







1. 生成式AI概览:什么是大模型,大模型应用场景(文生文,多模态)
-
生成式AI(Generative AI)是指通过机器学习模型生成新的数据或内容的人工智能技术。生成式AI可以生成文本、图像、音频、视频等多种形式的数据,广泛应用于内容创作、数据增强、自动化生成等领域。
-
大模型(Large Model)是指具有大量参数和复杂结构的深度学习模型。大模型通常基于深度神经网络,特别是Transformer架构,通过在大规模数据集上进行训练,能够捕捉复杂的模式和关系。大模型的代表包括 GPT-3、BERT、T5、DALL-E 等。
-
超大参数自然语言模型+对话交互=生成式AI
-
大模型参数指的是机器学习模型中的参数,这些参数决定了模型的复杂度和性能。参数越多,模型越复杂,能够拟合的数据也就越多,但同时也需要更多的训练数据和计算资源。
-
主流参数单位表示
a. M:百万,1M(million)
b. B:十亿,1B(billion)
c. T:万亿,1T(trillion)
d. 例子
i. GPT-3模型参数量为1750亿,即1.75T参数。
ii. 百度文心大模型ERNIE 3.0的参数量为2600亿,即2.6T参数。
-
参数量与模型性能
a. 一般来说,参数量越多,模型的性能越好,但同时也需要更多的训练数据和计算资源。因此,在实际应用中,需要根据具体场景和需求来选择合适的模型参数量。
-
参数量的未来趋势
a. 随着人工智能技术的不断发展,大模型参数量将会继续增长。未来,参数量达到百亿、千亿甚至万亿级别的大模型将会越来越普遍。
-
大语言模型代码文件解析
a. .gitignore :是一个纯文本文件,包含了项目中所有指定的文件和文件夹的列表,这些文件和文件夹是Git应该忽略和不追踪的
b. MODEL_LICENSE:模型商用许可文件
c. REDAME.md:略
d. config.json:模型配置文件,包含了模型的各种参数设置,例如层数、隐藏层大小、注意力头数及Transformers API的调用关系等,用于加载、配置和使用预训练模型。
e. configuration_chatglm.py:是该config.json文件的类表现形式,模型配置的Python类代码文件,定义了用于配置模型的 ChatGLMConfig 类。
f. modeling_chatglm.py:源码文件,ChatGLM对话模型的所有源码细节都在该文件中,定义了模型的结构和前向传播过程,例如 ChatGLMForConditionalGeneration 类。
g. model-XXXXX-of-XXXXX.safetensors:安全张量文件,保存了模型的权重信息。这个文件通常是 TensorFlow 模型的权重文件。
h. model.safetensors.index.json:模型权重索引文件,提供了 safetensors 文件的索引信息。
i. pytorch_model-XXXXX-of-XXXXX.bin:PyTorch模型权重文件,保存了模型的权重信息。这个文件通常是 PyTorch模型的权重文件。
j. pytorch_model.bin.index.json:PyTorch模型权重索引文件,提供了 bin 文件的索引信息。
k. quantization.py:量化代码文件,包含了模型量化的相关代码。
l. special_tokens_map.json:特殊标记映射文件,用于指定特殊标记(如起始标记、终止标记等)的映射关系。
m. tokenization_chatglm.py:分词器的Python类代码文件,用于chatglm3-6b模型的分词器,它是加载和使用模型的必要部分,定义了用于分词的 ChatGLMTokenizer 类。
n. tokenizer.model:包含了训练好的分词模型,保存了分词器的模型信息,用于将输入文本转换为标记序列;通常是二进制文件,使用pickle或其他序列化工具进行存储和读取。
o. tokenizer_config.json:含了分词模型的配置信息,用于指定分词模型的超参数和其他相关信息,例如分词器的类型、词汇表大小、最大序列长度、特殊标记等
p. LFS:Large File Storage,大文件存储
-
.safetensors格式文件是huggingface设计的一种新格式,大致就是以更加紧凑、跨框架的方式存储Dict[str, Tensor],主要存储的内容为tensor的名字(字符串)及内容(权重)。
-
鉴于大型语言模型(LLM)的解释性较差问题,我们需要开发相应复杂的评估方法,和优化手段。
-
如何训练出一个大语言模型?
a. 从互联网上爬取10TB text文本
b. 用6000张GPU训练12天,花费200万美元,总算力是1*1024次方 浮点运算每秒
c. 你最终得到一个140GB的zip压缩文件
d. 这个就是Llama 2 70B模型的训练过程
-
开源模型数据集数据来源于网页、社交网络对话内容、书籍、新闻、科学数据、代码
-
大模型的参数量越大,应用范围越广
a. 8B问答、语言理解
b. 10B以上有涌现能力
c. 62B问答、语言理解、代码补全、文本总结、翻译、感知解释
d. 540B问答、语言理解、代码补全、文本总结、翻译、感知解释、通用知识理解、阅读总结、图案识别、智能对话、笑话解读、常识理解
-
文生文是指通过大模型生成文本内容的应用场景。大模型在文生文任务中表现出色,能够生成连贯、自然的文本内容。
-
多模态生成是指通过大模型生成多种形式的数据或内容的应用场景。大模型在多模态生成任务中表现出色,能够生成图像、音频、视频等多种形式的内容
-
语言模型——大模型的前身
-
Transformer架构划时代地提升了NLP效果——传统NLP的努力
a. Transformer(2017,谷歌)是一种用于自然语言处理的神经网络模型,使用了一种“注意力机制”的技术,能够更好地捕捉序列中的关键信息,提高模型性能。是当前对序列文本建模的SOTA基础模型架构,可以有效考虑上下文关联。
b. 注意力(attention)机制:让模型在处理序列数据时,更加关注与当前任务相关的部分,而忽略与任务无关的部分。计算输入序列中每个位置与当前位置的相关性,然后根据相关性对输入序列进行加权求和,得到当前位置的表示。
-
GPT 使用 Transformer 的 Decoder 结构,并对 Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention。
-
不同transformer架构模型演进——主流是decoder-only
a. 绝大部分主流模型用decoder-only架构
b. 清华chatGLM用了encoder-decoder架构(成本高、吞吐低,但准确率高,适合toB、toG)
c. Encoder-only架构不适合大模型场景
-
大部分都是微调模型:基于已有大模型做微调,是一种非常有效的训练技术
-
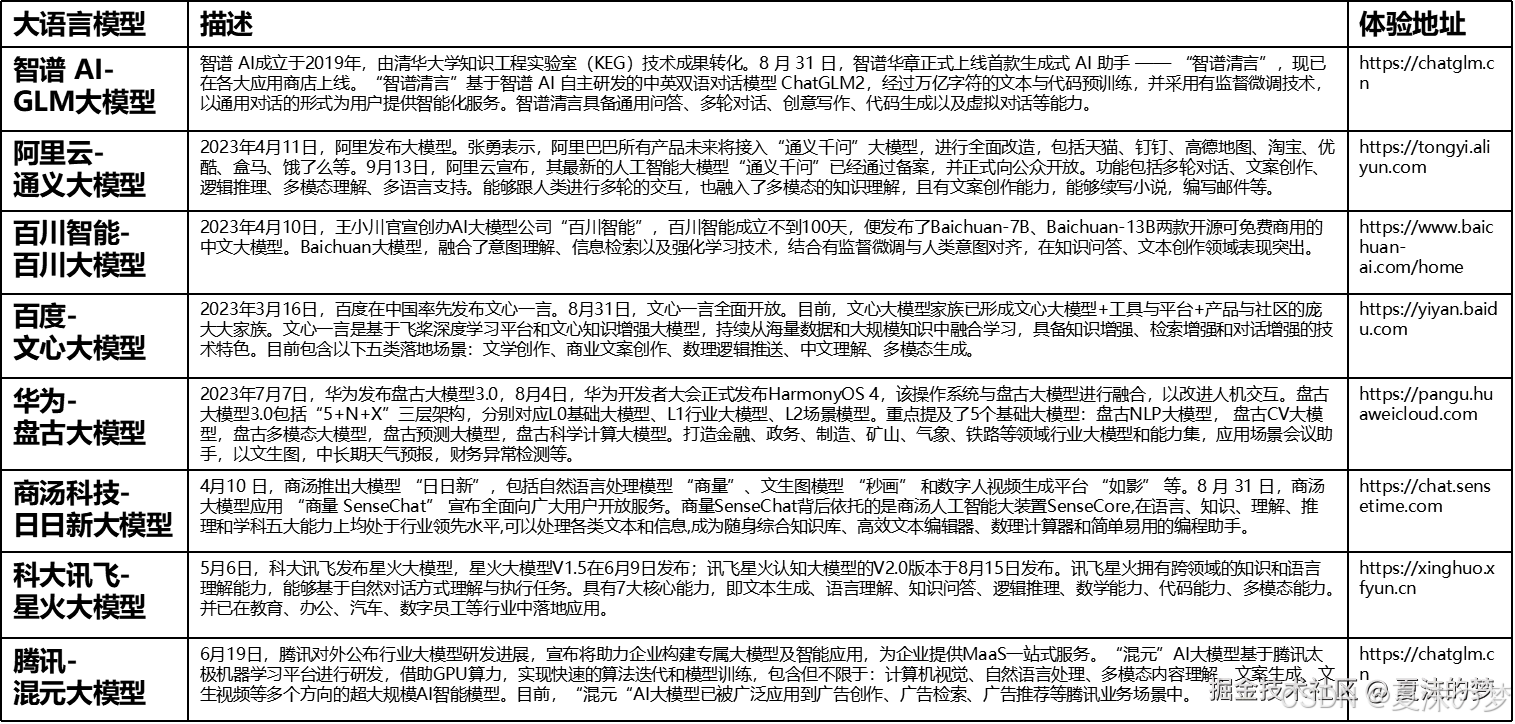
国内知名语言模型
-
基础大模型测评方法-第三方测评机构superclue测评中文大模型方法
-
多模态模型-文生图-stable diffusion模型
-
多模态模型-文生视频-sora
-
Sora文生视频模型工作原理:SORA 模型训练流程
a. Step1:使用 DALLE 3(CLIP ) 把文本和图像对 <text,image> 联系起来;
b. Step2:视频数据切分为 Patches 通过 VAE 编码器压缩成低维空间表示;
c. Step3:基于 Diffusion Transformer 从图像语义生成,完成从文本语义到图像语义进行映射;
d. Step4:DiT 生成的低维空间表示,通过 VAE 解码器恢复成像素级的视频数据;
-
多模态模型-图像、视频理解-GPTo
-
多模态模型-图像、视频理解-GPT-4o
-
优点:
- 强大的生成能力:大模型能够生成高质量的文本、图像、音频、视频等内容,表现出色。
- 自动特征提取:大模型能够自动提取和表示数据的特征,适应不同的应用场景。
- 广泛应用:大模型在文本生成、多模态生成等领域取得了显著的成功,广泛应用于内容创作、数据增强、自动化生成等。
-
缺点:
- 计算资源需求高:训练和推理大模型需要大量的计算资源和时间,通常依赖于高性能计算设备和分布式计算技术。
- 数据依赖:大模型的性能依赖于大规模数据集的质量和数量,数据获取和处理成本高。
- 解释性差:大模型的内部工作机制较为复杂,难以解释其生成过程和决策依据。
-
生成式AI通过大模型生成新的数据或内容,广泛应用于文本生成(文生文)和多模态生成等领域。大模型具有强大的生成能力和自动特征提取能力,但也面临计算资源需求高、数据依赖和解释性差等挑战。通过不断的研究和优化,生成式AI在各个领域取得了显著的成功,并将继续推动人工智能的发展。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











