






Lomdba
简介:
Lambda 架构(Lambda Architecture)是由 Twitter 工程师南森·马茨(Nathan Marz)提出的大数据处理架构。这一架构的提出基于马茨在 BackType 和 Twitter 上的分布式数据处理系统的经验。Lambda 架构使开发人员能够构建大规模分布式数据处理系统。它具有很好的灵活性和可扩展性,也对硬件故障和人为失误有很好的容错性。
Lambda 架构总共由三层系统组成:
批处理层(Batch Layer),速度处理层(Speed Layer),以及用于响应查询的服务层(Serving Layer)。
批处理层
批处理层存储管理主数据集(不可变的数据集)和预先批处理计算好的视图。 批处理层使用可处理大量数据的分布式处理系统预先计算结果。它通过处理所有的已有历史数据来实现数据的准确性。这意味着它是基于完整的数据集来重新计算的,能够修复任何错误,然后更新现有的数据视图。输出通常存储在只读数据库中,更新则完全取代现有的预先计算好的视图。
速度处理层
速度处理层会实时处理新来的大数据。 速度层通过提供最新数据的实时视图来最小化延迟。速度层所生成的数据视图可能不如批处理层最终生成的视图那样准确或完整,但它们几乎在收到数据后立即可用。而当同样的数据在批处理层处理完成后,在速度层的数据就可以被替代掉了。 本质上,速度层弥补了批处理层所导致的数据视图滞后。比如说,批处理层的每个任务都需要 1 个小时才能完成,而在这 1 个小时里,我们是无法获取批处理层中最新任务给出的数据视图的。而速度层因为能够实时处理数据给出结果,就弥补了这 1 个小时的滞后。
服务层
所有在批处理层和速度层处理完的结果都输出存储在服务层中,服务层通过返回预先计算的数据视图或从速度层处理构建好数据视图来响应查询。 例如广告投放预测这种推荐系统一般都会用到Lambda架构。一般能做精准广告投放的公司都会拥有海量用户特征、用户历史浏览记录和网页类型分类这些历史数据的。业界比较流行的做法有在批处理层用Alternating Least Squares (ALS)算法,也就是Collaborative Filtering协同过滤算法,可以得出与用户特性一致其他用户感兴趣的广告类型,也可以得出和用户感兴趣类型的广告相似的广告,而用k-means也可以对客户感兴趣的广告类型进行分类。 这里的结果是批处理层的结果,在速度层中根据用户的实时浏览网页类型在之前分好类的广告中寻找一些top K的广告出来,最终服务层可以结合速度层的top K广告和批处理层中分类好的点击率高的相似广告,做出选择投放给用户。
Lambda 架构的不足
1、使用 Lambda 架构时,架构师需要维护两个复杂的分布式系统,并且保证他们逻辑上产生相同的结果输出到服务层中。
2、维护 Lambda 架构的复杂性在于我们要同时维护两套系统架构:批处理层和速度层。在架构中加入批处理层是因为从批处理层得到的结果具有高准确性,而加入速度层是因为它在处理大规模数据时具有低延时性。
Kappa架构
简介:
由 LinkedIn 的前首席工程师杰伊·克雷普斯(Jay Kreps)提出的一种架构思想。克雷普斯是几个著名开源项目(包括Apache Kafka和 Apache Samza 这样的流处理系统)的作者之一,也是现在 Confluent 大数据公司的 CEO。
Kappa架构图
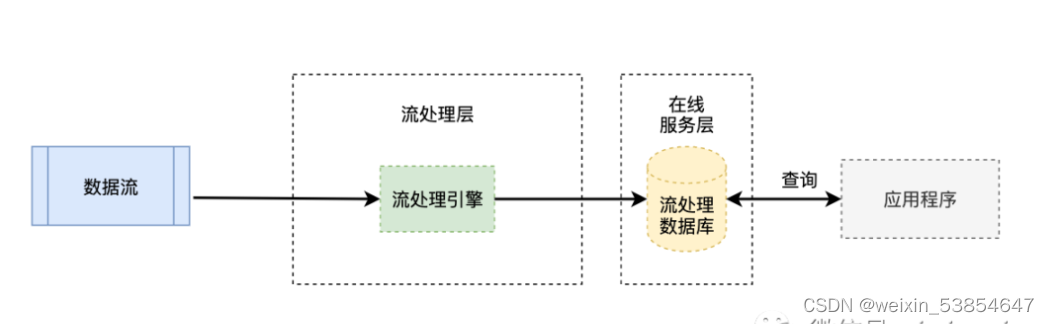
与Lomdba的区别
它去掉了批处理引擎,直接使用流处理引擎,目标是做到流批一体。
Kappa流行的主要原因
在于Kafka和Flink的兴起:
Kafka不仅起到消息队列的作用,也可以保存更长时间的历史数据,以替代Lambda架构中批处理层数据仓库部分。流处理引擎以一个更早的时间作为起点开始消费,起到了批处理的作用。
Flink流处理引擎解决了事件乱序下计算结果的准确性问题。
架构过程
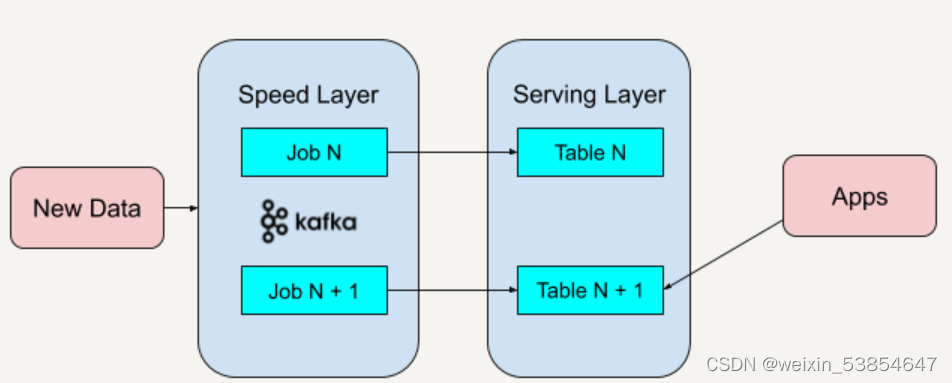
- 部署 Apache Kafka,并设置数据日志的保留期(Retention Period)。这里的保留期指的能够重新处理的历史数据的时间区间。例如,如果重新处理最多一年的历史数据,可以把 Apache Kafka 中的保留期设置为 365 天。如果处理所有的历史数据,可以把 Apache Kafka 中的保留期设置为“永久(Forever)”。
- 如果要改进现有的逻辑算法,就需要对历史数据进行重新处理。需要重新启动一个 Apache Kafka 作业实例(Instance)。该作业实例从头开始,重新计算保留好的历史数据,并将结果输出到一个新的数据视图中。重新计算只需要将Kafka 的 Log Offset 设置为 0,即可从头开始处理历史数据。
- 当新的数据视图处理过的数据进度赶上了旧的数据视图时,应用便可从新的数据视图中读取数据。
- 停止旧版本的作业实例,并删除旧的数据视图。
与 Lambda 架构不同的是,Kappa 架构去掉了批处理层这一体系结构,而只保留了速度层。只需要在业务逻辑改变又或者是代码更改的时候进行数据的重新处理。
Kappa 架构自身的不足:
- Kappa 架构只保留了速度层而缺少批处理层,在速度层上处理大规模数据如果有数据更新出错的情况发生,需要花费更多的时间在处理错误异常上面。
- Kappa 架构的批处理和流处理都放在了速度层上,导致了这种架构是使用同一套代码来处理算法逻辑,因此 Kappa 架构并不适用于批处理和流处理代码逻辑不一致的场景。
小结:
- 如果业务逻辑是设计一种稳健的机器学习模型来预测即将发生的事情,优先考虑 Lambda 架构,因为它拥有批处理层和速度层来确保更少的错误。
- 如果业务逻辑是希望实时性比较高,且客户端是根据运行时发生的实时事件来做出回应,应该优先考虑使用 Kappa 架构。
企业架构选型
| 公司刚上大数据或者公司业务没有实时场景 | 传统离线大数据架 |
| 公司离线业务多,实时业务少 | 离线数仓 + 实时链路的Lambda架构 |
| 公司离线业务和实时业务都比较多 | 离线数仓 + 实时数仓的Lombda架构 |
| 公司实时业务多,离线相对少 | Kappa纯实时数仓结构 |

















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









