






目录
RDD序列化
闭包检查:
从计算的角度来看,算子以外的代码都在Driver端执行,算子里面的代码都是在Executor端执行。那么在scala函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,也就意味着无法值给Executor端执行,就会发生错误,所以需要在执行任务计算前,检测闭包中的对象是否可以进行序列化,这个操作我们称之为闭包检测。
序列化方法和属性
从计算的角度,算子以外的代码都是Driver端执行,算子里面的代码都是在Executor端执行。


Kryo序列化框架:
java的序列化能够序列化任何的类,但是比较重,比较繁杂,字节多,序列化后,对象的提交也比较大。Spark为了提升性能,开始使用Kryo框架机制。Kryo是Serializable的十倍。当RDD在shuffle数据时,简单数据类型,数组和字符串已经在spark内部使用Kryo来序列化。
注意:即使使用 Kryo 序列化,也要继承 Serializable 接口。

RDD持久化(RDD persistence)
RDD persistence:可以将中间的结果保存,提供复用能力,加速基于中间结果的后续计算,经常可以提高10x以上的性能。,他的主要方法有persist()和cache()
RDDCache缓存
RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存 在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算 子
时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
// cache 操作会增加血缘关系,不改变原有的血缘关系 println(wordToOneRdd.toDebugString)
// 数据缓存。
wordToOneRdd.cache()
// 可以更改存储级别
//mapRdd.persist(StorageLevel.MEMORY_AND_DISK_2)
存储级别:
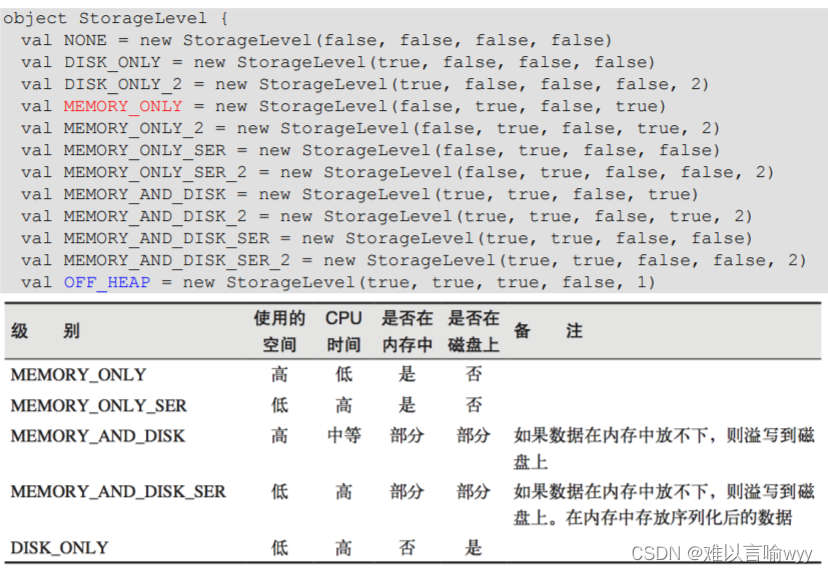
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD 的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于 RDD 的一系列转换,丢失的数据会被重算,由于 RDD 的各个 Partition 是相对独立的,因此只需要计算丢失的部分即可, 并不需要重算全部 Partition。 Spark 会自动对一些 Shuffle 操作的中间数据做持久化操作(比如:reduceByKey)。这样 做的目的是为了当一个节点 Shuffle 失败了避免重新计算整个输入。但是,在实际使用的时 候,如果想重用数据,仍然建议调用 persist 或 cache。
RDD persist缓存
persist()和cache()都是计算缓存。但是persist()功能更加强大,由于其支持设置存储级别,所以用起来更加灵活方便。cache()虽然是使用默认存储级别,但是在网上看到,使用cache()出现内存溢出的问题,换成persist()就没问题。我一般使用persist(),所以没遇到过这
个问题。
什么时候使用persist()?
1、当一个中间数据集,后面被多个计算重复使用,你应该对这个数据集使用persist()。
2、如果资源允许,你应该尽可能多的使用persist(),因为这可以极大的减少重复计算,提高程序性能。
当整个中间数据集不再被使用,便需要立刻释放这个数据集占用的资源,我们便需要使用unpersist()来释放资源。
persist在条件允许的情况下,默认使用默认存储级别(memory only)。
RDD CheckPoint 检查点
所谓的检查点其实就是通过将 RDD 中间结果写入磁盘 由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。 对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发。
缓存和检查点区别
- Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。 Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低,cache是persist的一种简化方式,cache调用的是persist的无参版本。
- cache默认持久化等级是内存且不能修改,persist可以修改持久化的等级。
- Checkpoint 的数据通常存 储在 HDFS 等容错、高可用的文件系统,可靠性高。
- 建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存 中读取数据即可,否则需要再从头计算一次 RDD。
- persist虽然持久化到磁盘,但是dirver program一但执行结束,被缓存在磁盘上的RDD也会清空。checpoint则是将RDD持久化到HDFS或者本地文件夹中,不手动删除的话,会一直存在,也就是会被下一个driver program使用。
注意:cache或者persist之后不可以有其他算子














 691
691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









