






Apriori算法代码:
def load_data_set():
"""
加载样本数据集
返回:
数据集:交易列表。 每个事务包含几个项目。
"""
data_set = [['A', 'C', 'S','l'], ['D', 'A','C','E','B'], ['A', 'B','C'],
['C', 'A', 'B','E']]
return data_set
def create_C1(data_set):
"""
通过扫描数据集创建频繁候选 1-itemset C1。
参数:
data_set:交易列表。 每个事务包含几个项目。
返回:
C1:包含所有频繁候选 1 项集的集合
"""
C1 = set()
for t in data_set:
for item in t:
item_set = frozenset([item])
C1.add(item_set)
return C1
def is_apriori(Ck_item, Lksub1):
"""
判断一个频繁候选k-itemset是否满足Apriori性质。
参数:
Ck_item:Ck中的一个频繁候选k-itemset,包含所有频繁
候选 k 项集。
Lksub1:Lk-1,一个包含所有频繁候选(k-1)项集的集合。
返回:
真:满足 Apriori 属性。
False:不满足 Apriori 属性。
"""
for item in Ck_item:
sub_Ck = Ck_item - frozenset([item])
if sub_Ck not in Lksub1:
return False
return True
def create_Ck(Lksub1, k):
"""
创建 Ck,一个包含所有频繁候选 k 项集的集合
通过Lk-1自己的连接操作。
参数:
Lksub1:Lk-1,一个包含所有频繁候选(k-1)项集的集合。
k:频繁项集的项号。
返回:
Ck:包含所有频繁候选 k 项集的集合。
"""
Ck = set()
len_Lksub1 = len(Lksub1)
list_Lksub1 = list(Lksub1)
for i in range(len_Lksub1):
for j in range(1, len_Lksub1):
l1 = list(list_Lksub1[i])
l2 = list(list_Lksub1[j])
l1.sort()
l2.sort()
if l1[0:k-2] == l2[0:k-2]:
Ck_item = list_Lksub1[i] | list_Lksub1[j]
# pruning
if is_apriori(Ck_item, Lksub1):
Ck.add(Ck_item)
return Ck
def generate_Lk_by_Ck(data_set, Ck, min_support, support_data):
"""
通过从 Ck 执行删除策略来生成 Lk。
参数:
data_set:交易列表。 每个事务包含几个项目。
Ck:包含所有频繁候选 k 项集的集合。
min_support:最小支持。
support_data:字典。 关键是频繁项集,值是支持度。
返回:
Lk:包含所有频繁 k 项集的集合。
"""
Lk = set()
item_count = {}
for t in data_set:
for item in Ck:
if item.issubset(t):
if item not in item_count:
item_count[item] = 1
else:
item_count[item] += 1
t_num = float(len(data_set))
for item in item_count:
if (item_count[item] / t_num) >= min_support:
Lk.add(item)
support_data[item] = item_count[item] / t_num
return Lk
def generate_L(data_set, k, min_support):
"""
生成所有频繁项集。
参数:
data_set:交易列表。 每个事务包含几个项目。
k:所有频繁项集的最大项数。
min_support:最小支持。
返回:
L:Lk的名单。
support_data:字典。 关键是频繁项集,值是支持度。
"""
support_data = {}
C1 = create_C1(data_set)
L1 = generate_Lk_by_Ck(data_set, C1, min_support, support_data)
Lksub1 = L1.copy()
L = []
L.append(Lksub1)
for i in range(2, k+1):
Ci = create_Ck(Lksub1, i)
Li = generate_Lk_by_Ck(data_set, Ci, min_support, support_data)
Lksub1 = Li.copy()
L.append(Lksub1)
return L, support_data
def generate_big_rules(L, support_data, min_conf):
"""
从频繁项集中生成大规则。
参数:
L:Lk的名单。
support_data:字典。 关键是频繁项集,值是支持度。
min_conf:最小的信心。
回报:
big_rule_list:包含所有大规则的列表。 每个大规则都被表示
作为一个三元组。
"""
big_rule_list = []
sub_set_list = []
for i in range(0, len(L)):
for freq_set in L[i]:
for sub_set in sub_set_list:
if sub_set.issubset(freq_set):
conf = support_data[freq_set] / support_data[freq_set - sub_set]
big_rule = (freq_set - sub_set, sub_set, conf)
if conf >= min_conf and big_rule not in big_rule_list:
# print freq_set-sub_set, " => ", sub_set, "conf: ", conf
big_rule_list.append(big_rule)
sub_set_list.append(freq_set)
return big_rule_list
if __name__ == "__main__":
"""
Test
"""
data_set = load_data_set()
L, support_data = generate_L(data_set, k=3, min_support=0.6) #minsup=60%
big_rules_list = generate_big_rules(L, support_data, min_conf=0.8) #minconf=80%
for Lk in L:
print("="*50)
print("frequent " + str(len(list(Lk)[0])) + "-itemsetsttsupport")
print("="*50)
for freq_set in Lk:
print(freq_set, support_data[freq_set])
print
print("Big Rules")
for item in big_rules_list:
print(item[0], "=>", item[1], "conf: ", item[2])效果图:

FP-tree算法:
# !/usr/bin/python3.4
# -*- coding: utf-8 -*-
from collections import Counter
# 遍历数据,进行计数
def countitem(array):
temp = []
for item in array:
for value in item:
temp.append(value)
# 写入字典
dict = {}
for key in Counter(temp).keys():
dict[key] = Counter(temp)[key]
# {'G': 2, 'B': 7, 'D': 6, 'A': 3, 'E': 4, 'C': 8, 'F': 1}
return dict
# 删除支持度不够的key
def deletekey(dict, support):
temp = dict.copy()
detele = []
for key in dict.keys():
if dict[key] < support:
temp.pop(key)
detele.append(key)
# {'A': 3, 'B': 7, 'E': 4, 'D': 6, 'C': 8}
# ['F', 'G']
return temp, detele
# 得到从大到小排序的数组
def sorfarray(array, dict, delect):
newarray = []
# 删除支持度不够的元素
for item in array:
temp = {}
for value in item:
if value in delect:
pass
else:
# 排除被删除的元素
# [['E', 'B', 'C'], ['D', 'C'], ['B', 'A', 'C'], ['B', 'D'], ['D', 'C', 'B'], ['E', 'A', 'C'], ['D', 'C'], ['A', 'E', 'B'], ['B', 'C', 'D'], ['E', 'C', 'B', 'D']]
temp[value] = dict[value]
temp = sorted(temp.items(), key=lambda d: d[1], reverse=True)
# 排序后得到
# [('C', 8), ('B', 7), ('E', 4)]
# [('C', 8), ('D', 6)]
# [('C', 8), ('B', 7), ('A', 3)]
# [('B', 7), ('D', 6)]
# [('C', 8), ('B', 7), ('D', 6)]
# [('C', 8), ('E', 4), ('A', 3)]
# [('C', 8), ('D', 6)]
# [('B', 7), ('E', 4), ('A', 3)]
# [('C', 8), ('B', 7), ('D', 6)]
# [('C', 8), ('B', 7), ('D', 6), ('E', 4)]
# temp[0][0] = C
tem = []
for tuple in temp:
tem.append(tuple[0])
newarray.append(tem)
# 得到排序后的新数组
# [['C', 'B', 'E'], ['C', 'D'], ['C', 'B', 'A'], ['B', 'D'], ['C', 'B', 'D'], ['C', 'E', 'A'], ['C', 'D'], ['B', 'E', 'A'], ['C', 'B', 'D'], ['C', 'B', 'D', 'E']]
return newarray
# info里面元素的种类
def getkinds(array):
temp = []
for item in array:
for value in item:
if value in temp:
pass
else:
temp.append(value)
# ['C', 'B', 'E', 'D', 'A']
# ['A', 'B', 'C', 'D', 'E']
return sorted(temp)
# 得到每一个种类的所有路径
def getrootpath(kinds, newinfo, dict):
allinfo = {}
for kind in kinds:
kindarr = []
for item in newinfo:
# 如果这一条路径包含某个种类
itemarr = []
if kind in item:
for value in item:
if kind == value:
break
else:
itemarr.append(value)
if itemarr:
kindarr.append(itemarr)
# print(kind, kindarr)
# A [[('C', 8), ('B', 7)], [('C', 8), ('E', 4)], [('B', 7), ('E', 4)]]
# B [[('C', 8)], [('C', 8)], [('C', 8)], [('C', 8)], [('C', 8)]]
# C []
# D [[('C', 8)], [('B', 7)], [('C', 8), ('B', 7)], [('C', 8)], [('C', 8), ('B', 7)], [('C', 8), ('B', 7)]]
# E [[('C', 8), ('B', 7)], [('C', 8)], [('B', 7)], [('C', 8), ('B', 7), ('D', 6)]]
allinfo[kind] = kindarr
return allinfo
# 得到所有组合的字典
def getrange(rootpath):
alldict = {}
for key in rootpath.keys():
root = rootpath[key]
# 一个元素的路径
onearr = []
dict = {}
# 实现一个元素路径
for item in root:
for value in item:
onearr.append(value)
dict[value] = onearr.count(value)
alldict[key] = dict
# {'B': {'C': 5}, 'C': {}, 'E': {'C': 3, 'B': 3, 'D': 1}, 'A': {'E': 2, 'C': 2, 'B': 2}, 'D': {'C': 5, 'B': 4}}
# 实现两个元素路径
for item1 in root:
tempdict = {}
for item2 in root:
if item1 == item2:
if len(item1) > 1:
x = "".join(item1)
if x in tempdict.keys():
tempdict[x] += 1
else:
tempdict[x] = 1
# print(tempdict)
if tempdict:
for x in tempdict:
alldict[key][x] = tempdict[x]
# print(alldict)
# {'D': {'CB': 3, 'C': 5, 'B': 4}, 'A': {'E': 2, 'B': 2, 'CB': 1, 'C': 2, 'BE': 1, 'CE': 1}, 'E': {'D': 1, 'C': 3, 'CB': 1, 'B': 3, 'CBD': 1}, 'B': {'C': 5}, 'C': {}}
return alldict
# 得到每个种类的置信度
def confidence(alldict, support, newinfo):
newdict = {}
for kind in alldict:
copydict = alldict[kind].copy()
for key in alldict[kind]:
if alldict[kind][key] < support:
copydict.pop(key)
if copydict:
newdict[kind] = copydict
# print(newdict)
# {'E': {'C': 3, 'B': 3}, 'B': {'C': 5}, 'D': {'C': 5, 'CB': 3, 'B': 4}}
# 计算置信度
for kind in newdict:
for key in newdict[kind].keys():
tempnum = newdict[kind][key]
denominator = 0
for item in newinfo:
if len(key) == 1:
if key in item:
denominator += 1
elif len(key) == 2:
if key[0] in item and key[1] in item:
denominator += 1
elif len(key) == 3:
if key[0] in item and key[1] in item and key[2] in item:
denominator += 1
newdict[kind][key] = str(tempnum) + "/" + str(denominator)
# {'E': {'B': '3/7', 'C': '3/8'}, 'B': {'C': '5/8'}, 'D': {'B': '4/7', 'C': '5/8', 'CB': '3/5'}}
# 买了C人,有3/8概率买E,有5/8概率买B,有5/8概率买D,且买了C又买了B的人有3/5的概率买D
return newdict
if __name__ == '__main__':
support = 3
info = [["A", "C", "S","L"], ["D", "A","C","E","B"], ["A", "B", "C"], ["C", "A","B","E"]]
# 遍历数据,进行计数
dict = countitem(info)
# 删除支持度不够的key
dict, delete = deletekey(dict, support)
# 得到从大到小排序的数组
newinfo = sorfarray(info, dict, delete)
# info里面元素的种类
kinds = getkinds(newinfo)
# 得到每一个种类的所有路径
rootpath = getrootpath(kinds, newinfo, dict)
# 得到所有组合的字典
alldict = getrange(rootpath)
# 得到每个种类的置信度
confidence(alldict, support, newinfo)
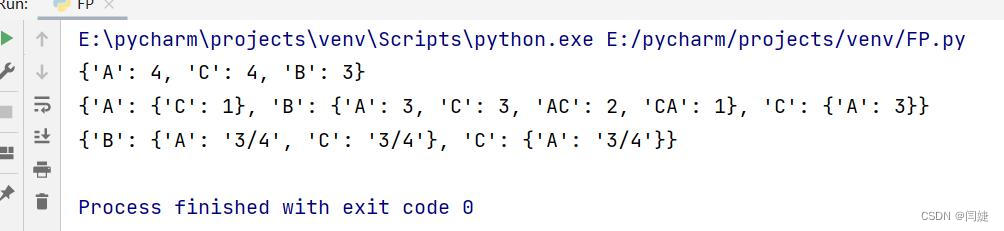
print(dict)
print("--------------------------------------------------------------------------------")
print(alldict)
print("--------------------------------------------------------------------------------")
print(confidence(alldict,support,newinfo))
print("--------------------------------------------------------------------------------")效果图:
《数据挖掘与知识发现》第二章第五题
内容来源于网络如有侵权请私信删除
FP-tree: 百哥么么哒|个人网站
Apriori: Apriori算法介绍(Python实现)















 2002
2002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









