






目录
引言
近来,丧尸题材的电影一直在全球范围内受到观众的热爱。通过网络电影评分平台,可以挖掘出很多有趣的信息,探讨电影评分、评价数以及影片内容之间的关系。将通过对一组丧尸电影数据的分析,探索分配评分、评价数与评分关系的,以及电影上映年份的影响。
数据概览
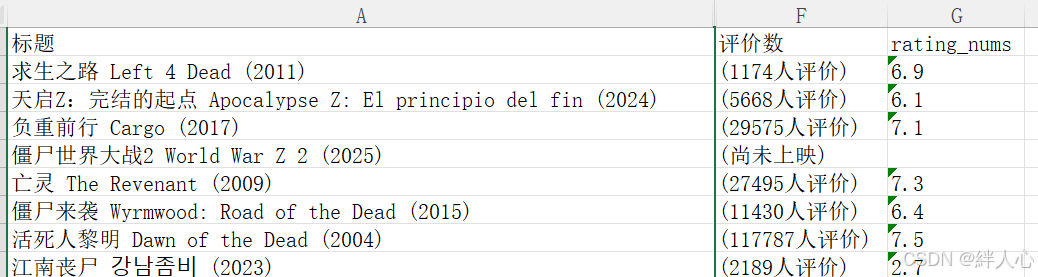
本文的数据来源于网络电影平台,包含了一些部丧片电影的评分、评价数等信息。以下是数据集的目标字段:
- 标题:电影名称
- 评分:用户给出的评分(1-10分)
- 评价数:参与评分的用户数量
- 年份:电影上映年份
通过这些字段,可以进行基本的统计分析和一些可视化,了解丧尸电影的整体评分趋势以及受欢迎程度。
数据预处理
在进行数据分析之前,对数据进行了预处理,主要步骤包括:
- 列名修改:为了方便分析,将原始列名修改为更易懂的名称。
- 抓取值处理:从标题中将电影的上映年份提取出来;对于评分数据,采用均值填充;对于评价数为空的数据,使用0填充。
- 过滤无效数据:删除包含无效评价数(如“(尚未上映)”或“(暂无评分)”)的电影。
- 数据类型转换:将评价数转换为整数类型,并从电影标题中提取上映年份信息,转换为整数类型。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 使用微软雅黑字体
plt.rcParams['axes.unicode_minus'] = False # 解决符号乱码问题
# 加载数据
df = pd.read_excel('./丧尸电影.xlsx')
# 修改列名
df = df.rename(columns={'rating_nums': '评分'})
# 截取有效数据
df = df[['标题', '评价数', '评分']]
# 填充或删除缺失值
df['评分'] = df['评分'].fillna(df['评分'].mean())
df['评价数'] = df['评价数'].fillna(0)
# 过滤无效数据
df = df[~df['评价数'].isin(['(尚未上映)', '(暂无评分)'])]
# 删除空白行
df = df.dropna()
# 处理评价数字段,并转类型
df['评价数'] = df['评价数'].str.split("(").str[1].str.split("人").str[0]
df['评价数'] = df['评价数'].astype('int')
# 处理年份字段,并转类型
df['年份'] = df['标题'].str.split("(").str[1].str.split(")").str[0]
df['年份'] = df['年份'].astype('int')
# 排序数据
df = df.sort_values(by=['年份', '评分'], ascending=[False, False])
评分分布情况
首先,对丧尸电影的评分进行分布分析,了解评分的集中程度及分布情况。通过直方图,可以观察到评分在什么范围内的集中程度,是否存在明显的偏差。
# 评分分布分析
sns.histplot(df['评分'], kde=True)
plt.title('丧尸电影评分分布')
plt.xlabel('评分')
plt.ylabel('频数')
plt.show()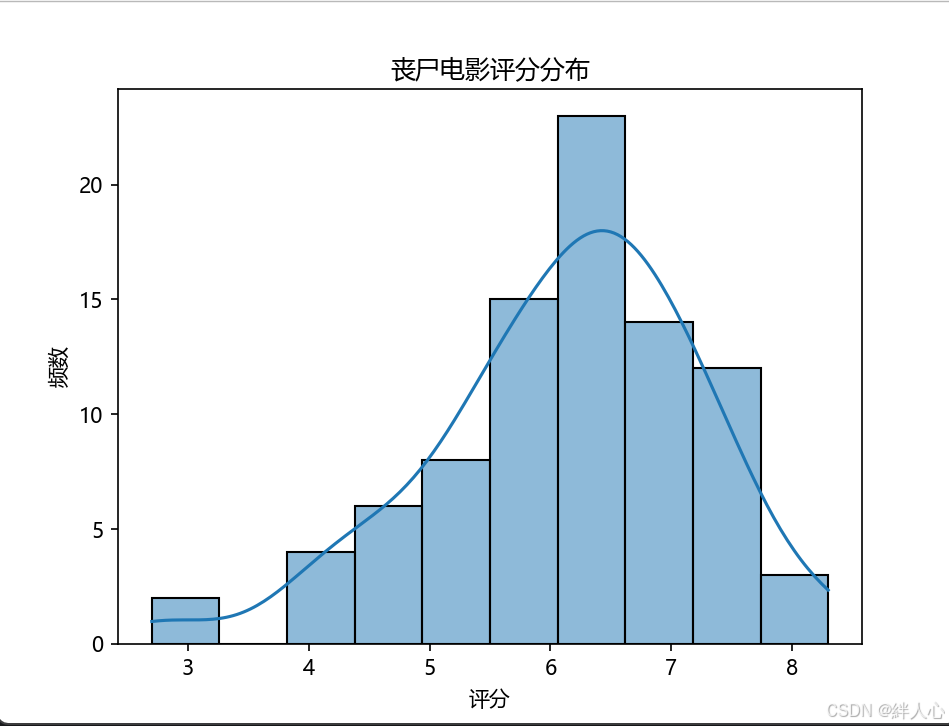 分析结果:通过评分分布图,发现大部分评分集中在6-7分之间,表明大部分丧片的观众对影片的评分中等偏下,少数影片的评分较低。
分析结果:通过评分分布图,发现大部分评分集中在6-7分之间,表明大部分丧片的观众对影片的评分中等偏下,少数影片的评分较低。
评分数与评分分析
接下来,通常探讨评价数与评分之间的关系的情况下,评价数基线的电影可能会有更准确的评分关系。通过散点图,能够判断评价数与评分之间的关系可能存在的潜在影响。
# 评价数与评分关系
sns.scatterplot(x='评价数', y='评分', data=df)
plt.title('评价数与评分关系')
plt.xlabel('评价数')
plt.ylabel('评分')
plt.show()
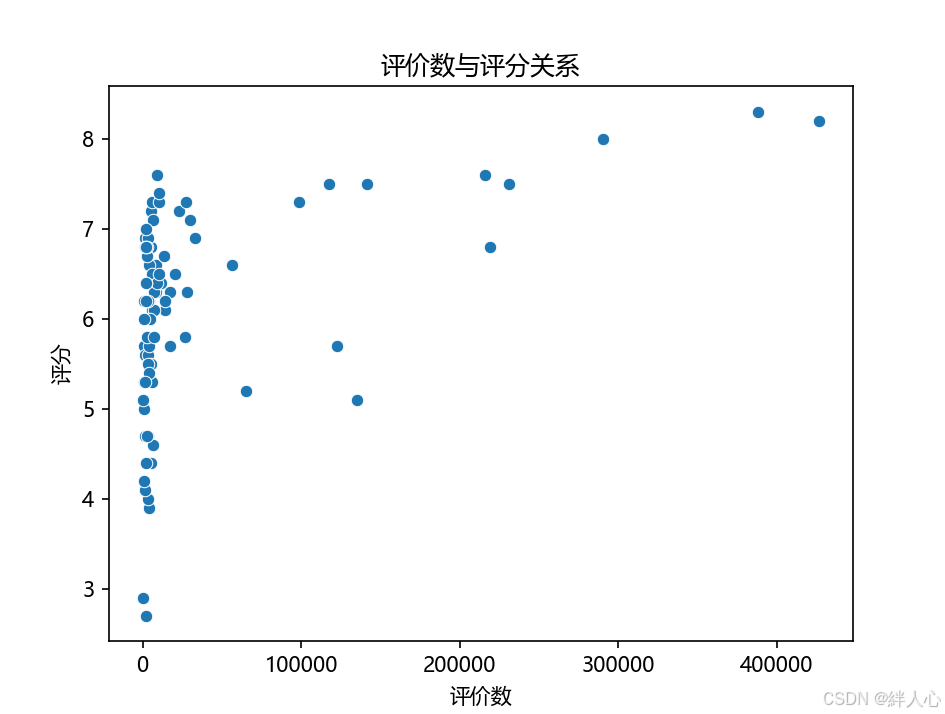 分析结果:散点图显示出评价数较高的电影主要集中在评分较高的区域,但也有少数电影评价数多但评分较低。这说明,评价数较多的电影往往得到了较为准确的评分,但并不是所有高评价电影都能获得高分。
分析结果:散点图显示出评价数较高的电影主要集中在评分较高的区域,但也有少数电影评价数多但评分较低。这说明,评价数较多的电影往往得到了较为准确的评分,但并不是所有高评价电影都能获得高分。
年份与评分分析
通过分析电影的上映年份与评分的关系,能够了解丧尸电影在不同年代的评分变化趋势。这对于预测未来丧尸电影的受欢迎程度具有一定的参考价值。
# 评分随年份变化的趋势
sns.lineplot(x='年份', y='评分', data=df, markers=True)
plt.title('丧尸电影评分随年份变化趋势')
plt.xlabel('年份')
plt.ylabel('评分')
plt.show()
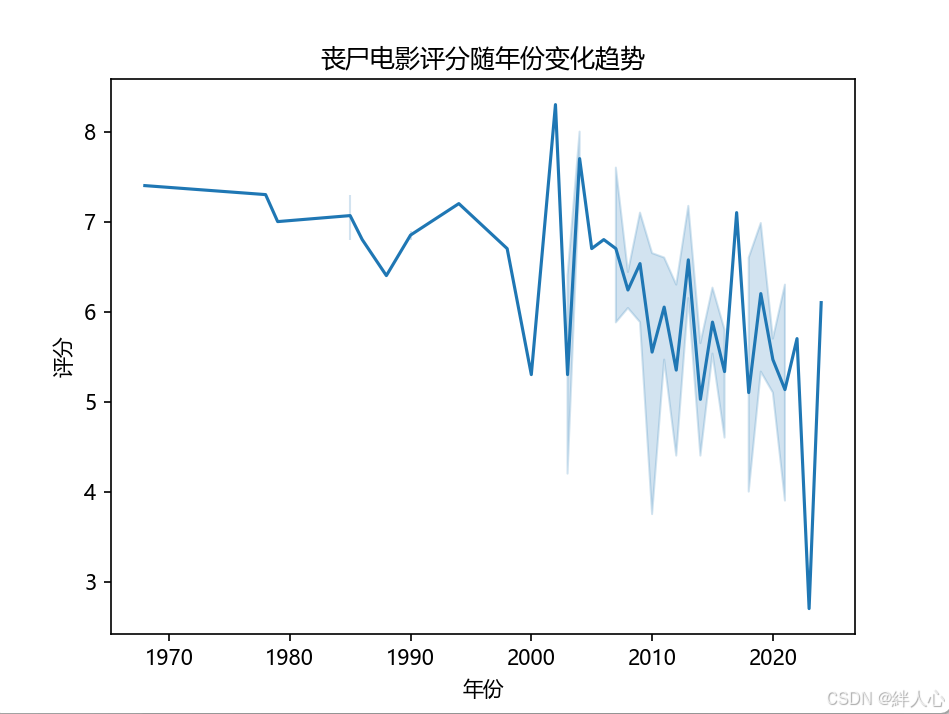
分析结果:从评分随年份变化的趋势图来看,丧尸电影在近几年内的评分有所波动,但整体呈现出逐渐下降的趋势。这表明随着丧尸电影题材的调整和制作质量的变化,观众对丧尸电影的评价逐步降低。
结论
通过对丧尸电影数据的分析,得出了一些有趣的结论:
- 评分分配:大部分丧片的评分集中在6-7分之间,少数电影的评分较低。
- 评价数与评分关系:评价数分区的电影通常有不太准确的评分,但也不乏高评价数却评分较低的电影。
- 年份影响:近几年上映的丧尸电影评分有所下降,表明该类型电影的质量在不断下降。
未来的分析可以考虑更多的因素,例如电影的详细类型、导演、演员等,以进一步深入挖掘影响电影评分的各种因素。
附录:完整代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 数据加载与预处理
df = pd.read_excel('./丧尸电影.xlsx')
df = df.rename(columns={'rating_nums': '评分'})
df = df[['标题', '评价数', '评分']]
df['评分'] = df['评分'].fillna(df['评分'].mean())
df['评价数'] = df['评价数'].fillna(0)
df = df[~df['评价数'].isin(['(尚未上映)', '(暂无评分)'])]
df = df.dropna()
df['评价数'] = df['评价数'].str.split("(").str[1].str.split("人").str[0]
df['评价数'] = df['评价数'].astype('int')
df['年份'] = df['标题'].str.split("(").str[1].str.split(")").str[0]
df['年份'] = df['年份'].astype('int')
df = df.sort_values(by=['年份', '评分'], ascending=[False, False])
# 评分分布分析
sns.histplot(df['评分'], kde=True)
plt.title('丧尸电影评分分布')
plt.xlabel('评分')
plt.ylabel('频数')
plt.show()
# 评价数与评分关系
sns.scatterplot(x='评价数', y='评分', data=df)
plt.title('评价数与评分关系')
plt.xlabel('评价数')
plt.ylabel('评分')
plt.show()
# 评分随年份变化的趋势
sns.lineplot(x='年份', y='评分', data=df, markers=True)
plt.title('丧尸电影评分随年份变化趋势')
plt.xlabel('年份')
plt.ylabel('评分')
plt.show()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









