




5 语法分析Syntax Analysis——自底向上
⭐⭐⭐⭐⭐⭐
Github主页👉https://github.com/A-BigTree
项目链接👉https://github.com/A-BigTree/college_assignment
⭐⭐⭐⭐⭐⭐
文章目录
5.1 概述
一个自底向上的语法分析过程对应于为一个输入串构造语法树的过程,它从叶子节点(底部)开始逐渐向上到达根节点(顶点)。
对于文法:
E
→
E
+
T
∣
T
T
→
T
∗
F
∣
F
F
→
(
E
)
∣
i
d
E\rightarrow E+T|T\\ T\rightarrow T*F|F\\ F\rightarrow (E)|\mathbf{id}
E→E+T∣TT→T∗F∣FF→(E)∣id
当输入串为:
i
d
∗
i
d
\mathbf{id}*\mathbf{id}
id∗id时,构造语法树过程如下:

5.1.1 归约
我们可以将自底向上语法分析过程看成将串 ω \omega ω“归约”为文法开始符号的过程。在每个*归约(reduction)*步骤中,一个与某产生式体相匹配的特定子串被替换为该产生式头部的非终结符。
对于刚刚示例构造语法树过程,可以用如下符号串序列来讨论这个过程:
i
d
∗
i
d
,
F
∗
i
d
,
T
∗
i
d
,
T
∗
F
,
T
,
E
\mathbf{id}*\mathbf{id},F*\mathbf{id},T*\mathbf{id},T*F,T,E
id∗id,F∗id,T∗id,T∗F,T,E
根据定义,一次归约是一个推导步骤的反向操作。因此,自顶向上语法分析的目标是一个反向构造一个推导过程。下面推导对应示例构造语法树过程:
E
⇒
T
⇒
T
∗
F
⇒
T
∗
i
d
⇒
F
∗
i
d
⇒
i
d
∗
i
d
E\Rightarrow T\Rightarrow T*F\Rightarrow T*\mathbf{id}\Rightarrow F*\mathbf{id}\Rightarrow \mathbf{id}*\mathbf{id}
E⇒T⇒T∗F⇒T∗id⇒F∗id⇒id∗id
5.1.2 移入—归约语法分析技术
主要的语法分析操作是移入和归约,但实际上一个移入—归约语法分析器可采取如下四种可能的动作:
- 移入(shift):将下一个输入符号移到栈的顶端;
- 归约(reduce):被归约的符号串的右端必然是栈顶。语法分析器在栈中确定这个串的左端,并决定用哪个非终结符来替代这个串;
- 接受(accept):宣布语法分析过程成功完成:
- 报错(error):发现一个语法错误,并调用一个错误恢复子进程;
下表表示了上面示例的移入—归约语法分析过程:
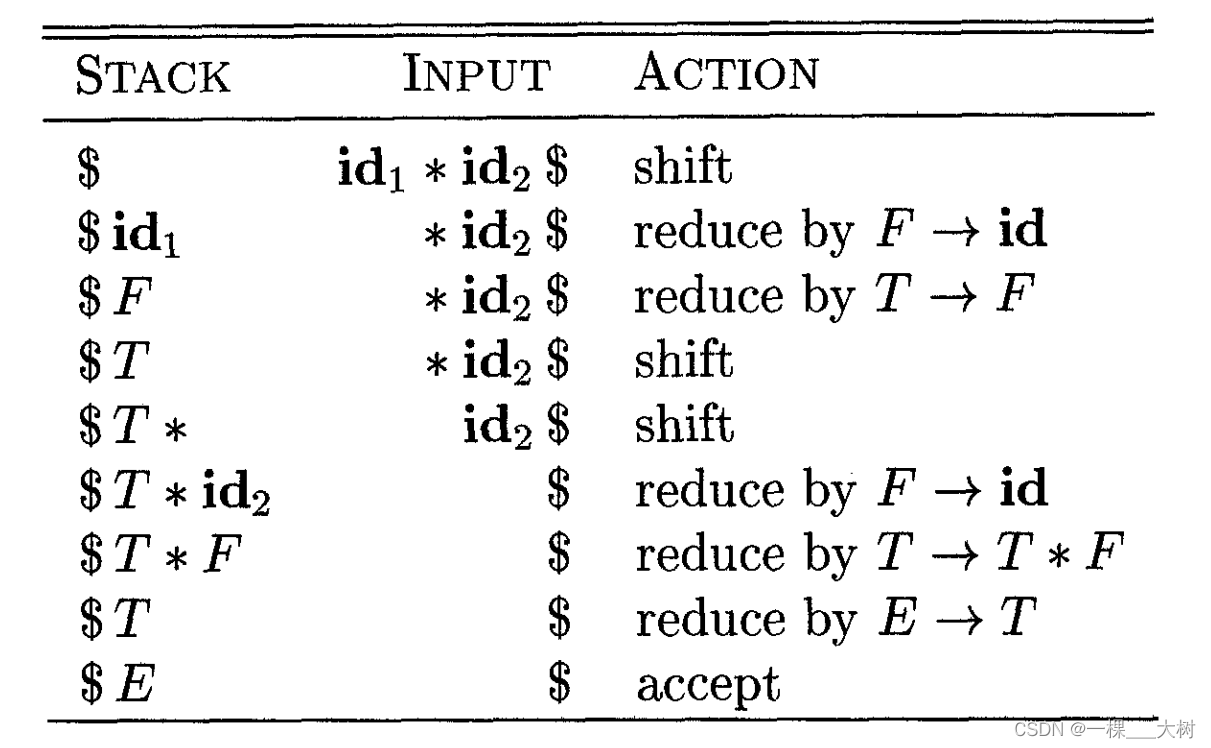
5.1.3 移入—归约语法分析中的冲突
即使知道了栈中的所有内容以及接下来的k个输入符号,我们仍然无法判断应该进行移入还是归约操作(移入/归约冲突),或者无法在多个可能的归约方法中选择正确的归约动作(归约/归约冲突)。
冲突发生在归约时
5.1.4 LR语法分析技术简介
自底向上语法分析器都是基于所谓的LR(k)语法分析的概念。其中,“L”表示对输入进行从左到右的扫描;“R”表示反向构造出一个最右推导序列,而k表示在做出语法分析决定时向前看k个输入符号。
常用的LR(k)文法包括:
- SLR:简单LR技术;
- LR(1):规范LR;
- LALR:向前看LR(Look ahead);
5.2 SLR:简单LR技术⭐
5.2.1 LR(0)项
一个LR语法分析器通过维护一些状态,用这些状态来表明我们在语法分析过程中所处的位置,从而做出移入—归约决定。这些状态代表了“项”(item)的集合。一个文法G的一个LR(0)项(简称为项)是G的一个产生式再加上一个位于它的体中某处的点。因此,产生式
A
→
X
Y
Z
A\rightarrow XYZ
A→XYZ产生了四个项:
A
→
⋅
X
Y
Z
A
→
X
⋅
Y
Z
A
→
X
Y
⋅
Z
A
→
X
Y
Z
⋅
A\rightarrow \cdot XYZ\\ A\rightarrow X\cdot YZ\\ A\rightarrow XY\cdot Z\\ A\rightarrow XYZ\cdot\\
A→⋅XYZA→X⋅YZA→XY⋅ZA→XYZ⋅
产生式
A
→
ε
A\rightarrow \varepsilon
A→ε只生成一个项
A
→
⋅
A\rightarrow \cdot
A→⋅。
5.2.2 增广文法
如果G是一个以S为开始符号的文法,那么G的增广文法G’就是在G中加上新开始符号S’和产生式 S ′ → S S'\rightarrow S S′→S而得到的文法 。
引入这个新的开始产生式的目的是告诉语法分析器何时应该停止语法分析并宣称接受输入符号串。也就是说,当且仅当语法分析器要使用规则 S ′ → S S'\rightarrow S S′→S进行归约时,输入符号串被接受。
5.2.3 项集的闭包 C L O S U R E CLOSURE CLOSURE函数
如果I是文法G的一个项集,那么CLOSURE(I)就是根据下面的两个规则从I构造得到的项集:
- 一开始,将I中的各项加入到CLOSURE(I)中;
- 如果 A → α ⋅ B β A\rightarrow \alpha\cdot B\beta A→α⋅Bβ在CLOSURE(I)中, B → γ B\rightarrow \gamma B→γ是一个产生式,并且项 B → ⋅ γ B\rightarrow \cdot\gamma B→⋅γ不在CLOSURE(I)中,就在这个项加入其中。不断应用这个规则,直到没有新项可以加入到CLOSURE(I)中;
下图为上例文法的增广文法的LR(0)项集组的LR(0)自动机:

像状态 I 0 , I 4 , I 6 , I 7 I_0,I_4,I_6,I_7 I0,I4,I6,I7的阴影部分都是白色部分产生式通过规则2拓展得到的,因此项集的闭包计算过程也称作 状态内部扩展 过程。
5.2.4 移点 G O T O GOTO GOTO函数
移点是 状态之间扩展 过程,即GOTO函数。
G O T O ( I , X ) GOTO(I,X) GOTO(I,X)定义为I中所有形如 [ A → α ⋅ X β ] [A\rightarrow \alpha\cdot X\beta] [A→α⋅Xβ]的项所对应的项 [ A → α X ⋅ β ] [A\rightarrow \alpha X\cdot\beta] [A→αX⋅β]的集合的闭包。直观的讲,GOTO函数用于定义一个文法的LR(0)自动机中状态的转换。
以上图为例,状态 I 0 ⇒ I 1 I_0\Rightarrow I_1 I0⇒I1过程即为 G O T O ( I 0 , E ) GOTO(I_0,E) GOTO(I0,E)转换过程。
5.2.5 语法分析动作 A C T I O N ACTION ACTION函数
ACTION函数有两个状态:一个是状态i,另一个是终结符a(或者是输入结束标记$)。
A C T I O N [ i , a ] ACTION[i,a] ACTION[i,a]的取值可以有下列四种形式:
- 移入状态j;
- 归约 A → β A\rightarrow \beta A→β;
- 接受;
- 报错;
5.2.6 构造SLR语法分析表⭐⭐
语法分析表由两个部分组成:一个语法分析动作函数ACTION和一个人转换函数GOTO。
对于一个增广文法G’,构建G’的SLR语法分析表函数ACTION和GOTO:
-
构建G’的规范LR(0)项集族 C = { I 0 , I 1 , … , I n } C=\{I_0,I_1,\dots,I_n\} C={I0,I1,…,In};
-
根据 I i I_i Ii得到i。状态i的语法分析动作有下面方法决定:
- 如果 [ A → α ⋅ a β ] 在 I i 中 并 且 G O T O [ I i , a ] = I j [A\rightarrow \alpha\cdot a\beta]在I_i中并且GOTO[I_i,a]=I_j [A→α⋅aβ]在Ii中并且GOTO[Ii,a]=Ij,那么将ACTION[i,a]设置为“移入j”,表中标记为== s j s_j sj==。这里的a必须为一个终结符;
- 如果 [ A → α ⋅ ] 在 I i [A\rightarrow \alpha\cdot]在I_i [A→α⋅]在Ii中,那么 FOLLOW(A) 中的所有a,将ACTION[i, a]设置为“归约 A → α A\rightarrow\alpha A→α”,表中标记为== r k r_k rk==,k为产生式 A → α A\rightarrow \alpha A→α的编号。这里A不等于S’;
- 如果 S ′ → S ⋅ 在 I i S'\rightarrow S\cdot在I_i S′→S⋅在Ii中,那么ACTION[i, $]设置为“接受”;
如果根据上面的规则生成任何冲突动作,我们就说这个文法不是SLR(1)的。
-
状态i对于各个非终结符号A的GOTO转换使用下面的规则构造得到:如果 G O T O [ I i , A ] = I j GOTO[I_i,A]=I_j GOTO[Ii,A]=Ij,那么GOTO[i, A] = j;
-
规则2,3没有定义的条目都设置为“报错”;
-
语法分析器的初始状态就是根据 [ S ′ → ⋅ S ] [S'\rightarrow\cdot S] [S′→⋅S]所在项集构造得到的状态;
5.2.7 SLR(1)示例
对于文法G构建SLR语法分析表:
E
→
E
+
T
∣
T
T
→
T
∗
F
∣
F
F
→
(
E
)
∣
i
d
E\rightarrow E+T|T\\ T\rightarrow T*F|F\\ F\rightarrow (E)|\mathbf{id}
E→E+T∣TT→T∗F∣FF→(E)∣id
- 构建增广文法G’并编号
( 0 ) E ′ → E ( 1 ) E → E + T ( 2 ) E → T ( 3 ) T → T ∗ F ( 4 ) T → F ( 5 ) F → ( E ) ( 6 ) F → i d \begin{aligned} &(0)E'\rightarrow E\\ &(1)E\rightarrow E+T\\ &(2)E\rightarrow T\\ &(3)T\rightarrow T*F\\ &(4)T\rightarrow F\\ &(5)F\rightarrow (E)\\ &(6)F\rightarrow\mathbf{id} \end{aligned} (0)E′→E(1)E→E+T(2)E→T(3)T→T∗F(4)T→F(5)F→(E)(6)F→id
- 构建G’的规范LR(0)项集族

- 构建语法分析表

- ✨根据语法分析表在处理输入 i d ∗ i d + i d \mathbf{id}*\mathbf{id}+\mathbf{id} id∗id+id时,栈和输入内容的序列如下图所需所示:

5.3 LR(1):规范LR⭐
规范LR,它充分地利用了向前看符号。这个方法使用了一个很大的项集,称为LR(1)项集。
5.3.1 规范LR(1)项
在SLR方法中,如果项集 I i I_i Ii包含项 [ A → α ⋅ ] [A\rightarrow \alpha\cdot] [A→α⋅],且当前输入符号a在FOLLOW(A)中,那么状态i就要按照 A → α A\rightarrow \alpha A→α进行归约。然而在某些状态下,当状态i出现在栈顶时,栈中的 可行前缀 是 β α \beta\alpha βα且在任何最右句型中a都不可能跟在 β A \beta A βA之后,那么当输入为a时不应该按照 A → α A\rightarrow \alpha A→α进行归约。
可行前缀:可以出现在一个移入—归约语法分析器的栈中的最右句型前缀被称为可行前缀(viable prefix)。定义如下:一个可行前缀是一个最右句型的前缀,并且它没有越过该最右句型的最右句柄的右端。
如果在状态中包含更多的信息,我们就可以排除掉一些这样的不正确的 A → α A\rightarrow \alpha A→α归约。在必要时,我们可以通过分裂某些状态,设法让LR语法分析器的每个状态精确地指向那些输入符号可以跟在句柄 α \alpha α的后面,从而使 α \alpha α可能被归约成为A。
将额外信息加入状态中的方法是对项进行精化。项的一般形式变成了 [ A → α ⋅ β , a ] [A\rightarrow \alpha\cdot\beta,a] [A→α⋅β,a],其中 A → α β A\rightarrow \alpha\beta A→αβ使一个产生式,而a使一个终结符号或右端标记$,我们称这样的对象为 LR(1)项。只有栈顶状态中包含一个LR(1)项 [ A → α ⋅ , a ] [A\rightarrow \alpha\cdot,a] [A→α⋅,a],我们才会输入输入为a时进行归约。这样的a的集合 总是FOLLOW(A)的子集。
5.3.2 构造LR(1)项集
构造有效LR(1)项集族的方法实质上和构造规范LR(0)项集族的方法相同。我们只需要修改两个过程:CLOSURE和GOTO。
CLOSURE(I)按如下方法构造:
- I的任何项都属于CLOSURE(I);
- 若有项 [ A → α ⋅ B β , a ] ∈ C L O S U R E ( I ) [A\rightarrow \alpha\cdot B\beta,a]\in CLOSURE(I) [A→α⋅Bβ,a]∈CLOSURE(I), B → γ B\rightarrow \gamma B→γ是文法中的产生式, β ∈ V ∗ , b ∈ F I R S T ( β a ) \beta\in V^*,b\in FIRST(\beta a) β∈V∗,b∈FIRST(βa),则 [ B → ⋅ γ , b ] ∈ C L O S U R E ( I ) [B\rightarrow \cdot\gamma,b]\in CLOSURE(I) [B→⋅γ,b]∈CLOSURE(I);
- 重复2直到CLOSURE(I)不再增大为止;
例子:
(
0
)
S
′
→
S
(
1
)
S
→
C
C
(
2
)
C
→
c
C
(
3
)
C
→
d
\begin{aligned} &(0)S'\rightarrow S\\ &(1)S\rightarrow CC\\ &(2)C\rightarrow cC\\ &(3)C\rightarrow d \end{aligned}
(0)S′→S(1)S→CC(2)C→cC(3)C→d
以初始状态为例,计算
{
[
S
′
→
⋅
S
,
结
束
符
]
}
\{[S'\rightarrow \cdot S,结束符]\}
{[S′→⋅S,结束符]} 的闭包。在求闭包时,将项
[
S
′
→
⋅
S
,
结
束
符
]
[S'\rightarrow \cdot S,结束符]
[S′→⋅S,结束符]和过程CLOSURE中的项
[
A
→
α
⋅
B
β
,
a
]
[A\rightarrow \alpha\cdot B\beta,a]
[A→α⋅Bβ,a]相匹配,
A
=
S
′
,
α
=
ε
,
B
=
S
,
β
=
ε
和
a
=
结
束
符
A=S',\alpha=\varepsilon,B=S,\beta=\varepsilon和a=结束符
A=S′,α=ε,B=S,β=ε和a=结束符。
B
→
γ
B\rightarrow \gamma
B→γ就是
S
→
C
C
S\rightarrow CC
S→CC,所以
b
=
F
I
R
S
T
(
β
a
)
=
F
I
R
S
T
(
ε
结
束
符
)
⇒
结
束
符
b=FIRST(\beta a)=FIRST(\varepsilon\ 结束符)\Rightarrow 结束符
b=FIRST(βa)=FIRST(ε 结束符)⇒结束符,所以加入
[
S
→
⋅
C
C
,
结
束
符
]
[S\rightarrow \cdot CC,结束符]
[S→⋅CC,结束符]。
后面过程同理,我们可以得到如下LR(1)项集:

5.3.3 构造规范LR(1)语法分析表⭐⭐
对于一个增广文法G’,构建G’的LR(1)语法分析表函数ACTION和GOTO:
-
构建G’的规范LR(1)项集族 C ′ = { I 0 , I 1 , … , I n } C'=\{I_0,I_1,\dots,I_n\} C′={I0,I1,…,In};
-
根据 I i I_i Ii得到i。状态i的语法分析动作有下面方法决定:
- 如果 [ A → α ⋅ a β , b ] 在 I i 中 并 且 G O T O [ I i , a ] = I j [A\rightarrow \alpha\cdot a\beta,b]在I_i中并且GOTO[I_i,a]=I_j [A→α⋅aβ,b]在Ii中并且GOTO[Ii,a]=Ij,那么将ACTION[i,a]设置为“移入j”,表中标记为 s j s_j sj。这里的a必须为一个终结符;
- 如果 [ A → α ⋅ , a ] 在 I i [A\rightarrow \alpha\cdot,a]在I_i [A→α⋅,a]在Ii中,将ACTION[i, a]设置为“归约 A → α A\rightarrow\alpha A→α”,表中标记为 r k r_k rk,k为产生式 A → α A\rightarrow \alpha A→α的编号。这里A不等于S’;
- 如果$[S’\rightarrow S\cdot,$]在I_i$中,那么ACTION[i, $]设置为“接受”;
如果根据上面的规则生成任何冲突动作,我们就说这个文法不是LR(1)的。
-
状态i对于各个非终结符号A的GOTO转换使用下面的规则构造得到:如果 G O T O [ I i , A ] = I j GOTO[I_i,A]=I_j GOTO[Ii,A]=Ij,那么GOTO[i, A] = j;
-
规则2,3没有定义的条目都设置为“报错”;
-
语法分析器的初始状态就是根据$[S’\rightarrow\cdot S,$]$所在项集构造得到的状态;
5.3.4 LR(1)示例
对于下面文法G是否为LR(1)文法:
S
→
C
C
C
→
c
C
∣
d
S\rightarrow CC\\ C\rightarrow cC|d
S→CCC→cC∣d
- 构建增广文法G’并编号
( 0 ) S ′ → S ( 1 ) S → C C ( 2 ) C → c C ( 3 ) C → d \begin{aligned} &(0)S'\rightarrow S\\ &(1)S\rightarrow CC\\ &(2)C\rightarrow cC\\ &(3)C\rightarrow d \end{aligned} (0)S′→S(1)S→CC(2)C→cC(3)C→d
- 构建G’的规范LR(1)项集族

- 构建语法分析表

表中不存在二义性操作,G’为LR(1)文法。
5.4 LALR:向前看LR⭐
向前看LR,它基于LR(0)项集族。和基于 LR(1)项的典型语法分析器相比,它的状态要少很多。通过向LR(0)项中小心地引入向前看符号,我们使用LALR方法处理的文法比使用SLR方法时处理的文法更多,同时构造得到的语法分析表却不比SLR表大。
5.4.1 构造LALR语法分析表⭐⭐
LALR(1)文法是在将LR(1)项集**相同核心的项项集合并,所谓和核心就是项集第一个分量的集合**。比如上例中的 I 4 和 I 7 , I 3 和 I 6 , I 8 和 I 9 I_4和I_7,I_3和I_6,I_8和I_9 I4和I7,I3和I6,I8和I9,一般而言,一个核心就是当前正处理文法的LR(0)项集,一个LR(1)文法可能产生多个具有相同核心的项集。
一个简单,但空间需求大的LALR分析表构造方法
对于一个增广文法G’,构建G’的LR(1)语法分析表函数ACTION和GOTO:
- 构建G’的规范LR(1)项集族 C ′ = { I 0 , I 1 , … , I n } C'=\{I_0,I_1,\dots,I_n\} C′={I0,I1,…,In};
- 对于LR(1)项集中的每个核心,将具有相同核心的项集进行合并,并将这些项集替换为它们的并集;
- 令 C ′ = { J 0 , J 1 , … , J m } C'=\{J_0,J_1,\dots,J_m\} C′={J0,J1,…,Jm}是合并项集后的LR(1)项集族。状态i的语法动作按照构建LR(1)语法分析表的算法进行构建,如果根据上面的规则生成任何冲突动作,我们就说这个文法不是LALR(1)的;
- GOTO表的构造方法如下。如果J是一个或多个LR(1)项集的并集,也是说 J = I 1 ∪ I 2 ∪ ⋯ ∪ I k J=I_1\cup I_2\cup\dots\cup I_k J=I1∪I2∪⋯∪Ik,令K是所有和 G O T O ( I 1 , X ) GOTO(I_1,X) GOTO(I1,X)具有相同核心的项集的并集,那么GOTO(J,X)=K;
5.4.2 LALR示例
与LA(1)示例前两步相同,在构建完LA(1)项集族后,将相同核心的I进行合并在构建语法分析表。
对于下面文法G是否为LALR(1)文法:
S
→
C
C
C
→
c
C
∣
d
S\rightarrow CC\\ C\rightarrow cC|d
S→CCC→cC∣d
- 构建增广文法G’并编号
( 0 ) S ′ → S ( 1 ) S → C C ( 2 ) C → c C ( 3 ) C → d \begin{aligned} &(0)S'\rightarrow S\\ &(1)S\rightarrow CC\\ &(2)C\rightarrow cC\\ &(3)C\rightarrow d \end{aligned} (0)S′→S(1)S→CC(2)C→cC(3)C→d
- 构建G’的规范LR(1)项集族
- 构建语法分析表
I 4 和 I 7 合 并 为 I 47 , I 3 和 I 6 合 并 为 I 36 , I 8 和 I 9 合 并 为 I 89 I_4和I_7合并为I_{47},I_3和I_6合并为I_{36},I_8和I_9合并为I_{89} I4和I7合并为I47,I3和I6合并为I36,I8和I9合并为I89,语法分析表如下:

5.5 使用二义性文法
每个二义性文法(Ambiguous grammar)都不是LR的,二义性就是构造文法分析表中出现的移入/归约冲突或归约/归约冲突。
5.5.1 用优先级和结合性解决冲突
比如以下文法:
E
→
E
+
E
∣
E
∗
E
∣
(
E
)
∣
i
d
E\rightarrow E+E|E*E|(E)|\mathbf{id}
E→E+E∣E∗E∣(E)∣id
其增广表达式的LR(0)项集族如下:

构建文法分析表如下:
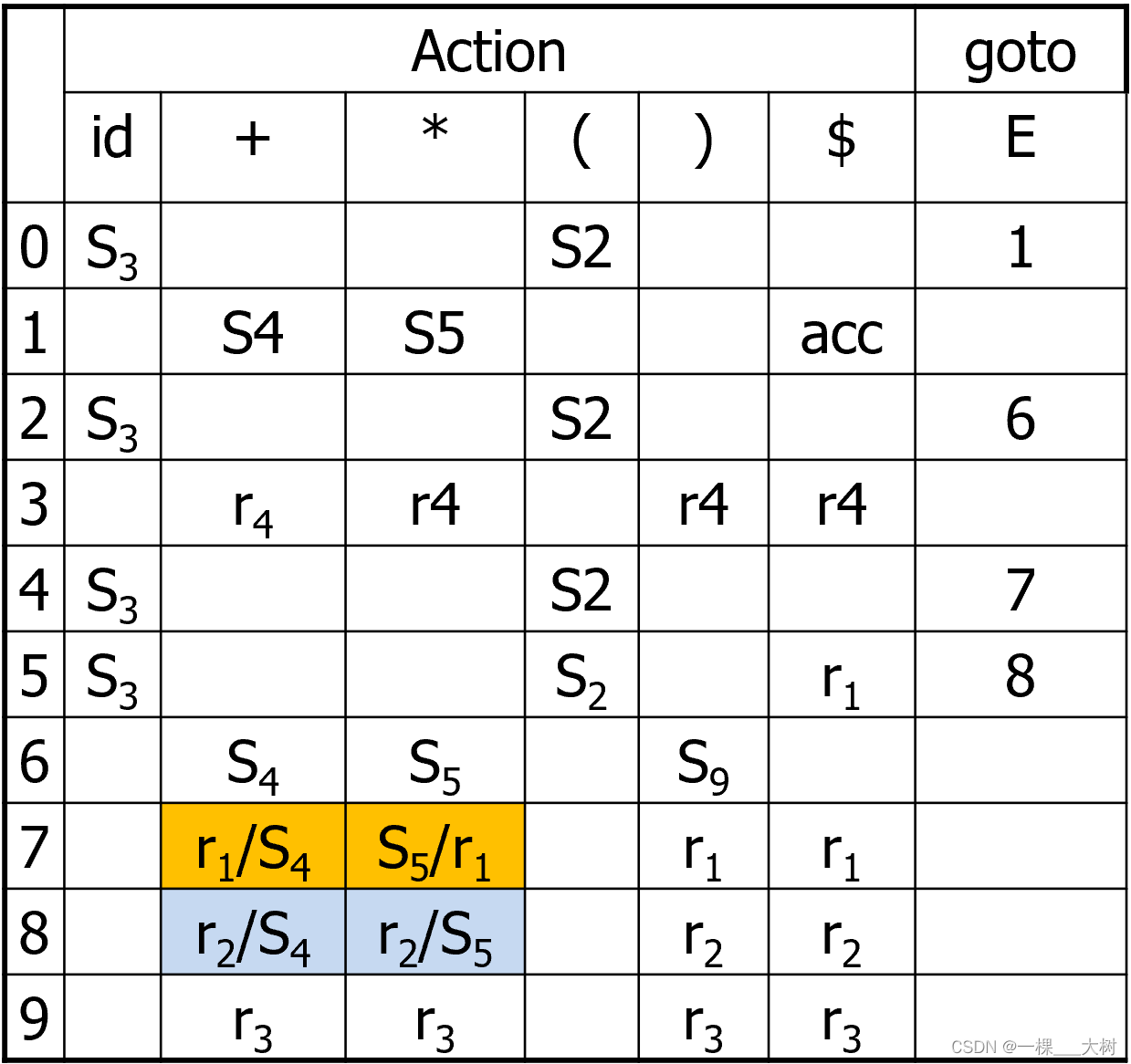
我们发现在状态7和状态8的符号+和*上都出现移入/归约冲突。
- 考虑输入 i d + i d ∗ i d \mathbf{id}+\mathbf{id}*\mathbf{id} id+id∗id:
当输入乘号*时,解析器不知道应该先将栈里的E+E归约,还是先将*移入栈中,并准备将这个*和其左右的id归约;
- 考虑输入 i d + i d + i d \mathbf{id}+\mathbf{id}+\mathbf{id} id+id+id:
同理我们不知道+是左结合还是右结合,哪一个先进行归约;
假设+是左结合,状态7输入+时应该进行归约;*的优先级高,那么状态7在输入*时应该移入,当栈顶为E*E时,状态8进行归约;考虑到*也是左结合,同理得到解决冲突的语法分析表如下:

5.5.2 悬空else的二义性
考虑文法:
S
′
→
S
S
→
i
S
e
S
∣
i
S
∣
a
S'\rightarrow S\\ S\rightarrow iSeS|iS|a
S′→SS→iSeS∣iS∣a
其中i代表if exper then,e表示eles,a表示“所有其他产生式”;
其构建的LR状态集如下:

状态4中我们不知道是将iS进行归约,还是输入else,所以我们规定优先移入else,规定后语法分析表如下:

5.6 语法分析总结

⭐⭐⭐⭐⭐⭐
Github主页👉https://github.com/A-BigTree
项目链接👉https://github.com/A-BigTree/college_assignment
⭐⭐⭐⭐⭐⭐


















 9365
9365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











