






1.Redis基础
1.1Redis核心数据结构
1.1.1 string
set a a -> get a
mset a a b b -> mget a b
setnx c c -> (分布式锁,看是否插入成功)
incr article:1> get article:1(微信点赞、收藏与标签基于Redis实现)
incrby article:1 100 -> 100人点赞
1.1.2 hash
HSET key field value -> 存储一个hash类型,也可多个
HSETNX key field value -> 存储一个不存在的hash类型
HMSET key field value [field value … -> 设置该hash表多个key,val
HGET key field ->获取哈希表key对应的field的val
HMGET key field [field … ->批量获取哈希表key中多个field键值
HDEL key field [field … ->删除哈希表key中的field键值
HLEN key ->返回哈希表key中field的数量
HGETALL key -> 返回哈希表key中所有的key和val
HINCRBY hash表 key num -> 为某个key +num
- 购物车基于Redis实现

- 对比string
优点:
同类数据在一个hash表,便于管理
相比string存储更节省空间
缺点:
过期时间不能用在field上,只能用在hash表上
redis集群架构不合适大规模使用(通过key去路由打到哪台机器,可能某些机器存储数据量过大)
1.1.3 List
lpush key value [val…]
rpop key
lrange key start stop -> 不会去除list中的数据
BlPOP key timeout -> 阻塞获取
- 应用场景,朋友圈

1.1.3 Set

1.1.2 zset

1.1.3 Redis Pipeline(管道)
批量发送命令,节省了网络传输的开销
若10条命令,5条成功5条失败,会返回执行结果,管道不具备原子性
1.1.4 Redis Stream队列
1.1.5 HyperLogLog
用于统计uv、pv,非常节约内存
HyperLogLog 提供了 3 个命令: pfadd、pfcount、pfmerge
1.2 Redis高性能核心原理
1.2.1 Redis是单线程的吗?
Redis单线程主要是指Redis网络io和键值对的读写由一个线程来完成。
但是redis的其他功能,比如持久化,异步删除,集群数据同步等是由其他的线程执行。
1.2.2 Redis 单线程为什么还能这么快?
因为它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性 能损耗问题。正因为 Redis 是单线程,所以要小心使用 Redis 指令,对于那些耗时的指令(比如 keys),一定要谨慎使用,一不小心就可能会导致 Redis 卡顿。
1.2.3 Redis 单线程如何处理那么多的并发客户端连接?
Redis的IO多路复用:redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器

2.持久化、主从、哨兵
2.1持久化
2.1.1 RDB(快照)

可以手动执行save, bgsave可以手动生成dump.rdb文件
bgsave写时复制机制:
bgsave 子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。 bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。此时,如果主线程对这些 数据也都是读操作,那么,主线程和 bgsave 子进程相互不影响。但是,如果主线程要修改一块数据,那 么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文 件,而在这个过程中,主线程仍然可以直接修改原来的数据。

rdb缺点,redis宕机可能丢失的数据,因为部分数据可能没有触发生成快照
2.1.2 AOP(append-only file)

- 何时aof?
appendfsync always:每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全。
appendfsync everysec:每秒 fsync 一次,足够快,并且在故障时只会丢失 1 秒钟的数据。
appendfsync no:从不 fsync ,将数据交给操作系统来处理。更快,也更不安全的选择。
- AOF重写
简化redis命令,例如多次+1,只需要存一个命令
#auto‐aof‐rewrite‐min‐size64mb//aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就很快,重写的意义不大
#auto‐aof‐rewrite‐percentage100//aof文件自上一次重写后文件大小增长了100%则再次触发重写
- RDB和AOF如何选择
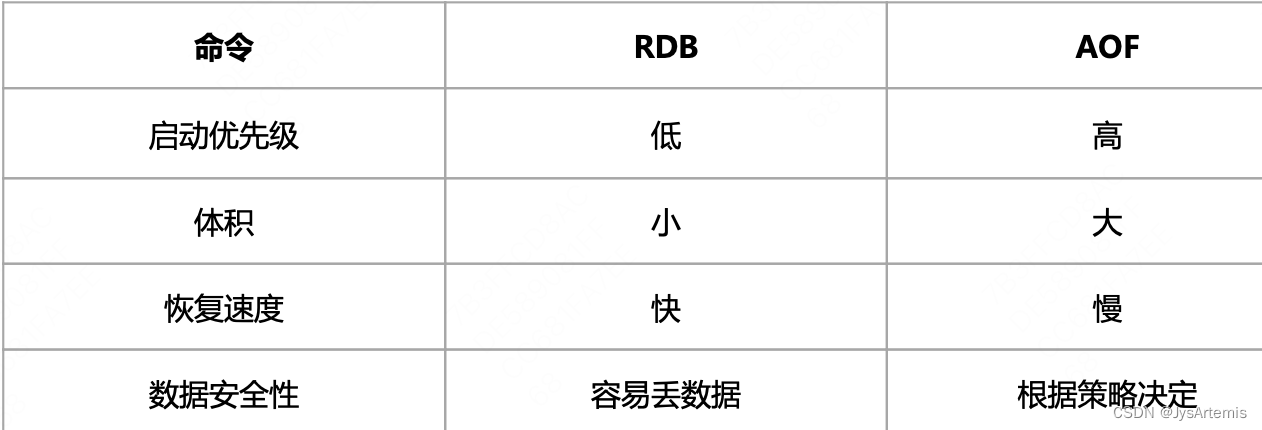
2.1.3 Redis4.0 混合持久化

开启了混合持久化,
AOF在重写时,不再是单纯将内存数据写入AOF文件,而是将重写这一刻之前的内存做RDB快照处理,并且将RDB快照内容和增量的AOF修改内存数据的命令存在一起,都写入新的AOF文件,新的文件一开始不叫appendonly.aof,等到重写完新的AOF文件才会进行改名,覆盖原有的AOF文件,完成新旧两个AOF文件的替换。

- 数据备份策略:
根据自己的策略定时备份aof,redis在重启时会取这个文件的数据。
2.2 Redis主从架构
主负责写,从负责读,需要自己去写逻辑完成
2.2.1 从节点全量复制原理:

2.2.2 数据部分复制复制原理:

2.2.3 主从复制风暴
多个从节点从主节点复制数据,导致主节点压力过大
这种情况可以让部分从节点与从节点同步数据
主从模式下,需要手动将从节点晋升为主节点,后面的哨兵可以完成自动故障迁移

2.3 Redis哨兵高可用架构

sentinel哨兵是特殊的redis服务,不提供读写服务,主要用来监控redis实例节点。 哨兵架构下client端第一次从哨兵找出redis的主节点,后续就直接访问redis的主节点,不会每次都通过 sentinel代理访问redis的主节点,当redis的主节点发生变化,哨兵会第一时间感知到,并且将新的redis 主节点通知给client端(这里面redis的client端一般都实现了订阅功能,订阅sentinel发布的节点变动消息)
2.4 Redis Cluster集群
2.4.1 哨兵集群和cluster架构的区别
1.sentinel主从切换段时候用不了
2.sentinel只有一个主节点对外提供服务,没法支持很高的并发
3.单个主节点内存也不宜设置得过大,否则会导致持久化文件过大,影响数据恢复或主从同步的效率
2.4.2 redis高可用集群
cluster集群读写都走master节点,slave主要用于容灾后主从切换

- 槽位定位算法
Cluster 默认会对 key 值使用 crc16 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模 来得到具体槽位。
- 跳转重定位

- Redis集群选举原理分析
1.slave发现master挂了
2.发送广播消息(主观下线),若超过一半的节点认为它的master挂了,就客观下线了,slave会等待一个随机的延迟向集群中其他的master发起投票选举
3.其他节点master只会给第一次发消息的slave发送ack
4.收到半数以上的投票,选举成功
5.slave通知其他集群节点
从节点并不是在主节点一进入 FAIL 状态就马上尝试发起选举,而是有一定延迟,一定的延迟确保我们等待 FAIL状态在集群中传播,slave如果立即尝试选举,其它masters或许尚未意识到FAIL状态,可能会拒绝投票 •延迟计算公式:
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
•SLAVE_RANK表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。这种方式下,持有最新数据的slave将会首先发起选举(理论上)。
- 集群脑裂数据丢失问题
redis集群没有过半机制会有脑裂问题,网络分区导致脑裂后多个主节点对外提供写服务,一旦网络分区恢复, 会将其中一个主节点变为从节点,这时会有大量数据丢失。
如何解决:
min‐replicas‐to‐write 1 //写数据成功最少同步的slave数量
- Redis集群对批量操作命令的支持
mset {user1}:1:name zhuge {user1}:1:age 18
对于类似mset,mget这样的多个key的原生批量操作命令,redis集群只支持所有key落在同一slot的情况,如 果有多个key一定要用mset命令在redis集群上操作,则可以在key的前面加上{XX},这样参数数据分片hash计 算的只会是大括号里的值,这样能确保不同的key能落到同一slot里去
3.springboot整合redis
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RedisOperations.class)
@EnableConfigurationProperties(RedisProperties.class)//该注解会注册RedisProperties,redis的id,port...
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")//这里会默认配置redisTemplate的bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {//这里会默认配置stringRedisTemplate的bean
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
}
4.Redisson
因为没有lua导致redis没有原子性会引起一系列的问题,jvm锁在集群环境也是不能用的
4.1Redisson.lock()
public void lockInterruptibly(long leaseTime, TimeUnit unit) throws InterruptedException {
long threadId = Thread.currentThread().getId();
Long ttl = tryAcquire(leaseTime, unit, threadId);//核心
if (ttl == null) {//获取到锁ttl为null
return;
}
RFuture<RedissonLockEntry> future = subscribe(threadId);//发布消息,到时候释放锁唤醒未抢到锁的线程
commandExecutor.syncSubscription(future);
try {
while (true) {
ttl = tryAcquire(leaseTime, unit, threadId);//ttl为获取锁的线程还需要多久释放锁
if (ttl == null) {
break;
}
if (ttl >= 0) {
getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);//这里使用信号量,不会占用cpu资源,等等待时间到了,获取持有锁的线程释放锁了,继续获取锁,redission默认的是非公平锁
} else {
getEntry(threadId).getLatch().acquire();
}
}
} finally {
unsubscribe(future, threadId);
}
}
//这个方法是`看门狗`,服务续约
private <T> RFuture<Long> tryAcquireAsync(long leaseTime, TimeUnit unit, final long threadId) {
if (leaseTime != -1) {
return tryLockInnerAsync(leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(), TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
ttlRemainingFuture.addListener(new FutureListener<Long>() {
@Override
public void operationComplete(Future<Long> future) throws Exception {
if (!future.isSuccess()) {
return;
}
Long ttlRemaining = future.getNow();
if (ttlRemaining == null) {//若获取到的ttl不为null,即没有获取到锁,会进行服务续约
scheduleExpirationRenewal(threadId);
}
}
});
return ttlRemainingFuture;
}
//服务续约
private void scheduleExpirationRenewal(final long threadId) {
if (expirationRenewalMap.containsKey(getEntryName())) {
return;
}
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
RFuture<Boolean> future = commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +//这一句更新了过期时间
"return 1; " +
"end; " +
"return 0;",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
future.addListener(new FutureListener<Boolean>() {
@Override
public void operationComplete(Future<Boolean> future) throws Exception {
expirationRenewalMap.remove(getEntryName());
if (!future.isSuccess()) {
log.error("Can't update lock " + getName() + " expiration", future.cause());
return;
}
if (future.getNow()) {
scheduleExpirationRenewal(threadId);
}
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);//可以看到这里是指定时间的三分之一执行,这里没有使用自带的定时任务,是时间间隔能更好的控制(第一次触发时间更加合理)
if (expirationRenewalMap.putIfAbsent(getEntryName(), task) != null) {
task.cancel();
}
}
//这个方法是获取锁的核心
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +//注意这里ARGV[2]对应下面的getLockName(threadId),不同的线程进来是不一样的
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
4.2 Redisson和zk作为分布式锁的区别
- Redis主从架构锁失效问题解析
redis数据默认异步同步到从节点,万一主节点挂了,从节点会丢失数据。zk不会存在这个问题,zk要操过半数节点同步数据后才会返回成功,若主节点挂了,会让数据较新的从节点升为主节点
- 网上说红锁可以解决redis主从失效?
红锁思路和zk相似,像所有master写,多半master节点成功才算加锁成功。但是还是存在一定的问题
1.若master未同步到从节点,下一次加锁请求到从节点晋升后的主节点是可以加锁成功的。
2.持久化,一般设置1s持久化一次,可能在那一秒挂了,没有持久化挂了
4.3 Redisson作为锁如何提升性能
1.锁的粒度越小越好
2.分段锁(可以提升几十倍性能,例如同一个商品拆分为多个key,101_stock,102_stock这样,相当于把一把锁从业务逻辑角度拆成了多把锁)
5.秒杀,穿透、击穿、大Key
5.1缓存数据冷热数据分离
缓存中存在数据,查到后刷新缓存
5.2 突发性热点数据系统压力大
分布式锁锁住redis -> mysql,这样同一个产品只会有一个打到数据库
5.3 缓存与数据库双写不一致
线程1在查数据,更新缓存这两个操作之间,别的线程修改了缓存, 解决:加锁
5.4压力暴增及锁优化
- 可以根据业务使用读写锁,redisson也有自己的读写锁,加了一个mode:读/写属性
2.若10000个线程抢同一个锁,运行玩需要加锁解锁10000次,可以考虑tryLock,具体时间更具业务代码执行时间,但若时间到了第一个线程没有放缓存,后面的线程会出现问题
3.单机redis能扛10w,但是jvm缓存能扛100w,使用多级缓存
5.5缓存穿透
缓存穿透和缓存击穿的区别在于这个透,代表所有缓存层失效,打到mysql
解决:1.打到mysql后,没有查到任何数据,缓存空对象
2.使用布隆过滤器,可以判断一定不存在和可能存在
5.5.1 布隆过滤器
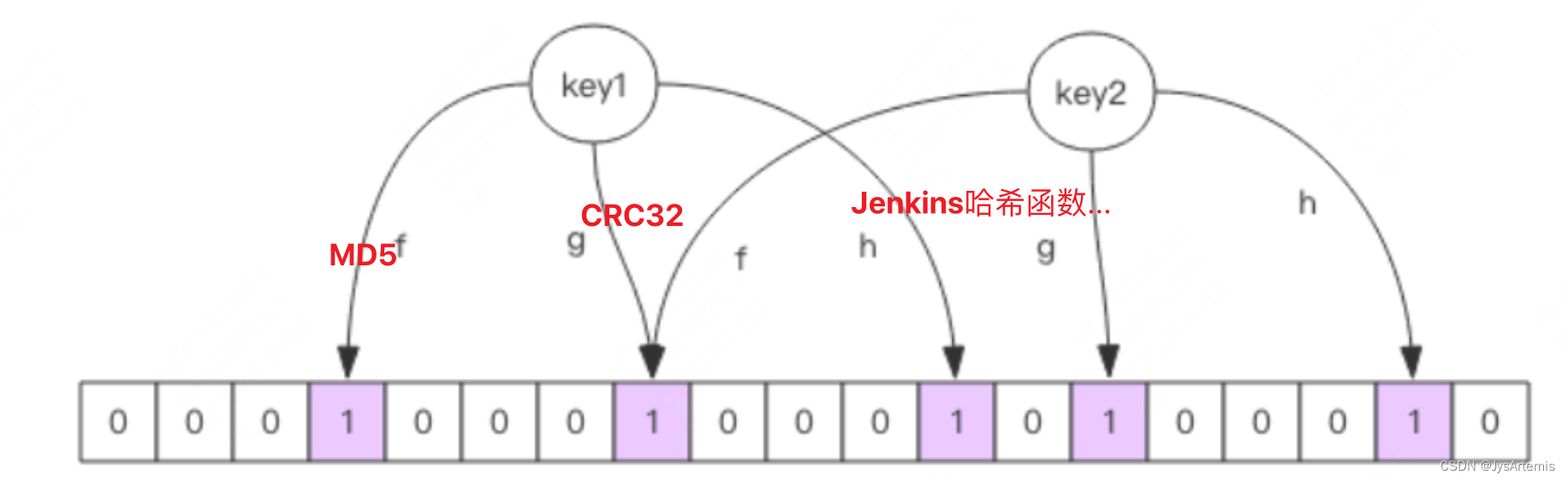
初始化一个很长的bit数组,8个bit才是一byte,很小,若1亿的长度的bit数组占用内存才10M多点儿。原理是对一个key进行多种hash算法,然后%数组长度,落在哪里就标记为1,例如图中的key1,三种hash算法把三个bit标记为1,判断它是否存在的时候就再次用这三种hash算法看是否都是1,若都是1,代表key存在。 但是布隆过滤器不能100%判断key是否存在,即使数组无限长,也存在概率hash冲突,所以在我们使用布隆过滤器的时候,可以指定一个精度,例如96%,这样布隆过滤器能够拦截住大量无效流量,即使存在少部分流程穿透,我们也有缓存层。注意:布隆过滤器不能新增key,或更新key,只能重构整个布隆过滤器
5.6 缓存失效(击穿)
大批量缓存同一时间失效
过期时间加一些随机值
5.7 缓存雪崩
缓存雪崩指的是缓存层支撑不住或宕掉后, 流量会像奔逃的野牛一样, 打向后端存储层。
1.保证缓存层的高可用
2.为后端限流熔断并降级。比如使用Sentinel或Hystrix限流降级组件。
5.8 BigKey
主要针对val来说,一般认为val超过10kb算作bigkey
BigKey的危害:
1.导致redis阻塞,redis执行业务命令线程是单线
2.网络阻塞,比如一个bigkey为1MB,qps1000,就是1个G的流量,对于千兆网卡带宽才128M来说是灭顶之灾
3.过期删除,如果没有使用Redis 4.0的过期异步删除(lazyfree-lazy- expire yes),就会存在阻塞Redis的可能性
BigKey的产生:
一般来说由于程序设计不当,我们可以拆分: eg:big list: list1、list2、…listN,
6 Redis6.0 连环问题
1.redis6.0之前是单线程吗?
业务线程是,但是主从同步,异步删除等命令不是
2.redis6.0之前为什么不引入多线程?
redis是内存中的key,val数据库,对于redis来讲,cpu从来不是瓶颈,主要受限于内存和网络,在一个普普通通的piepline,每秒可以完成100w次请求,多线程会上下文切换…问题
3.redis6.0后为什么引入多线程
cpu执行指令大概0.6ns,内存大概100ns,redis最多10w次,这是物理机的极限。热点key,例如微博x明显结婚了,在redis就是一对key,val键值对,即使集群也只能落在一台机器上,而且即使集群了redis可能发生数据倾斜
通过多线程提高io读写,利用多核cpu的优点
4.redis6.0是否默认开启多线程
默认未开启。
5.redis引用多线程后,性能提升如何?
官方说大概翻一倍,原来10w,现在20w
6.redis多线程的实现机制?
网络读写多线程,操作内存时是单线程
7.开启多线程后,是否存在线程并发安全问题?
多线程处理网络读写,对内存的操作依旧单线程,所以不会出现
7 Redis事务
卵的,很卵
multi开启事务, exec提交事务
redis只会处理命令错误,若命令本身没有错,只有运行的时候会出错,redis不会察觉到
还有一个watch命令,在开启事务前watch一个key,然后开启事务,若这个key变化了,事务失效
redis7.0优化了主从复制
















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









