







RDD编程初级实践
1、需求描述
本次实验所需要用到的是RDD编程、pyspark运行环境以及spark独立应用程序等相关知识。RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。现在开发的过程中都是面向对象的思想,那么我们创建类的时候会对类封装一些属性和方法,那么创建出来的对象就具备着这些属性和方法,类也属于对数据的抽象,而Spark中的RDD就是对操作数据的一个抽象。在 Spark 中,对数据的所有操作不外乎创建 RDD、转化已有RDD 以及调用 RDD 操作进行求值。每个 RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含 Python、Java、Scala 中任意类型的对象, 甚至可以包含用户自定义的对象。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
2、环境介绍
Ubuntu系统为Ubuntu16.04,本实验采用的版本是Spark2.1.0。Spark可以独立使用,也可以和Hadoop,一起使用Apache Spark 是一个新兴的大数据处理通用引擎,提供了分布式的内存抽象。Spark 最大的特点就是快,可比 Hadoop MapReduce 的处理速度快 100 倍。以Python为编程语言,使用Spark对数据进行分析,Python版本为3.5.2。
3、数据来源描述
1、pyspark交互式编程
本作业提供分析数据data.txt,该数据集包含了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
2、编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。本文给出门课的成绩(A.txt、B.txt)下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
20200101 x
20200102 y
20200103 x
20200104 y
20200105 z
20200106 z
输入文件B的样例如下:
20200101 y
20200102 y
20200103 x
20200104 z
20200105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20200101 x
20200101 y
20200102 y
20200103 x
20200104 y
20200104 z
20200105 y
20200105 z
20200106 z
3、编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。本文给出门课的成绩(Algorithm.txt、Database.txt、Python.txt),下面是输入文件和输出文件的一个样例,供参考。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
4、数据上传及上传结果查看
1、pyspark交互式编程
在/usr/local/spark/路径下查看是否存在data.txt文件,并查看文件内容。如下图4.1.1、图4.1.2所示。

图4.1.1 data.txt文件

图4.1.2 data.txt文件内容
2、编写独立应用程序实现数据去重
在/usr/local/spark/mycode/remdup路径下,查看是否存在A.txt、B.txt文件并查看文件内容,如下图4.2.1、图4.2.2、图4.2.3所示。

图4.2.1 A.txt、B.txt文件

图4.2.2 A.txt文件内容

图4.2.3 B.txt文件内容
3、编写独立应用程序实现求平均值问题
在/usr/local/spark/mycode/avgscore路径下,查看是否存在Alqorithm.txt、Database.txt、Python.txt文件并查看具体文件内容,如下图4.3.1、图4.3.2、图4.3.3、图4.3.4所示。

图4.3.1 Alqorithm.txt、Database.txt、Python.txt文件

图4.3.2 Alqorithm.txt文件内容

图4.3.3 Database.txt文件内容

图4.3.4 Python.txt文件内容
5、数据处理过程描述
1、pyspark交互式编程
在/urs/local/spark路径下进入pyspark环境中,读取data.txt文件并生成RDD文件,如下图5.1.1所示。

图5.1.1
(1)该系总共有多少学生;
获取每行数据的第1列,使用distinct进行去重,用sum取元素总数,如下图5.1.2所示。

图5.1.2
(2)该系共开设了多少门课程;
获取每行数据的第2列,使用distinct进行去重,用sum取元素总数,如下图5.1.3所示。

图5.1.3
(3)Tom同学的总成绩平均分是多少;
过滤Tom同学的成绩信息并显示数据,提取每门成绩转换为int类型,显示平均分数值,如下图5.1.4、图5.1.5、图5.1.6、图5.1.7所示。

图5.1.4

图5.1.5

图5.1.6
计算平均成绩

图5.1.7
(4)求每名同学的选修的课程门数;
学生每门课程对应(姓名,1),对相同key的数据进行处理,最终每个key只保留一条信息,最后显示选修课程的信息,如下图5.1.8、图5.1.9、图5.1.10、图5.1.11、图5.1.12所示。

图5.1.8

图5.1.9

图5.1.10

图5.1.11
…

图5.1.12
(5)该系DataBase课程共有多少人选修;
过滤课程为“DataBase”的信息,并显示数值,如下图5.1.13所示。

图5.1.13
(6)各门课程的平均分是多少;
每门课程的分数后面新增一列1,则表示有1个学生选择了该门课程,之后对相同key的数据进行处理,最终每个key只保留一条记录,并按照课程的名字聚合总分和选课人数,如下图5.1.14所示。

图5.1.14
(7)使用累加器计算共有多少人选了DataBase这门课。
过滤课程为“DataBase”的信息,使用累加器accum定义由0开始,并显示最终结果,如下图5.1.15所示。

图5.1.15
2、编写独立应用程序实现数据去重
在/usr/local/spark/sparksqldata路径下,将A.txt,B.txt文件的内容分别复制到”vim A”,”vim B”中,同时创建一个“C.py”的文件,具体步骤如下图5.2.1所示。

图5.2.1
在“C.py”中编辑程序,如下图5.2.2所示。

图5.2.2
运行“C.py”,在/usr/local/spark/sparksqldata/result路径下获取part-00000 _SUCCESS的文件。具体操作如下图5.2.3所示。

图5.2.3
查看part-00000 _SUCCESS的文件,如下图5.2.4所示。

图5.2.4
3、编写独立应用程序实现求平均值问题
在/usr/local/spark/mycode/avgscore路径下,将Algorithm.txt,Database.txt、Python.txt文件的内容分别复制到”vim Algorithm”,”vim Database”,”vim Python”中,同时创建一个“avg.py”的文件,具体步骤如下图5.3.1所示。

图5.3.1
在“avg.py”中编辑程序,如下图5.3.2所示。
初始化SparkContext;
加载三个文件;
合并三个文件;
为每行数据新增一列1,方便后续统计每个学生选修的课程数目,data的数据格式为(‘小明’,(92,1));
根据key也就是学生姓名合计每门课程的成绩,以及选修的课程数目,res的数据格式为(‘小明’,(263,3));
利用总成绩除以选修的课程数来计算每个学生的每门课程的平均分,并利用round(x,2)保留两位小数;
将结果写入result文件中,repartition(1)的作用是让结果合并到一个文件中,不加的话结果会加入到三个文件中。

图5.3.2
运行“avg.py”,在/usr/local/spark/mycode/avgscore路径下查看是否存在result1文件,并在/usr/local/spark/mycode/avgscore/result1路径下获取part-00000 _SUCCESS的文件。具体操作如下图5.3.3、图5.3.4所示。

图5.3.3
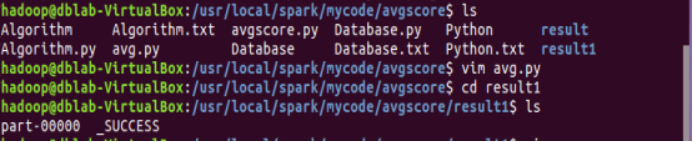
图5.3.4
查看part-00000 _SUCCESS的文件,如下图5.3.5所示。

图5.3.5















 6616
6616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









