






仅仅是个笔记而已
1.NIO
1.1 NIO概述
1.1.1 NIO:用于进行数据传输的
1.1.2 与javaSE中的IO(BIO)的区别:
- BIO:Blocking IO 阻塞式IO
a. 一对一连接:每个客户端都需要一个服务器端的线程来处理,如果并发量增大的时候,服务器端会产生大量的线程,此时线程数量过多就可能导致服务器崩溃
b. 单向流:需要创建大量的流对象,内存就会被大量占用
c. 客户端连接之后即使不产生任何操作也会占用服务器端的线程,导致服务器资源的浪费 - NIO:NEW IO – Non Blocking IO 同步非阻塞式IO,专门为了应对高并发场景设计的
- BIO是面向流设计的:比如线程调用wait(),该线程被阻塞,直到数据被读取完成或者数据写入
完成之后,当前线程不能执行其他的操作 - NIO是面向缓冲区设计的:将数据读取到一个线程稍后处理的缓冲区当中,在有需要的时候再处理缓冲区中的数据;非阻塞式,该线程从通道发送请求读取数据,会读取到可用的数据,如果目前没有可用数据则什么都不获取,并不会保持在线程阻塞状态,也即直到数据变得可用之前,该线程是可以继续执行其他操作的,同理,一个线程请求一些数据到通道,不需要等数据完全写入,当前线程可以同时执行其他操作。
1.1.3 NIO组件
- Buffer缓冲区:用于存储数据
- Channel通道:用于传输数据
- Selector选择器:基于通道进行选择
- NIO就是基于此三个组件进行工作的,数据从通道读取到缓冲区中,从缓冲区写入数据到通道中,选择器用于监听多个通道的事件(比如建立连接、数据写入等),实现单个线程可以同时监听多个通道
1.2 NIO-Buffer概述
1.2.1 Buffer—缓冲区
- 在NIO中用于进行数据的存储,底层是基于数组实现进行存储,所存储的数据类型是基本数据类型,也对应提供了对应类型的缓冲区子类
- 常见的Buffer子实现类:ByteBuffer/CharBuffer/ShortBuffer/IntBuffer/
LongBuffer/FloatBuffer/DoubleBuffer,其中最常用的是ByteBuffer - 关键要素:
a. capacity:容量,用于定义缓冲区的容量,也即是底层数组的长度
b. limit:限制位,用于标记操作所能达到的最大尺度,默认在缓冲区的最后一位
c. position:操作位,用于指向要操作的位置,默认值为0
d. mark:标记位,用于标记数据的位置,一般是在校验时使用,默认值为-1表示不启用 - 重要操作
a. allocate(capacity):创建缓冲区并声明缓冲区容量
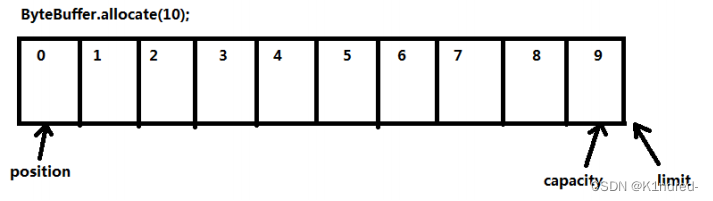
b. put():写入数据,底层实际上调用的是put(byte[],0,data.length);从下标为0处开始写入数据
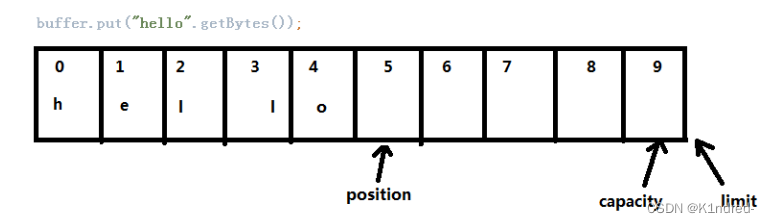
c. position():获取当前操作位,可以传入newPosition,表示挪动操作位
d. get():获取数据,读取一次position自增一次;也可以获取指定操作位的数据
e. flip():反转缓冲区,会将将limit移到当前position上,将position归零,mark置为-1;通常用于遍历缓冲区
f. clear():清空缓冲区,回归缓冲区的原始状态,将position归零、将limit归capacity,此时缓冲区中的数据其实未被清除,由于此时position
=0&limit=capacity,那么再次操作缓冲区时就是从0开始写入数据,本质是还原标记位遗忘之前的数据操作
g. reset():重置缓冲区,结合mark()标记当前position,将position挪到此mark上
h. rewind():重绕缓冲区,将position归零,mark置为-1,limit保持不变,用于重读缓冲区中的数据
i. wrap(byte []data):根据已知数据创建缓冲区
1.3 NIO-Channel概述
1.3.1 Channel通道
- 用于进行数据的传输,是一个双向通道–可以进行数据的双向传输,提供了从文件、网络读取数据的通道,但是读写数据都是面向缓冲区进行操作的
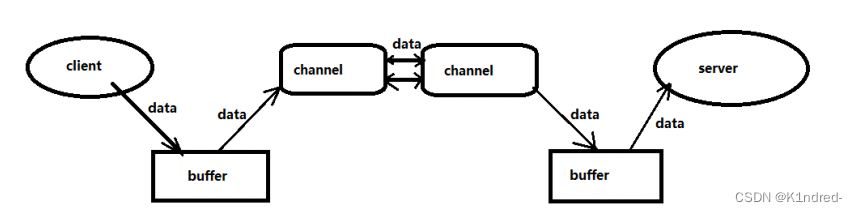
- Channel常见的实现类:
a. 文件型通道:FileChannel
b. TCP协议通道:SocketChannel,ServerSocketChannel
c. UDP协议通道:DatagramChanne - 文件通道的应用:
a. 准备一个文件,实现写入读取
public class FileChannelDemo{
publicstaticvoidmain(String[]args){
//利用RandomAccessFile获取文件通道
RandomAccessFileaccessFile=null;
try{
accessFile=newRandomAccessFile("src/LICENSE","rw");
//在此文件上开启文件通道
FileChannelfc=accessFile.getChannel();
//创建缓冲区
ByteBufferbuffer=ByteBuffer.allocate(1024);
//向缓冲区中写入数据
intread=fc.read(buffer);
System.out.println("buffer值="+newString(buffer.array()));
System.out.println("read值="+read);
//读取缓冲区中数据
while(read!=-1){
buffer.flip();
while(buffer.hasRemaining()){
System.out.println((char)buffer.get());
}
//思考如何处理数据,得到文件中的字符串
System.out.println(newString(buffer.array()));
//继续写入数据,并且不会覆盖到未读数据
//将未读取的数据拷贝到Buffer起始位置处
//然后将position设置到最后一个未读元素后面,limit设置为capacity
buffer.compact();
System.out.println("position值="+buffer.position());
read=fc.read(buffer);//将read置为-1
System.out.println(newString(buffer.array()));
System.out.println("read值="+read);
}catch(Exceptione){
e.printStackTrace();
}finally{
try{
accessFile.close();
}catch(IOExceptione){
e.printStackTrace();
}
}
}
}
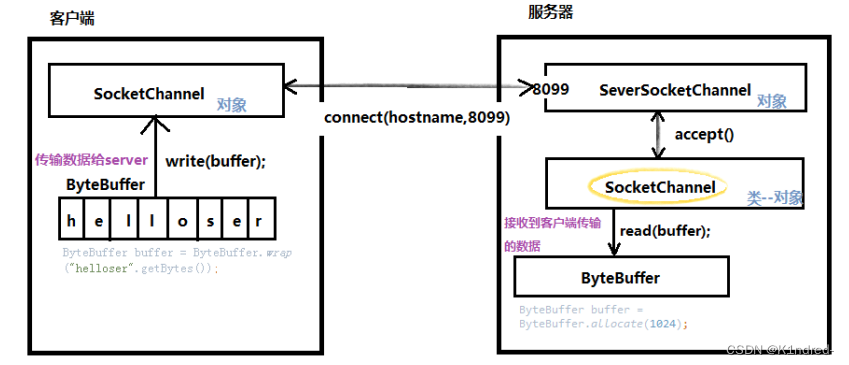
- TCP协议通道
a. SocketChannel & ServerSocketChannel
b. NIO的服务器端ServerSocketChannel的使用:
c. NIO的客户端SocketChannel的使用:
d. NIO的通道传输数据图解:
//开启服务器端的通道:
ServerSocketChannel ssc = ServerSocketChannel.open();
//绑定所监听的端口:
ssc.bind(new InetSocketAddress(8099));
//设置此通道为非阻塞式:
ssc.configureBlocking(false);
//接收客户端通道的连接并判断是否连接成功:
SocketChannel sc = ssc.accept();
//判断此时客户端连接是否真正建立成功
while(sc==null){
sc=ssc.accept();
}
//打开客户端通道
SocketChannel sc=SocketChannel.open();
//设置非阻塞式
sc.configureBlocking(false);
//发送连接请求到服务器127.0.0.1:8099
发送连接请求到服务器127.0.0.1:8099
sc.connect(new InetSocketAddress("127.0.0.1",8099));
//客户端确认连接是否成功建立
//底层会进行计数,如果多次连接均未成功,那么就认为此连接无法建立,抛出异常
while(!sc.isConnected()){
System.out.println("连接未成功建立");
sc.finishConnect();
}
1.4 详细案例
1.4.1 要求
- 使用TCP通道完成聊天室功能
a. 客户端与服务器之间相互发送消息
b. 获取用户从控制台输出的数据,存储到缓冲区中,通过通道进行双向传输
1.4.2 环境
- jdk1.8
- 操作系统win10
- 编译器idea2022.3
1.4.3 服务器端代码
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Scanner;
public class ServerAction {
public static void main(String args[]) throws Exception {
int action = 1; //操作指示器
Scanner cin = new Scanner(System.in);
ByteBuffer readBuffer = null; //接收消息缓冲区
ByteBuffer writeBuffer = null; //发送消息缓冲区
ServerSocketChannel ssc = ServerSocketChannel.open();
// 监听50000号端口
ssc.bind(new InetSocketAddress(50000));
ssc.configureBlocking(false);
SocketChannel sc =null;
while(sc == null){
sc = ssc.accept();
}
System.out.println("====================");
System.out.println("用户已连接!");
System.out.println("====================");
while(true){
// 0为发送,1为接收
if(action == 1){
readBuffer = ByteBuffer.allocate(3072);
sc.read(readBuffer);
String question = new String(readBuffer.array());
if(readBuffer.get(0) == 0){
action = 1 - action; //如果用户还未提问则继续等待
}
else{
System.out.println("用户的问题是:" + question);
System.out.println("====================");
}
}
else{
System.out.print("我的回答是:");
String answer = cin.nextLine();
System.out.println("====================");
writeBuffer = ByteBuffer.wrap(answer.getBytes());
sc.write(writeBuffer);
}
action = 1 - action; //切换操作
}
}
}
1.4.4 客户端代码
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SocketChannel;
import java.util.Scanner;
public class UserAction {
public static void main(String args[]) throws Exception {
int action = 0; //操作指示器
Scanner cin = new Scanner(System.in);
ByteBuffer readBuffer = null; //接收消息缓冲区
ByteBuffer writeBuffer = null; //发送消息缓冲区
SocketChannel sc = SocketChannel.open();
sc.configureBlocking(false);
//发送连接请求
sc.connect(new InetSocketAddress("127.0.0.1", 50000));
while(!sc.isConnected()){
sc.finishConnect();
}
System.out.println("====================");
System.out.println("服务器已连接!");
System.out.println("====================");
while(true){
// 0为发送,1为接收
if(action == 0){
System.out.print("我的问题是:");
String question = cin.nextLine();
System.out.println("====================");
writeBuffer = ByteBuffer.wrap(question.getBytes());
sc.write(writeBuffer);
}
else{
readBuffer = ByteBuffer.allocate(3072);
int count = sc.read(readBuffer);
String answer = new String(readBuffer.array());
if(count <= 0){
action = 1 - action; //若服务器未回答则继续等待
}
else{
System.out.println("服务器的回答是:" + answer);
System.out.println("====================");
}
}
action = 1 - action; //切换操作
//Thread.sleep(2000);
}
}
}
1.4.5 效果描述
- 任意一方只有等到对方回复后,才可发送新的信息
- 信息显示在控制台
1.5 NIO—Selector
1.5.1 选择器的意义
- 含义:
a. 传统的IO流是阻塞式的,也就是说,当一个线程调用read()或者write(),该线程被阻塞,直到有一些数据被读取或写入,该线程在此期间不能执行其他任务;因此,在完成网络通信进行IO操作,由于线程会阻塞,所以服务器端必须要为每一个客户端都提供一个独立的线程进行处理,当服务器端需要处理大量客户端时,性能急剧下降
b. NIO是可以设置为非阻塞式模式,当线程从某个通道进行读写数据时,若没有数据可用时,该线程可以进行其他的任务。线程通常将非阻塞IO的空闲时间用于在其他通道上执行IO操作,所以单独的线程可以管理多个输入和输出的通道,因此NIO可以让服务器使用一个或者几个线程来同时处理连接到服务器端的所有客户端 - 多路复用选择器—Selector
a. 选择器(Selector)是SelectableChannel对象的多路复用器,Selector可以同时监控多个SelectableChannel的IO状况;也就是说,利用Selector可以使得一个单独的线程管理多个Channel。
b. Selector是非阻塞IO的核心:用于进行通道的选择,基于事件驱动机制来完成,即通道身上必须有对应事件才能被处理(被动触发),此时选择器上注册的通道必须是非阻塞式的
c. 事件驱动机制:`
接收请求 OP_ACCEPT
发起连接请求 OP_CONNECT
读取 OP_READ
写入片 OP_WRITE - 应用
//打开选择器:
Selector selector=Selector.open();
//注册通道以及通道感兴趣的事件
SelectionKey selectionKey=ssc.register(selector,SelectionKey.OP_ACCEPT);
//注意:此时返回的SelectionKey 对象就代表着注册到当前Selector的通道
//返回已有感兴趣事件且就绪的通道
int i= selector.select();
//注意:此方法为阻塞方法,会等待直到返回可用通道或等待超时(可以通过select(TIMEOUT)指定超时时间)
//一旦有一个或多个就绪的通道,访问“已选择键集”中的通道:
Set<SelectionKey> selectionKeys = selector.selectedKeys();
//迭代器遍历键集:
Iterator<SelectionKey> it=selectionKeys.iterator();
while(it.hasNext()){
//取出每一个事件
SelectionKey key=it.next();
}
//获取通道,根据所需要的通道类型进行转型
ServerSocketChannel sscx= (ServerSocketChannel)key.channel();
SocketChannel sc=(SocketChannel)key.channel();
//处理完某类事件,将通道上的事件注销
sc.register(selector,key.interestOps()^SelectionKey.OP_WRITE);
- 总结:
a. 利用选择器可以避免使用“阻塞式”客户端时一些浪费资源的“忙等”情况;
b. 利用Selector阻塞等待你,直到有一个通道可以进行IO操作,并且指出具体是哪一个通道;
c. 可以利用selector实现同时检查若干个通道的IO状态
2.序列化
2.1 序列化概述
2.1.1 概述
- 数据序列化:将对象或数据结构转化成特定格式(字节序列),使得数据可以在网络中进行传输或者可以保存在磁盘文件当中;相应的,反序列化就是将特定格式(字节序列)还原成对象或数据
- 数据序列化的重点在于数据的交换和传输
- Java原生的序列化接口Serializable:
a. 无法实现跨语言&跨平台使用:在进行序列化\反序列化时,是按照Java指定的格式来进行对象的解析,解析为字节码格式,当其他语言或其他平台接收到此对象的字节码文件时解析还原为对象较为困难甚至无法解析 - 序列化的衡量标准:
a. 序列化\反序列化的耗时以及占用的CPU
b. 序列化之后的数据大小:因为序列化的数据要通过网络进行传输或者存储在磁盘文件中,此时数据量越小则传输越快存储越不占用空间
c. 序列化能够跨平台、跨语言:因为在实际企业开发中,一个项目往往是由多个系统可能使用多种语言进行架构和实现的,那么在异构的网络系统中,网络双方可能使用的不同的语言甚至不同的操作系统,例如客户端使用Windows系统、开发语言为Java,而服务器端的是Linux系统、开发语言为C++,要求序列化框架能够实现在不同语言和不同平台之间进行数据的解析传输。
2.1.2 常见的序列化框架
- Java的原生序列化接口
- Avro:Apache提供的开源的序列化和反序列化框架:
a. 丰富的数据结构类型:8种基本&6种复杂
b. 快速可压缩的二进制格式
c. 提供容器文件用于持久化数据
d. 远程过程调用RPC框架
e. 简单的动态语言结合功能
f. Hadoop的子工程,又不仅仅可用于Hadoop框架 - Protobuf:Google提供的序列化框架
- Thrift:Facebook提供的序列化框架,目前属于Apache
2.1.3 远程过程调用 RPC
- 全称Remote Produce Call:是一种用于进程间通信的方式 ,允许程序调用另一个地址空间(通常是共享网络中的另一台机器上)的过程或者函数,而不用程序员显式地编码这个远程调用的细节。也即是无论是本地
还是远程调用,本质上编写的调用代码基本相同 - 特点:
a. 简单
b. 高效
c. 通用 - 架构:
a. 客户端client(用户user)
b. 客户端代理程序ClientStub(用户存根UserStub)
c. 网络Network
d. 服务器端代理程序ServerStub
e. 服务器Server - 流程图
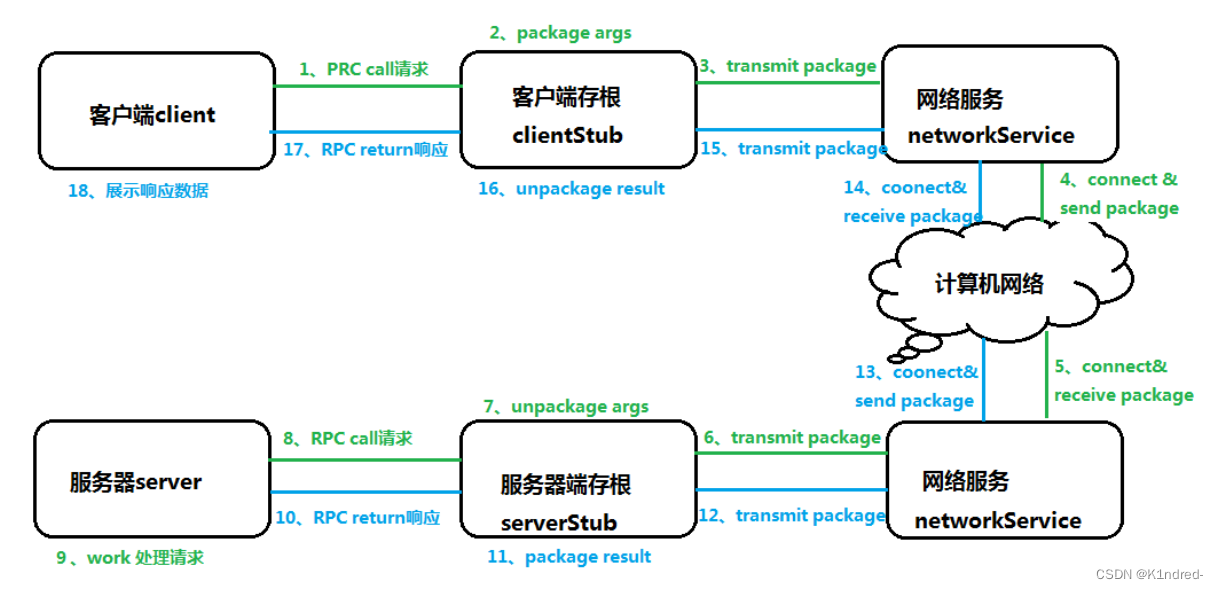
- 调用细节:
a. 接口方式的调用:RPC的设计目的在于可以让调用者以类似本地调用的方式来调用远程服务,具体实现的方式就是调用接口,在Java中底层通过Java动态代理方式来生成接口的代理类(存根Stub),代理类中封装和远程通信的细节:
- 客户端请求消息:
a.接口名称
b.方法名
c.参数类型以及参数值
d.requestID
e.代理Stub添加的网络通信模块- 服务器端返回响应
a. 结果值
b. requestID
c. 代理Stub添加的网络通信模块
b. 序列化\反序列化
2.2 序列化框架
2.2.1 简介
- AVRO是一种远程过程调用的数据序列化框架,是在Apache的Hadoop之内开发;它使用JSON格式来定义数据类型和通讯协议的,使用压缩二进制格式来序列化数据
- 主要用于Hadoop,可以为持久化数据提供一种序列化格式并且为Hadoop集群中多个节点之间以及从客户端程序到Hadoop服务器之间的通信提供一种电报格式
- 通过AVRO每次进行序列化要根据模式schema来实现,提升性能:
a. 丰富的数据结构类型:8种基本&6种复杂
b. 快速可压缩的二进制格式
c. 提供容器文件用于持久化数据
d. 远程过程调用RPC框架
e. 简单的动态语言结合功能
f. Hadoop的子工程,又不仅仅可用于Hadoop框架
2.2.2 数据类型
- 基本数据类型:
| Avro类型 | 说明 |
|---|---|
| null | 没有值 |
| boolean | 一个二级制布尔值 |
| int | 32位有符号整数 |
| long | 64位有符号整数 |
| float | 32位单精度浮点数 |
| double | 64位双精度浮点数 |
| bytes | 8位无符号字节序列 |
| string | 字符序列 |
- 复杂数据类型:
a. 每种复杂数据类型都含有各自的一些属性,其中部分属性是必需的,部分是可选的
b. 其中Record类型中的fields属性有默认值:
| 类型 | 属性 | 说明 |
|---|---|---|
| record | class | |
| name | a JSON string providing the name of the record (required). | |
| namespace | a JSON string that qualifies the name(optional). | |
| doc | a JSON string providing documentation to the user of this schema (optional). | |
| aliases | a JSON array of strings, providing alternate names for this record (optional). | |
| fields | a JSON array, listing fields (required). | |
| –name | a JSON string. | |
| –type | a schema/a string of defined record. | |
| –default | a default value for field when lack. | |
| –order | ordering of this field. | |
| Enums | enum | |
| name | a JSON string providing the name of the enum (required). | |
| namespace | a JSON string that qualifies the name. | |
| doc | a JSON string providing documentation to the user of this schema (optional). | |
| aliases | a JSON array of strings, providing alternate names for this enum (optional) | |
| symbols | a JSON array, listing symbols, as JSON strings (required). All symbols in an enum must be unique | |
| Arrays | array | |
| items | he schema of the array’s items. | |
| Maps | map | |
| values | the schema of the map’s values. | |
| Fixed | fixed | |
| name | a string naming this fixed (required). | |
| namespace | a string that qualifies the name. | |
| aliases | a JSON array of strings, providing alternate names for this enum (optional). | |
| size | an integer, specifying the number of bytes per value (required). | |
| Unions | a JSON arrays |
3.与json对比:
| Avro类型 | json类型 | 举例 |
|---|---|---|
| null | null | null |
| boolean | boolean | true |
| int,long | integer | 1 |
| float,double | number | 1.1 |
| bytes | string | “\u00FF” |
| string | string | “foo” |
| record | object | {“a”: 1} |
| enum | string | “FOO” |
| array | array | [1] |
| map | object | {“a”: 1} |
| fixed | string | “\u00ff” |
2.3 AVRO-API:序列化
2.3.1 AVRO-API:序列化
- 步骤
a. 创建maven工程,导入pom依赖(这里是MAVEN5.3):
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<avro-version>1.7.5</avro-version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!--日志包-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.6.4</version>
<scope>compile</scope>
</dependency>
<!--avro包-->
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>${avro-version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--添加avro相关插件-->
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>${avro-version}</version>
<executions>
<execution>
<id>schema</id>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<!--存放avro的模板文件avsc/avdl的目录-->
<sourceDirectory>${project.basedir}/src/main/avro</sourceDirectory>
<!--存放产生的Java文件的存放目录-->
<outputDirectory>${project.basedir}/src/main/java</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
<plugins>
- 定义avro的schema文件:通过JSON格式来定义,通常要以.avsc结尾;会根据Maven创建自动去指定目录(src/main/avro)下获取.avsc结尾的模式文件并自动构建生成Java文件
a. 在src/main创建avro目录,并设置为source:
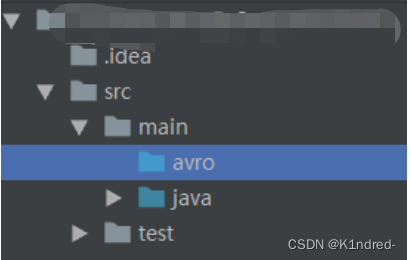
b. 新建一个名为user.avsc的schema文件:
{
“type”:“record”,
“name”:“User”,
“namespace”:“avro.domain”,
{“type”:“string”,“name”:“username”},
{“type”:“int”,“name”:“age”}
]
“fields”:[
}
c. 生成User的Java文件:在当前工程上执行maven中的install
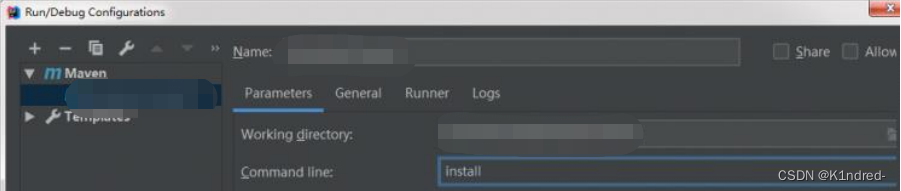
其中maven的avro插件会主动搜索到user.avsc文件,并在指定目录生成avro.domian.User的java文件执行成功(提示build success),查看到此文件:
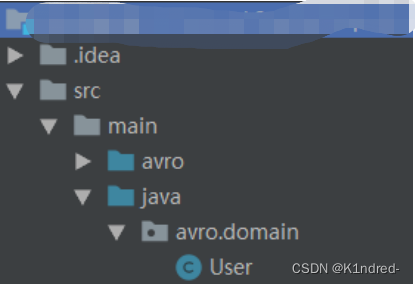
d. 另一种方式:借助avro-tools.jar的支持来实现构建schema文件
i.在pom.xml中添加依赖坐标:
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-tools</artifactId>
<version>${avro-version}</version>
</dependency>
ii. 此时会自动联网将上述jar包下载到本机的本地仓库中
iii. 将此jar包完整拷贝至工程的src/main/avro目录下;进入到文件所在的盘符路径下,并输入cmd,进行命令执行窗口
iv. 通过java -jar指令来执行构建:
java -jar avro-tools-1.8.1.jar compile schema . user.avsc …\java
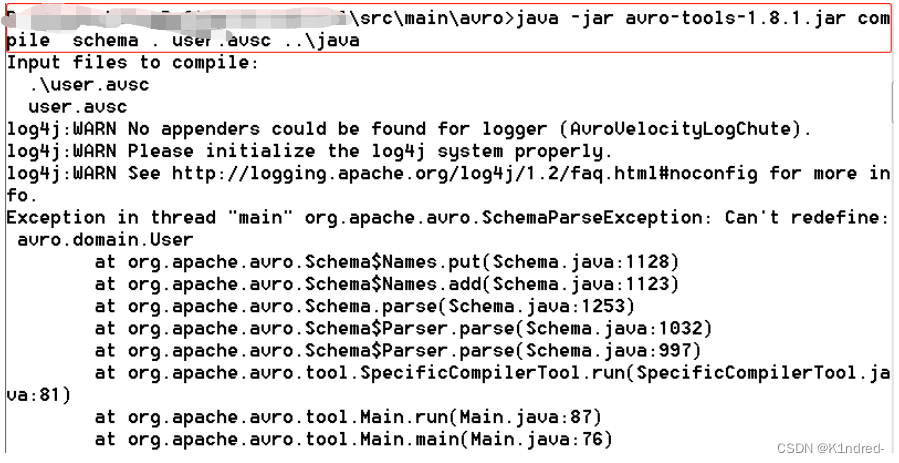
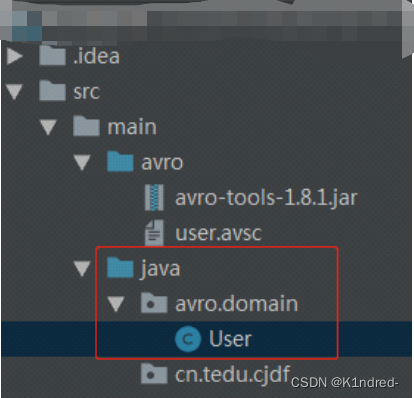
v. 回车执行,查看此时src/main/java目录下是否有avro/domain/User.java文件
- 实现序列化和反序列化:
a. 序列化:
//序列化方法:将对象|数据结构以特定格式持久化到磁盘中,存储到磁盘文件
@Test
public void testSerial() throws IOException{
//创建两个对象
User u1=new User("Amy",17);
User u2=User.newBuilder(u1).setUsername("Jerry").build();
//创建AVRO的序列化流:将对象从内存写出到磁盘文件中
DatumWriter<User> dw=new SpecificDatumWriter<>(User.class);
//创建AVRO的文件流
DataFileWriter<User> dfw=new DataFileWriter<>(dw);
//指定文件
dfw.create(User.SCHEMA$,newFile("user.txt"));
//进行序列化
dfw.append(u1);
dfw.append(u2);
//关流
dfw.close();
}
b. 反序列化
//反序列化:将字节文件转换成对象
@Test
publicvoidtestDeserial()throwsIOException{
//创建AVRO的反序列化流:将对象从文件的字节转换出兵读取到内存中
DatumReader<User> dr=new SpecificDatumReader<>(User.class);
//创建AVRO的文件流
DataFileReader<User> dfr = new DataFileReader<User>(newFile("user.txt"),dr);
//AVRO将DataFileReader设计为了一个迭代器:因为序列化文件中往往包含若 干个对象
//遍历此dfr获取其中每一个对象
User user=dfr.next();
System.out.println("user值="+user);
while(dfr.hasNext()){
}
//关流
dfr.close();
}
输出结果:
user值={“username”: “Amy”, “age”: 17}
user值={“username”: “Jerry”, “age”: 17}
2.3.2 AVRO-API:RPC
- 创建maven工程,导入pom依赖
a. 相较于序列化,增加以下依赖:
<!--avro-rpc包-->
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-ipc</artifactId>
<version>${avro-version}</version>
</dependency>
b. 插件修改:
<goals>
<goal>schema</goal>
<goal>protocol</goal>
<goal>idl-protocol</goal>
</goals>
- 在src/main目录下创建avro目录,并设置为sources源目录
- 编写user.avsc模式文件,根据此文件的数据类型构建User.java实体类
{
"type":"record",
"namespace":"avro.beans",
"name":"User",
"doc":"test avro-rpc user",
"fields":[
{"type":"int","name":"id"},
{"type":"string","name":"username"},
{"type":"int","name":"age"},
{"type":"string","name":"gender"}
]
}
- 编写avdl协议文件,定义数据传输方式:
a. protocolMsg.avdl传输基本数据类型的数值的协议:
@namespace("avro.rpc")
protocol AddService{
int add(int i,int j);
}
b. protocolMsg2.avdl传输对象类型的数值的协议:
@namespace("avro.rpc")
protocol TransferService{
import schema "user.avsc";
void parseUser(avro.beans.User user);
}
c. protocolMsg3.avdl传输map类型且其中存储了User对象的数值的协议:
@namespace("avro.rpc")
protocol MapService{
import schema "user.avsc";
void parseUserMap(map<avro.beans.User> userMap);
}
d. 格式非常类似java中的接口,并且的确会被构建成接口
- 书写无误,则maven install编译构建出所需的User.java以及协议相应的接口
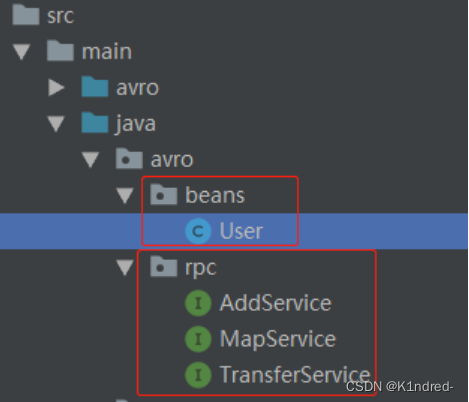
- 案例1:基本类型数据传输
//a. 服务器端实现协议接口,重写自己的逻辑
public class AddServiceImpl implements AddService{
@Override
public int add(inti,intj) throws AvroRemoteException{
returni+j;
}
}
//b. 编写server服务器端:
public class FundationServer{
public static void main(String [] args){
System.out.println("启动服务器::::");
//模拟开启一台服务器:
//采用基于Netty的MNettyServer,传入封装了响应的Responder以及服务器监听的接口
//Responder需要指明协议以及代理程序(实现类)
SpecificResponder responder = new SpecificResponder(AddService.class,new AddServiceImpl());
NettyServer nettyServer = new NettyServer(responder,new InetSocketAddress(6666));
}
}
//c.编写client:
public class FundationClient{
public static void main(String[]args) throws IOException{
//向监听6666端口的服务器发起请求,传输数据
//利用TCP的SocketTransceiver:传入要连接的服务器的地址&端口
NettyTransceiver transceiver = new NettyTransceiver(new InetSocketAddress("127.0.0.1",6666));
//发送RPC调用:利用SpecificRequestor生成客户端的代理类
AddService clientProxy = SpecificRequestor.getClient(AddService.class,transceiver);
//传输数据,并获取响应结果
int result=clientProxy.add(10,30);
System.out.println("result值="+result);
}
}
d.执行:
i. 先运行服务器

ii. 再运行客户端

- 案例2:实现对象的传输
// a. 服务器端实现对象数据传输协议接口,重写自己的逻辑
public class ServerTransferServiceImpl implements TransferService{
@Override
public Void parseUser(User user) throws AvroRemoteException{
System.out.println("Server————》接收到:"+user.toString());
return null;
}
}
// b. 编写服务器端:
public class UserServer{
public static void main(String [] args){
//封装响应
Responder responder = new SpecificResponder(TransferService.class,new ServerTransferServiceImpl());
//创建服务器:监听8888端口,传入响应
NettyServer server = new NettyServer(responder,new InetSocketAddress(8888));
}
}
// c. 编写客户端:
public class UserClient{
public static void main(String [] args) throws IOException{
//连接服务器
NettyTransceiver client = new NettyTransceiver(new InetSocketAddress("localhost",8888));
//获取客户端代理
TransferService clientProxy = SpecificRequestor.getClient(TransferService.class,client);
//创建要传输的对象
User user=new User(1,"lisa",20,"female");
//客户端代理传输数据
clientProxy.parseUser(user);
}
}
3.虚拟机准备(三台)
3.1 入门
- 不理解的同学请请移步至Linux入门学习笔记(Centos7安装,基本指令,VIM操作 )
3.2 克隆
- 从源服务器(以下称cjdg-bigdata01)链接克隆2台虚拟机,命名为cjdf-bigdata02和cjdf-bigdata03
- 开机后修改静态IP:
a. 查看IP:ip addr
此时ens33网卡的第一个IP为此主机的IP地址
b. 编辑网卡文件:vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改其中的IPADDR为刚才查询到的新IP
c. 重启网络:systemctl restart network - 修改主机名(分别为master,slave01,slave02,后文只写一个):
a. 查看:hostname
b. 修改:hostname slave01
c. 系统级别:hostnamectl set-hostname slave01 - 重启虚拟机
3.3 网络通信
- 配置三台虚拟机的hosts文件,将主机名与IP地址进行映射,并且能够与集群内的其他服务器通信
- 编辑hosts文件:
a. 编辑:vim /etc/hosts
b. 先将前两行内容修改为:
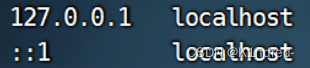
c. 追加三台虚拟机的IP地址与各自的主机名的映射关系:

d. 保存退出即可 - 可以将bigdata01上的hosts文件远程拷贝至其余两台服务器上
a. bigdata01》bigdata02:scp /etc/hosts root@slave01:/etc
b. bigdata01》bigdata03:scp /etc/hosts root@slave02:/etc - 此时不出意外,三台服务器均可以通过主机名实现互相免密登录;自行验证即可:
每一台上都依次去执行 ssh master & logout || ssh slave01 logout ||ssh slave02 logout
4.Zookeeper
4.1 zookeeper入门
4.1.1 分布式思想
- 当文件数据的体量超出了某一台服务器所能够存储的最大容量时,如果要继续存储,则首先根据数据整体规模大小以及单台服务器所能存储的最大容量,计算出存储该文件数据所需要的服务器总台数,进而实现服务器节点数
量的规划; - 其次将这些规划好的服务器以网络的形式组织起来,形成一个集群;
- 在这个集群当中,每一台服务器进行文件部分数据的存储以及计算等操作,统一管理集群中的各个服务器资源
4.1.2 zookeeper概述
- 概念:zookeeper是分布式协调服务框架,用于解决分布式环境下一些常见的问题:集群统一管理、统一命名服务、信息配置服务、分布式锁等等
- 分布式的解决方案:
a. 引入监控和管理节点来保证集群中服务器之间的任务调度
b. 为了防止单一监控节点带来的单点故障问题,所以需要引入多个监控节点
c. 为了防止多个监控节点之间的任务调度不同,需要从中选举出一个主监控节点(重点在于选举)
d. 为了避免主监控节点宕机而导致所有数据丢失的问题,需要将监控节点的数据进行统一
4.1.3 zookeeper的单机安装——bigdata01
- 创建软件管理目录:mkdir -p /home/software
将下发的jdk&zookeeper的压缩包上传至此目录下 - 虚拟机的防火墙:
a. 查看防火墙状态:systemctl status firewalld
b. 临时关闭:systemctl stop firewalld
c. 永久关闭:chkconfig firewalld off
d. 永久开启:chkconfig firewalld on
e. 临时开启:service firewalld start - zookeeper需要JDK环境支持(这里使用JDK1.8):
a. 虚拟机中安装JDK1.8,并配置其环境变量(当前工作目录为/home/software)
b. 解压:tar -zxvf jdk-8u181-linux-x64.tar.gz
c. 重命名:mv jdk1.8.0_181/ jdk
d. 设置jdk1.8的环境变量:
编辑环境变量的配置文件:vim /etc/profile
在此文件末尾添加(修改)以下内容:
JAVA_HOME=/home/software/jdk
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
保存修改并退出
重新加载此文件使得修改生效:source /etc/profile
e.确认此时系统中java版本信息:java -version

4. zookeeper的单机安装
a. 解压:tar -zxf zookeeper-3.4.7.tar.gz
b. 重命名:mv zookeeper-3.4.7 singleZK
c. 重要目录说明
i. bin:可执行文件所在目录

ii. conf:配置文件所在目录

d. 配置zookeeper的单机形式:
i. 切换到singleZK/conf目录下:cd singleZK/conf
ii. 复制一份模板文件zoo_sample.cfg,命名为 zoo.cfg:cp zoo_sample.cfg zoo.cfg
注意:zk在启动的时候会主动去conf目录下寻找名为zoo.cfg的配置文件,根据其中的配置项来启动zk服务
iii. 进行配置:vim zoo.cfg
iv. 修改其中的dataDir属性的值,指定数据文件(版本信息、事务日志、快照日志等等)的存储目录:

v. 保存修改即可
- 运行并使用单机的zk服务
a. 切换到singleZK/bin目录下:cd …/bin
b. 启动zk服务器端,执行zkServer.sh可执行文件:
i. 执行方式:./zkServer.sh || sh zkServer.sh
ii. 命令说明:
./zkServer.sh {start|start-foreground|stop|restart|status|upgrade|print-cmd}
iii. 启动服务:./zkServer.sh start

c. 确保zk服务是否正常运行:
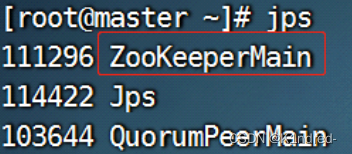
i. 查看进程:
ps -ef |grep zookeeper
jps
ii. 查看状态:./zkServer.sh status

说明:此时mode状态一定要是standalone才表示单机zk服务能够运行
d. 启动zk客户端,连接服务器进行使用:
命令说明:./zkCli.sh [-server] {host:port}
[-server] {host:port}可以省略,则表示默认连接本机上的占用了2181端口的ZK服务
启动客户端:./zkCli.sh
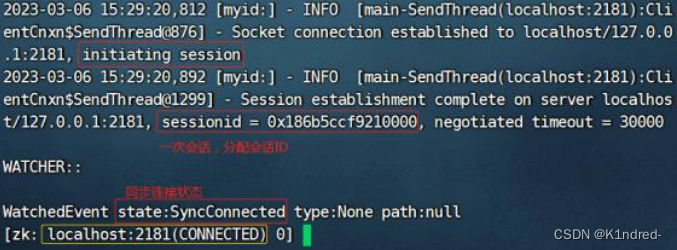
通过jsp指令查看到客户端进程:
4.1.4 zookeeper的结构特点
- zookeeper是一个树状结构,根节点为/,zookeeper中的每一个节点被称为znode节点,树状结构称为znode树
- znode树的所有znode都是从根节点出发(绝对路径,无相对路径形式的path)
- 每一个znode的路径都是唯一不可重复,可以实现集群中的统一命名服务
- znode的类型分为四种:
a. 持久节点:一经创建就会持久化到磁盘中
b. 临时节点:跟随客户端会话session销毁而销毁,归属于客户端会话
c. 持久顺序节点:持久化并编号
d. 临时顺序节点:临时并编号 - . 每一个持久节点znode都可以挂载子节点
- znode树是维系在内存中,也即每一个znode节点以及其存储的数据也是维系在内存中;便于查找
- znode树也可以持久化到磁盘,zookeeper提供了持久化机制(由zoo.cfg的dataDir属性来决定持久化目录);
便于恢复数据 - 每一个znode都必须存储数据,但是不能存储海量数据:
a. znode维系在内存中,并且假设是 集群模式每个zk存储的数据都是相同,造成了内存浪费甚至崩溃
b. zookeeper是为了实现分布式协调服务而不是存储服务 - zookeeper会为每一次事务(增删改)操作提供一个全局递增的事务ID——Zxid
4.1.5 zookeeper的客户端操作
- 客户端常见指令:
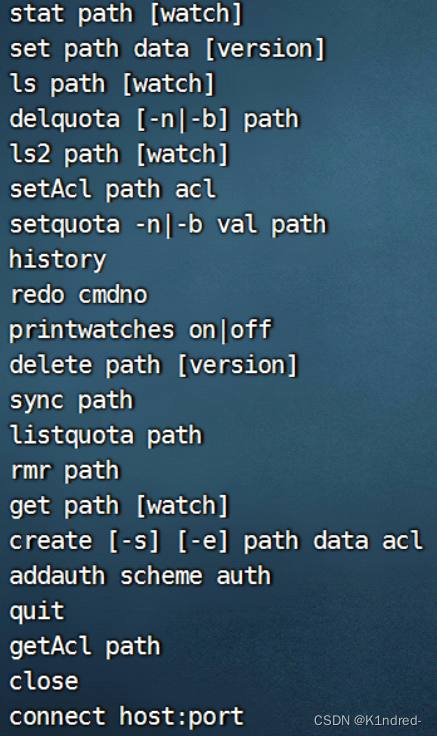
- 指令及其说明:
| 指令 | 说明 |
|---|---|
| ls / | 查看根节点/下的所有节点 |
| create /node01 | “zk” 在根节点下创建node01持久节点,并存储数据“zk” |
| create -e /node02 | “zk” 在根节点下创建node02临时节点,并存储数据“zk”;注意此节点不能挂载子节点,只归属于当前客户端会话 |
| create -s /node03 | “zk” 在根节点下创建node030000000002持久顺序节点,并存储数据“zk” |
| get /node01 | 查看/node01节点的所有信息 |
| set /node01 | “test” 修改/node01节点的数据并在屏幕 上打印修改后的节点信息(数据 & mZxid) |
| delete /node01 | 删除/node01节点,注意此时此节点不能有子节点,否则无法删除(文件夹) |
| rmr /node01 | 删除/node01节点及其子节点 |
- 节点信息:
| 信息 | 说明 |
|---|---|
| cZxid | 创建节点时所分配的全局事务id |
| ctime | 创建时间 |
| mZxid | 修改节点时所分配的全局事务id |
| mtime | 修改时间 |
| pZxid | 子节点的全局事务id;无子节点则与自身cZxid一致 |
| cversion | 子节点版本=子节点更改次数 |
| dataVersion | 数据版本=数据更改次数 |
| aclVersion | 权限版本=权限更改次数 |
| ephemeralOwner | 临时节点所有者;非临时节点则此值为0x0;是临时节点则此值为当前客户端会话的sessionID |
| dataLength | 数据长度 |
| numChildren | 子节点个数 |
- 关闭客户端:quit

说明:本质上是关闭了客户端会话,后续再次连接是一个全新的客户端会话,会重新分配sessionID
4.1.6 zookeeper的事务日志
- 概念:
a. 在zookeeper正常运行过程中针对所有的事务操作,在返回客户端ack的响应之前,zk会先保证已经将本次事务操作写入到磁盘中指定持久化目录的日志文件当中
b. 单机模式下,日志文件位于:/home/software/singleZK/tmp/version-2目录下
c. 启动zk服务就会开始写日志,此事务日志文件是二进制文件,无论使用vim\cat\tail哪个工具查看均是乱码 - 需要根据zk提供的日志jar包中的API的支持来实现事务日志文件的查看
a. 切换到singleZK/lib目录下: cd /home/software/singleZK/lib
b. 将其中的slf4j-api-1.6.1.jar拷贝到zookeeper的事务日志文件所在的数据目录下:
cp slf4j-api-1.6.1.jar …/tmp/version-2/
c. 将singleZK目录下的zookeeper-3.4.7.jar拷贝至数据目录下:
cp …/zookeeper-3.4.7.jar …/tmp/version-2/
d. 切换回到数据目录下:cd …/tmp/version-2/
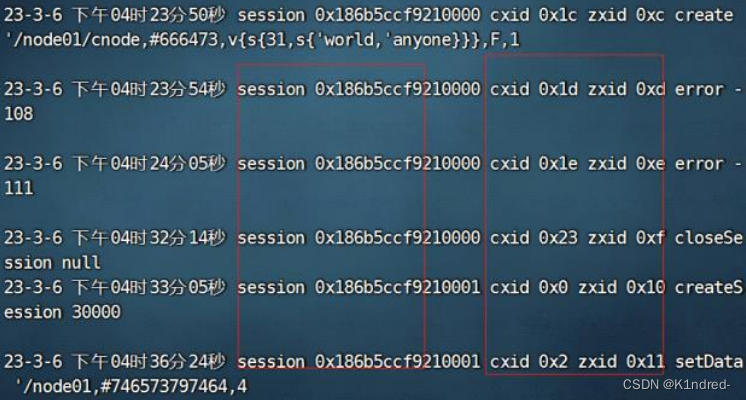
e. 执行查看二进制日志文件log.1的指令:
java -cp .:zookeeper-3.4.7.jar:slf4j-api-1.6.1.jar org.apache.zookeeper.server.LogFormatter log.1
4.2 zookeeper集群安装
4.2.1 环境准备工作
- 调整bigdata02 & bigdata03的环境
a. 关闭防火墙:
systemctl stop firewalld
chkconfig firewalld off
b. 创建工作目录:
mkdir -p /home/software
c. 将bigdata01上解压后的jdk远程拷贝至bigdata02 & bigdata03机器上,并设置环境变量:
i. 远程拷贝jdk文件夹(在master机上操作):
scp -r /home/software/jdk root@slave01:/home/software/
scp -r /home/software/jdk root@slave02:/home/software/
ii. 远程拷贝/etc/profile:
scp /etc/profile root@slave01:/etc
scp /etc/profile root@slave02:/etc
iii. bigdata02&bigdata03上
重新加载文件:source /etc/profile
查看此时的java版本:java -version
4.2.2 集群安装(第一台)
- 首先在bigdata01上配置集群中的第一台zk服务器:
- 切换到软件工作目录:cd /home/software/
- 再次解压zookeeper安装包:tar -zxf zookeeper-3.4.7.tar.gz
- 重命名:mv zookeeper-3.4.7 clusterZK
- 切换到clusterZK的conf目录下:cd clusterZK/conf
- 拷贝配置模板文件:cp zoo_sample.cfg zoo.cfg
- 编辑zoo.cfg文件,设置集群配置项:vim zoo.cfg
a. 数据持久化目录:dataDir=/home/software/clusterZK/tmp
b. 在配置文件的末尾构建zookeeper集群中所有服务器的地址以及原子广播端口&选举端口:
格式:server.服务器编号=服务器IP:原子广播端口:选举端口
例如:
server.1=192.168.88.177:2888:3888
server.2=192.168.88.178:2888:3888
server.3=192.168.88.179:2888:3888
注意:
1.服务器编号一定是数字,并且不能重复,是唯一的;此数字需要与后续服务器编号文件myid内数字一致
2.两个端口只要不和当前已使用的端口冲突即可
c. 保存退出 - 创建服务器编号文件myid:
a. 切换回到clusterZK目录下: cd …/
b. 创建tmp目录:mkdir tmp
c. 在此tmp目录下创建myid文件:touch tmp/myid
d. 编辑此文件,填入对应编号1:vim tmp/myid
bigdata01的myid——1,以此类推 - 配置zk的环境变量:
a. 编辑:vim /etc/profile
b. 添加新的ZK_HOME并修改PATH:
ZK_HOME=/home/software/clusterZK
PATH=$JAVA_HOME/bin:$ZK_HOME/bin:$PATH
export JAVA_HOME CLASSPATH ZK_HOME PATH
c. 保存退出,并重新加载:source /etc/profile
- 注意,此时要检查之前的单机ZK是否已经关闭,若未关闭,则通过指令:
a. 先jsp查看QuorumPeerMain前的进程号
b. 然后:kill -9 进程号
4.2.3 zookeeper集群使用
- 启动集群中的三台zk服务器:
a. 依次在三台机器上分别执行:zkServer.sh start - 查看集群的状态:
a. jps查看进程

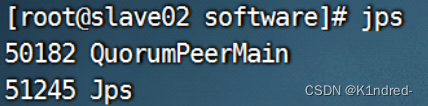
b. zkServer.sh status查看状态,其中Mode是否为leader或follower:
i. bigdata01:

ii. bigdata02:

iii. bigdata03:

iv. 注意:此时但凡出现非leader||follower,例如standalone || not running则表示此台服务器配置有误导致未能成功加入到集群当中 - 依次启动客户端:zkCli.sh
4.2.4 zoo.cfg可配置项
| 参数 | 说明 |
|---|---|
| clientPort | 客户端连接服务器端的端口,即Zookeeper的对外服务端口,一般默认为2181 |
| dataDir | 数据目录,即存储快照文件以及事务日志文件的目录 |
| dataLogDir | 1.事务日志输出目录。在不指定的情况下,和dataDir一致 |
| 2.正常运行过程中,针对所有事务操作,在返回客户端ACK的响应前,Zookeeper会确保已经将本次事务操作的事务日志写到磁盘上,只有这样,事务才会生效 | |
| tickTime | Zookeeper中的一个时间单元。Zookeeper中所有时间都是以这个时间单元为基础,进行整数倍配置,默认值:2000ms |
| initLimit | 1. follower在启动过程中,会从leader同步所有最新数据,然后确定自己能够对外服务的起始状态。leader允许follower在initLimit 时间内完成这个工作 |
| 2.如果Zookeeper集群的数据量确实很大了,follower在启动的时候,从leader上同步数据的时间也会相应变长,因此在这种情况下,有必要适当调大这个参数了,默认是:10*ticktime | |
| syncLimit | 1.表示leader 与 follower 之间发送消息,请求和应答时间长度,默认是:5*ticktime |
| 2.如果follower 在设置的时间内不能与leader 进行通信,那么此 follower 将被丢弃 | |
| 3.当集群网络环境不好时,可以适当调大 | |
| minSessionTimeout maxSessionTimeout | 1.Session超时时间限制,如果客户端设置的超时时间不在这个范围,那么会被强制设置为最大或最小时间,默认的Session超时时间是在2 * tickTime ~ 20 * tickTime 这个范围 |
| snapCount | 1. snapshot文件存储的快照数量。即在Zookeeper中每进行snapCount次事务之后,Zookeeper会生成一个新的快照文件snapshot.*,同时创建一个新的日志文件log. *默认值为100000 |
| 2. 在产生新的leader的时候,也会产生新的快照文件以及对应的事务日志 | |
| autopurge.purgeInterval | 1.表示清理快照文件和事务日志的间隔时间,默认单位是小时,默认数量是0,即不开启 |
| 2. 从Zookeeper的3.4.0版本开始,Zookeeper提供了自动清理快照和事务日志的功能。 | |
| autopurge.snapRetainCount | 表示在清理快照文件的时候需要保留的文件个数 |
| server.x=hostname:端口号1:端口号2 | 1.配置集群中的主机 |
| 2.x是主机编号,即myid | |
| 3.端口号1是原子广播端口,用于leader和follower之间的通信 | |
| 4.端口号2是选举端口,用于选举过程中的通信。 | |
| jute.maxbuffer | 用于控制每一个节点的最大存储的数据量。 默认是1M |
| globalOutstandingLimit | 1.最大请求堆积数。默认是1000 |
| 2.Zookeeper运行的时候, 尽管server已经没有空闲来处理更多的客户端请求了,但是还是允许客户端将请求提交到服务器上来,以提高吞吐性能。而为了防止server内存溢出,用该属性限制请求堆积数。 | |
| preAllocSize | 预先开辟磁盘空间,用于后续写入事务日志,默认是64M,即每个事务日志大小就是64M。 |
| leaderServers | 默认情况下,leader是会接受客户端连接,并提供正常的读写服务。但是,如果需要leader专注于集群中机器的事务协调(原子广播),那么可以将这个参数设置为no,这样一来,会提高整个zk集群性能。 |
| maxClientCnxns | 控制的每一台zk服务器能处理的客户端并发请求数。默认是60。 |
4.3 zookeeper集群状态指令
4.3.1 nc工具
- 简介:netcat是一个小型的网络通信工具,模拟发起TCP请求;可以借助Linux nc工具来查看zookeeper集群服务器状态
4.3.2 集群状态指令
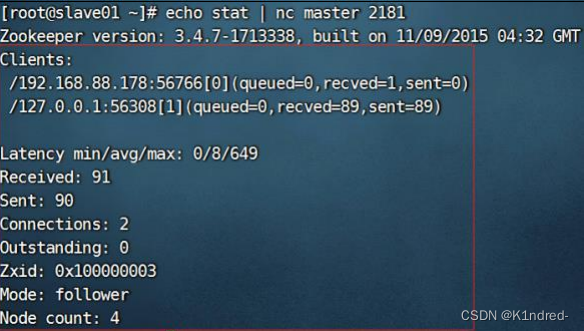
- 查看集群中某个服务器的状态:echo stat | nc master 2181
- 查看集群中某个服务器是否正常运行:echo ruok | nc slave01 2181
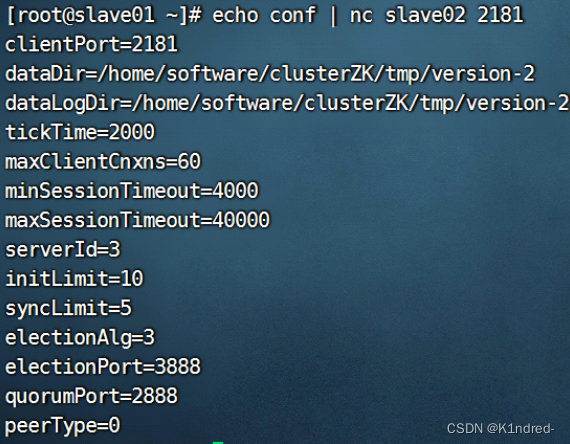
执行完成后回复 imok ,则表示当前节点已经启动 - 查看集群中某个服务器的节点配置信息:echo conf | nc slave02 2181
- 关闭集群中某个服务器: echo kill | nc master 2181
4.4 zookeeper集群特性
4.4.1 数据一致性
- 客户端不论连接到zookeeper集群中的哪个服务器上,展示给客户端的都是相同的视图;也即znode树结构一致以及数据一致
4.4.2 原子性
- 对于事务型决议的更新(增删改),只有成功或者失败两种可能,没有中间状态;
- 要么都更新更新,要么都更新失败
- 要么整个集群中所有机器都成功应用了某个事务,要么都没有应用某个事务;一定不会出现集群中部分
机器应用了该事务,而另一部分机器没用应用的情况
4.4.3 可靠性
- 一旦zookeeper集群中服务器端成功应用了某个事务(记录了该事务日志),并且完成了客户端的响
应,那么该事务所引起的服务器端状态变化就会一直保留下来,直到有另一个事务对其进行了更改
4.4.4 顺序性
- 只要某一台服务器上消息a是在消息b之前发布的,那么在所有的服务器上消息a都是消息b之前被发布
- 客户端在发起请求时,都会跟着一个递增的命令号(在底层指的就是zxid);根据此机制,zookeeper会确保客户端提交的事务的执行顺序
4.4.5 实时性
- zookeeper可以保证客户端在非常短的时间间隔范围内感知到服务器的更新信息、失效信息或者指定监听事件的变化信息
- 示例:
a. 服务器关闭,此时客户端会立即感知到所连接到这台服务器出错:Session 0x186c4330ffe0000 for server null, unexpected error, closing socket connection and attempting reconnect
b. 再次开启服务器,若还在此时客户端会话的连接超时时间范围内,则会恢复当前客户端会话;若此
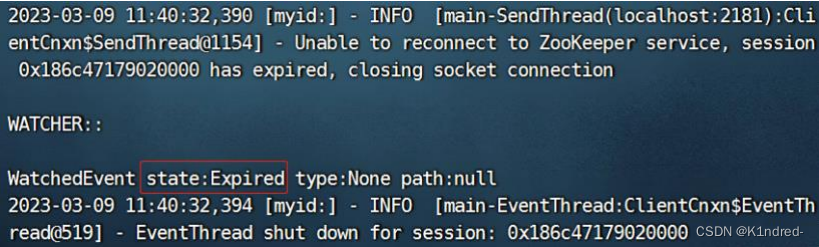
时已经超过连接时间,会提示当前客户端会话已经过期:Unable to reconnect to ZooKeeper service, session 0x186c47179020000 has expired, closing socket connection
c. 若超时过期,则需要重新开启一个客户端
4.4.6 过半性
- 过半服务(运行):zookeeper集群中只有超过一半服务器正常工作(状态正常),才能对外提供服务,举例:
a. 关闭掉bigdata01&bigdata03上的zkServer.sh stop,立马bigdata02上的客户端会提示:
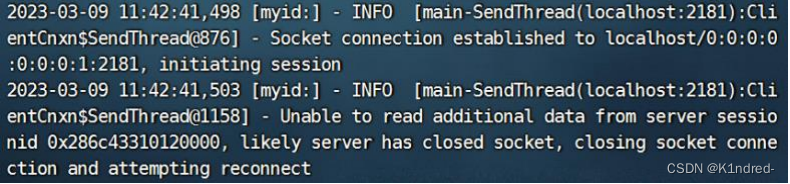
b. bigdata02上的服务器状态变为:

- 过半操作:zookeeper集群中只有超过一半服务器存活,客户端才能提交请求应用请求;在zookeeper集群在做事务决议的时候,一定要有半数以上的服务器正常写入了此事务(增删改)才能更新事务
- 所以一般来说,zookeeper集群的数量最好是奇数个
- 过半选举
4.5 选举机制
4.5.1 第一阶段:数据恢复阶段
- 即恢复之前数据
4.5.2 第二阶段:选举阶段
- 集群中每一台zookeeper服务器都会推举自己成为leader并且提交选举协议:
a. 自己所拥有的最大事务id——zxid(一般是指mZxid或者pzxid)
b. 自己的选举id——服务器编号——myid
c. 逻辑时钟值——currentEpoch:用于确保每一台zookeeper服务器都处于同一轮选举当中
d. 每一台zookeeper服务器都会包含以上信息的选举协议通过选举端口3888发给集群中的其他服务器,然后进行PK - PK原则:
a. 在选举的时候,会先比较两个服务器上的事务日志文件中所记录的最大事务id,也即zxid;zxid越大,说明此时此台服务器执行过的事务越新;则zxid较大的胜出
b. 如果zxid一致,则比较选举id,也即myid;则myid较大的胜出
c. 过半选举:
i. 只有集群中超过半数的服务器节点统一才能通过leader的选举,也即一个服务器节点胜过了一半及以上的节点时,此节点才能成为leader
ii. 当一个集群中已经选举出了leader,那么后续添加|启动的服务器节点无论zxid和myid多大,这个节点都只能成为follower
4.6 ZAB协议
4.6.1概述
- ZAB协议:此原子广播协议是为zookeeper分布式协调服务框架而设计的支持数据广播和崩溃恢复的协议
- 此协议是基于2PC 二阶段提交,核心在于“一票否决”:
a. 确认阶段:协调者(部分等价领导者leader)接收到客户端请求之后,将请求转发给每一个参与者(部分等价跟随者follower),等待参与者的反馈
b. 提交阶段:如果所有的参与者都返回请求执行成功的应答,那么协调者就会给参与者发布指令执行这个请求,兵器协调者会给客户端返回成功信号
c. 中止阶段:如果协调者收到参与者返回请求执行失败的应答 或者 没有收到全部参与者的成功应答,那么会要求其余参与者删除该请求操作并且同时给客户端返回失败信号 - ZAB协议包括了两种基本模式:
a. 消息原子广播:保证了数据的一致性
b. 崩溃恢复:解决了2PC算法的单点故障
4.6.2 原子广播
- 在zookeeper中,主要依赖ZAB协议中的原子广播来实现分布式数据一致性;基于此协议,ZK可以实现主备模式的系统架构保证集群的一致性
- 实现原理:ZK使用一个单一的主进程——leader服务器来接收并处理客户端的所有事务请求,并采用ZAB的原子广播协议,将服务器此时的数据状态变更以事务请求的形式广播到所有的从进程——follower服务器;所有的事务请求必须由一个全局的唯一的服务器leader来协调处理
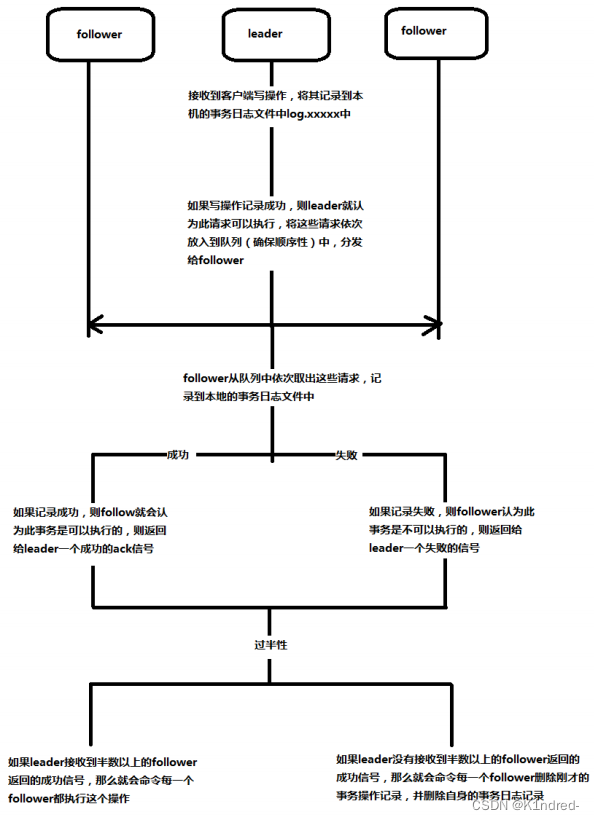
- 流程图(以三台服务器为例):
- 具体流程
a. 针对客户端的事务决议,leader服务器会将事务写入到本地的log文件中
b. 然后,leader服务器会为本次请求对应的事务决议分配一个全局递增的唯一的事务ID——zxid
c. leader服务器会给每个follower服务器都各自分配一个单独的队列queue,将需要广播的事务决议依次(依照事务id的大小)放入到队列中,分发给每个follower
d. 每个follower收到队列之后,从中依次取出事务决议,写入到本地的log文件中
e. 如果写入成功则返回给leader一个ack成功信号,此时leader若接收到半数以上的follower的ack信号,就会广播commit消息给所有follower通知其进行事务的提交,同时leader自身也进行事务提交
f. 注意:如果某个follower记录一个事务请求为失败,但是整个集群又决定执行此操作,那么此时follower会给leader发送请求,然后leader会将该操作再次发送给follower进行重新记录,在此follower重新记录的过程中,不参与过半投票
g. 如果写入失败则返回给leader一个失败信号,此时leader若未接受到半数以上的成功信号,就会广播rollback消息给所有follower通知其删除刚才的事务请求,同时leader也删除事务请求
4.6.3 崩溃恢复
- 当整个集群中的leader丢失的时候(当leader服务器出现崩溃、关机、重启等场景)或者因为网络故障问题导致过半follower不能与此leader服务器保持通信,zookeeper集群就会进入到崩溃恢复模式下;
- 只要此时集群中存在着过半的服务器能够彼此正常通信时,集群会自动选举出一个新的leader;
- 每次新选举的leader会自动分配一个全局递增的epochID;当leader选举出来之后,将epochID分发给其余每个follower,如果同时出现了两个leader,那么这个zookeeper会自动kill掉epochID较小的leader来保证集群中只有一个leader
- 当选举出了新的leader服务器,同时集群中已经有过半服务器和该leader完成了状态同步,ZAB协议就会推出崩溃恢复模式
状态同步:数据同步,用于保证集群中服务器数据一致性
- 当集群中有过半follower服务器和leader服务器完成了状态同步,那么zookeeper集群就可以进入到原子广播模式
- 每更换过一次leader,就会产生一个新的事务日志文件
- 如果有一台同样遵循ZAB协议的服务器启动后加入到集群中,如果此时集群中已经存在一个leader在负责进行原子广播,那么新加入的服务器就会自觉进入到数据恢复模式:和leader服务器通信,进行状态同步,然后加入到消息原子广播流程中
4.7 zookeeper的动态扩容
4.7.1 集群的动态扩容
- 不停机扩容:zookeeper集群在扩容过程中可以正常对外提供服务,同时不能丢失数据(正确同步数据)
- 优缺点:
a. zookeeper集群的扩容,对于读请求来说是提升性能;
b. 但是对于写请求未必是一件好事,因为如果添加了更多的集群服务器,由于写请求都是需要leader统一协调处理并且写入操作要成功要求需要半数以上的服务器同意,因此投票成本随着投票者越多越显著增加
c. 配置项leaderServers - zookeeper集群的动态扩容分为两种形式:
a. 正常意义的扩容:给源服务器增加follower节点
b. 附属意义的扩容:扩容的新增节点为观察者observer(zookeeper的另一种节点状态)
4.7.2 正常意义的扩容——增加follower状态节点
- 教学环境,采用伪分布式集群的形式(通过监听服务器不同的端口来模拟一台新的zookeeper服务器)演示
- 因为zookeeper集群特性的过半性,在follower扩容时建议扩容的服务器节点个数为偶数个,确保最终扩容后的集群服务器个数为奇数个
- 源服务器(三台)配置:
a. dataDir=/home/software/clusterZK/tmp
b. clientPort=2181
c. 集群地址:
server.1=192.168.88.177:2888:3888
server.2=192.168.88.178:2888:3888
server.3=192.168.88.179:2888:3888
bigdata01:192.168.88.177:2181
bigdata02:192.168.88.178:2181
bigdata03:192.168.88.179:2181
- 扩容的集群服务器
a. 重新在bigdata03上解压zookeeper的安装包
b. 复制出两个zookeeper文件夹,分别命名为clusterZK01 & clusterZK02
c. 修改clusterZK01的conf/zoo.cfg:
i. dataDir=/home/software/clusterZK01/tmp
ii. clientPort=2182
iii.构建扩容后的集群地址:
server.1=192.168.88.177:2888:3888
server.2=192.168.88.178:2888:3888
server.3=192.168.88.179:2888:3888
server.4=192.168.88.179:2889:3889
server.5=192.168.88.179:2890:3890
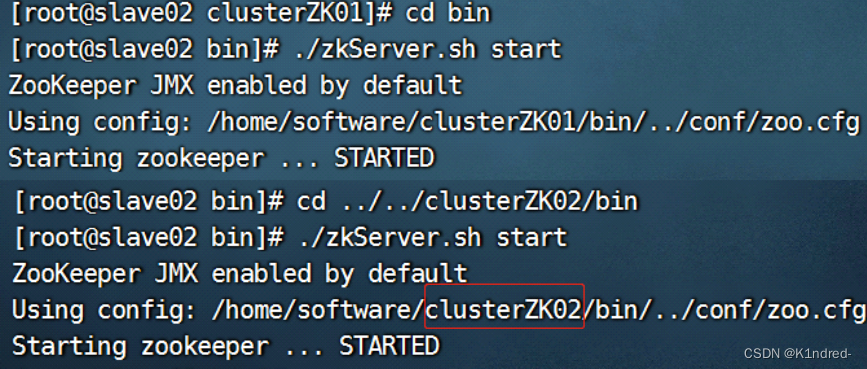
iv. 新建tmp目录并在其中新建myid文件,编号为4 - 启动扩容节点:
a. 分别进入到clusterZK01/bin & clusterZK02/bin下执行:./zkServer.sh start
b. 查看状态:
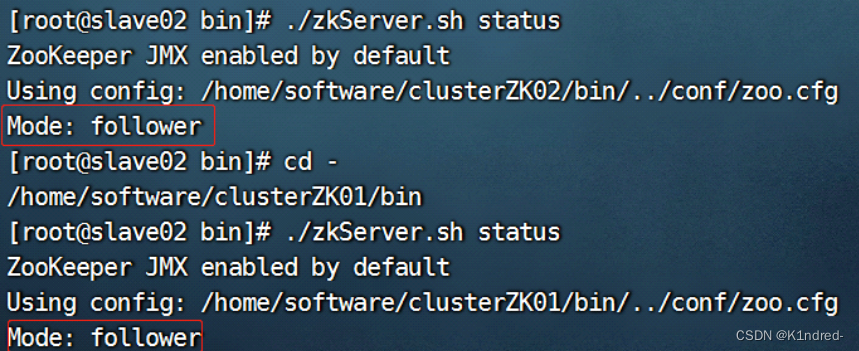
- 注意:
a. 扩容节点的zk服务启动之后,首先处于投票选举状态(Looking\Voting);收到源服务器的leader和follower的选票,统计选票,如果集群中已经某个节点拥有超过半数的选票(已经是leader状态),则扩容节点设置自身状态为follower,退出选举环节
b. 此时扩容服务器和源集群建立了正常的连接
c. 随意登录某一台扩容机的客户端:./zkCli.sh -server slave02:2182

d. 当同样遵守ZAB协议的服务器启动并加入到集群中,如果此时集群中已经存在一个leader服务器在负
责进行消息原子广播,那么新加入的服务器会自觉的进入到数据恢复模式 - 当前扩容节点配置完成之后,故障与否不会影响到源集群的过半机制判断
假设先将server.3 & server.4 & server.5三台服务器宕机,此时集群中存活>着server.1 & server.2机器,并且仍然可以正常对外提供服务
因为源集群从配置角度来看是依旧保持独立的,如果需要真正的保证扩容后的集群符合所有特性,那么则需要修改时源集群中所有服务器的集群地址配置项并且重启源集群!!
4.7.3 附属意义的扩容:扩容的新增节点为观察者observer
- 观察者概念:
a. 在zookeeper引入此新的zookeeper节点类型为observer,是为了帮助处理投票成本随着追随者增加而增加的问题并且进一步完善了zookeeper的可扩展性
b. 观察者不参与投票,他只监听投票的结果,但是观察者可以和追随者一样运行;也即 客户端可以连接到观察者状态的服务器发起读取和写入的请求,会像追随者一样转发请求到领导者,而观察者只是简单的等待监听投票的结果
c. 观察者数量不会影响到投票性能,因此观察者不是zookeeper集群整体的主要节点,观察者产生故障或者从集群中断开连接都不会影响到集群的性能 - 意义:
在实际使用中,观察者可以连接到比追随者更不可靠的网络;事实上,观察者可以用于从其他数据中心和zookeeper服务器通信 - 优点:
a. 提升集群的读性能,对写性能影响很小
b. 可以将observer部署在异地机房,读请求就近发起,降低延迟 - 缺点:
a. 对写操作有一定的影响:观察者所在的服务器处于无监控状态,无法保证数据都同步成功了,可能会因为网络原因造成一些写入请求被丢弃等
b. 如果observer部署异地机房,写同步的延迟可能会增加
c. 源集群的稳定性没有提高 - observer扩容配置:
a. 假设扩容的observer服务器为server.6 & server.7
b. 重新在bigdata03上解压并重命名为observerZK01 || observerZK02
c. 并且在conf/zoo.cfg文件中进行以下配置:
01:
dataDir=/home/software/observerZK01/tmp
clientPort= 2184
02:
dataDir=/home/software/observerZK02/tmp
clientPort=2185
01&02:
添加声明当前zk服务器类型为observer server的属性:
peerType=observer
在构建集群地址时,需要将配置为观察者的主机后添加上观察者标记:observer
server.1=192.168.88.177:2888:3888
server.2=192.168.88.178:2888:3888
server.3=192.168.88.179:2888:3888
server.4=192.168.88.179:2889:3889
server.5=192.168.88.179:2890:3890
server.6=192.168.88.179:2891:3891:observer
server.7=192.168.88.179:2892:3892:observer
分别新建并设置 myid为 6 & 7
d. 启动服务器 并且查看此时服务器的状态是否为observer:
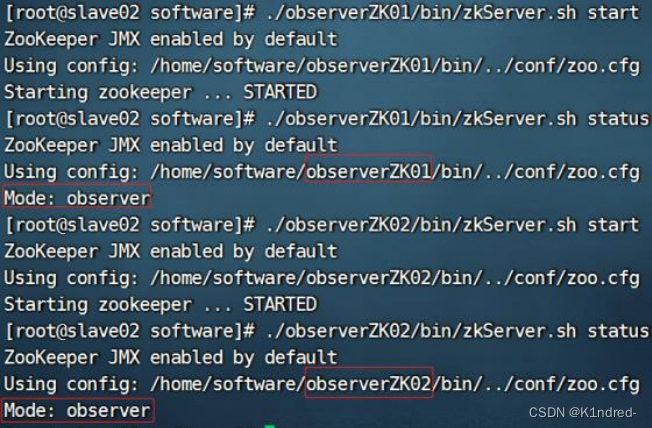
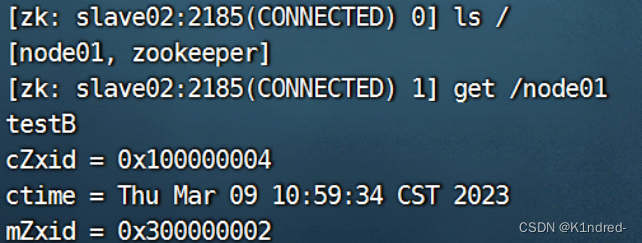
e. 连接到observer服务器的客户端: ./observerZK02/bin/zkCli.sh -server slave02:2185
4.8 zookeeper的API
4.8.1 开发java-maven工程
- 编写pom.xml文件,导入依赖:
<dependencies>
<!--zookeeper压缩包中有以下依赖包-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.7</version>
</dependency>
</dependencies>
- 将log4j.properties文件拷贝到工程的src/main/resources目录下
- 注意:如果maven工程存在问题,pom之类的无法导入jar依赖包,则改为创建普通java工程,从zookeeper-3.4.7.tar.gz的解压包中将其中依赖包导入到工程即可
4.8.2 开发zookeeper-API
- 基础代码(这里用了另外的三台)
a.所有操作在进行之前首先需要连接
b.方法名即为操作,create表示添加,delete表示删除,get表示获取
c.Sycn表示同步,Asycn表示异步
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import org.junit.Before;
import org.junit.Test;
import java.util.concurrent.CountDownLatch;
public class ZookeeperAPI {
private String connectString="192.168.160.130:2181,192.168.160.131:2181,192.168.88.135:2181";
private int sessionTimeout = 5000;
private ZooKeeper zk = null;
@Before
public void testConnect() throws Exception {
//线程递减锁
final CountDownLatch cdl = new CountDownLatch(1);
//第一个参数connectString为要连接的zk集群服务器地址
//第二个参数sessionTimeout为连接超时时间
//第三个参数为监听事件:事件状态为SyncConnect时表示连接成功
zk = new ZooKeeper(
connectString,
sessionTimeout,
new Watcher(){
@Override
public void process(WatchedEvent event){
//判断此时event的状态
if(event.getState() == Event.KeeperState.SyncConnected){
//客户端已经连接上集群中的某一台
System.out.println("连接成功");
}
//减掉锁
cdl.countDown();
}
});
//除非减为0,否则不会执行结束
cdl.await();
System.out.println("zk:"+zk);
}
@Test
public void testSycnCreate() throws Exception {
//path:节点路径
String node = zk.create(
"/node03",
"testSycnCreate".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT
);
System.out.println("Node:" + node);
}
@Test
public void testAsyncCreate() throws Exception {
final CountDownLatch cdl = new CountDownLatch(1);
zk.create(
"/node04",
"cfeateAsycn".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT,
new AsyncCallback.StringCallback() {
@Override
public void processResult(int rc, String path, Object ctx, String name) {
System.out.println(String.format("异步回调:rc=%s;path=%s;ctx=%s;name=%s",rc,path,ctx,name));
cdl.countDown();
}
},
"context"
);
cdl.await();
}
@Test
public void testSycnDelete() throws Exception{
zk.delete("/node03", -1);
}
@Test
public void testAsyncDelete() throws Exception{
final CountDownLatch cdl = new CountDownLatch(1);
zk.delete("/node04", -1, new AsyncCallback.VoidCallback() {
@Override
public void processResult(int i, String s, Object o) {
System.out.println(String.format("异步:rc=%s;path=%s;ctx=%s;",i,s,o));
cdl.countDown();
}
},
"context");
cdl.await();
}
@Test
public void testSyncGet() throws Exception{
Stat stat = new Stat();
byte[] data = zk.getData("/node05", null, stat);
String dataStr = new String(data, "utf-8");
System.out.println("node值:" + dataStr);
}
@Test
public void testAsyncGet() throws Exception{
final CountDownLatch cdl = new CountDownLatch(1);
zk.getData("/node04",
null,
new AsyncCallback.DataCallback() {
@Override
public void processResult(int i, String s, Object o, byte[] bytes, Stat stat) {
System.out.println(String.format("异步:path=%s;data=%s;stat=%s",s, new String(bytes), stat));
cdl.countDown();
}
},
"context");
cdl.await();
}
@Test
public void listenDataChange() throws Exception{
//监听
final CountDownLatch cdl = new CountDownLatch(1);
byte[] oldData = zk.getData("/node03",
new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
//节点变化则放行
if(watchedEvent.getType() == Event.EventType.NodeDataChanged){
System.out.println("节点数据更新");
try{
byte[] data = zk.getData("/node03",null,null);
System.out.println("更新后数据:" + new String(data));
}catch (Exception e){
e.printStackTrace();
}
}
cdl.countDown();
}
},
null);
System.out.println("此时节点数据:" + new String(oldData));
cdl.await();
}
}
- 拓展
a. 异步回调获取节点数据,并监听节点数据的变化
b. 判断节点是否存在,并监听节点的变化(增加|删除)
c. 获取某个节点的子节点,并监听子节点的变化
import org.apache.zookeeper.AsyncCallback;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import org.junit.Before;
import org.junit.Test;
import java.util.List;
import java.util.concurrent.CountDownLatch;
/**
* Author:K1ndred
*/
public class WorkDemo {
private String connectString="192.168.160.130:2181,192.168.160.131:2181,192.168.88.135:2181";
private int sessionTimeout = 5000;
private ZooKeeper zk = null;
//连接集群
@Before
public void testConnect() throws Exception {
final CountDownLatch cdl = new CountDownLatch(1);
zk = new ZooKeeper(
connectString,
sessionTimeout,
new Watcher(){
@Override
public void process(WatchedEvent event){
//判断此时event的状态
if(event.getState() == Event.KeeperState.SyncConnected){
//客户端已经连接上集群中的某一台
System.out.println("Connection Succeeded!");
}
cdl.countDown();
}
});
//除非减为0,否则不会执行结束
cdl.await();
System.out.println("zk:"+zk);
//分割控制台
System.out.println("====================");
}
//拓展a:异步回调获取节点数据,并监听节点数据的变化
@Test
public void WorkDemo1() throws Exception {
final CountDownLatch cdl = new CountDownLatch(2);
zk.getData("/node03",
new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
//节点变化则放行
if(watchedEvent.getType() == Event.EventType.NodeDataChanged){
System.out.println("New Data!");
try{
byte[] data = zk.getData("/node03",null,null);
System.out.println("更新后数据:" + new String(data));
}catch (Exception e){
e.printStackTrace();
}
System.out.println("====================");
}
cdl.countDown();
}
},
new AsyncCallback.DataCallback() {
@Override
public void processResult(int i, String s, Object o, byte[] bytes, Stat stat) {
System.out.println(String.format("异步:path=%s;data=%s;stat=%s",s, new String(bytes), stat));
System.out.println(String.format("当前数据:data=%s",new String(bytes)));
//分割
System.out.println("====================");
cdl.countDown();
}
},
"context");
cdl.await();
}
//拓展b:判断节点是否存在,并监听节点的变化(增加|删除)
@Test
public void WorkDemo2() throws Exception{
final CountDownLatch cdl = new CountDownLatch(2);
//异步判断
zk.exists("/node05",
new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
if(watchedEvent.getType() == Event.EventType.NodeCreated){
System.out.println("节点出现了!");
System.out.println("====================");
}
else if(watchedEvent.getType() == Event.EventType.NodeDeleted){
System.out.println("节点跑走了!");
System.out.println("====================");
}
cdl.countDown();
}
},
new AsyncCallback.StatCallback() {
@Override
public void processResult(int i, String s, Object o, Stat stat) {
System.out.println(String.format("异步:path=%s;ctx=%s;stat=%s",s, o, stat));
if(stat == null){
System.out.println("节点不存在");
}
else{
System.out.println("节点存在");
}
//分割
System.out.println("====================");
cdl.countDown();
}
},
"context");
cdl.await();
}
//拓展c:获取某个节点的子节点,并监听子节点的变化
@Test
public void WorkDemo3() throws Exception{
final CountDownLatch cdl = new CountDownLatch(2);
//异步获取
zk.getChildren("/node03",
new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
if (watchedEvent.getType() == Event.EventType.NodeChildrenChanged) {
try {
List<String> nodes = zk.getChildren("/node03", false);
System.out.println("子节点发生变化!");
System.out.println("现在子节点如下:");
for (String node : nodes) {
System.out.println(node);
}
System.out.println("====================");
} catch (Exception e) {
e.printStackTrace();
}
}
cdl.countDown();
}
},
new AsyncCallback.Children2Callback() {
@Override
public void processResult(int i, String s, Object o, List<String> list, Stat stat) {
System.out.println(String.format("异步:path=%s;ctx=%s;stat=%s",s, o, stat));
System.out.println("当前子节点如下:");
for(String node : list){
System.out.println(node);
}
System.out.println("====================");
cdl.countDown();
}
},
"context");
cdl.await();
}
}
- API的方法还有很多,比如判断是否存在的exists等
- 根据分析,异步操作的方法大部分是没有返回值的,反之则然
- 调整线程锁的数量可以实现不同的业务

















 5987
5987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











