






1.用过哪些集合?hashmap扩容?如果<string>如何查找?散列函数用什么散列为什么大小是2的幂次?如果是key 为abc怎么散列?如何知道key不存在?默认大小是否可以修改 ,改为30 、32 可以不?是否看过源码?hashmap查找时间复杂度?arrayList查找时间复杂度?
1.Java 提供了一系列的集合框架,常用的包括 ArrayList, LinkedList, HashMap, TreeMap, HashSet, TreeSet 等。
2.在添加元素或初始化的时候需要调用resize方法进行扩容,第一次添加数据初始化数组长度为16,以后每次扩容都是达到了扩容阈值(数组长度 * 0.75),每次扩容的时候,都是扩容之前容量的2倍;扩容之后,会新创建一个数组,需要把老数组中的数据挪动到新的数组中,没有hash冲突的节点,则直接使用 e.hash & (newCap - 1) 计算新数组的索引位置。如果是红黑树,走红黑树的添加。如果是链表,则需要遍历链表,可能需要拆分链表,判断(e.hash & oldCap)是否为0,该元素的位置要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上。
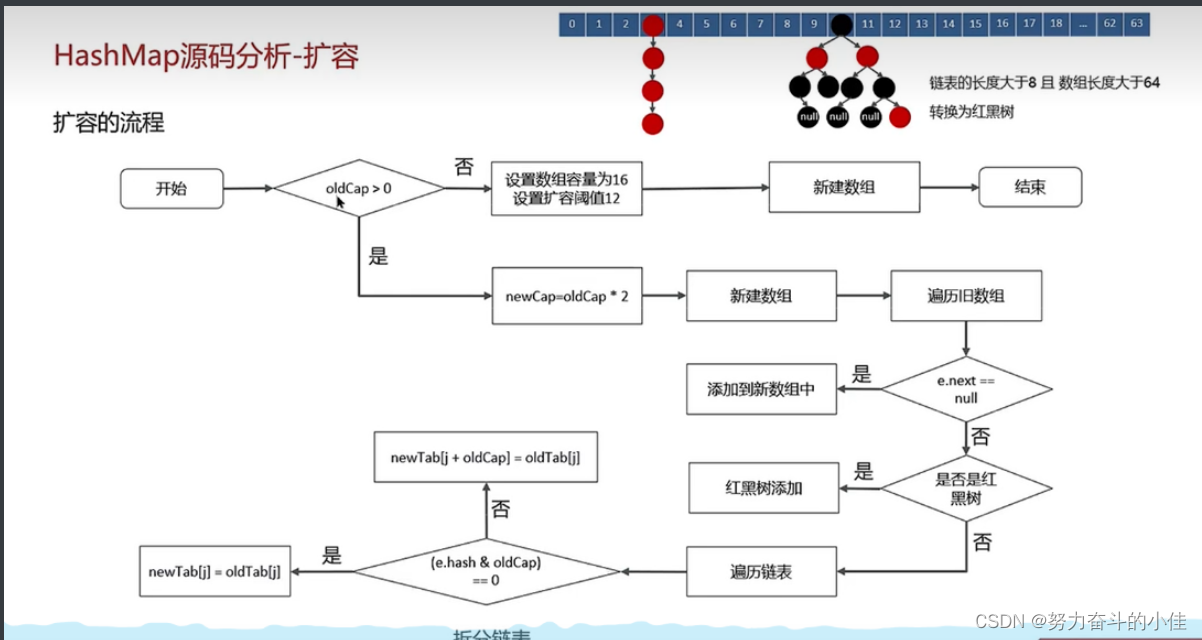
3.先计算出key的哈希值,然后直接使用 e.hash & (newCap - 1) 计算新数组的索引位置,从而查找到对应的元素。
4.在Java的HashMap中,容量是2的幂次方(比如16、32、64等),这样设计的主要目的是为了让散列值的分布更加均匀,并且能够利用位运算来代替模运算,以提高计算索引位置的效率。当使用2的幂次作为数组的大小时,计算索引的模运算(通常是hashCode % arraySize)可以被转换为位运算(hashCode & (arraySize - 1)),这是因为arraySize是2的幂次方,所以arraySize - 1将是一个所有位都是1的数字,这样就可以保证散列值均匀分布在数组的各个位置上。
为什么位运算比模运算要快
位运算(如与运算&)直接操作数字的二进制位,而不需要执行除法运算。在计算机处理中,位运算是非常快的,因为它们直接在CPU级别上进行操作,而不涉及更复杂的数学运算。相比之下,模运算(%)通常需要执行除法操作,除法是CPU中较慢的操作之一,尤其是当除数是变量而不是常数时。
如何计算取模
当我们说HashMap的索引位置计算时使用位运算代替模运算,实际上是这样操作的:
- 计算hashCode:首先计算键的
hashCode()方法返回的散列码。 - 高位运算:在某些实现中,可能会对hashCode进行进一步的处理,如右移和异或操作,以减少高位不变时低位变化不足的问题,这步骤可以提高散列的均匀性。
- 计算索引位置:最后,使用
hashCode & (n - 1)计算这个键应该存放的数组索引,其中n是数组的大小,且为2的幂次方。这里的&操作实际上是取模的一个快速操作,能够确保计算出的索引位置不会超过数组的最大索引。
例如,如果数组大小是16(n = 16),则n - 1 = 15,二进制为1111。任何数与1111进行与运算,都会得到一个0到15之间的数,等同于这个数对16取模的结果,但速度更快。
第一:
计算索引时效率更高:如果是 2 的 n 次幂可以使用位与运算代替取模
第二:
扩容时重新计算索引效率更高:在进行扩容是会进行判断 ((e.hash & oldCap))hash值按位与运算旧数组长租是否 == 0。如果等于0,则把元素留在原来位置 ,否则新位置是等于旧位置的下标+旧数组长度
5.如果键不存在,通过键的哈希值找到的数组位置将是null或者该位置的链表(或红黑树)中没有与该键相匹配的节点。
6.HashMap的初始大小可以通过构造函数指定,但它总是会被转换成2的幂次方。如果尝试设置为30,实际会被调整为32,因为32是大于30的最小的2的幂次方。
7.
HashMap的查找时间复杂度在最佳情况下是O(1)。但在最坏的情况下,如果所有的元素都被映射到同一个桶(哈希冲突),时间复杂度会退化到O(n)。自Java 8起,当链表长度大于阈值(默认为8)时,链表会转换成红黑树,这样即使在最坏的情况下时间复杂度也是O(log n)。ArrayList的查找时间复杂度是O(n),因为需要从头到尾遍历列表来查找元素。
2.varchar(50)和varchar(500)有什么区别?内存空间都一样的话,我为什么不都用varchar(500)呢?
-
数据完整性:字段长度应该根据实际的业务规则来设定。例如,如果一个字段用来存储用户的名字,那么
VARCHAR(50)通常就足够了。设置适当的长度可以帮助维护数据的完整性,避免不必要的数据错误。 -
性能考虑:尽管
VARCHAR类型字段存储实际所用空间加上一个长度标识,并不会因为声明的最大长度而占用更多的物理存储空间,但是在某些操作中,如排序或建立索引时,过长的字段可能会导致性能下降。这是因为数据库可能需要为这些操作分配更多的内存空间,尤其是当这些字段中存储了接近其最大长度的数据时。 -
存储效率:在设计数据库时,考虑存储效率是很重要的。虽然磁盘空间相对便宜,但是优化存储结构可以提高查询效率,减少IO操作。此外,更高效的存储也意味着更好的缓存利用率和更快的数据访问速度。
-
应用层验证:在应用层设置字段长度限制也是确保数据质量的一个重要手段。使用
VARCHAR(500)而非VARCHAR(50)意味着在应用层也需要相应地处理更长的字符串输入,这可能会增加数据验证的复杂度。
3.查看一下这两段代码有什么区别?
public class Test {
private double result = 0.0D;
public void addAll(double[] values){
for (double value : values) {
result+=value;
}
System.out.println(result);
}
public void addAll01(double[] values){
double sum = 0.0D;
for (double value : values) {
sum += value;
}
result += sum;
System.out.println(result);
}
}
这两种实现在功能上是相似的,但第二种实现(下部分)使用了一个额外的局部变量 sum 来存储中间累加结果,这在某些情况下可以避免多线程环境下的竞态条件(race condition),因为修改局部变量不会影响到类的状态,直到最后将累加结果赋给 result。然而,如果 Accumulator 类的实例不是被多个线程共享的,那么这种额外的预防措施可能是不必要的。
4.mysql版本?数据库隔离级别用的哪个?
在我的最近一个项目中,我使用的是MySQL 8.0,这是目前的一个稳定版本,它提供了许多改进的功能和性能优化,比如更好的JSON支持、窗口函数、公共表表达式(CTEs)、提高了索引的效率等。我使用 的是mysql的默认隔离级别不可重复读,他可以解决脏读以及不可重复度问题,而且性能也比较好。
5.如何排查慢查询,explain字段的作用?
我们当时做压测的时候有的接口非常的慢,接口的响应时间超过了2秒以上,因为我们当时的系统部署了运维的监控系统Skywalking ,在展示的报表中可以看到是哪一个接口比较慢,并且可以分析这个接口哪部分比较慢,这里可以看到SQL的具体的执行时间,所以可以定位是哪个sql出了问题如果,项目中没有这种运维的监控系统,其实在MySQL中也提供了慢日志查询的功能,可以在MySQL的系统配置文件中开启这个慢日志的功能,并且也可以设置SQL执行超过多少时间来记录到一个日志文件中,我记得上一个项目配置的是2秒,只要SQL执行的时间超过了2秒就会记录到日志文件中,我们就可以在日志文件找到执行比较慢的SQL了。
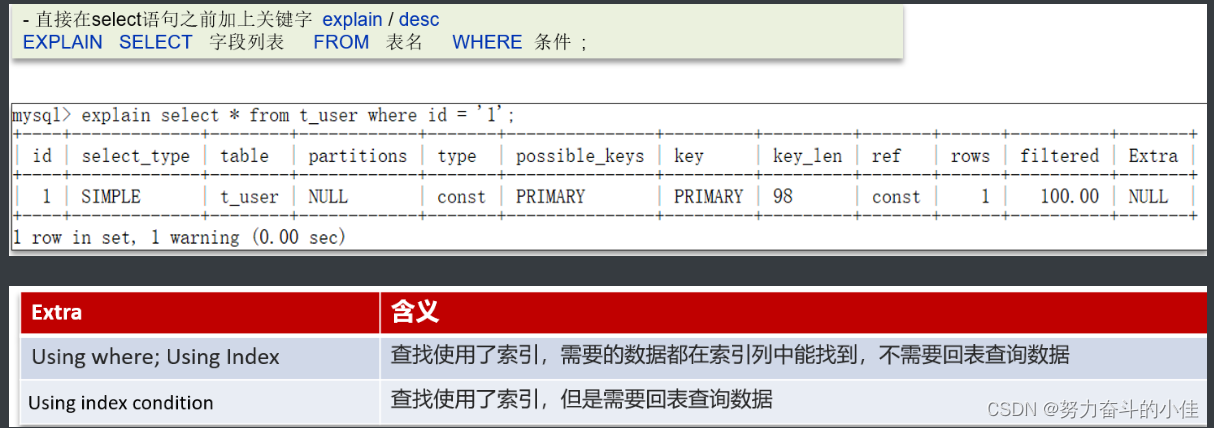
如果一条sql执行很慢的话,我们通常会使用mysql自动的执行计划explain来去查看这条sql的执行情况,比如在这里面可以通过key和key_len检查是否命中了索引,如果本身已经添加了索引,也可以判断索引是否有失效的情况,第二个,可以通过type字段查看sql是否有进一步的优化空间,是否存在全索引扫描或全盘扫描,第三个可以通过extra建议来判断,是否出现了回表的情况,如果出现了,可以尝试添加索引或修改返回字段来修复。
6.sql优化如何优化?
嗯,这个也有很多,比如SELECT语句务必指明字段名称,不要直接使用select * ,还有就是要注意SQL语句避免造成索引失效的写法;如果是聚合查询,尽量用union all代替union ,union会多一次过滤,帅选不重复的数据,效率比较低;如果是表关联的话,尽量使用innerjoin ,不要使用用left join right join,如必须使用 一定要以小表为驱动,内连接会对两个表进行优化,优先把小表放在外面,把大表放在里面。插入数据时最好是批量插入和主键顺序插入,尽量降低主键的长度,主键长度越长,那么数据库的磁盘io就消耗越大。最好根据索引去更新,索引更新是加了行锁,否则是表级锁。
7.索引类型?聚集索引和非聚集索引的区别是什么?
索引是数据库管理系统中用于加速数据检索的数据结构。在数据库中,主要有两种类型的索引:聚集索引(Clustered Index)和非聚集索引(Non-Clustered Index)。它们在存储数据和检索效率方面有着根本的区别:
聚簇索引主要是指数据与索引放到一块,B+树的叶子节点保存了整行数据,有且只有一个,一般情况下主键在作为聚簇索引的。
非聚簇索引值的是数据与索引分开存储,B+树的叶子节点保存对应的主键,可以有多个,一般我们自己定义的索引都是非聚簇索引















 2452
2452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









