






前文链接:http://t.csdnimg.cn/hQjRd
缓存双写一致性
只要使用redis作为缓存,那么就可能会涉及到redis缓存与数据库双存储双写,那么只要是双写就一定会有数据一致性的问题。
如果redis中有数据,那么需要和数据库中的值相同。
如果redis中没有数据,那么数据库中如果有新值回写redis。
读写缓存的两种策略
同步直写策略
写数据库后也同步写redis缓存,换成和数据库中的数据一致。
对于读写缓存来说,要想保证缓存和数据库中的数据一致就要采用同步直写策略。
同步直写策略一般用于重要的数据或者热点数据,需要保证及时一致性的情况。
异步缓写策略
正常业务中,mysql的数据变动了,但是可以在业务上容许出现一定时间后才作用于redis,比如仓库,物流等等。如果出现异常,需要借助kafka或者rabbitMQ等消息中间件实现重试重写。
高并发情况下为了避免缓存击穿,需要使用双检加锁策略。
双检加锁策略
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
import com.atguigu.redis.entities.User;
import com.atguigu.redis.mapper.UserMapper;
import io.swagger.models.auth.In;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.stereotype.Service;
import org.springframework.web.bind.annotation.PathVariable;
import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;
@Service
@Slf4j
public class UserService {
public static final String CACHE_KEY_USER = "user:";
@Resource
private UserMapper userMapper;
@Resource
private RedisTemplate redisTemplate;
/**
* 业务逻辑没有写错,对于小厂中厂(QPS《=1000)可以使用,但是大厂不行
* @param id
* @return
*/
public User findUserById(Integer id)
{
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql
user = (User) redisTemplate.opsForValue().get(key);
if(user == null)
{
//2 redis里面无,继续查询mysql
user = userMapper.selectByPrimaryKey(id);
if(user == null)
{
//3.1 redis+mysql 都无数据
//你具体细化,防止多次穿透,我们业务规定,记录下导致穿透的这个key回写redis
return user;
}else{
//3.2 mysql有,需要将数据写回redis,保证下一次的缓存命中率
redisTemplate.opsForValue().set(key,user);
}
}
return user;
}
/**
* 加强补充,避免突然key失效了,打爆mysql,做一下预防,尽量不出现击穿的情况。
* @param id
* @return
*/
public User findUserById2(Integer id)
{
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql,
// 第1次查询redis,加锁前
user = (User) redisTemplate.opsForValue().get(key);
if(user == null) {
//2 大厂用,对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysql
synchronized (UserService.class){
//第2次查询redis,加锁后
user = (User) redisTemplate.opsForValue().get(key);
//3 二次查redis还是null,可以去查mysql了(mysql默认有数据)
if (user == null) {
//4 查询mysql拿数据(mysql默认有数据)
user = userMapper.selectByPrimaryKey(id);
if (user == null) {
return null;
}else{
//5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作
redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS);
}
}
}
}
return user;
}
}给缓存设置过期时间,定期清理缓存并回写,是保证最终一致性的解决方案。
我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存,达到一致性,切记,要以mysql的数据库写入库为准。
缓存一致性的更新策略:
先更新数据库,再删除缓存
可能出现的异常情况:假如缓存删除失败或者来不及,导致请求再次访问redis时缓存命中,读取到的是缓存旧值。
解决方案
1、可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用Kafka/RabbitMQ等)。
2、当程序没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。
3、如果能够成功地删除或更新,我们就要把这些值从消息队列中去除,以免重复操作,此时,我们也可以保证数据库和缓存的数据一致了,否则还需要再次进行重试
在大多数业务场景下, 优先使用先更新数据库,再删除缓存的方案(先更库→后删存)。因为如果先删除缓存值再更新数据库,有可能导致请求因缓存缺失而访问数据库,给数据库带来压力导致打满mysql。如果业务应用中读取数据库和写缓存的时间不好估算,那么,延迟双删中的等待时间就不好设置。
在使用先更新数据库,再删除缓存方案时,如果业务层要求必须读取一致性的数据,那么我们就需要在更新数据库时,先在Redis缓存客户端暂停并发读请求,等数据库更新完、缓存值删除后,再读取数据,从而保证数据一致性,这是理论可以达到的效果,但实际,不推荐,因为真实生产环境中,分布式下很难做到实时一致性,一般都是最终一致性。
Canal
面试题:我想mysql有记录改动(有增删改写操作),立刻同步反应到redis,该如何做?
可以使用canal,canal能够监听到mysql、的变动且及时的通知给redis。
canal主要用于Mysql数据库增量日志解析,提供增量数据订阅和消费。
功能
数据库镜像。数据库实时备份。索引构建和实时维护(拆分异构索引、倒排索引等等)。业务cache刷新。带业务逻辑的增量数据处理。
工作原理
传统MySQL主从复制工作原理:
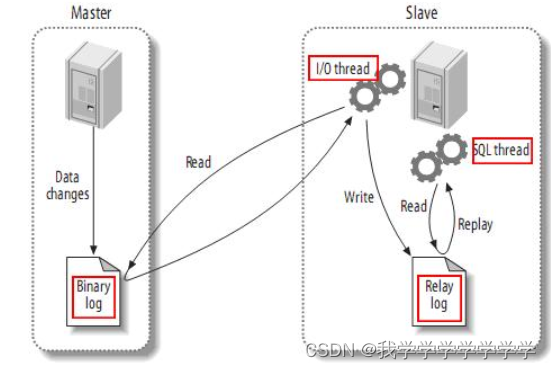
1、当 master 主服务器上的数据发生改变时,则将其改变写入二进制事件日志文件中;
2、salve 从服务器会在一定时间间隔内对 master 主服务器上的二进制日志进行探测,探测其是否发生过改变,如果探测到 master 主服务器的二进制事件日志发生了改变,则开始一个 I/O Thread 请求 master 二进制事件日志;
3、同时 master 主服务器为每个 I/O Thread 启动一个dump Thread,用于向其发送二进制事件日志;
4、slave 从服务器将接收到的二进制事件日志保存至自己本地的中继日志文件中;
5、salve 从服务器将启动 SQL Thread 从中继日志中读取二进制日志,在本地重放,使得其数据和主服务器保持一致;
6、最后 I/O Thread 和 SQL Thread 将进入睡眠状态,等待下一次被唤醒。
canal工作原理:
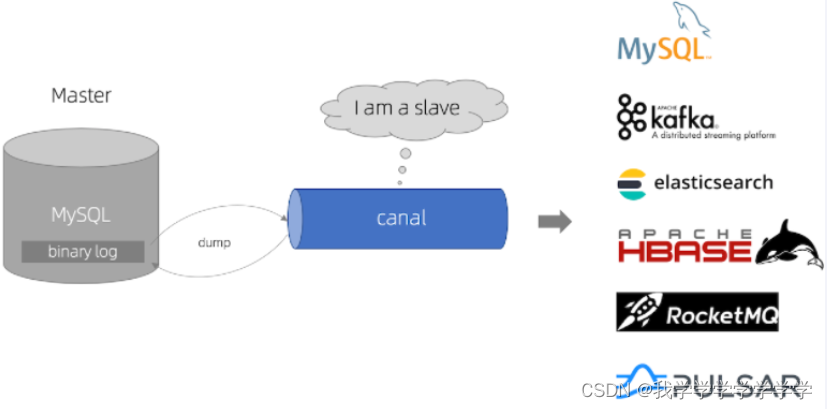
1、canal模拟MySQLslave的交互协议,伪装自己为MySQLslave,向MySQLmaster发送dump协议;
2、MySQLmaster收到dump请求,开始推送binary log给slave(即cana);
3、cana解析binary log对象(原始为byte流)。
bitmap-大数据统计
bitmap是由0和1状态标识的二进制位的bit数组。
用于状态统计。Y、N,类似 AtomicBoolean (AtomicBoolean 内部持有了一个 volatile变量修饰的value,底层通过对象在内存中的偏移量(valueOffset)对应的旧值与当前值进行比较,相等则更新并返回true;否则返回false。即CAS的交换思想,AtomicBoolean 内部可以保证,在高并发情况下,同一时刻只有一个线程对变量修改成功。)
适用需求:用户是否登录过,比如京东签到领取京豆;统计连续打卡用户;统计用户一年之中的登录天数等。
布隆过滤器
布隆过滤器是由一个初值都为0的bit数字和多个哈希函数构成,用来快速判断集合中是否存在某个元素。
通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、哈希表等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n),O(logn),O(1)。这个时候,布隆过滤器(Bloom Filter)就应运而生。
布隆过滤器实际是一个很长的二进制数组(00000000)+一系列随机hash算法映射函数,本质就是判断具体数据是否存在于一个大的集合里。是一种类似set的数据结构,只是统计结果在巨量数据下有点小瑕疵。

特点
1、高效的插入和查询,占用空间少,返回的结果是不确定性的,不够完美。
2、布隆过滤器中一个元素如果判断结果:存在时,元素不一定存在;但是判断结果为不存在时,则一定不存在。
3、布隆过滤器可以添加元素,但是不可以删除元素,由于设计hashcode判断依据,删除元素会导致误判率增加。
布隆过滤器原理
布隆过滤器(Bloom Filter) 是一种专门用来解决去重问题的高级数据结构。
实质就是一个大型位数组和几个不同的无偏hash函数(无偏表示分布均匀)。由一个初值都为零的bit数组和多个个哈希函数构成,用来快速判断某个数据是否存在。但是跟 HyperLogLog 一样,它也一样有那么一点点不精确,也存在一定的误判概率。
添加key时
使用多个hash函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,每个hash函数都会得到一个不同的位置,将这几个位置都置1就完成了add操作。
查询key时
只要有其中一位是零就表示这个key不存在,但如果都是1,则不一定存在对应的key。
哈希冲突导致数据不精准
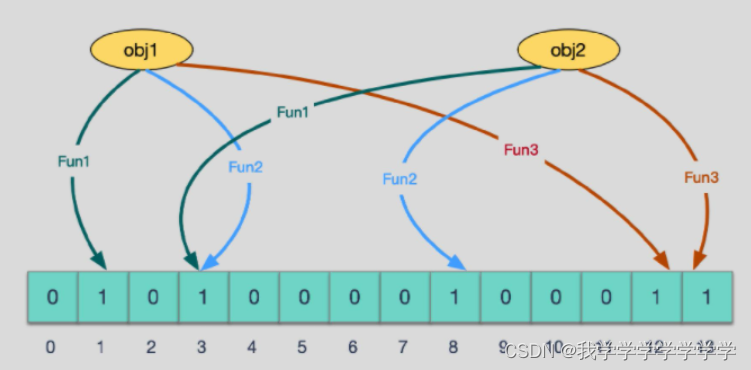
当有变量被加入集合时,通过N个映射函数将这个变量映射成位图中的N个点,把它们置为 1(假定有两个变量都通过 3 个映射函数)。查询某个变量的时候我们只要看看这些点是不是都是 1, 就可以大概率知道集合中有没有它了。
如果这些点,有任何一个为零则被查询变量一定不在,如果都是 1,则被查询变量很可能存在,
使用步骤
初始化bitmap
布隆过滤器 本质上 是由长度为 m 的位向量或位列表(仅包含 0 或 1 位值的列表)组成,最初所有的值均设置为 0
添加占坑位
当我们向布隆过滤器中添加数据时,为了尽量地址不冲突,会使用多个 hash 函数对 key 进行运算,算得一个下标索引值,然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
例如,我们添加一个字符串wmyskxz,对字符串进行多次hash(key) → 取模运行→ 得到坑位
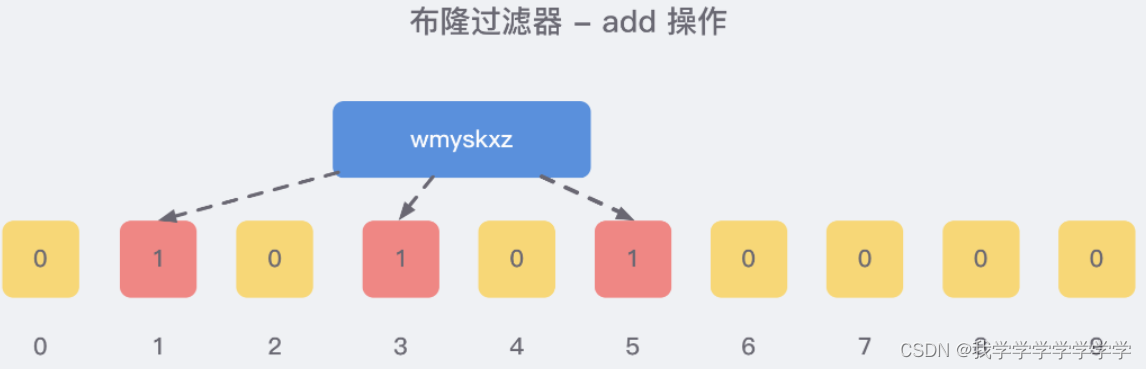
判断是否存在
向布隆过滤器查询某个key是否存在时,先把这个 key 通过相同的多个 hash 函数进行运算,查看对应的位置是否都为 1,只要有一个位为零,那么说明布隆过滤器中这个 key 不存在;如果这几个位置全都是 1,那么说明极有可能存在;因为这些位置的 1 可能是因为其他的 key 存在导致的,也就是hash冲突。就比如我们在 add 了字符串wmyskxz数据之后,很明显下面1/3/5 这几个位置的 1 是因为第一次添加的 wmyskxz 而导致的;此时我们查询一个没添加过的不存在的字符串inexistent-key,它有可能计算后坑位也是1/3/5 ,这就是误判了。
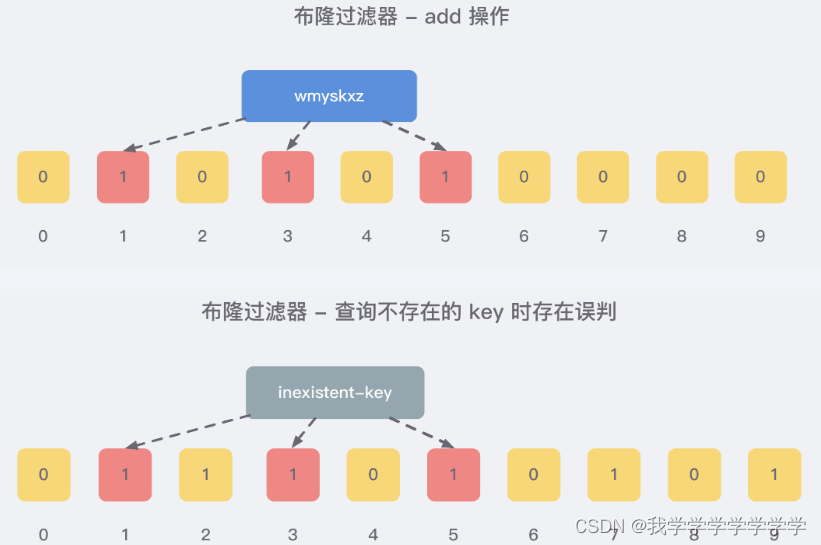
布隆过滤器误判
布隆过滤器的误判是指多个输入经过哈希之后在相同的bit位置1了,这样就无法判断究竟是哪个输入产生的,因此误判的根源在于相同的 bit 位被多次映射且置 1。
这种情况也造成了布隆过滤器的删除问题,因为布隆过滤器的每一个 bit 并不是独占的,很有可能多个元素共享了某一位。如果我们直接删除这一位的话,会影响其他的元素。
结论
使用布隆过滤器判断是否存在:有,可能有!无,一定无!
使用时最好不要让实际元素数量远大于初始化数量,一次给够避免扩容。
当实际元素数量超过初始化数量时,应对布隆过滤器进行重建,重新分配一个size更大的过滤器,再将所有历史元素add。
布隆过滤器使用场景举例
1、解决缓存穿透问题,和redis结合bitmap使用
缓存穿透是什么?
一般情况下,先查询缓存redis是否有该条数据,缓存中没有时,再查询数据库。当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透。缓存透带来的问题是,当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库。
可以使用布隆过滤器解决缓存穿透的问题
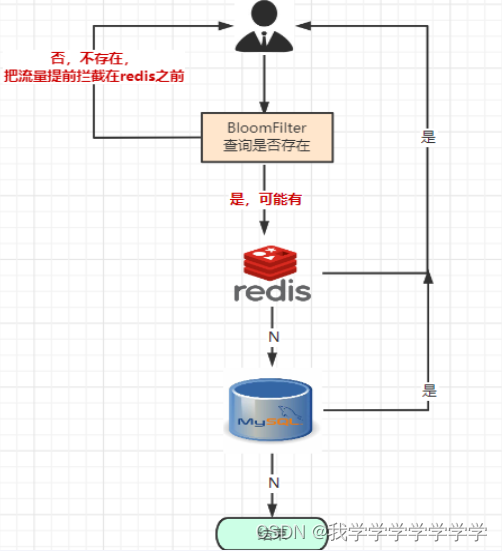
把已存在数据的key存在布隆过滤器中,相当于redis前面挡着一个布隆过滤器。
当有新的请求时,先到布隆过滤器中查询是否存在:
如果布隆过滤器中不存在该条数据则直接返回;
如果布隆过滤器中已存在,才去查询缓存redis,如果redis里没查询到则再查询Mysql数据库。
2、黑名单校验,识别垃圾邮件
优点
缺点
缓存穿透、雪崩、击穿
缓存雪崩
缓存雪崩是由于redis中有大量的key同时过期大面积失效。这在软件开发中是严重的问题。那么如何去预防和解决呢?
1、redis中的key设置为永不过期或者过期时间错开。但要注意redis中的key设置为永不过期可能会导致redis中存在大量的无用数据占据空间。
2、redis缓存集群实现高可用:主从+哨兵;Redis Cluster;开启redis持久化机制AOF/RDB,尽快恢复缓存集群。
3、多缓存结合预防雪崩:ehcache本地缓存+redis缓存。(本地缓存基于单机架构,即数据仅本机可用,无法共享给其他服务。除非使用服务调用来获取。而redis本身基于分布式架构,支持跨服务调取。所以当数据需要分布式调用时,则适用于redis,如果数据只需要本地获取,则可考虑本地缓存)
4、Hystrix、阿里sentinel限流或降级。
缓存穿透
缓存穿透是当请求去查询一条数据记录时,先去查询redis发现没有,又去查mysql也没有,都查询不到这条记录。每次请求都会打到数据库上面,数据库压力暴增被暴击导致缓存穿透,这个时候redis就形同虚设了。
解决方案
1、空对象缓存或缺省值,回写增强
如果发生了缓存穿透,我们可以针对要查询的数据,在Redis里存一个和业务部门商量后确定的缺省值(比如,零、负数、defaultNull等)。比如,键uid:abcd,值defaultNull作为案例的key和value,先去redis查键uid:abcd没有,再去mysql查没有获得 ,这就发生了一次穿透现象。
但是可以增强回写机制,mysql也查不到的话就让redis存入刚刚查不到的key并保护mysql。
第一次来查询uid:abcd,redis和mysql都没有,返回null给调用者,但是增强回写后第二次来查uid:abcd,此时redis就有值了。可以直接从Redis中读取default缺省值返回给业务应用程序,避免了把大量请求发送给mysql处理,打爆mysql。
但是,此方法有缺陷......,只能解决key相同的情况,由于存在空对象缓存和缓存回写,可能会导致redis中的无用key越来越多,需要根据业务设置过期时间。
2、使用Google布隆过滤器Guava解决缓存穿透。
自研过滤器白名单案例:白名单中有才能通过,没有直接返回null。存在一定的误判,但误判率较低。
/**
* BloomFilter → redis → mysql
* 白名单:whitelistCustomer
* @param customerId
* @return
*/
public Customer findCustomerByIdWithBloomFilter (Integer customerId) {
Customer customer=null;
//缓存的redis的key名称
String key=CACHE_KEY_CUSTOMER+customerId;
//布隆过滤器check,无是绝对无,有是可能有,可能有才去redis查询
//===============================================
if(!checkUtils.checkWithBloomFilter("whitelistCustomer",key))
{
log.info("白名单无此顾客信息:{}",key);
return null;
}
//去redis查询
customer = (Customer) redisTemplate.opsForValue().get(key);
//redis有直接返回,没有再去查询数据库
if(customer==null){
//查询数据库
customer=mapper.selectByPrimaryKey(customerId);
//mysql有,redis无
if(customer!=null){
//把mysql查出来的数据回写redis,保持一致性
redisTemplate.opsForValue().set(key,customer);
}
}
return customer;@Component
@Slf4j
public class CheckUtils
{
@Resource
private RedisTemplate redisTemplate;
public boolean checkWithBloomFilter(String checkItem,String key)
{
int hashValue = Math.abs(key.hashCode());
long index = (long) (hashValue % Math.pow(2, 32));
boolean existOK = redisTemplate.opsForValue().getBit(checkItem, index);
log.info("----->key:"+key+"\t对应坑位index:"+index+"\t是否存在:"+existOK);
return existOK;
}
}
如要使用成熟的Guava布隆过滤器需要引入依赖
<!--guava Google 开源的 Guava 中自带的布隆过滤器-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
缓存击穿
缓存击穿是由于大量的请求同时查询一个key时,这个key刚好失效,导致大量的请求打到数据库。redis热点key突然失效。会导致某一时间数据库请求压力剧增。
解决方案
1、差异失效时间,对于访问频繁的热点key,干脆就不设置过期时间。
也可开辟两块缓存,主A从B,先更新从B再更新A,严格按照这个顺序进行;在查询的时候先查询主缓存A,如果A没有(消失了或者失效了)再查询缓存B,但是要注意B缓存的过期时间需要比A缓存的过期时间长,否则过期时间一致,还是会同时过期。
2、互斥更新,采用双检加锁策略:
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
| 缓存问题 | 产生原因 | 解决方案 |
| 缓存更新方式 | 数据变更、缓存时效性 | 同步更新,失效更新,异步更新,定时更新 |
| 缓存不一致 | 同步更新失败、异步更新 | 增加重试、补偿任务、最终一致 |
| 缓存穿透 | 恶意攻击,一个根本不存在的数据 | 空对象缓存、bloomfilter过滤器 |
| 缓存击穿 | 热点key失效 | 互斥更新,随机避退,差异失效时间 |
| 缓存雪崩 | 大面积失效,缓存挂了 | 快速失败熔断、主从模式、集群模式 |
Redis分布式锁
分布式锁
我们常说的锁有synchronized、Lock接口,那么已经有了这些,为什么还要有分布式锁呢?在单机版(同一个jvm许虚拟机内),我们可以使用synchronized、Lock接口;但是在分布式(多个不同jvm虚拟机内),单机的线程锁机制就不再起作用了,资源类在不同的服务器上,无法共享;这个时候就需要使用分布式锁来进行业务的处理了。
那么一个合格的分布式锁应该具备什么样的条件呢?
高可用高并发Redis分布式锁的条件
1、独占性。任何时刻有且只能有一个线程持有。
2、高可用。如果在Redis集群环境下,不能因为某个节点挂了而出现获取锁和释放锁失败的情况发生。高并发请求下,性能不下降。
3、防死锁。死锁的发生在业务上是很严重的问题,杜绝死锁,必须要有超时控制机制或者撤销操作,需要有一个兜底的跳出方案。
4、不乱抢。自己的锁只有自己释放,无法释放别人持有的锁。防止张冠李戴。
5、可重入性。同一个节点的同一个线程如果获取锁之后,那么它可以呀再次获取这个锁。
那么如何设计分布式锁才能让他具备这些条件又能够高可用呢?
Redis分布式锁设计
V2.0
单机版加锁配合nginx和jmeter压测后,不满足高并发分布式锁的性能要求,出现超卖。
//V2.0
private Lock lock=new ReentrantLock();
public String save() {
String retMessage="";
lock.lock();
try {
//先查询库存信息
String result = stringRedisTemplate.opsForValue().get("inventory001");
//判断库存是否足够,如果result等于空,那说明没了,为0
Integer inventoryNumber= result==null ? 0:Integer.parseInt(result);
//扣减库存,每次减1
if(inventoryNumber>0){
stringRedisTemplate.opsForValue().set("inventory001", String.valueOf(--inventoryNumber));
retMessage="成功卖出一个商品,库存剩余:"+inventoryNumber;
System.out.println(retMessage+"\t"+"服务端口号:"+port);
}else {
retMessage="商品已售空,o(╥﹏╥)o";
}
}finally {
lock.unlock();
}
return retMessage+"\t"+"服务端口号:"+port;
}V3.1
递归重试,容易导致Stack Overflowerror栈溢出,不推荐。另外高并发下唤醒不建议使用if,容易出现JUC中的虚假唤醒,推荐使用while。
//V3.1
public String save() {
String retMessage="";
String key="wxxRedisLock";
String uuidValue= IdUtil.simpleUUID()+":"+Thread.currentThread(). getId();
//setnx加锁
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, uuidValue);
//如果flag==false,没抢到的进程进行重试
if(!flag){
//暂停10毫秒进行递归重试
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
save();
}else {
//抢锁成功的进程进行正常的业务流程,扣减库存
try {
//先查询库存信息
String result = stringRedisTemplate.opsForValue().get("inventory001");
//判断库存是否足够,如果result等于空,那说明没了,为0
Integer inventoryNumber= result==null ? 0:Integer.parseInt(result);
//扣减库存,每次减1
if(inventoryNumber>0){
stringRedisTemplate.opsForValue().set("inventory001", String.valueOf(--inventoryNumber));
retMessage="成功卖出一个商品,库存剩余:"+inventoryNumber;
System.out.println(retMessage+"\t"+"服务端口号:"+port);
}else {
retMessage="商品已售空,o(╥﹏╥)o";
}
}finally {
//释放锁
stringRedisTemplate.delete(key);
}
}
return retMessage+"\t"+"服务端口号:"+port;
}
V3.2
存在的问题:部署了微服务的java程序机器挂了,代码层面根本没走到finally,没有办法保证解锁,没有过期时间的key一直存在,没有被删除,其他的进程无法获取到锁,需要设置过期时间来限制key。
//V3.2
public String save() {
String retMessage="";
String key="wxxRedisLock";
String uuidValue= IdUtil.simpleUUID()+":"+Thread.currentThread(). getId();
//setnx加锁
//不用递归,高并发下容易出错,我们用自旋替代递归方法重试调用,不使用if,使用while
while (!stringRedisTemplate.opsForValue().setIfAbsent(key, uuidValue)){
//暂停10毫秒进行递归重试
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
//抢锁成功的进程进行正常的业务流程,扣减库存
try {
//先查询库存信息
String result = stringRedisTemplate.opsForValue().get("inventory001");
//判断库存是否足够,如果result等于空,那说明没了,为0
Integer inventoryNumber= result==null ? 0:Integer.parseInt(result);
//扣减库存,每次减1
if(inventoryNumber>0){
stringRedisTemplate.opsForValue().set("inventory001", String.valueOf(--inventoryNumber));
retMessage="成功卖出一个商品,库存剩余:"+inventoryNumber;
System.out.println(retMessage+"\t"+"服务端口号:"+port);
}else {
retMessage="商品已售空,o(╥﹏╥)o";
}
}finally {
//释放锁
stringRedisTemplate.delete(key);
}
return retMessage+"\t"+"服务端口号:"+port;
}
V4.0
实际业务处理超出了过期时间,业务执行过程中锁已经过期,B进程持有锁进行操作,A操作完了删除锁,但是删的并不是自己的锁,删除了B的锁,应该自己的锁只能自己删除。
//4.0
public String save() {
String retMessage="";
String key="wxxRedisLock";
String uuidValue= IdUtil.simpleUUID()+":"+Thread.currentThread(). getId();
//setnx加锁
//不用递归,高并发下容易出错,我们用自旋替代递归方法重试调用,不使用if,使用while
//改进点:加锁和设置过期时间是一条命令,保证原子性
while (!stringRedisTemplate.opsForValue().setIfAbsent(key, uuidValue,30L,TimeUnit.SECONDS)){
//暂停10毫秒进行递归重试
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
//设置过期时间,但是这样也不行,因为创建锁和设置过期时间不是原子性命令。应该合二为一
stringRedisTemplate.expire(key,30L,TimeUnit.SECONDS);
//抢锁成功的进程进行正常的业务流程,扣减库存
try {
//先查询库存信息
String result = stringRedisTemplate.opsForValue().get("inventory001");
//判断库存是否足够,如果result等于空,那说明没了,为0
Integer inventoryNumber= result==null ? 0:Integer.parseInt(result);
//扣减库存,每次减1
if(inventoryNumber>0){
stringRedisTemplate.opsForValue().set("inventory001", String.valueOf(--inventoryNumber));
retMessage="成功卖出一个商品,库存剩余:"+inventoryNumber;
System.out.println(retMessage+"\t"+"服务端口号:"+port);
}else {
retMessage="商品已售空,o(╥﹏╥)o";
}
}finally {
//释放锁
stringRedisTemplate.delete(key);
}
return retMessage+"\t"+"服务端口号:"+port;
}
V5.0
存在的问题:最后删除锁的判断和删除不是原子性操作,可能出现隐患,需要使用lua脚本进行修改。
//V5.0
public String save() {
String retMessage="";
String key="wxxRedisLock";
String uuidValue= IdUtil.simpleUUID()+":"+Thread.currentThread(). getId();
//setnx加锁
//不用递归,高并发下容易出错,我们用自旋替代递归方法重试调用,不使用if,使用while
//改进点:加锁和设置过期时间是一条命令,保证原子性
while (!stringRedisTemplate.opsForValue().setIfAbsent(key, uuidValue,30L,TimeUnit.SECONDS)){
//暂停10毫秒进行重试
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
//设置过期时间,但是这样也不行,因为创建锁和设置过期时间不是原子性命令。应该合二为一
stringRedisTemplate.expire(key,30L,TimeUnit.SECONDS);
//抢锁成功的进程进行正常的业务流程,扣减库存
try {
//先查询库存信息
String result = stringRedisTemplate.opsForValue().get("inventory001");
//判断库存是否足够,如果result等于空,那说明没了,为0
Integer inventoryNumber= result==null ? 0:Integer.parseInt(result);
//扣减库存,每次减1
if(inventoryNumber>0){
stringRedisTemplate.opsForValue().set("inventory001", String.valueOf(--inventoryNumber));
retMessage="成功卖出一个商品,库存剩余:"+inventoryNumber;
System.out.println(retMessage+"\t"+"服务端口号:"+port);
}else {
retMessage="商品已售空,o(╥﹏╥)o";
}
}finally {
//释放锁
//改进点:自己的锁只能自己删除
if(uuidValue.equalsIgnoreCase(stringRedisTemplate.opsForValue().get(key))){
stringRedisTemplate.delete(key);
}
}
return retMessage+"\t"+"服务端口号:"+port;
}V6.0
使用lua脚本删除保证了原子性。
//V6.0
//改进点:使用lua脚本保证原子性
public String save() {
String retMessage="";
String key="wxxRedisLock";
String uuidValue= IdUtil.simpleUUID()+":"+Thread.currentThread(). getId();
//setnx加锁
//不用递归,高并发下容易出错,我们用自旋替代递归方法重试调用,不使用if,使用while
//改进点:加锁和设置过期时间是一条命令,保证原子性
while (!stringRedisTemplate.opsForValue().setIfAbsent(key, uuidValue,30L,TimeUnit.SECONDS)){
//暂停10毫秒进行重试
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
//设置过期时间,但是这样也不行,因为创建锁和设置过期时间不是原子性命令。应该合二为一
stringRedisTemplate.expire(key,30L,TimeUnit.SECONDS);
//抢锁成功的进程进行正常的业务流程,扣减库存
try {
//先查询库存信息
String result = stringRedisTemplate.opsForValue().get("inventory001");
//判断库存是否足够,如果result等于空,那说明没了,为0
Integer inventoryNumber= result==null ? 0:Integer.parseInt(result);
//扣减库存,每次减1
if(inventoryNumber>0){
stringRedisTemplate.opsForValue().set("inventory001", String.valueOf(--inventoryNumber));
retMessage="成功卖出一个商品,库存剩余:"+inventoryNumber;
System.out.println(retMessage+"\t"+"服务端口号:"+port);
}else {
retMessage="商品已售空,o(╥﹏╥)o";
}
}finally {
//释放锁的时候判断是不是自己的锁,使用lua脚本保证原子性
String luaScript=
"if redis.call('get',KEYS[1]) == ARGV[1] then" +
"return redis.call('del',KEYS[1]) " +
"else" +
"return 0 end";
//一定要记得使用这个带有指定返回值类型的
stringRedisTemplate.execute(new DefaultRedisScript<>(luaScript,Long.class), Arrays.asList(key),uuidValue);
}
return retMessage+"\t"+"服务端口号:"+port;
}
V6.0版本虽已经相较完善,但是没有解决可重入锁的问题,那么什么是可重入锁呢?
可重入锁
指的是一个线程中的多个流程可以获取同一把锁,持有这把同步锁可以再次进入。也就是说自己可以获取自己的内部锁。
可重入锁的种类
1、隐式锁(即synchronized关键字使用的锁)默认是可重入锁。
Synchronized的重入的实现机理:
每个锁对象拥有一个锁计数器和一个指向持有该锁的线程的指针。当执行monitorenter时,如果目标锁对象的计数器为零,那么说明它没有被其他线程所持有,Java虚拟机会将该锁对象的持有线程设置为当前线程,并且将其计数器加1。在目标锁对象的计数器不为零的情况下,如果锁对象的持有线程是当前线程,那么 Java 虚拟机可以将其计数器加1,否则需要等待,直至持有线程释放该锁。当执行monitorexit时,Java虚拟机则需将锁对象的计数器减1。计数器为零代表锁已被释放。
//同步块
public class ReEntryLockDemo
{
public static void main(String[] args)
{
final Object objectLockA = new Object();
new Thread(() -> {
synchronized (objectLockA)
{
System.out.println("-----外层调用");
synchronized (objectLockA)
{
System.out.println("-----中层调用");
synchronized (objectLockA)
{
System.out.println("-----内层调用");
}
}
}
},"a").start();
}
}//同步方法
//在一个Synchronized修饰的方法或代码块的内部调用本类的其他Synchronized修饰的方法或代码时,
//是永远可以得到锁的
public class ReEntryLockDemo
{
public synchronized void m1()
{
System.out.println("-----m1");
m2();
}
public synchronized void m2()
{
System.out.println("-----m2");
m3();
}
public synchronized void m3()
{
System.out.println("-----m3");
}
public static void main(String[] args)
{
ReEntryLockDemo reEntryLockDemo = new ReEntryLockDemo();
reEntryLockDemo.m1();
}
}2、显式锁(即lock)也有ReentrantLock这样的可重入锁。
/**
* 在一个Synchronized修饰的方法或代码块的内部调用本类的其他Synchronized修饰的方法或代码块时,是永远可以得到锁的
*/
public class ReEntryLockDemo
{
static Lock lock = new ReentrantLock();
public static void main(String[] args)
{
new Thread(() -> {
lock.lock();
try
{
System.out.println("----外层调用lock");
lock.lock();
try
{
System.out.println("----内层调用lock");
}finally {
lock.unlock(); // 正常情况,加锁几次就要解锁几次
}
}finally {
lock.unlock();
}
},"a").start();
new Thread(() -> {
lock.lock();
try
{
System.out.println("b thread----外层调用lock");
}finally {
lock.unlock();
}
},"b").start();
}
}V7.0
实现可重入性锁使用lua脚本(可重入锁)+设计模式(工厂设计模式)。
加锁逻辑:先判断redis分布式锁这个key是否存在,使用exists key,返回0说明不存在,使用hset新建当前线程属于自己的锁,返回1说明有,进一步判断是不是自己的。
解锁逻辑:判断有没有锁且是自己的锁,返回0,说明根本没有锁,不是0,说明有锁且是自己的锁。直接调用hincrby -1表示每次递减1,解锁一次。知道它变成0表示可以删除该锁的key, del key。
//加锁lua脚本
if redis.call('exists',KEYS[1]) == 0 or redis.call('hexists',KEYS[1],ARGV[1]) == 1 then
redis.call('hincrby',KEYS[1],ARGV[1],1)
redis.call('expire',KEYS[1],ARGV[2])
return 1
else
return 0
end
//解锁lua脚本
if redis.call('hexists',KEYS[1],ARGV[1]) == 0 then
return nil
elseif redis.call('hincrby',KEYS[1],ARGV[1],-1) == 0 then
return redis.call('del',KEYS[1])
else
return 0DistributedLockFactory工厂模式:
@Component
public class DistributedLockFactory
{
private StringRedisTemplate stringRedisTemplate;
private String lockName;
private String uuidValue;
public DistributedLockFactory()
{
this.uuidValue = IdUtil.simpleUUID();//UUID
}
public Lock getDistributedLock(String lockType){
if(lockType==null) return null;
if(lockType.equalsIgnoreCase("redis")){
lockName = "wxxRedisLock";
// return new RedisDistributedLock(stringRedisTemplate,lockName);
return new RedisDistributedLock(stringRedisTemplate,lockName,uuidValue);
}else if(lockType.equalsIgnoreCase("ZOOKEEPER")){
//TODO zookeeper版本的分布式锁实现
//return new ZookeeperDistributedLock();
} else if(lockType.equalsIgnoreCase("MYSQL")){
//TODO mysql版本的分布式锁实现
return null;
}
return null;
}
}
自研的redis分布式锁,实现了lock接口:
public class RedisDistributedLock implements Lock
{
private StringRedisTemplate stringRedisTemplate;
private String lockName;//KEYS[1]
private String uuidValue;//ARGV[1]
private long expire;//ARGV[2]
public RedisDistributedLock(StringRedisTemplate stringRedisTemplate, String lockName,String uuidValue)
{
this.stringRedisTemplate = stringRedisTemplate;
this.lockName = lockName;
this.uuidValue = uuidValue+":"+Thread.currentThread().getId();
this.expire = 30L;
}
//原先的构造方法每次都new一个this.uuidValue=IdUtil.simpleUUID()+":"+Thread.currentThread().getId();
//会造成在可重入性时,线程id是同一个,但是uuid不是同一个,所以不能每次都new一个,而是使用的时候传
// public RedisDistributedLock(StringRedisTemplate stringRedisTemplate, String lockName) {
// this.stringRedisTemplate = stringRedisTemplate;
// this.lockName = lockName;
// this.uuidValue=IdUtil.simpleUUID()+":"+Thread.currentThread().getId();
// this.expire=50L;
// }
@Override
public void lock() {
tryLock();
}
@Override
public boolean tryLock() {
try {tryLock(-1L,TimeUnit.SECONDS);} catch (InterruptedException e) {throw new RuntimeException(e);}
return false;
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
if(time == -1L){
String script="" +
"if redis.call('exists',KEYS[1]) == 0 or redis.call('hexists',KEYS[1],ARGV[1]) == 1 then " +
"redis.call('hincrby',KEYS[1],ARGV[1],1) " +
"redis.call('expire',KEYS[1],ARGV[2]) " +
"return 1 " +
"else " +
"return 0 " +
"end";
System.out.println("lockName:"+lockName+",vlaue:"+uuidValue);
while (!stringRedisTemplate.execute(new DefaultRedisScript<>(script,Boolean.class),Arrays.asList(lockName),uuidValue,String.valueOf(expire))){
try {
TimeUnit.MILLISECONDS.sleep(60);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
return true;
}
return false;
}
@Override
public void unlock() {
String script="" +
"if redis.call('hexists',KEYS[1],ARGV[1]) == 0 then " +
"return nil " +
"elseif redis.call('hincrby',KEYS[1],ARGV[1],-1) == 0 then " +
"return redis.call('del',KEYS[1]) " +
"else " +
"return 0";
//nil==false,1==ture,0==false
Long falg = stringRedisTemplate.execute(new DefaultRedisScript<>(script, Long.class), Arrays.asList(lockName), uuidValue, String.valueOf(expire));
if(null==falg){
throw new RuntimeException("此锁不存在!!!");
}
}
@Override
public void lockInterruptibly() throws InterruptedException {
}
@Override
public Condition newCondition() {
return null;
}
}
整合实现可重入分布式锁:
//V7.0 可重入锁+设计模式(工厂设计模式)
@Autowired
private DistributedLockFactory distributedLockFactory;
public String save()
{
String retMessage = "";
Lock redisLock = distributedLockFactory.getDistributedLock("redis");
redisLock.lock();
try
{
//1 查询库存信息
String result = stringRedisTemplate.opsForValue().get("inventory001");
//2 判断库存是否足够
Integer inventoryNumber = result == null ? 0 : Integer.parseInt(result);
//3 扣减库存
if(inventoryNumber > 0) {
stringRedisTemplate.opsForValue().set("inventory001",String.valueOf(--inventoryNumber));
retMessage="成功卖出一个商品,库存剩余:"+inventoryNumber;
System.out.println(retMessage);
}else{
retMessage = "商品已售空,o(╥﹏╥)o";
}
}catch (Exception e){
e.printStackTrace();
}finally {
redisLock.unlock();
}
return retMessage+"\t"+"服务端口号:"+port;
}锁续期
前面我们为了避免死锁,给锁加了过期时间,那么如果在业务过程中,本应该在10s就执行完的业务流程,可能会因为一些不定因素他并没有在10s完成,业务还未完成,锁已经过期。为了确保redis锁的过期时间大于业务处理流程需要的时间,我们需要时间锁的续期。
可以使用lua脚本实现自动续期功能,后台自定义一个扫描程序 ,如果规定时间内(比如锁的过期时间已经1/2)没有完成业务逻辑,调用自动续期的脚本。
改造RedisDistributedLock增加锁续期:
public class RedisDistributedLock implements Lock
{
private StringRedisTemplate stringRedisTemplate;
private String lockName;//KEYS[1]
private String uuidValue;//ARGV[1]
private long expire;//ARGV[2]
public RedisDistributedLock(StringRedisTemplate stringRedisTemplate, String lockName,String uuidValue)
{
this.stringRedisTemplate = stringRedisTemplate;
this.lockName = lockName;
this.uuidValue = uuidValue+":"+Thread.currentThread().getId();
this.expire = 30L;
}
//原先的构造方法每次都new一个this.uuidValue=IdUtil.simpleUUID()+":"+Thread.currentThread().getId();
//会造成在可重入性时,线程id是同一个,但是uuid不是同一个,所以不能每次都new一个,而是使用的时候传
// public RedisDistributedLock(StringRedisTemplate stringRedisTemplate, String lockName) {
// this.stringRedisTemplate = stringRedisTemplate;
// this.lockName = lockName;
// this.uuidValue=IdUtil.simpleUUID()+":"+Thread.currentThread().getId();
// this.expire=50L;
// }
@Override
public void lock() {
tryLock();
}
@Override
public boolean tryLock() {
try {tryLock(-1L,TimeUnit.SECONDS);} catch (InterruptedException e) {throw new RuntimeException(e);}
return false;
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
if(time == -1L){
String script="" +
"if redis.call('exists',KEYS[1]) == 0 or redis.call('hexists',KEYS[1],ARGV[1]) == 1 then " +
"redis.call('hincrby',KEYS[1],ARGV[1],1) " +
"redis.call('expire',KEYS[1],ARGV[2]) " +
"return 1 " +
"else " +
"return 0 " +
"end";
System.out.println("lockName:"+lockName+",vlaue:"+uuidValue);
while (!stringRedisTemplate.execute(new DefaultRedisScript<>(script,Boolean.class),Arrays.asList(lockName),uuidValue,String.valueOf(expire))){
try {
TimeUnit.MILLISECONDS.sleep(60);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
//新建一个后台扫描程序,来监视key当前的ttl(过期时间),是否到我们规定的1/2 or 1/3来实现续期
renewExpire();
return true;
}
return false;
}
/**
* 锁自动续期
*/
private void renewExpire() {
String script="" +
"if redis.call('HEXISTS',KEYS[1],ARGV[1]) == 1 then " +
"return redis.call('expire',KEYS[1],ARGV[2]) " +
"else " +
"return 0 " +
"end";
new Timer().schedule(new TimerTask() {
@Override
public void run() {
if (stringRedisTemplate.execute(new DefaultRedisScript<>(script, Boolean.class), Arrays.asList(lockName),uuidValue,String.valueOf(expire))) {
renewExpire();//循环调用,不断的判断是否需要续期直至锁释放删除
}
}
},(this.expire * 1000)/3);
}
@Override
public void unlock() {
String script="" +
"if redis.call('hexists',KEYS[1],ARGV[1]) == 0 then " +
"return nil " +
"elseif redis.call('hincrby',KEYS[1],ARGV[1],-1) == 0 then " +
"return redis.call('del',KEYS[1]) " +
"else " +
"return 0";
//nil==false,1==ture,0==false
Long falg = stringRedisTemplate.execute(new DefaultRedisScript<>(script, Long.class), Arrays.asList(lockName), uuidValue, String.valueOf(expire));
if(null==falg){
throw new RuntimeException("此锁不存在!!!");
}
}
@Override
public void lockInterruptibly() throws InterruptedException {
}
@Override
public Condition newCondition() {
return null;
}
}
至此一个完善的Redis分布式锁已经设计完成。
RedLock红锁
前面设计的分布式锁不是特别高并发场景是足够使用的,单机redis业务也没有问题。但是如果负责加锁解锁的redis挂了,也就是架构中的单点故障,我们首先可能会想到使用主从,但是这是不可行的,因为Redis的复制是异步的。
比如:线程 1 首先获取锁成功,将键值对写入 redis 的 master 节点,在 redis 将该键值对同步到 slave 节点之前,master 发生了故障;redis 触发故障转移,其中一个 slave 升级为新的 master,此时新上位的master并不包含线程1写入的键值对,因此线程 2 尝试获取锁也可以成功拿到锁,此时相当于有两个线程获取到了锁,可能会导致各种预期之外的情况发生,例如最常见的脏数据。
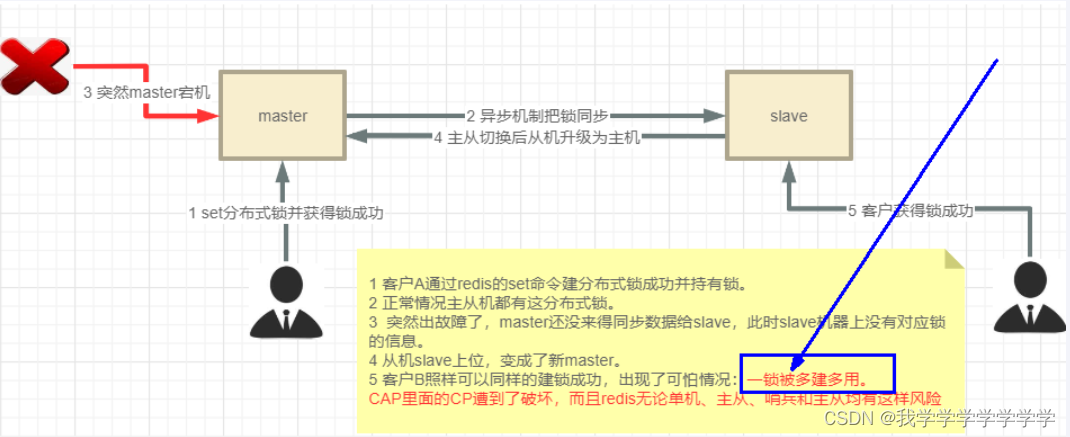
Redis之父提出了RedLock算法解决这个问题,用来实现基于多个实例的分布式锁。
锁变量由多个实例维护,即使有实例发生了故障,锁变量仍然是存在的,客户端还是可以完成锁操作。
Redlock算法
Redlock算法是实现高可靠分布式锁的一种有效解决方案,可以在实际开发中使用。在算法的分布式版本中,我们假设我们有N个Redis主节点。这些节点是完全独立的,他类似于集群,但并不是集群,因为这些节点都是主节点,相互独立,没有salve。所以就不需要使用复制或者Italy隐式协调系统,因此我们需要再不同的计算机或者虚拟机上运行5个Redis master ,以确保它们以独立的方式存在。
设计理念
该方案也是基于(set 加锁、Lua 脚本解锁)进行改良的,所以redis之父antirez 只描述了差异的地方,大致方案如下。
假设我们有N个Redis主节点,例如 N = 5这些节点是完全独立的,我们不使用复制或任何其他隐式协调系统,
为了取到锁客户端执行以下操作:
|
1
|
获取当前时间,以毫秒为单位;
|
|
2
|
依次尝试从5个实例,使用相同的 key 和随机值(例如 UUID)获取锁。当向Redis 请求获取锁时,客户端应该设置一个超时时间,这个超时时间应该小于锁的失效时间。例如你的锁自动失效时间为 10 秒,则超时时间应该在 5-50 毫秒之间。这样可以防止客户端在试图与一个宕机的 Redis 节点对话时长时间处于阻塞状态。如果一个实例不可用,客户端应该尽快尝试去另外一个 Redis 实例请求获取锁;
|
|
3
|
客户端通过当前时间减去步骤 1 记录的时间来计算获取锁使用的时间。当且仅当从大多数(N/2+1,这里是 3 个节点)的 Redis 节点都取到锁,并且获取锁使用的时间小于锁失效时间时,锁才算获取成功;
|
|
4
|
如果取到了锁,其真正有效时间等于初始有效时间减去获取锁所使用的时间(步骤 3 计算的结果)。
|
|
5
|
如果由于某些原因未能获得锁(无法在至少 N/2 + 1 个 Redis 实例获取锁、或获取锁的时间超过了有效时间),客户端应该在所有的 Redis 实例上进行解锁(即便某些Redis实例根本就没有加锁成功,防止某些节点获取到锁但是客户端没有得到响应而导致接下来的一段时间不能被重新获取锁)。
|
该方案为了解决数据不一致的问题,直接舍弃了异步复制只使用 master 节点,同时由于舍弃了 slave,为了保证可用性,引入了 N 个节点,官方建议是 5。
客户端只有在满足下面的这两个条件时,才能认为是加锁成功。
条件1:客户端从超过半数(大于等于N/2+1)的Redis实例上成功获取到了锁;
条件2:客户端获取锁的总耗时没有超过锁的有效时间。
为什么是master节点数是奇数? N = 2X + 1 (N是最终部署机器数,X是容错机器数)
1、先知道什么是容错
失败了多少个机器实例后我还是可以容忍的,所谓的容忍就是数据一致性还是可以Ok的,CP数据一致性还是可以满足
RedLock落地实现Redisson
Redisson是Java的Redis客户端之一,提供了一些api方便操作Redis。
引入依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.4</version>
</dependency>配置类RedisConfig,添加redisson配置:
@Configuration
public class RedisConfig
{
@Bean
public RedisTemplate<String, Object> redisTemplate(LettuceConnectionFactory lettuceConnectionFactory)
{
RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(lettuceConnectionFactory);
//设置key序列化方式string
redisTemplate.setKeySerializer(new StringRedisSerializer());
//设置value的序列化方式json
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
//redisson配置
@Bean
public Redisson redisson()
{
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379").setDatabase(0);
return (Redisson) Redisson.create(config);
}
}
InventoryController:
@RestController
@Api(tags = "redis分布式锁测试")
public class InventoryController
{
@Autowired
private InventoryService inventoryService;
@ApiOperation("扣减库存saleByRedisson,一次卖一个")
@GetMapping(value = "/inventory/saleByRedisson")
public String saleByRedisson()
{
return inventoryService.saveByRedisson();
}
}InventoryService:
//引入redisson对应的官网推荐redlock算法实现类
@Autowired
private Redisson redisson;
public String saveByRedisson()
{
String retMessage = "";
RLock redissonLock = redisson.getLock("wxxRedisLock");
redissonLock.lock();
try
{
//1 查询库存信息
String result = stringRedisTemplate.opsForValue().get("inventory001");
//2 判断库存是否足够
Integer inventoryNumber = result == null ? 0 : Integer.parseInt(result);
//3 扣减库存
if(inventoryNumber > 0) {
stringRedisTemplate.opsForValue().set("inventory001",String.valueOf(--inventoryNumber));
retMessage="成功卖出一个商品,库存剩余:"+inventoryNumber;
System.out.println(retMessage);
}else{
retMessage = "商品已售空,o(╥﹏╥)o";
}
}catch (Exception e){
e.printStackTrace();
}finally {
//只能删除自己的,判断他是否持有锁,且持有锁是否是当前线程id
if(redissonLock.isLocked() && redissonLock.isHeldByCurrentThread()){
redissonLock.unlock();
}
}
return retMessage+"\t"+"服务端口号:"+port;
}
Redisson看门狗
redis分布式锁过期了,但是业务逻辑还没有执行完怎么办呢?如果负责存储这个分布式锁的redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁就会出现锁死的状态。
核心:额外起一个线程,定期检查线程是否还持有锁,如果有则延长过期时间。
为了避免这种情况的发生。redisson内部提供了一个监控锁的看门狗(使用“看门狗”定期检查(每1/3的锁时间检查1次),如果线程还持有锁,则刷新过期时间),他的作用是在redisson实例被关闭前,不断的延长锁得有效期。默认情况下,看门狗的检查锁的超时时间是30秒钟,也可以通过修改config.lockWatchdogTimeout来另行指定。另外redisson还通过加锁的方法提供了leaseTime的参数来指定加锁的时间,超过这个时间后锁就会自动解开。















 4240
4240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









