,三种都可以,我们就用前序来写吧。当我写递归的时候,我们就会想,当前的节点是在那个层呢,我们是一定要知道当前节点在哪个层的,只有知道了当前节点在哪个层,我们才能将相同层的节点都放到同一个数组中去,因此我们在递归时要借助一个变量来表示我当前的节点在哪个层。假设根节点在第0层,从上到下一次递增。具体分析看代码中的注释。
class Solution {
List<List<Integer>> result=new ArrayList<List<Integer>>();//用来存储各层数组的数组
public List<List<Integer>> levelOrder(TreeNode root) {
dfs(root,0);//根节点的层数初始化为0
return result;
}
public void dfs(TreeNode root,int lefv){//参数lefv记录当前节点在第几层
if(root==null){//当遇到最底层的空节点,直接返回
return;
}
if(result.size()<lefv+1){//存放结果数组的数组大小如果小于层数,说明存放结果的数组的数组不够了,
//在加入一个存放当前lefv层的数组,用此数组来专门存放lefv层的数据.
result.add(new ArrayList<Integer>());
}
result.get(lefv).add(root.val);//处理根节点
dfs(root.left,lefv+1);//递归处理左子节点
dfs(root.right,lefv+1);//递归处理右子节点
}
}















 826
826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









