







 本文探讨了大语言模型如ChatGPT、LLaMa的部署挑战,包括高计算量、大存储需求、网络带宽和成本问题。提出了云计算预算评估、模型压缩、硬件选择和推理产品选择等策略来优化基础设施成本。模型压缩技术如量化、剪枝和蒸馏可降低模型大小,硬件优化和无服务器推理则有助于成本效益的可扩展性。建议在部署时根据业务需求和预算进行综合考量和优化。
本文探讨了大语言模型如ChatGPT、LLaMa的部署挑战,包括高计算量、大存储需求、网络带宽和成本问题。提出了云计算预算评估、模型压缩、硬件选择和推理产品选择等策略来优化基础设施成本。模型压缩技术如量化、剪枝和蒸馏可降低模型大小,硬件优化和无服务器推理则有助于成本效益的可扩展性。建议在部署时根据业务需求和预算进行综合考量和优化。
1. 引言
ChatGPT、LLaMa、Bard 等大语言模型(LLMs)取得了非常巨大突破,迅速在公众领域流行起来。LLMs所展现的强大文本生产能力让用户惊叹不已,属于划时代的产品。这些模型拥有数十亿甚至数千亿个参数,因而这些模型通常的部署和维护成本都惊人的高昂。这类大模型的的训练和推理都需要大量的计算资源和内存资源,企业需要投入海量的基础设施成本(不管是云服务还是自建机房都非常贵),来保证大模型能够稳定提供服务。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EBoNgj1Y-1690958463827)(https://s.zhangguiyi.cn/vent/optimizing-infrastructure-costs-for-deploying-large-nlp-models-1.png)]
那么有没有办法花小钱办大事呢?
当然有。
本文旨在提供一些策略、提示和技巧,您可以在部署基础架构时应用这些策略、提示和技巧来优化基础架构。我们将重点探讨这些内容:
-
- 大模型部署与应用时将会面临的基础架构挑战
-
- 如何降低大模型部署与应用的成本
-
- 其他的一些有用的策略
2. 大模型部署与应用的挑战
LLMs遵循规模效应,也就是说参数越大,效果越好。因此它们一般需要海量GPU计算资源才能获得最佳性能。通常会面临以下的挑战:
2.1 高计算量
部署 LLM 是一个充满挑战的任务,因为它们需要大量计算资源来执行推理,尤其是模型用于实时应用程序(例如聊天机器人或虚拟助手)为甚。
以 ChatGPT 为例,大多数情况下它能够在几秒钟内处理和响应用户查询。尤其是繁忙时段瞬间涌入海量用户会使得推理时间会变长。还有其他因素可能会延迟推理,例如问题的复杂性、生成响应所需的信息量等等。总而言之,大模型要提供实时服务,它必须能够实现高吞吐量和低延迟。
2.2 大存储量
由于模型参数规模从数百万到数千亿,LLM 的存储也是一个充满挑战的问题。由于大模型规模太大,所以无法直接将整个模型存储在单个存储设备。
例如,OpenAI 的 GPT-3 模型有 1750亿 个参数,仅其权重参数存储就需要超过 300GB 的存储空间。
此外,它还需要至少具有 16GB 显存的 GPU 才能高效运行(意味着起码是T4级别以上的N卡)。
因此,在单个设备上存储和运行如此大的模型对于许多用户场景来说是不切实际的。整体来说,
LLM 的存储容量存在三个主要问题:
- 内存限制 : LLMs需要大量内存,因为它们要处理大量信息。部署此类模型的一种方法是使用分布式系统,模型分布在多个服务器节点上。这种系统允许将推理任务切分分配到多台服务器上,实现负载均衡和推理加速。这类系统通常架构都比较复杂,需要大量的专业知识来设置和维护这些分布式机器。模型越大,需要的服务器就越多,这也增加了部署成本。还有一种复杂的场景就是,如何将大模型部署在手机等内存较小的设备上。
- 模型规模 : 如果输入查询又长又复杂,即便运行在大内存显卡上的模型推理过程中也很容易耗尽内存。即使对于 LLM 的基本推理,也需要多个加速器或多节点计算集群(例如多个 Kubernetes Pod)。
- 可扩展性 : 大模型通常使用模型并行化(MP)进行扩展,这涉及将模型分成更小的部分并将其分布在多台机器上。每台机器处理模型的不同部分,并将结果组合起来产生最终输出。该技术有助于大模型训练,但也需要仔细考虑机器之间的通信开销。
2.3 网络带宽
如上所述,LLM 必须使用 MP 进行扩展。但我们发现的问题是,模型并行化 在单节点集群中是有较好效果,但在多节点集群中,由于网络通讯开销,导致推理效率不高。
2.4 成本与能耗
如上文所述,部署和使用 LLM 的成本可能很高,包括硬件和基础设施的成本,尤其是在推理过程中使用 GPU 或 TPU 等资源来实现低延迟和高吞吐量时。对小公司和个人来说,这是一个非常大的挑战。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qLcS6fkh-1690958463827)(https://s.zhangguiyi.cn/vent/optimizing-infrastructure-costs-for-deploying-large-nlp-models-2.png)]
LLMs的费用估算以及碳足迹| 来源
根据 NVIDIA的说法,80-90% 的机器学习工作负载是推理带来的。同样,根据 AWS 的数据,推理占云中机器学习需求的 90%。
在22年12月份,chatGPT 的运行成本约为每天 100,000 美元或每月 300 万美元。随着ChatGPT的大获成功,GPT-4的推出等,估计现在(23年7月)估计要比当时(22年12月)高出一个数量级了
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Csa9NwHC-1690958463827)(https://s.zhangguiyi.cn/vent/optimizing-infrastructure-costs-for-deploying-large-nlp-models-3.png)]
关于ChatGPT成本的推文 | 来源
3. 优化大模型基础设施成本的策略
在本节中,我们将探讨并讨论前一节中讨论的挑战的可能解决方案和技术。
首先以AWS作为云供应商,来实现大模型推理的工作流作为例子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iLSHz6KO-1690958463827)(https://s.zhangguiyi.cn/vent/optimizing-infrastructure-costs-for-deploying-large-nlp-models-4.png)]
AWS上的大模型推理的工作流 | 来源
您可以按照以下的步骤尽可能高效地部署大模型。
3.1 云计算预算评估与规划
使用云计算服务可以提供动态、按需使用包括CPU,GPU,TPU在内的各种强大的计算资源。云计算服务灵活且可扩展性强,但是在使用云服务的时候,首先你需要为自己的项目制定一个项目预算,这样能够让你的基础设施投入更加合理可控。
云服务提供商如AWS、Azure和google cloud提供了一系列部署LLM的产品,包括虚拟机、容器和无服务器计算。但是尽管如此,建议还是需要根据自己业务情况进行研究和计算,选择更加合理的云服务解决方案。例如,你必须核实以下三个方面信息:
- 模型尺寸
- 关于要使用的硬件的详情
- 合理的推理产品方案
根据上述三个方面的信息,可以计算出你需要多少加速计算能力,从而规划并执行适合你自身业务的大模型部署。
3.1.1 计算模型大小
您可以根据以下表格,折算自己模型大概需要多少多少FLOPs算力,从而确定要在云平台上找到相相应的GPU。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ktkuTEmM-1690958463828)(https://s.zhangguiyi.cn/vent/optimizing-infrastructure-costs-for-deploying-large-nlp-models-5-1.png)]
预估计算FLOPs
另外这个工具也可以帮你计算模型在训练和推理过程中所需的FLOPs。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AFuk8QTF-1690958463828)(https://s.zhangguiyi.cn/vent/optimizing-infrastructure-costs-for-deploying-large-nlp-models-6.png)]
3.1.2 选择合适的硬件
当你计算出所需的FLOPs,就可以继续选择GPU。确保你了解GPU所提供的功能。例如,查看下面的图片以了解情况。可以参考以下A100的GPU规格,选择符合预算的显卡。最新的H100芯片可以访问这个链接
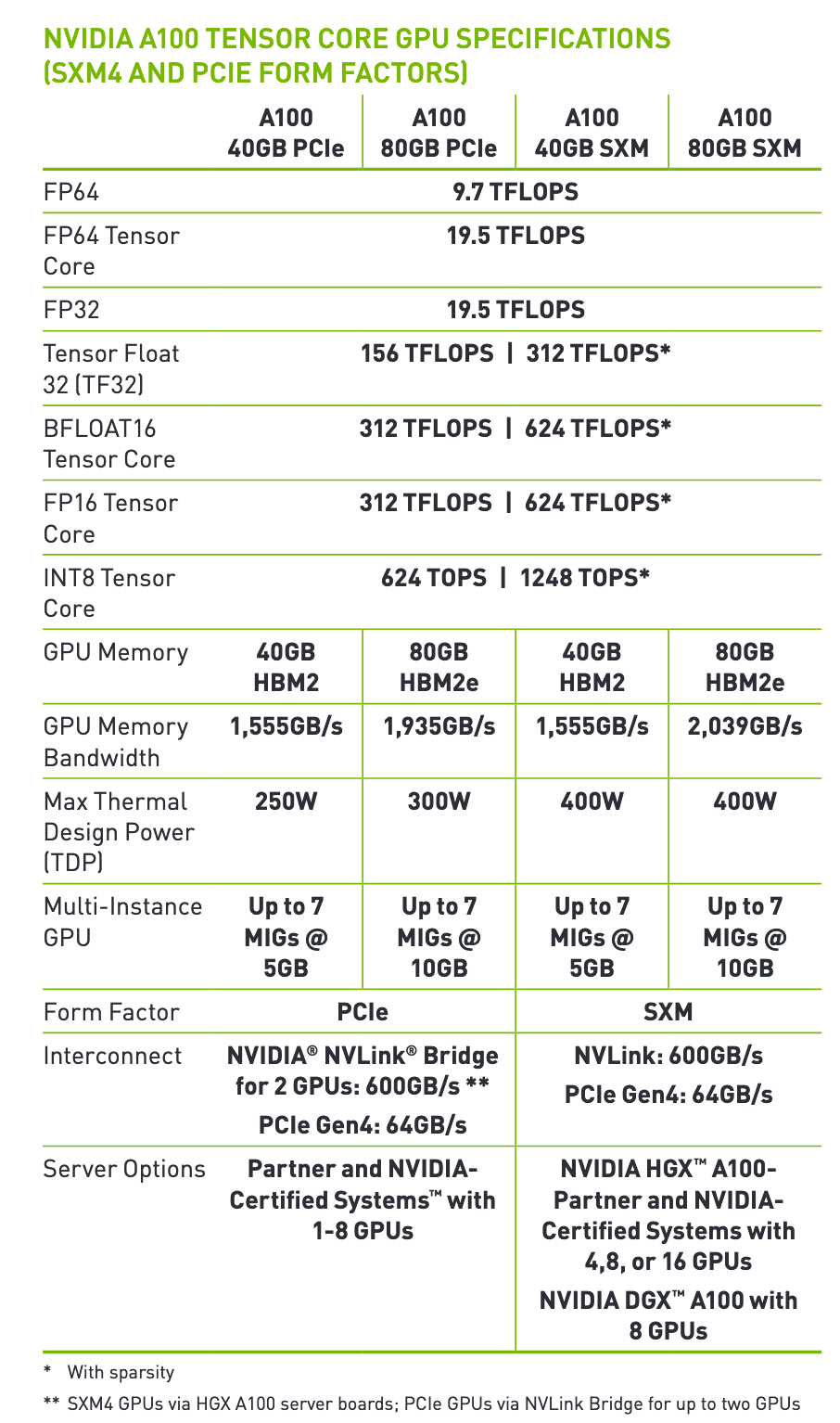
3.1.3 选择正确的推理产品
Amazon SageMaker是一个机器学习云服
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









