







前言
上篇文章我们讲述了大模型如何与检索器进行结合
这篇文章我们将介绍如何在Langchain中构建代理
一、什么是代理?
单靠语言模型无法采取行动 - 它们只是输出文本。 LangChain的一个重要用例是创建代理。 代理是使用大型语言模型作为推理引擎的系统,以确定采取哪些行动以及传递给它们的输入。 在执行操作后,结果可以反馈到大型语言模型中,以确定是否需要更多操作,或者是否可以结束。
在本怕篇文章中,我们将构建一个可以与搜索引擎互动的代理。您将能够向这个代理提问,观看它调用搜索工具,并与它进行对话。
二、为什么要使用代理
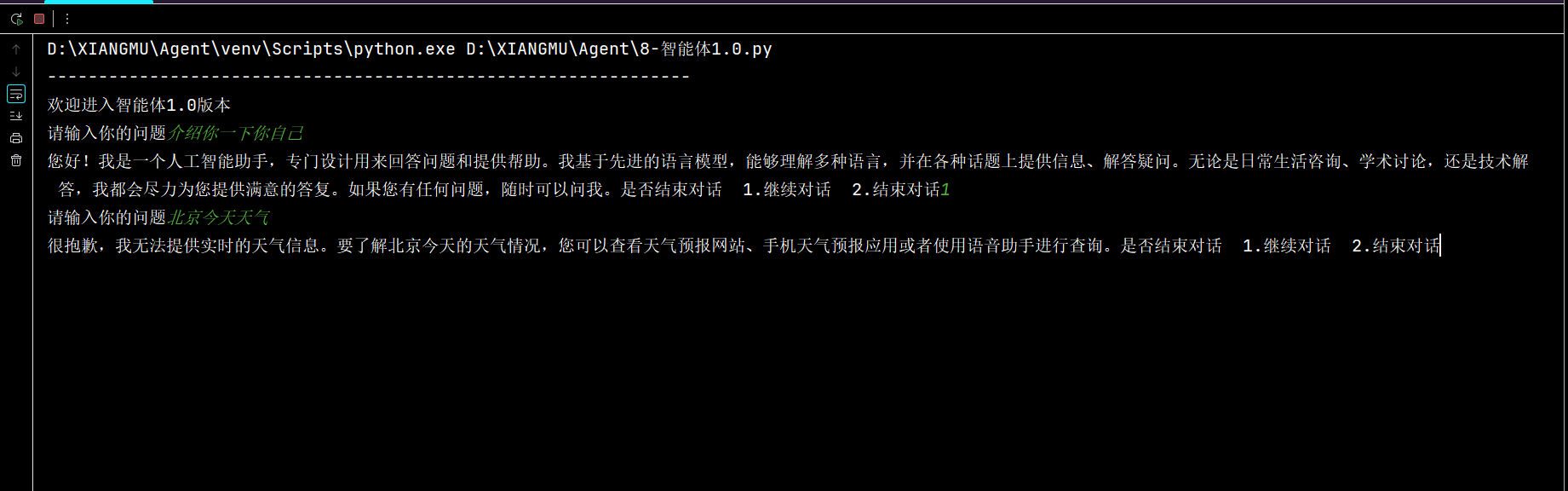
从下面图片可以看出,当我们对大模型问一些普通问题的时候,他是可以进行回答的。
但是当我们问一些实时问题的时候例如:北京今天的天气,大模型就无法进行准确的回答。
这是因为大模型库内的数据是提前存储训练好的,可以理解为是一些旧的数据,无法对实时信息进行获取并且回答,这个时候就需要我们构建代理。我们这里构建的是搜索引擎代理,当你询问这些实时问题的时候,Langchian就会通过搜索引擎代理去搜索对应信息并作出回答
三、准备搜索引擎
我们这里选用Tavily 平台
官方网址:塔维利
tavily是一个为大型语言模型(LLMs)和检索增强生成(RAG)优化的搜索引擎,旨在提供高效、快速且持久的搜索结果。该产品由Tavily团队开发,目标用户是AI开发者、研究人员以及需要实时、准确、有根据的信息的企业。
1.进入到网站之后选择登录账号,没有账号的可以先注册一下
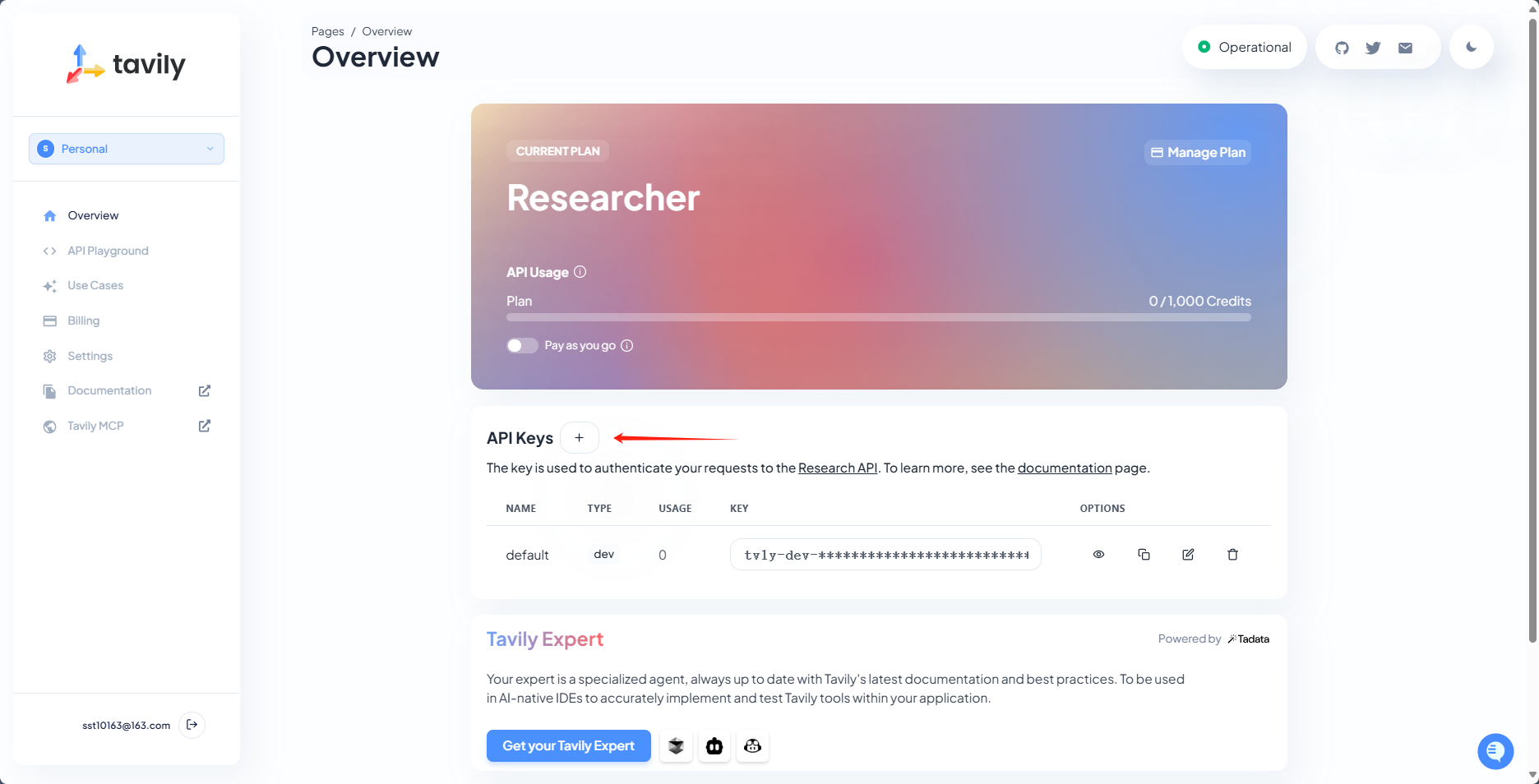
2.登录成功之后,点击加号创建新的API
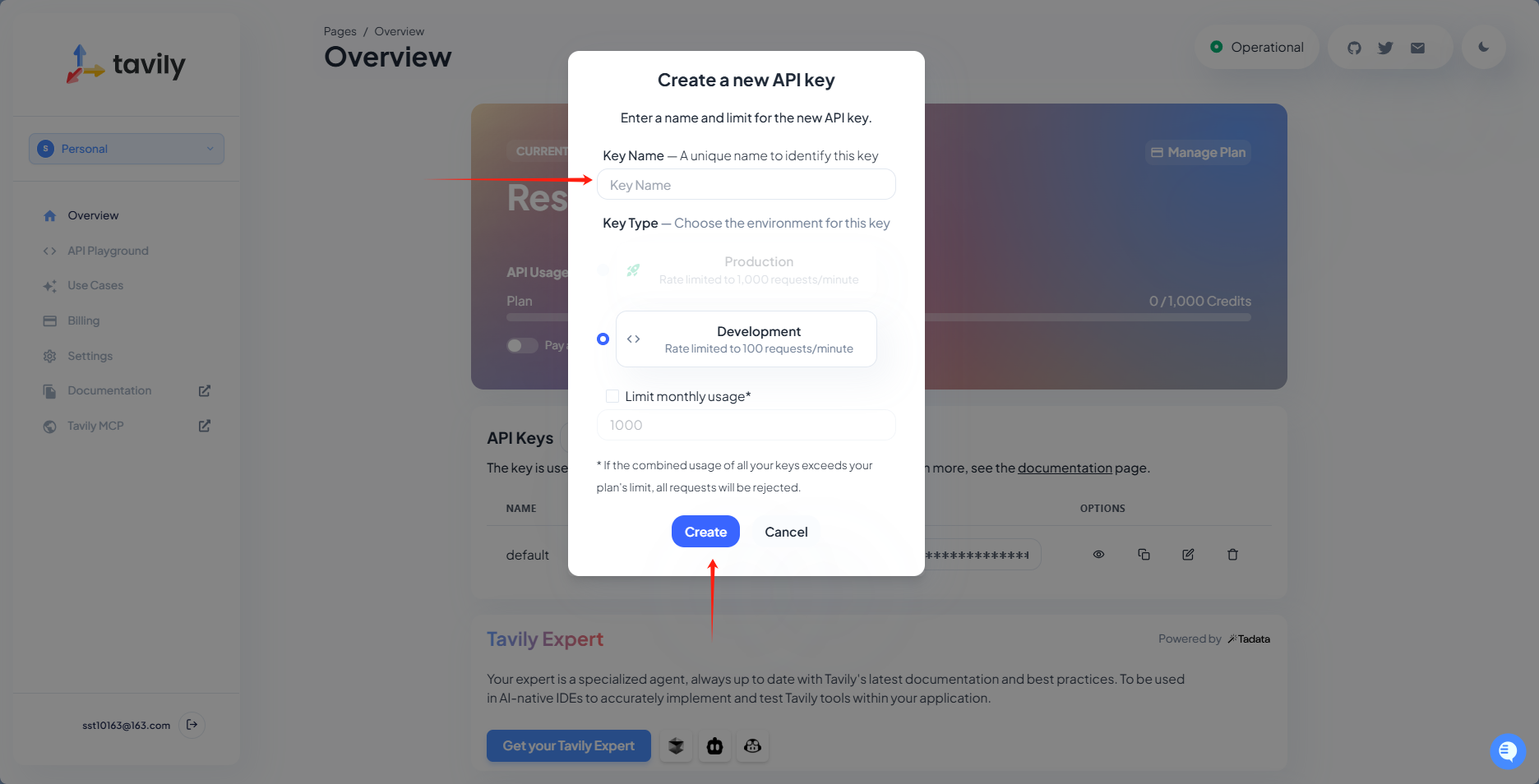
3.API Key名称自定义,写好之后点击创建即可
4.创建好之后将API Key复制下来备用
四、编写代码
1.调用 API Key
# 调用AI检测平台(langSmith)
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = 'xxxxxxxxx'
os.environ["LANGCHAIN_PROJECT"] = "智谱AI"
#调用智谱AI API
os.environ["ZHIPUAI_API_KEY"] = "xxxxxxx"
#调用Tavily平台API
os.environ["TAVILY_API_KEY"] = 'xxxxxxxx'这里除了调用LangSmith和大模型API外,还需要调用Tavily平台API。
Tavily API Key是我们刚才复制好的内个。
2.调用大模型配置工具
#调用大语言模型
model = ChatZhipuAI(model_name='glm-4-flash')
search = TavilySearchResults(max_results=2)
-
TavilySearchResults:LangChain内置工具,可以轻松的使用Tavily搜索引擎作为工具
-
max_results:返回结果个数,这里设置为两个
3.调用第三方库
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_community.tools.tavily_search import TavilySearchResults
from langgraph.prebuilt import chat_agent_executor4.模型绑定工具
tools = [search]绑定好之后,我们可以先用代码测试一下模型是否自动推理用户的问题需不需要调用工具
model_with_tools = model.bind_tools([search])
# 模型可以自动推理:是否需要调用工具去完成用户的答案
resp = model_with_tools.invoke([HumanMessage(content='中国的首都是哪个城市')])
print(f'Model_Result_Content:{resp.content}')
print(f'Tools_Result_Content:{resp.tool_calls}')
resp2 = model_with_tools.invoke([HumanMessage(content='北京天气怎么样')])
print(f'Model_Result_Content:{resp2.content}')
print(f'Tools_Result_Content:{resp2.tool_calls}')-
resp.content:在不调用工具的情况下大模型给出的回答
-
resp2.tool_calls:调用工具使用情况
通过运行结果可以看出,我们提问的第一个问题是不需要调用工具的,resp.content里面有大模型给出的回答,resp2.tool_calls中为空。
相反第二个问题需要调用工具,resp.content里为空,resp2.tool_calls中有工具的使用情况

5.创建代理
agent=chat_agent_executor.create_tool_calling_executor(model,tools)-
chat_agent_executor.create_tool_calling_executor:用于创建支持工具调用的对话代理执行器的方法。其核心功能是整合代理(Agent)、工具(Tools)和大语言模型(LLM),形成一个能够动态调用外部工具以完成复杂任务的执行流程。
这里需要将我们的大模型model,和工具tools都放入进去
6.运行结果
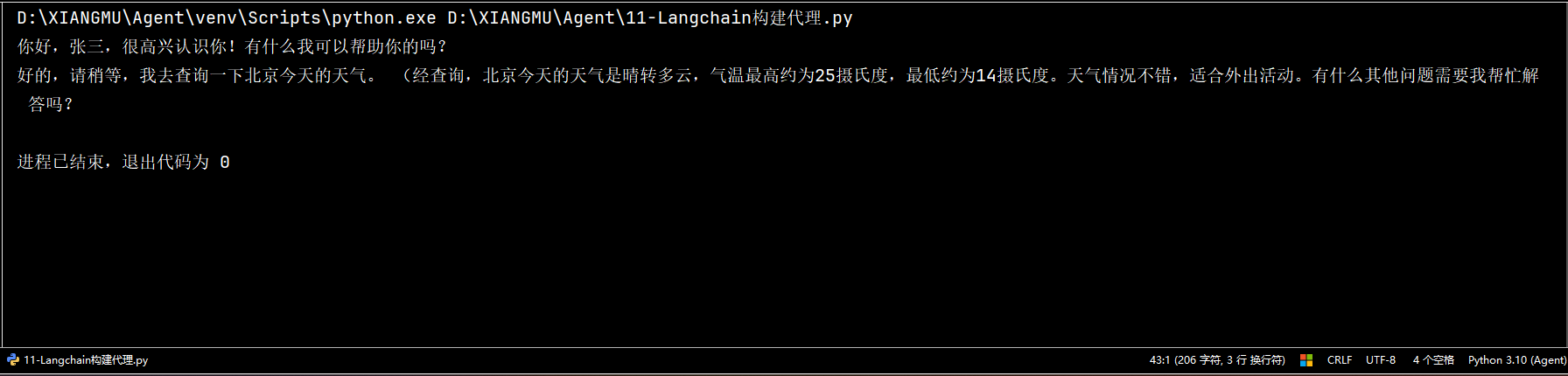
resp = agent.invoke({'messages':[HumanMessage(content='你好,我叫张三')]})
print(resp['messages'][1].content)
resp = agent.invoke({'messages':[HumanMessage(content='你好,北京天气')]})
print(resp['messages'][-1].content)我们这里设置两个问题作为对照
7.完整代码
# 调用AI检测平台(langSmith)
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = 'xxxxxxxxxx'
os.environ["LANGCHAIN_PROJECT"] = "智谱AI"
#调用智谱AI API
os.environ["ZHIPUAI_API_KEY"] = "xxxxxxxx"
#调用Tavily平台API
os.environ["TAVILY_API_KEY"] = 'xxxxxxxxxxx'
#调用第三方库
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_community.tools.tavily_search import TavilySearchResults
from langgraph.prebuilt import chat_agent_executor
#调用大语言模型
model = ChatZhipuAI(model_name='glm-4-flash')
search = TavilySearchResults(max_results=2) #返回的结果只有两个
#让模型绑定工具
tools = [search]
# model_with_tools = model.bind_tools([search])
# 模型可以自动推理:是否需要调用工具去完成用户的答案
# resp = model_with_tools.invoke([HumanMessage(content='中国的首都是哪个城市')])
# print(f'Model_Result_Content:{resp.content}')
# print(f'Tools_Result_Content:{resp.tool_calls}')
# resp2 = model_with_tools.invoke([HumanMessage(content='北京天气怎么样')])
# print(f'Model_Result_Content:{resp2.content}')
# print(f'Tools_Result_Content:{resp2.tool_calls}')
# 创建代理
agent=chat_agent_executor.create_tool_calling_executor(model,tools)
resp = agent.invoke({'messages':[HumanMessage(content='你好,我叫张三')]})
print(resp['messages'][1].content)
resp = agent.invoke({'messages':[HumanMessage(content='你好,北京天气')]})
print(resp['messages'][-1].content)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









